Citation: Mireille Khacho, Ruth S. Slack. Mitochondrial dynamics in neurodegeneration: from cell death to energetic states[J]. AIMS Molecular Science, 2015, 2(2): 161-174. doi: 10.3934/molsci.2015.2.161

| [1] |
Newmeyer DD, Ferguson-Miller S (2003) Mitochondria: releasing power for life and unleashing the machineries of death. Cell 112: 481-490. doi: 10.1016/S0092-8674(03)00116-8

|
| [2] | Attwell D, Laughlin SB (2001) An energy budget for signaling in the grey matter of the brain. J Cereb Blood Flow Metab 21: 1133-1145. |
| [3] | Kann O, Kovács R (2007) Mitochondria and neuronal activity. Am J Physiol Cell Physiol 292: C641-C657. |
| [4] |
Detmer SA, Chan DC (2007) Functions and dysfunctions of mitochondrial dynamics. Nat Rev Mol Cell Biol 8: 870-879. doi: 10.1038/nrm2275
|
| [5] | Chan DC (2006) Mitochondria: dynamic organelles in disease, aging, and development. Cell125: 1241-1252. |
| [6] |
Nunnari J, Suomalainen A (2012) Mitochondria: in sickness and in health. Cell 148: 1145-1159. doi: 10.1016/j.cell.2012.02.035
|
| [7] | Burté F, Carelli V, Chinnery PF, et al. (2015) Disturbed mitochondrial dynamics and neurodegenerative disorders. Nat Rev Neurol 11: 11-24. |
| [8] |
Archer SL (2013) Mitochondrial dynamics--mitochondrial fission and fusion in human diseases. N Engl J Med 369: 2236-2251. doi: 10.1056/NEJMra1215233
|
| [9] |
Itoh K, Nakamura K, Iijima M, et al. (2013) Mitochondrial dynamics in neurodegeneration. Trends Cell Biol 23: 64-71. doi: 10.1016/j.tcb.2012.10.006
|
| [10] |
Benard G, Rossignol R (2008) Ultrastructure of the mitochondrion and its bearing on function and bioenergetics. Antioxid Redox Signal 10: 1313-1342. doi: 10.1089/ars.2007.2000
|
| [11] |
Chan DC (2012) Fusion and fission: interlinked processes critical for mitochondrial health. Annu Rev Genet 46: 265-287. doi: 10.1146/annurev-genet-110410-132529
|
| [12] |
Liesa M, Shirihai OS (2013) Mitochondrial Dynamics in the Regulation of Nutrient Utilization and Energy Expenditure. Cell Metabolism 17: 491-506. doi: 10.1016/j.cmet.2013.03.002
|
| [13] | Khacho M, Tarabay M, Patten D, et al. (2014) Acidosis overrides oxygen deprivation to maintain mitochondrial function and cell survival. Nat Commun 5: 3550. |
| [14] | Stroud DA, Ryan MT (2013) Mitochondria: Organization of Respiratory Chain Complexes Becomes Cristae-lized. CURBIO 23: R969-R971. |
| [15] | Germain M (2015) OPA1 and mitochondrial solute carriers in bioenergetic metabolism. Mol Cell Oncol [in press]. |
| [16] |
Patten DA, Wong J, Khacho M, et al. (2014) OPA1-dependent cristae modulation is essential for cellular adaptation to metabolic demand. EMBO J 33: 2676-2691. doi: 10.15252/embj.201488349
|
| [17] |
Cogliati S, Frezza C, Soriano ME, et al. (2013) Mitochondrial cristae shape determines respiratory chain supercomplexes assembly and respiratory efficiency. Cell 155: 160-171. doi: 10.1016/j.cell.2013.08.032
|
| [18] |
Mannella CA (2006) Structure and dynamics of the mitochondrial inner membrane cristae. Biochimica et Biophysica Acta (BBA). Mol Cell Res 1763: 542-548. doi: 10.1016/j.bbamcr.2006.04.006
|
| [19] |
Song Z, Ghochani M, McCaffery JM, et al. (2009) Mitofusins and OPA1 mediate sequential steps in mitochondrial membrane fusion. Mol Biol Cell 20: 3525-3532. doi: 10.1091/mbc.E09-03-0252
|
| [20] |
Cipolat S, Martins de Brito O, Dal Zilio B, et al. (2004) OPA1 requires mitofusin 1 to promote mitochondrial fusion. Proc Natl Acad Sci USA 101: 15927-15932. doi: 10.1073/pnas.0407043101
|
| [21] |
Chen H, Detmer SA, Ewald AJ, et al. (2003) Mitofusins Mfn1 and Mfn2 coordinately regulate mitochondrial fusion and are essential for embryonic development. J Cell Biol 160: 189-200. doi: 10.1083/jcb.200211046
|
| [22] |
Meeusen S, DeVay R, Block J, et al. (2006) Mitochondrial inner-membrane fusion and crista maintenance requires the dynamin-related GTPase Mgm1. Cell 127: 383-395. doi: 10.1016/j.cell.2006.09.021
|
| [23] |
Frezza C, Cipolat S, Martins de Brito O, et al. (2006) OPA1 controls apoptotic cristae remodeling independently from mitochondrial fusion. Cell 126: 177-189. doi: 10.1016/j.cell.2006.06.025
|
| [24] |
Smirnova E, Griparic L, Shurland DL, et al. (2001) Dynamin-related protein Drp1 is required for mitochondrial division in mammalian cells. Mol Biol Cell 12: 2245-2256. doi: 10.1091/mbc.12.8.2245
|
| [25] |
Losón OC, Song Z, Chen H, et al. (2013) Fis1, Mff, MiD49, and MiD51 mediate Drp1 recruitment in mitochondrial fission. Mol Biol Cell 24: 659-667. doi: 10.1091/mbc.E12-10-0721
|
| [26] |
Li S, Xu S, Roelofs BA, et al. (2015) Transient assembly of F-actin on the outer mitochondrial membrane contributes to mitochondrial fission. J Cell Biol 208: 109-123. doi: 10.1083/jcb.201404050
|
| [27] |
Friedman JR, Lackner LL, West M, et al. (2011) ER tubules mark sites of mitochondrial division. Science 334: 358-362. doi: 10.1126/science.1207385
|
| [28] |
Korobova F, Ramabhadran V, Higgs HN (2013) An actin-dependent step in mitochondrial fission mediated by the ER-associated formin INF2. Science 339: 464-467. doi: 10.1126/science.1228360
|
| [29] |
Gomes LC, Di Benedetto G, Scorrano L (2011) During autophagy mitochondria elongate, are spared from degradation and sustain cell viability. Nat Cell Biol 13: 589-598. doi: 10.1038/ncb2220
|
| [30] |
Tondera D, Grandemange S, Jourdain A, et al. (2009) SLP-2 is required for stress-induced mitochondrial hyperfusion. EMBO J 28: 1589-1600. doi: 10.1038/emboj.2009.89
|
| [31] |
Mannella CA (2006) The relevance of mitochondrial membrane topology to mitochondrial function. Biochim Biophys Acta 1762: 140-147. doi: 10.1016/j.bbadis.2005.07.001
|
| [32] |
Gomes LC, Di Benedetto G, Scorrano L (2011) Essential amino acids and glutamine regulate induction of mitochondrial elongation during autophagy. Cell Cycle 10: 2635-2639. doi: 10.4161/cc.10.16.17002
|
| [33] |
Molina AJA, Wikstrom JD, Stiles L, et al. (2009) Mitochondrial networking protects beta-cells from nutrient-induced apoptosis. Diabetes 58: 2303-2315. doi: 10.2337/db07-1781
|
| [34] | Khacho M, Tarabay M, Patten D, et al. (2014) Acidosis overrides oxygen deprivation to maintain mitochondrial function and cell survival. Nat Commun 5: 3550. |
| [35] |
Kijima K, Numakura C, Izumino H, et al. (2005) Mitochondrial GTPase mitofusin 2 mutation in Charcot-Marie-Tooth neuropathy type 2A. Hum Genet 116: 23-27. doi: 10.1007/s00439-004-1199-2
|
| [36] |
Züchner S, Mersiyanova IV, Muglia M, et al. (2004) Mutations in the mitochondrial GTPase mitofusin 2 cause Charcot-Marie-Tooth neuropathy type 2A. Nat Genet 36: 449-451. doi: 10.1038/ng1341
|
| [37] |
Alexander C, Votruba M, Pesch UE, et al. (2000) OPA1, encoding a dynamin-related GTPase, is mutated in autosomal dominant optic atrophy linked to chromosome 3q28. Nat Genet 26:211-215. doi: 10.1038/79944
|
| [38] |
Delettre C, Lenaers G, Griffoin JM, et al. (2000) Nuclear gene OPA1, encoding a mitochondrial dynamin-related protein, is mutated in dominant optic atrophy. Nat Genet 26: 207-210. doi: 10.1038/79936
|
| [39] |
Knott AB, Perkins G, Schwarzenbacher R, et al. (2008) Mitochondrial fragmentation in neurodegeneration. Nat Rev Neurosci 9: 505-518. doi: 10.1038/nrn2417
|
| [40] |
Cavallucci V, Bisicchia E, Cencioni MT, et al. (2014) Acute focal brain damage alters mitochondrial dynamics and autophagy in axotomized neurons. Cell Death Disease 5: e1545-12. doi: 10.1038/cddis.2014.511
|
| [41] |
Oettinghaus B, Licci M, Scorrano L, et al. (2012) Less than perfect divorces: dysregulated mitochondrial fission and neurodegeneration. Acta Neuropathol 123: 189-203. doi: 10.1007/s00401-011-0930-z
|
| [42] |
Dodson MW, Guo M (2007) Pink1, Parkin, DJ-1 and mitochondrial dysfunction in Parkinson's disease. Curr Opin Neurobiol 17: 331-337. doi: 10.1016/j.conb.2007.04.010
|
| [43] |
Wood-Kaczmar A, Gandhi S, Wood NW (2006) Understanding the molecular causes of Parkinson's disease. Trends Mol Med 12: 521-528. doi: 10.1016/j.molmed.2006.09.007
|
| [44] |
Yang Y, Ouyang Y, Yang L, et al. (2008) Pink1 regulates mitochondrial dynamics through interaction with the fission/fusion machinery. Proc Natl Acad Sci USA 105: 7070-7075. doi: 10.1073/pnas.0711845105
|
| [45] |
Deng H, Dodson MW, Huang H, et al. (2008) The Parkinson's disease genes pink1 and parkin promote mitochondrial fission and/or inhibit fusion in Drosophila. Proc Natl Acad Sci USA 105:14503-14508. doi: 10.1073/pnas.0803998105
|
| [46] |
Poole AC, Thomas RE, Andrews LA, et al. (2008) The PINK1/Parkin pathway regulates mitochondrial morphology. Proc Natl Acad Sci USA 105: 1638-1643. doi: 10.1073/pnas.0709336105
|
| [47] |
Wang H, Song P, Du L, et al. (2011) Parkin ubiquitinates Drp1 for proteasome-dependent degradation: implication of dysregulated mitochondrial dynamics in Parkinson disease. J Biol Chem 286: 11649-11658. doi: 10.1074/jbc.M110.144238
|
| [48] |
Wang X, Yan MH, Fujioka H, et al. (2012) LRRK2 regulates mitochondrial dynamics and function through direct interaction with DLP1. Hum Mol Genet 21: 1931-1944. doi: 10.1093/hmg/dds003
|
| [49] |
Niu J, Yu M, Wang C, et al. (2012) Leucine-rich repeat kinase 2 disturbs mitochondrial dynamics via Dynamin-like protein. J Neurochem 122: 650-658. doi: 10.1111/j.1471-4159.2012.07809.x
|
| [50] |
Wang X, Su B, Lee H-G, et al. (2009) Impaired balance of mitochondrial fission and fusion in Alzheimer's disease. J Neurosci 29: 9090-9103. doi: 10.1523/JNEUROSCI.1357-09.2009
|
| [51] |
Calkins MJ, Manczak M, Mao P, et al. (2011) Impaired mitochondrial biogenesis, defective axonal transport of mitochondria, abnormal mitochondrial dynamics and synaptic degeneration in a mouse model of Alzheimer's disease. Hum Mol Genet 20: 4515-4529. doi: 10.1093/hmg/ddr381
|
| [52] |
Manczak M, Calkins MJ, Reddy PH (2011) Impaired mitochondrial dynamics and abnormal interaction of amyloid beta with mitochondrial protein Drp1 in neurons from patients with Alzheimer's disease: implications for neuronal damage. Hum Mol Genet 20: 2495-2509. doi: 10.1093/hmg/ddr139
|
| [53] |
Bossy-Wetzel E, Petrilli A, Knott AB (2008) Mutant huntingtin and mitochondrial dysfunction. Trends Neurosci 31: 609-616. doi: 10.1016/j.tins.2008.09.004
|
| [54] |
Song W, Chen J, Petrilli A, et al. (2011) Mutant huntingtin binds the mitochondrial fission GTPase dynamin-related protein-1 and increases its enzymatic activity. Nat Med 17: 377-382. doi: 10.1038/nm.2313
|
| [55] |
Jendrach M, Pohl S, Vöth M, et al. (2005) Morpho-dynamic changes of mitochondria during ageing of human endothelial cells. Mech Ageing Dev 126: 813-821. doi: 10.1016/j.mad.2005.03.002
|
| [56] |
Chauhan A, Vera J, Wolkenhauer O (2014) The systems biology of mitochondrial fission and fusion and implications for disease and aging. Biogerontology 15: 1-12. doi: 10.1007/s10522-013-9474-z
|
| [57] |
Scheckhuber CQ, Erjavec N, Tinazli A, et al. (2007) Reducing mitochondrial fission results in increased life span and fitness of two fungal ageing models. Nat Cell Biol 9: 99-105. doi: 10.1038/ncb1524
|
| [58] | Crane JD, Devries MC, Safdar A, et al. (2010) The effect of aging on human skeletal muscle mitochondrial and intramyocellular lipid ultrastructure. J Gerontol A Biol Sci Med Sci 65:119-128. |
| [59] |
Daum B, Walter A, Horst A, et al. (2013) Age-dependent dissociation of ATP synthase dimers and loss of inner-membrane cristae in mitochondria. Proc Natl Acad Sci USA 110:15301-15306. doi: 10.1073/pnas.1305462110
|
| [60] | Stauch KL, Purnell PR, Fox HS (2014) Aging synaptic mitochondria exhibit dynamic proteomic changes while maintaining bioenergetic function. Aging (Albany NY) 6: 320-334. |
| [61] |
Barsoum MJ, Yuan H, Gerencser AA, et al. (2006) Nitric oxide-induced mitochondrial fission is regulated by dynamin-related GTPases in neurons. EMBO J 25: 3900-3911. doi: 10.1038/sj.emboj.7601253
|
| [62] |
Frank S, Gaume B, Bergmann-Leitner ES, et al. (2001) The role of dynamin-related protein 1, a mediator of mitochondrial fission, in apoptosis. Dev Cell 1: 515-525. doi: 10.1016/S1534-5807(01)00055-7
|
| [63] |
Almeida A, Delgado-Esteban M, Bolaños JP, et al. (2002) Oxygen and glucose deprivation induces mitochondrial dysfunction and oxidative stress in neurones but not in astrocytes in primary culture. J Neurochem 81: 207-217. doi: 10.1046/j.1471-4159.2002.00827.x
|
| [64] | Schinder AF, Olson EC, Spitzer NC, et al. (1996) Mitochondrial dysfunction is a primary event in glutamate neurotoxicity. J Neurosci 16: 6125-6133. |
| [65] |
Grohm J, Kim S-W, Mamrak U, et al. (2012) Inhibition of Drp1 provides neuroprotection in vitro and in vivo. Cell Death Differ 19: 1446-1458. doi: 10.1038/cdd.2012.18
|
| [66] |
Jahani-Asl A, Pilon-Larose K, Xu W, et al. (2011) The mitochondrial inner membrane GTPase, optic atrophy 1 (Opa1), restores mitochondrial morphology and promotes neuronal survival following excitotoxicity. J Biol Chem 286: 4772-4782. doi: 10.1074/jbc.M110.167155
|
| [67] |
Jahani-Asl A, Cheung EC, Neuspiel M, MacLaurin JG, Fortin A, et al. (2007) Mitofusin 2 protects cerebellar granule neurons against injury-induced cell death. J Biol Chem 282:23788-23798. doi: 10.1074/jbc.M703812200
|
| [68] |
Zanelli SA, Trimmer PA, Solenski NJ (2006) Nitric oxide impairs mitochondrial movement in cortical neurons during hypoxia. J Neurochem 97: 724-736. doi: 10.1111/j.1471-4159.2006.03767.x
|
| [69] |
Liu X, Hajnoczky G (2011) Altered fusion dynamics underlie unique morphological changes in mitochondria during hypoxia-reoxygenation stress. Cell Death Differ 18: 1561-1572. doi: 10.1038/cdd.2011.13
|
| [70] |
Dagda RK, Cherra SJ, Kulich SM, et al. (2009) Loss of PINK1 function promotes mitophagy through effects on oxidative stress and mitochondrial fission. J Biol Chem 284: 13843-13855. doi: 10.1074/jbc.M808515200
|
| [71] |
Lutz AK, Exner N, Fett ME, et al. (2009) Loss of parkin or PINK1 function increases Drp1-dependent mitochondrial fragmentation. J Biol Chem 284: 22938-22951. doi: 10.1074/jbc.M109.035774
|
| [72] |
Grünewald A, Gegg ME, Taanman J-W, et al. (2009) Differential effects of PINK1 nonsense and missense mutations on mitochondrial function and morphology. Exp Neurol 219: 266-273. doi: 10.1016/j.expneurol.2009.05.027
|
| [73] |
Cui M, Tang X, Christian WV, et al. (2010) Perturbations in mitochondrial dynamics induced by human mutant PINK1 can be rescued by the mitochondrial division inhibitor mdivi-1. J Biol Chem 285: 11740-11752. doi: 10.1074/jbc.M109.066662
|
| [74] |
Rappold PM, Cui M, Grima JC, et al. (2014) Drp1 inhibition attenuates neurotoxicity and dopamine release deficits in vivo. Nat Commun 5: 5244. doi: 10.1038/ncomms6244
|
| [75] |
Su Y-C, Qi X (2013) Inhibition of excessive mitochondrial fission reduced aberrant autophagy and neuronal damage caused by LRRK2 G2019S mutation. Hum Mol Genet 22: 4545-4561. doi: 10.1093/hmg/ddt301
|
| [76] |
Zhang N, Wang S, Li Y, et al. (2013) A selective inhibitor of Drp1, mdivi-1, acts against cerebral ischemia/reperfusion injury via an anti-apoptotic pathway in rats. Neurosci Lett 535:104-109. doi: 10.1016/j.neulet.2012.12.049
|
| [77] | Cui M, Ding H, Chen F, et al. (2014) Mdivi-1 Protects Against Ischemic Brain Injury via Elevating Extracellular Adenosine in a cAMP/CREB-CD39-Dependent Manner. Mol Neurobiol [in press]. |
| [78] |
Zhao Y-X, Cui M, Chen S-F, et al. (2014) Amelioration of ischemic mitochondrial injury and Bax-dependent outer membrane permeabilization by Mdivi-1. CNS Neurosci Ther 20: 528-538. doi: 10.1111/cns.12266
|
| [79] |
Youle RJ, van der Bliek AM (2012) Mitochondrial fission, fusion, and stress. Science 337:1062-1065. doi: 10.1126/science.1219855
|
| [80] |
Ramonet D, Perier C, Recasens A, et al. (2013) Optic atrophy 1 mediates mitochondria remodeling and dopaminergic neurodegeneration linked to complex I deficiency. Cell Death Differ 20: 77-85. doi: 10.1038/cdd.2012.95
|
| [81] |
Cipolat S, Rudka T, Hartmann D, et al. (2006) Mitochondrial rhomboid PARL regulates cytochrome c release during apoptosis via OPA1-dependent cristae remodeling. Cell 126:163-175. doi: 10.1016/j.cell.2006.06.021
|
| [82] |
Germain M, Mathai JP, McBride HM, et al. (2005) Endoplasmic reticulum BIK initiates DRP1-regulated remodelling of mitochondrial cristae during apoptosis. EMBO J 24: 1546-1556. doi: 10.1038/sj.emboj.7600592
|
| [83] |
Montessuit S, Somasekharan SP, Terrones O, et al. (2010) Membrane remodeling induced by the dynamin-related protein Drp1 stimulates Bax oligomerization. Cell 142: 889-901. doi: 10.1016/j.cell.2010.08.017
|
| [84] |
Rambold AS, Kostelecky B, Elia N, et al. (2011) Tubular network formation protects mitochondria from autophagosomal degradation during nutrient starvation. Proc Natl Acad Sci USA 108: 10190-10195. doi: 10.1073/pnas.1107402108
|
| [85] |
Hall CN, Klein-Flügge MC, Howarth C, et al. (2012) Oxidative phosphorylation, not glycolysis, powers presynaptic and postsynaptic mechanisms underlying brain information processing. J Neurosci 32: 8940-8951. doi: 10.1523/JNEUROSCI.0026-12.2012
|
| [86] |
Bolaños JP, Almeida A, Moncada S (2010) Glycolysis: a bioenergetic or a survival pathway? Trends Biochem Sci 35: 145-149. doi: 10.1016/j.tibs.2009.10.006
|
| [87] |
Kasischke KA, Vishwasrao HD, Fisher PJ, et al. (2004) Neural activity triggers neuronal oxidative metabolism followed by astrocytic glycolysis. Science 305: 99-103. doi: 10.1126/science.1096485
|
| [88] |
Vander Heiden MG, Cantley LC, Thompson CB (2009) Understanding the Warburg effect: the metabolic requirements of cell proliferation. Science 324: 1029-1033. doi: 10.1126/science.1160809
|
| [89] | Kroemer G, Pouyssegur J (2008) Tumor cell metabolism: cancer“s Achilles” heel. Cancer Cell13: 472-482. |
| [90] |
Hsu PP, Sabatini DM (2008) Cancer cell metabolism: Warburg and beyond. Cell 134: 703-707. doi: 10.1016/j.cell.2008.08.021
|
| [91] |
Zorzano A, Liesa M, Sebastián D, et al. (2010) Mitochondrial fusion proteins: dual regulators of morphology and metabolism. Semin Cell Dev Biol 21: 566-574. doi: 10.1016/j.semcdb.2010.01.002
|
| [92] |
Amati-Bonneau P, Guichet A, Olichon A, et al. (2005) OPA1 R445H mutation in optic atrophy associated with sensorineural deafness. Ann Neurol 58: 958-963. doi: 10.1002/ana.20681
|
| [93] |
Zanna C, Ghelli A, Porcelli AM, et al. (2008) OPA1 mutations associated with dominant optic atrophy impair oxidative phosphorylation and mitochondrial fusion. Brain 131: 352-367 doi: 10.1093/brain/awm335
|
| [94] |
Pich S, Bach D, Briones P, et al. (2005) The Charcot-Marie-Tooth type 2A gene product, Mfn2, up-regulates fuel oxidation through expression of OXPHOS system. Hum Mol Genet 14:1405-1415. doi: 10.1093/hmg/ddi149
|
| [95] |
Agier V, Oliviero P, Lainé J, et al. (2012) Defective mitochondrial fusion, altered respiratory function, and distorted cristae structure in skin fibroblasts with heterozygous OPA1 mutations. Biochim Biophys Acta 1822: 1570-1580. doi: 10.1016/j.bbadis.2012.07.002
|
| [96] |
Chen H, Vermulst M, Wang YE, et al. (2010) Mitochondrial fusion is required for mtDNA stability in skeletal muscle and tolerance of mtDNA mutations. Cell 141: 280-289. doi: 10.1016/j.cell.2010.02.026
|
| [97] |
Ono T, Isobe K, Nakada K, et al. (2001) Human cells are protected from mitochondrial dysfunction by complementation of DNA products in fused mitochondria. Nat Genet 28:272-275. doi: 10.1038/90116
|
| [98] |
Hackenbrock CR (1968) Chemical and physical fixation of isolated mitochondria in low-energy and high-energy states. Proc Natl Acad Sci USA 61: 598-605. doi: 10.1073/pnas.61.2.598
|
| [99] | Hackenbrock CR (1966) Ultrastructural bases for metabolically linked mechanical activity in mitochondria. I. Reversible ultrastructural changes with change in metabolic steady state in isolated liver mitochondria. J Cell Biol 30: 269-297. |
| [100] | Hackenbrock CR (1968) Ultrastructural bases for metabolically linked mechanical activity in mitochondria. II. Electron transport-linked ultrastructural transformations in mitochondria. J Cell Biol 37: 345-369. |
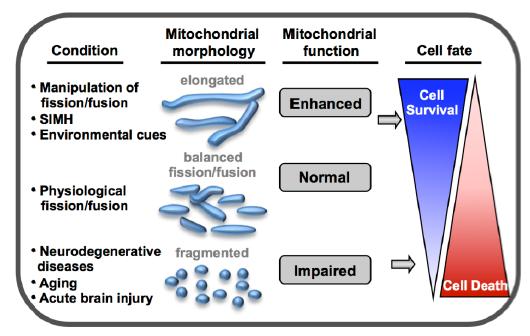
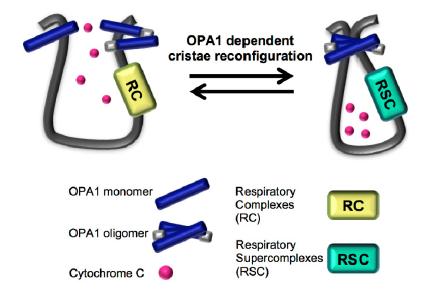
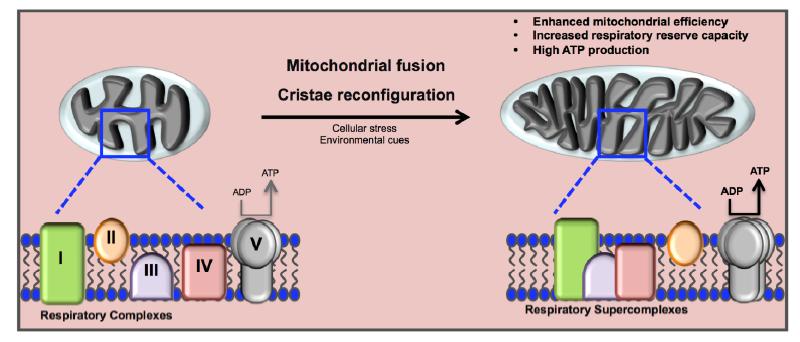
Figures(3)

Mireille Khacho, Ruth S. Slack. Mitochondrial dynamics in neurodegeneration: from cell death to energetic states[J]. AIMS Molecular Science, 2015, 2(2): 161-174. doi: 10.3934/molsci.2015.2.161







 DownLoad:
DownLoad: