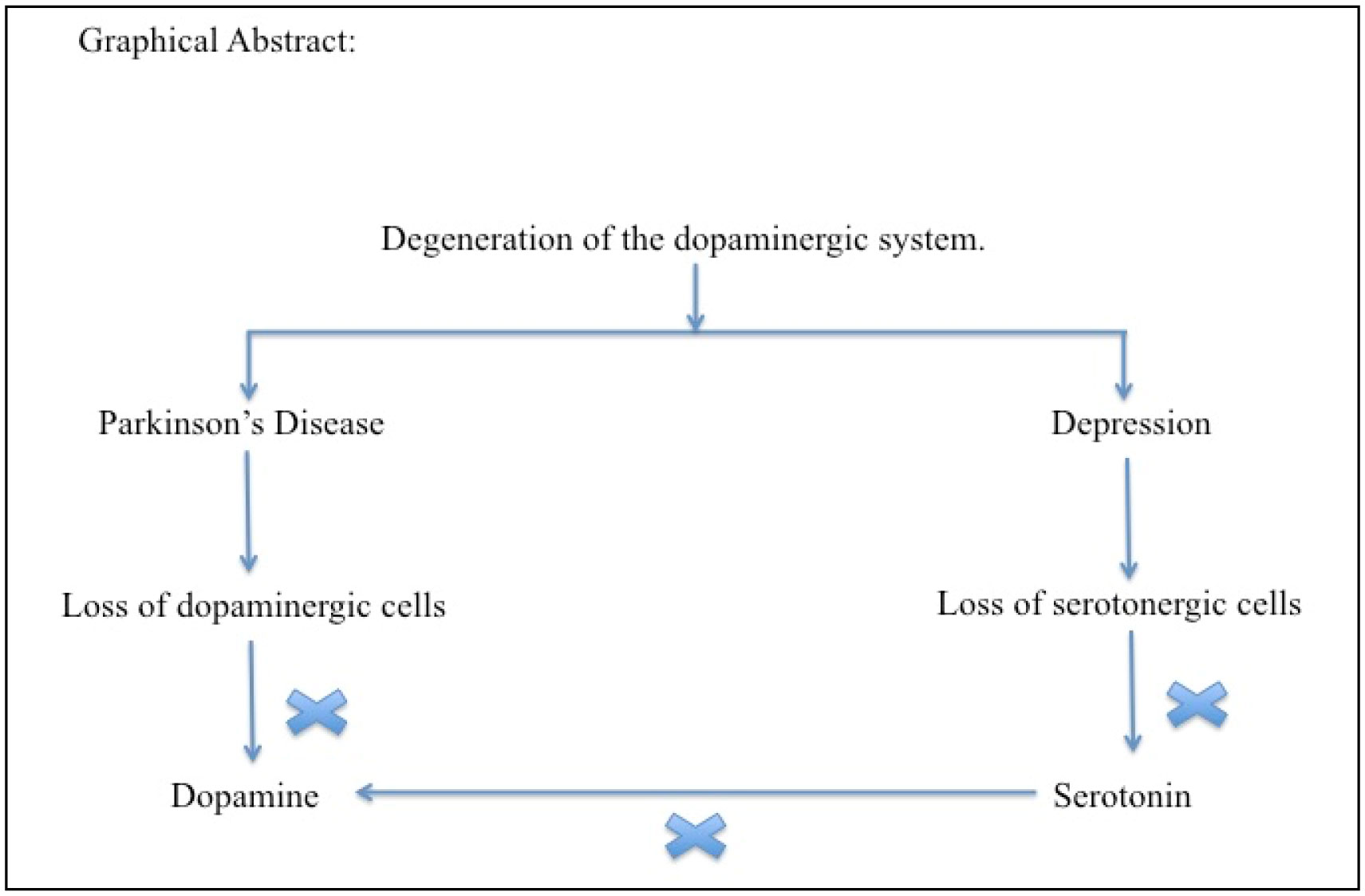
Parkinson's disease (PD) is a neurodegenerative disease, however, besides the motor symptoms, such as rest tremor, hypokinesia, postural instability and rigidity, PD patients have also non-motor symptoms, namely neuropsychiatric disorders. Apart from the required motor symptoms, psychopathological symptoms are very common and include mood disorders, anxiety disorders, hallucinations, psychosis, cognitive deterioration and dementia. The underlying pathophysiological process in PD is mainly due to the loss of dopaminergic neural cells and thereby causes the shortage of nigrostriatal dopamine content in them. In addition, it may involve other neurotransmitter systems such as the noradrenergic, serotonergic, cholinergic and noradrenergic systems as well. Depression can result from any unhealthy conditions making the diagnosis a challenging task. The manifestation of depression associated with or without PD is inadequate. The co-occurrence of depression and PD often leads to the conceptual discussion on whether depressive symptoms appear before or after PD develops. This paper will discuss the conceptual mechanism of PD and depression. Keep in mind both conditions belong to two separate entities but share some similar aspects in their pathophysiology.
Citation: Ashok Chakraborty, Anil Diwan. Depression and Parkinson's disease: a Chicken-Egg story[J]. AIMS Neuroscience, 2022, 9(4): 479-490. doi: 10.3934/Neuroscience.2022027
Parkinson's disease (PD) is a neurodegenerative disease, however, besides the motor symptoms, such as rest tremor, hypokinesia, postural instability and rigidity, PD patients have also non-motor symptoms, namely neuropsychiatric disorders. Apart from the required motor symptoms, psychopathological symptoms are very common and include mood disorders, anxiety disorders, hallucinations, psychosis, cognitive deterioration and dementia. The underlying pathophysiological process in PD is mainly due to the loss of dopaminergic neural cells and thereby causes the shortage of nigrostriatal dopamine content in them. In addition, it may involve other neurotransmitter systems such as the noradrenergic, serotonergic, cholinergic and noradrenergic systems as well. Depression can result from any unhealthy conditions making the diagnosis a challenging task. The manifestation of depression associated with or without PD is inadequate. The co-occurrence of depression and PD often leads to the conceptual discussion on whether depressive symptoms appear before or after PD develops. This paper will discuss the conceptual mechanism of PD and depression. Keep in mind both conditions belong to two separate entities but share some similar aspects in their pathophysiology.

| [1] |
Ray Chaudhuri K, Healy DG, Schapira AHV (2006) Non-motor symptoms of Parkinson's disease: diagnosis and management. Lancet Neurol 5: 235-245. https://doi.org/10.1016/S1474-4422(06)70373-8 
|
| [2] |
Klein C, Westenberger A (2012) Genetics of Parkinson's disease. Cold Spring Harb Perspect Med 2: a008888. https://doi.org/10.1101/cshperspect.a008888
|
| [3] | Parkinson's Disease: Causes, Symptoms, and Treatments. Available from: https://www.nia.nih.gov/health/parkinsons-disease. |
| [4] | World Health OrganizationDepression: Fact Sheet (2017). Available from: http://www.who.int/mediacentre/factsheets/fs369/en. |
| [5] | (2000) American Psychiatric AssociationDiagnostic and statistical manual of mental disorders (DSM-IV-TR). Washington, DC: American Psychiatric Association. https://doi.org/10.1002/9780470479216.corpsy0271 |
| [6] | Hornykiewicz O (1975) Brain monoamines and parkinsonism. Natl Inst Drug Abuse Res 11: 13-21. https://doi.org/10.1037/e472122004-001 |
| [7] | Jellinger K (1986) An overview of morphological changes in Parkinson's disease. Adv Neurol 45: 1-18. |
| [8] |
Hantz P, Cardoc-Davies G, Cardoc-Davies T, et al. (1994) Depression in Parkinson's disease. Am J Psychiatry 151: 1010-1014. https://doi.org/10.1176/ajp.151.7.1010
|
| [9] |
Tandberg E, Larsen JP, Aarsland D, et al. (1996) The occurrence of depression in Parkinson's disease; a community based study. Arch Neurol 53: 175-179. https://doi.org/10.1001/archneur.1996.00550020087019
|
| [10] |
Beekman ATF, Copeland JRM, Prince MJ (1999) Review of community prevalence of depression in later life. Br J Psychiatry 174: 307-311. https://doi.org/10.1192/bjp.174.4.307
|
| [11] |
Reijnders JSAM, Ehrt U, Weber WEJ, et al. (2008) A systematic review of prevalence studies of depression in Parkinson's disease. Movement Disord 23: 183-189. https://doi.org/10.1002/mds.21803
|
| [12] | Mayeux R (1990) The serotonergic hypothesis for depression in Parkinson's disease. Adv Neurol 53: 163-166. |
| [13] |
Van Praag HM, De Haen S (1979) Central serotonergic metabolism and frequency of depression. Psychiatr Res 1: 219-224. https://doi.org/10.1016/0165-1781(79)90002-7
|
| [14] |
Baquero M, Martin N (2015) Depressive symptoms in neurodegenerative diseases. World J Clin Cases 3: 682-693. https://doi.org/10.12998/wjcc.v3.i8.682
|
| [15] |
Hemmerle AM, Herman JP, Seroogy KB (2012) Stress, depression and Parkinson's disease. Exp Neurol 233: 79-86. https://doi.org/10.1016/j.expneurol.2011.09.035
|
| [16] |
Van Praag HM, Asnis GM, Kahn RS (1990) Monoamines and abnormal behaviour: a multi-aminergic perspective. Br J Psychiatry 157: 723-734. https://doi.org/10.1192/bjp.157.5.723
|
| [17] |
Hobson P, Holden A, Meara J (1990) Measuring the impact of Parkinson's disease with the Parkinson's Disease Quality of Life questionnaire. Age Ageing 28: 341-346. https://doi.org/10.1093/ageing/28.4.341
|
| [18] |
Liu CY, Wang SJ, Fuh JL, et al. (1997) The correlation of depression with functional ability in Parkinson's disease. J Neurol 244: 493-498. https://doi.org/10.1007/s004150050131
|
| [19] | (2000) American Psychiatric AssociationPractice guideline for major depressive disorder in adults. American Psychiatric Association practice guidelines for the treatment of psychiatric disorder. Washington, DC: American Psychiatric Association 413-495. |
| [20] |
Fibiger HC (1984) The neurobiological substrates of depression in Parkinson's disease: a hypothesis. Can J Neurol Sci 11: 105-107. https://doi.org/10.1017/S0317167100046230
|
| [21] |
Gonul AS, Aksu M (1999) SSRI-induced parkinsonism may be an early sign of future Parkinson's disease. J Clin Psychiatry 60: 410. https://doi.org/10.4088/JCP.v60n0611d
|
| [22] |
Mayeux R, Stern Y, Cote L, et al. (1984) Altered serotonin metabolism in depressed patients with Parkinson's disease. Neurology 34: 642-646. https://doi.org/10.1212/WNL.34.5.642
|
| [23] |
Schuurman AG, Van den Akker M, Ensinck KTJL, et al. (2002) Increased risk of Parkinson's disease after depression: a retrospective cohort study. Neurology 58: 1501-1504. https://doi.org/10.1212/WNL.58.10.1501
|
| [24] |
Nilsson FM, Kessing LV, Bolwig TG (2001) Increased risk of developing Parkinson's disease for patients with major affective disorder: a register study. Acta Psychiatr Scand 104: 380-386. https://doi.org/10.1034/j.1600-0447.2001.00372.x
|
| [25] |
McEwen BS (2003) Mood disorders and allostatic load. Biol Psychiatry 54: 200-207. https://doi.org/10.1016/S0006-3223(03)00177-X
|
| [26] |
Cole SA, Woodard JL, Juncos JL, et al. (1996) Depression and disability in Parkinson's disease. J Neuropsychiatry Clin Neurosci 8: 20-25. https://doi.org/10.1176/jnp.8.1.20
|
| [27] | Santamaria J, Tolosa ES, Valles A, et al. (1986) Mental depression in untreated Parkinson's disease of recent onset. Adv Neurol 45: 443-446. |
| [28] |
Schrag A, Jahanshahi M, Quinn NP (2001) What contributes to depression in Parkinson's disease?. Psychol Med 31: 65-73. https://doi.org/10.1017/S0033291799003141
|
| [29] |
Starkstein S, Preziosi TJ, Bolduc PL, et al. (1990) Depression in Parkinson's disease. J Nerv Ment Dis 178: 27-31. https://doi.org/10.1097/00005053-199001000-00005
|
| [30] |
Tandberg E, Larsen JP, Aarsland D, et al. (1997) Risk factors for depression in Parkinson's disease. Arch Neurol 54: 625-630. https://doi.org/10.1001/archneur.1997.00550170097020
|
| [31] |
Rektorova I, Rektor I, Bares M, et al. (2003) Pramipexole and per-golide in the treatment of depression in Parkinson's disease: a national multicentre prospective randomized study. Eur J Neurol 10: 399-406. https://doi.org/10.1046/j.1468-1331.2003.00612.x
|
| [32] |
Corrigan MH, Denehan AQ, Wright CE, et al. (2000) Comparison of pramipexole, fluoxetine, and placebo in patients with major depression. Depress Anxiety 11: 58-65. https://doi.org/10.1002/(SICI)1520-6394(2000)11:2<58::AID-DA2>3.0.CO;2-H
|
| [33] |
De Battista C, Solvason HB, Heilig Breen JA, et al. (2000) Pramipexole augmentation of a selective serotonin reuptake inhibitor in the treatment of depression. J Clin Psychopharmacol 20: 274-275. https://doi.org/10.1097/00004714-200004000-00029
|
| [34] |
Mayeux R, Stern Y, Cote L, et al. (1984) Altered serotonin metabolism in depressed patients with Parkinson's disease. Neurology 34: 642-646. https://doi.org/10.1212/WNL.34.5.642
|
| [35] |
Kitada T, Asakawa S, Hattori N, et al. (1998) Mutations in the parkin gene cause autosomal recessive juvenile parkinsonism. Nature 392: 605-8. https://doi.org/10.1038/33416
|
| [36] |
D'Souza T, Rajkumar A (2020) Systematic review of genetic variants associated with cognitive impairment and depressive symptoms in Parkinson's disease. Acta Neuropsychiatrica 32: 10-22. https://doi.org/10.1017/neu.2019.28
|
| [37] |
Jo S, Kim SO, Park KW, et al. (2021) The role of APOE in cognitive trajectories and motor decline in Parkinson's disease. Sci Rep 11: 7819. https://doi.org/10.1038/s41598-021-86483-w
|
| [38] |
Herbert J, Ban M, Brown GW, et al. (2012) Interaction between the BDNF gene Val/66/Met polymorphism and morning cortisol levels as a predictor of depression in adult women. Br J Psychiatry 201: 313-9. https://doi.org/10.1192/bjp.bp.111.107037
|
| [39] | Chakraborty A, Diwan A (2022) A genetic abnormalities behind the PD, and its therapeutic intervention. Neurol Curr Res 2: 1012. |
| [40] |
Levinson DF (2006) The Genetics of Depression: A Review. Biol Psychiat 60: 84-92. https://doi.org/10.1016/j.biopsych.2005.08.024
|
| [41] |
Sia M-W, Foo J-N, Saffari S-E, et al. (2021) Polygenic Risk Scores in a Prospective Parkinson's Disease Cohort. Movement Disord 36: 2936-2940. https://doi.org/10.1002/mds.28761
|
| [42] | Maria S, Bondarenko EA, Slominsky PA (2018) Genetics factors in major depression disease. Front Psychiatry 9: 334. https://doi.org/10.3389/fpsyt.2018.00334 |
| [43] |
Pezzoli G, Cereda E (2013) Exposure to pesticides or solvents and risk of Parkinson disease. Neurology 80: 2035. https://doi.org/10.1212/WNL.0b013e318294b3c8
|
| [44] | Gamache P-L, Roux-Dubois N, Provencher P, et al. (2017) Professional exposure to pesticides and heavy metals hastens Parkinson Disease onset (P6.008). Neurology 88: P6.008. |
| [45] |
Elbaz A, Clavel J, Rathouz PJ, et al. (2009) Professional exposure to pesticides and Parkinson disease. Ann Neurol 66: 494-504. https://doi.org/10.1002/ana.21717
|
| [46] |
Pouchieu C, Piel C, Carles C, et al. (2018) Pesticide use in agriculture and Parkinson's disease in the AGRICAN cohort study. Int J Epidemiol 47: 299-310. https://doi.org/10.1093/ije/dyx225
|
| [47] |
Castillo S, Muñoz P, Behrens MI, et al. (2017) On the role of mining exposure in epigenetic effects in Parkinson's disease. Neurotox Res 32: 172-4. https://doi.org/10.1007/s12640-017-9736-7
|
| [48] |
Willis AW, Evanoff BA, Lian M, et al. (2010) Metal emissions and urban incident Parkinson disease: a community health study of medicare beneficiaries by using geographic information systems. Am J Epidemiol 172: 1357-63. https://doi.org/10.1093/aje/kwq303
|
| [49] |
Palacios N (2017) Air pollution and Parkinson's disease – evidence and future directions. Rev Environ Health 32: 303-13. https://doi.org/10.1515/reveh-2017-0009
|
| [50] |
Ritz B, Lee P-C, Hansen J, et al. (2016) Traffic-related air pollution and Parkinson's disease in Denmark: a case–control study. Environ Health Perspect 124: 351-6. https://doi.org/10.1289/ehp.1409313
|
| [51] |
Finkelstein MM, Jerrett M (2007) A study of the relationships between Parkinson's disease and markers of traffic-derived and environmental manganese air pollution in two Canadian cities. Environ Res 104: 420-32. https://doi.org/10.1016/j.envres.2007.03.002
|
| [52] |
Todd G, Pearson-Dennett V, Wilcox RA, et al. (2016) Adults with a history of illicit amphetamine use exhibit abnormal substantia nigra morphology and parkinsonism. Parkinsonism Relat Disord 25: 27-32. https://doi.org/10.1016/j.parkreldis.2016.02.019
|
| [53] |
Todd G, Noyes C, Flavel SC, et al. (2013) Illicit stimulant use is associated with abnormal substantia nigra morphology in humans. PLoS ONE 8: e56438. https://doi.org/10.1371/journal.pone.0056438
|
| [54] |
Mursaleen LR, Stamford JA (2016) Drugs of abuse and Parkinson's disease. Prog Neuropsychopharmacol Biol Psychiatry 64: 209-17. https://doi.org/10.1016/j.pnpbp.2015.03.013
|
| [55] |
Remes O, Mendes JF, Templeton P (2021) Biological, Psychological, and Social Determinants of Depression: A Review of Recent Literature. Brain Sci 11: 1633. https://doi.org/10.3390/brainsci11121633
|
| [56] |
Schrempft S, Jackowska M, Hamer M, et al. (2019) Associations between social isolation, loneliness, and objective physical activity in older men and women. BMC Public Health 19: 74. https://doi.org/10.1186/s12889-019-6424-y
|
| [57] | Depression. Parkinson's Foundation. Available from: https://www.parkinson.org›non-movement-symptoms |
| [58] |
Ishihara L, Brayne C (2006) A systematic review of depression and mental illness preceding Parkinson's disease. Acta Neurol Scand 113: 211-20. https://doi.org/10.1111/j.1600-0404.2006.00579.x
|
| [59] | NIH: National Institute of Mental HealthDepression. Available from: https://www.nimh.nih.gov/health/publications/depression |
| [60] | Parkinson's FoundationDepression. https://www.parkinson.org/understanding-parkinsons/symptoms/non-movement-symptoms/depression |
| [61] |
Leentjens AF, Van den Akker M, Metsemakers JF, et al. (2003) Higher incidence of depression preceding the onset of Parkinson's disease: a register study. Mov Disord 18: 414-8. https://doi.org/10.1002/mds.10387
|
| [62] |
Looi JC, Matis M, Ruzich MJ (2005) Conceptualization of depression in Parkinson's disease. Neuropsychiatr Dis Treat 1: 135-43. https://doi.org/10.2147/nedt.1.2.135.61051
|
| [63] | Anand A, Charney DS (2000) Norepinephrine dysfunction in depression. J Clin Psychiatry 61: 16-24. |
| [64] | American Parkinson Disease AssociationDepression in Parkinson's. Available from: https://www.apdaparkinson.org/what-is parkinsons/symptoms/depression/ |
| [65] | American Parkinson Disease AssociationDepression and Parkinson's disease. Available from: https://d2icp22po6iej.cloudfront.net/wp-content/uploads/2017/02/APDA1709-Supplement-Depression-D4V1.pdf |
| [66] |
Marsh L (2013) Depression and Parkinson's disease: current knowledge. Curr Neurol Neurosci Rep 13: 409. https://doi.org/10.1007/s11910-013-0409-5
|
| [67] | Michael J Fox Foundation for Parkinson's Research. Depression and Anxiety. Available from: https://www.michaeljfox.org/news/depression-anxiety |
| [68] | Parkinson's FoundationDepression. Available from: https://www.parkinson.org/Understanding-Parkinsons/Symptoms/Non-Movement-Symptoms/Depression |
| [69] | Mayeux R, Stern Y, Williams JBW, et al. (1986) Clinical and biochemical features of depression in Parkinson's disease. Am J Psychiatry 43: 756-9. https://doi.org/10.1176/ajp.143.6.756 |
| [70] |
Kostic VS, Djuricic BM, Covickovic-Sternic N, et al. (1987) Depression and Parkinson's disease: possible role of serotonergic mechanisms. J Neurol 234: 94-96. https://doi.org/10.1007/BF00314109
|
| [71] | Placebo study.Imipramine in Treatment of Parkinsonism: a Double-blind Placebo Study. Br BMJ (1965) 2: 33-34. https://doi.org/10.1136/bmj.2.5452.33 |
| [72] |
Laitinen L (1969) Desipramine in treatment of Parkinson's disease. Acta Neurol Scand 45: 109-113. https://doi.org/10.1111/j.1600-0404.1969.tb01224.x
|
| [73] |
Anderson J, Aabro E, Gulmann N, et al. (1980) Anti-depressive treatment in Parkinson's disease: a controlled trial of the effect of nortriptyline in patients with Parkinson's disease treated with L-dopa. Acta Neurol Scand 62: 210-19. https://doi.org/10.1111/j.1600-0404.1980.tb03028.x
|
| [74] |
Goetz CG, Tanner CM, Klawans HL (1984) Bupropion in Parkinson's disease. Neurology 34: 1092-1094. https://doi.org/10.1212/WNL.34.8.1092
|
| [75] |
Klaassen T, Verhey FRJ, Sneijders GHJ, et al. (1995) Treatment of depression in Parkinson's disease: a meta-analysis. J Neuropsychiatry Clin Neurosci 7: 281-286. https://doi.org/10.1176/jnp.7.3.281
|
Figures(1) / Tables(3)

Ashok Chakraborty, Anil Diwan. Depression and Parkinson's disease: a Chicken-Egg story[J]. AIMS Neuroscience, 2022, 9(4): 479-490. doi: 10.3934/Neuroscience.2022027







 DownLoad:
DownLoad: