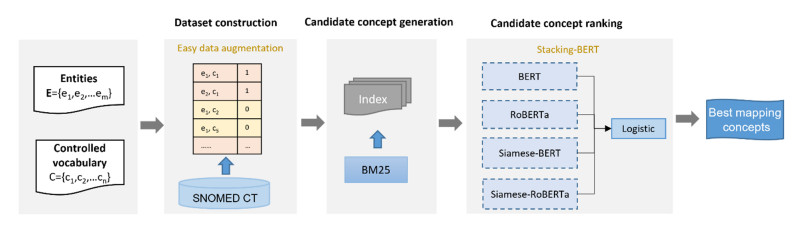
Medical procedure entity normalization is an important task to realize medical information sharing at the semantic level; it faces main challenges such as variety and similarity in real-world practice. Although deep learning-based methods have been successfully applied to biomedical entity normalization, they often depend on traditional context-independent word embeddings, and there is minimal research on medical entity recognition in Chinese Regarding the entity normalization task as a sentence pair classification task, we applied a three-step framework to normalize Chinese medical procedure terms, and it consists of dataset construction, candidate concept generation and candidate concept ranking. For dataset construction, external knowledge base and easy data augmentation skills were used to increase the diversity of training samples. For candidate concept generation, we implemented the BM25 retrieval method based on integrating synonym knowledge of SNOMED CT and train data. For candidate concept ranking, we designed a stacking-BERT model, including the original BERT-based and Siamese-BERT ranking models, to capture the semantic information and choose the optimal mapping pairs by the stacking mechanism. In the training process, we also added the tricks of adversarial training to improve the learning ability of the model on small-scale training data. Based on the clinical entity normalization task dataset of the 5th China Health Information Processing Conference, our stacking-BERT model achieved an accuracy of 93.1%, which outperformed the single BERT models and other traditional deep learning models. In conclusion, this paper presents an effective method for Chinese medical procedure entity normalization and validation of different BERT-based models. In addition, we found that the tricks of adversarial training and data augmentation can effectively improve the effect of the deep learning model for small samples, which might provide some useful ideas for future research.
Citation: Luqi Li, Yunkai Zhai, Jinghong Gao, Linlin Wang, Li Hou, Jie Zhao. Stacking-BERT model for Chinese medical procedure entity normalization[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1018-1036. doi: 10.3934/mbe.2023047
Medical procedure entity normalization is an important task to realize medical information sharing at the semantic level; it faces main challenges such as variety and similarity in real-world practice. Although deep learning-based methods have been successfully applied to biomedical entity normalization, they often depend on traditional context-independent word embeddings, and there is minimal research on medical entity recognition in Chinese Regarding the entity normalization task as a sentence pair classification task, we applied a three-step framework to normalize Chinese medical procedure terms, and it consists of dataset construction, candidate concept generation and candidate concept ranking. For dataset construction, external knowledge base and easy data augmentation skills were used to increase the diversity of training samples. For candidate concept generation, we implemented the BM25 retrieval method based on integrating synonym knowledge of SNOMED CT and train data. For candidate concept ranking, we designed a stacking-BERT model, including the original BERT-based and Siamese-BERT ranking models, to capture the semantic information and choose the optimal mapping pairs by the stacking mechanism. In the training process, we also added the tricks of adversarial training to improve the learning ability of the model on small-scale training data. Based on the clinical entity normalization task dataset of the 5th China Health Information Processing Conference, our stacking-BERT model achieved an accuracy of 93.1%, which outperformed the single BERT models and other traditional deep learning models. In conclusion, this paper presents an effective method for Chinese medical procedure entity normalization and validation of different BERT-based models. In addition, we found that the tricks of adversarial training and data augmentation can effectively improve the effect of the deep learning model for small samples, which might provide some useful ideas for future research.

| [1] |
N. Kang, B. Singh, Z. Afzal, E. M. van Mulligen, J. A. Kors, Using rule-based natural language processing to improve disease normalization in biomedical text, J. Am. Med. Inf. Assoc., 20 (2013), 876–881. https://doi.org/10.1136/amiajnl-2012-001173 doi: 10.1136/amiajnl-2012-001173

|
| [2] | O. Ghiasvand, R. J. Kate, UWM: Disorder mention extraction from clinical text using CRFs and normalization using learned edit distance patterns, in Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), (2014), 828–832. https://doi.org/10.3115/v1/S14-2147 |
| [3] |
O. Bodenreider, The unified medical language system (UMLS): integrating biomedical terminology, Nucleic Acids Res., 32 (2004), 267–270. https://doi.org/10.1093/nar/gkh061 doi: 10.1093/nar/gkh061
|
| [4] |
J. Jovanovixc, E. Bagheri, Semantic annotation in biomedicine: The current landscape, J. Biomed. Semant., 8 (2017), 1–18. https://doi.org/10.1186/s13326-017-0153-x doi: 10.1186/s13326-017-0153-x
|
| [5] |
W. Shen, J. Wang, J. Han, Entity linking with a knowledge base: Issues, techniques, and solutions, IEEE Trans. Knowl. Data Eng., 27 (2015), 443–460. https://doi.org/10.1109/TKDE.2014.2327028 doi: 10.1109/TKDE.2014.2327028
|
| [6] | S. Vashishth, R. Joshi, R Dutt, D. Newman-Griffis, C. Rose, MedType: improving medical entity linking with semantic type prediction, Preprint, arXiv: 2005.00460. https://doi.org/10.48550/arXiv.2005.00460 |
| [7] |
H. Li, Q. Chen, B. Tang, X. Wang, H. Xu, B. Wang, et al., CNN-based ranking for biomedical entity normalization, BMC Bioinf., 18 (2017), 385. https://doi.org/10.1186/s12859-017-1805-7 doi: 10.1186/s12859-017-1805-7
|
| [8] | Y. Luo, G. Song, P. Li, Z. Qi, Multi-task medical concept normalization using multi-view convolutional neural network, in Proceedings of the AAAI Conference on Artificial Intelligence, 32 (2018). |
| [9] | I. Mondal, S. Purkayastha, S. Sarkar, P. Goyal, J. Pillai, A. Bhattacharyya, et al., Medical entity linking using triplet network, in Proceedings of the 2nd Clinical Natural Language Processing Workshop, (2019), 95–100. https://doi.org/10.18653/v1/W19-1912 |
| [10] | J. Devlin, M. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, preprint, arXiv: 1810.04805. https://doi.org/10.18653/v1/N19-1423 |
| [11] |
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, et al., BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics, 36 (2020), 1234–1240. https://doi.org/10.1093/bioinformatics/btz682 doi: 10.1093/bioinformatics/btz682
|
| [12] | K. Huang, J. Altosaar, R. Ranganath, ClinicalBERT: Modeling clinical notes and predicting hospital readmission, preprint, arXiv: 1904.05342. https://doi.org/10.48550/arXiv.1904.05342 |
| [13] |
F. Li, Y. Jin, W. Liu, B. P. S. Rawat, P. Cai., H Yu, Fine-tuning bidirectional encoder representations from transformers (BERT)-based models on large-scale electronic health record notes: an empirical study, JMIR Med. Inf., 7 (2019), e14830. https://doi.org/10.2196/14830 doi: 10.2196/14830
|
| [14] |
K. S. Kalyan, S. Sangeetha, BertMCN: Mapping colloquial phrases to standard medical concepts using BERT and highway network, Artif. Intell. Med., 112 (2021), 102008. https://doi.org/10.1016/j.artmed.2021.102008. doi: 10.1016/j.artmed.2021.102008
|
| [15] | M. Sung, H. Jeon, J. Lee, J. Kang, Biomedical entity representations with synonym marginalization, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020. https://doi.org/10.48550/arXiv.2005.00239 |
| [16] |
Y. Xia, H. Zhao, K. Liu, H. Zhu, Normalization of Chinese informal medical terms based on multi-field indexing, Commun. Comput. Inf. Sci., 496 (2014), 311–320. https://doi.org/10.1007/978-3-662-45924-928. doi: 10.1007/978-3-662-45924-928
|
| [17] | Y. Zhang, X. Ma, G. Song, Chinese medical concept normalization by using text and comorbidity network embedding, in 2018 IEEE International Conference on Data Mining (ICDM), (2018), 777–786. https://doi.org/10.1109/ICDM.2018.00093 |
| [18] |
Q. Wang, Z. Ji, J. Wang, S. Wu, W. Lin, W. Li, et al., A study of entity-linking methods for normalizing Chinese diagnosis and procedure terms to ICD codes, J. Biomed. Inf., 105 (2020), 103418. https://doi.org/10.1016/j.jbi.2020.103418 doi: 10.1016/j.jbi.2020.103418
|
| [19] | CHIP 2019, Chinese Information Processing Society of China, 2021. Available from: http://www.cips-chip.org.cn/. |
| [20] | S. E. Robertson, S. Walker, S. Jones, M. Hancock-Beaulieu, M. Gatford, Okapi at TREC-3, in Proceedings of TREC, (1995), 109–126. |
| [21] | Z. Ji, Q. Wei, H. Xu, Bert-based ranking for biomedical entity normalization, preprint, arXiv: 1908.03548. https://doi.org/10.48550/arXiv.1908.03548 |
| [22] | S. Chopra, R. Hadsell, Y. Lecun, Learning a similarity metric discriminatively, with application to face verification, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), 1 (2005), 539–546. https://doi.org/10.1109/CVPR.2005.202 |
| [23] | N. Paul, M. Versteegh, M. Rotaru, Learning text similarity with siamese recurrent networks, in Proceedings of the 1st Workshop on Representation Learning for NLP, (2016), 149–157. https://doi.org/10.18653/v1/W16-1617 |
| [24] | G. Kertész, S. Szénási, Z. Vámossy, Vehicle image matching using siamese neural networks with multi-directional image projections, in 2018 IEEE 12th International Symposium on Applied Computational Intelligence and Informatics (SACI), 2018. https://doi.org/10.1109/SACI.2018.8440917 |
| [25] | S. Fakhraei, J. Mathew, L. A. José, NSEEN: neural semantic embedding for entity normalization, in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, Cham, (2019), 665–680. https://doi.org/10.48550/arXiv.1811.07514 |
| [26] | C. May, A. Wang, S. Bordia, S. R. Bowman, R. Rudinger, On measuring social biases in sentence encoders, preprint, arXiv: 1903.10561. https://doi.org/10.18653/v1/N19-1063 |
| [27] | T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi, BERTScore: Evaluating text generation with BERT, preprint, arXiv.1904.09675. https://doi.org/10.48550/arXiv.1904.09675 |
| [28] | Y. Qiao, C. Xiong, Z. Liu, Z. Liu, Understanding the behaviors of BERT in ranking, preprint, arXiv: 1904.07531. https://doi.org/10.48550/arXiv.1904.07531 |
| [29] | N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, preprint, arXiv: 1908.10084. https://doi.org/10.48550/arXiv.1908.10084 |
| [30] |
L. Shoushan, C. Huang, Chinese sentiment classification based on stacking combination method, J. Chin. Inf. Process., 24 (2010), 56–61. https://doi.org/10.1109/ACCESS.2020.3007889 doi: 10.1109/ACCESS.2020.3007889
|
| [31] | bert-base-chinese, Hugging Face, 2021. Available from: https://huggingface.co/bert-base-chinese/tree/main. |
| [32] | CLUEPretrainedModels, Github, 2021. Available from: https://github.com/CLUEbenchmark/CLUEPretrainedMode-ls. |
| [33] | scikit-learn: Machine Learning in Python, scikit-learn, 2022. Available from: https://scikit-learn.org/stable/. |
| [34] | T. Miyato, A. M. Dai, I. Goodfellow, Adversarial training methods for semi-supervised text classification, preprint, arXiv: 1605.07725. https://doi.org/10.48550/arXiv.1605.07725 |
| [35] | A. Madry, A. Makelov, L. Schmidt, D. Tsipras, A. Vladu, Towards deep learning models resistant to adversarial attacks, preprint, arXiv: 1706.06083. https://doi.org/10.48550/arXiv.1706.06083 |
| [36] | L. Bergroth, H. Hakonen, T. Raita, A survey of longest common subsequence algorithms, in Proceedings Seventh International Symposium on String Processing and Information Retrieval, SPIRE 2000, IEEE, (2000), 39–48. https://doi.org/10.1109/SPIRE.2000.878178 |
| [37] | bert-as-service, Github, 2021. Available from: https://github.com/hanxiao/bert-as-service. |
| [38] | S. Sherazi, J. W. Bae, J. Y. Lee, A soft voting ensemble classifier for early prediction and diagnosis of occurrences of major adverse cardiovascular events for STEMI and NSTEMI during 2-year follow-up in patients with acute coronary syndrome, Plos One, 16 (2021), e0249338. https://doi.org/0.1371/journal.pone.0249338 |





Figures(6) / Tables(7)

Luqi Li, Yunkai Zhai, Jinghong Gao, Linlin Wang, Li Hou, Jie Zhao. Stacking-BERT model for Chinese medical procedure entity normalization[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1018-1036. doi: 10.3934/mbe.2023047







 DownLoad:
DownLoad: