The novel Coronavirus (COVID-19) is spreading and has caused a large-scale infection in China since December 2019. This has led to a significant impact on the lives and economy in China and other countries. Here we develop a discrete-time stochastic epidemic model with binomial distributions to study the transmission of the disease. Model parameters are estimated on the basis of fitting to newly reported data from January 11 to February 13, 2020 in China. The estimates of the contact rate and the effective reproductive number support the efficiency of the control measures that have been implemented so far. Simulations show the newly confirmed cases will continue to decline and the total confirmed cases will reach the peak around the end of February of 2020 under the current control measures. The impact of the timing of returning to work is also evaluated on the disease transmission given different strength of protection and control measures.
Citation: Sha He, Sanyi Tang, Libin Rong. A discrete stochastic model of the COVID-19 outbreak: Forecast and control[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 2792-2804. doi: 10.3934/mbe.2020153
The novel Coronavirus (COVID-19) is spreading and has caused a large-scale infection in China since December 2019. This has led to a significant impact on the lives and economy in China and other countries. Here we develop a discrete-time stochastic epidemic model with binomial distributions to study the transmission of the disease. Model parameters are estimated on the basis of fitting to newly reported data from January 11 to February 13, 2020 in China. The estimates of the contact rate and the effective reproductive number support the efficiency of the control measures that have been implemented so far. Simulations show the newly confirmed cases will continue to decline and the total confirmed cases will reach the peak around the end of February of 2020 under the current control measures. The impact of the timing of returning to work is also evaluated on the disease transmission given different strength of protection and control measures.

| [1] | World Health Organization (WHO). Coronavirus. Available from: https://www.who.int/health-topics/coronavirus (accessed on January 23, 2020). |
| [2] | Wuhan Municipal Health Commission. Available from: http://wjw.wuhan.gov.cn/front/web/showDetail/2019123108989 (accessed on December 31, 2019). |
| [3] | World Health Organization (WHO). Disease Outbreak News. Available from: https://www.who.int/csr/don/archive/disease/novelcoronavirus/en/ (accessed on January 14, 2020). |
| [4] | World Health Organization (WHO). Situation reports. Available from: http://who.maps.arcgis.com/apps/opsdashboard/index.html#/c88e37cfc43b4ed3baf977d77e4a0667 (accessed on January 23, 2020). |
| [5] | National Health Commission of the People's Republic of China. Available from: http://www.nhc.gov.cn/xcs/xxgzbd/gzbdindex.shtml (accessed on February 14, 2020). |
| [6] |
Y. Zhou, Z. Ma, F. Brauer, A Discrete Epidemic Model for SARS Transmission and Control in China, Math. Comput. Model., 40 (2004), 1491-1506. doi: 10.1016/j.mcm.2005.01.007

|
| [7] |
G. Chowell, C. Castillo-Chavez, P. Fenimore, M. Christopher, C. Kribs-Zaleta, L. Arriola, et al., Model Parameters and Outbreak Control for SARS, Emerg. Infect. Dis., 10 (2004), 1258-1263. doi: 10.3201/eid1007.030647
|
| [8] |
P. Lekone, B. Finkenstädt, Statistical Inference in a Stochastic Epidemic SEIR Model with Control Intervention: Ebola as a Case Study, Biometrics, 62 (2006), 1170-1177. doi: 10.1111/j.1541-0420.2006.00609.x
|
| [9] | J. Wu, K. Leung, G. Leung, Nowcasting and forecasting the potential domestic and international spread of the 2019-nCoV outbreak originating in Wuhan, China: a modelling study, Lancet (2020). |
| [10] |
S. Zhao, S. Musa, Q. Lin, J. Ran, G. Yang, W. Wang, et al., Estimating the unreported number of novel coronavirus (2019-nCoV) vases in China in the first half of January 2020: a data-driven modelling analysis of the early outbreak, J. Clin. Med., 9 (2020), 388. doi: 10.3390/jcm9020388
|
| [11] | B. Prasse, M. Achterberg, L. Ma, P. Mieghem, Network-Based Prediction of the 2019-nCoV Epidemic Outbreak in the Chinese Province Hubei, arXiv preprint arXiv (2002), 2002.04482. |
| [12] | C. Anastassopoulou, L. Russo, A. Tsakris, C. Siettos, Data-Based Analysis, Modelling and Forecasting of the novel Coronavirus (2019-nCoV) outbreak, medRxiv (2020). |
| [13] | Y. Yang, Q. Lu, M. Liu, Y. Wang, A. Zhang, N. Jalali, et al., Epidemiological and clinical features of the 2019 novel coronavirus outbreak in China, medRxiv (2020). |
| [14] | C. You, Y. Deng, W. Hu, J. Sun, Q. Lin, F. Zhou, et al., Estimation of the Time-Varying Reproduction Number of COVID-19 Outbreak in China, medRxiv (2020). |
| [15] | S. Hermanowicz, Forecasting the Wuhan coronavirus (2019-nCoV) epidemics using a simple (simplistic) model, medRxiv (2020). |
| [16] | K. Mizumoto, K. Kagaga, G. Chowell, Early epidemiological assessment of the transmission potential and virulence of 2019 Novel Coronavirus in Wuhan City: China, 20192020. medRxiv (2020). |
| [17] |
B. Tang, X. Wang, Q. Li, N. L. Bragazzi, S. Tang, Y. Xiao, et al., Estimation of the transmission risk of the 2019-nCoV and its implication for public health interventions, J. Clin. Med., 9 (2020), 462. doi: 10.3390/jcm9020462
|
| [18] |
B. Tang, N. Bragazzi, Q. Li, S. Tang, Y. Xiao, J. Wu, An updated estimation of the risk of transmission of the novel coronavirus (2019-nCov), Infect. Disease Model., 5 (2020), 248-255. doi: 10.1016/j.idm.2020.02.001
|
| [19] | Health Commission of Hubei Province. Available from: http://wjw.hubei.gov.cn/bmdt/ztzl/fkxxgzbdgr f yyq/ (accessed on February 15, 2020). |
| [20] |
L. Bettencourt, R. Ribeiro, Real Time Bayesian Estimation of the Epidemic Potential of Emerging Infectious Diseases, PLoS One, 3 (2008), e2185. doi: 10.1371/journal.pone.0002185
|
| [21] |
A. Morton, B. Finkenstädt, Discrete time modelling of disease incidence time series by using Markov chain Monte Carlo methods, J. R. Stat. Soc., 54 (2005), 575-594. doi: 10.1111/j.1467-9876.2005.05366.x
|
| [22] |
S. Tang, Y. Xiao, Y. Yang, Y. zhou, J. Wu, Z. Ma, Community-based measures for mitigating the 2009 H1N1 pandemic in China, PLoS One, 5 (2010), e10911. doi: 10.1371/journal.pone.0010911
|
| [23] | World Health Organization (WHO). Available from: https://www.who.int/news-room/detail/23-01-2020-statement-on-the-meeting-of-the-international-health-regulations-(2005)-emergency-committee-regarding-the-outbreak-of-novel-coronavirus-(2019-ncov) (accessed on January 23, 2020). |
| [24] |
G. Chowell, N. Hengartner, C. Castillo-Chavez, P. Fenimore, J. Hyman, The basic reproductive number of Ebola and the effects of public health measures: the cases of Congo and Uganda, J. Theor. Biol., 229 (2004), 119-126. doi: 10.1016/j.jtbi.2004.03.006
|
| [25] |
C. Favier, N. Degallier, M. Rosa-Freitas, J. Boulanger, J. R. Costa Lima, J. Luitgards-Moura, et al., Early determination of the reproductive number for vector-borne diseases: the case of dengue in Brazil, Trop. Med. Int. Health., 11 (2006), 332-340. doi: 10.1111/j.1365-3156.2006.01560.x
|
| [26] | C. Althaus, Estimating the Reproduction Number of Ebola Virus (EBOV) During the 2014 Outbreak in West Africa, PLoS Curr., 6 (2014). |
| [27] |
G. Chowell, H. Nishiura, L. Bettencourt, Comparative estimation of the reproduction number for pandemic influenza from daily case notification data, J. R. Soc. Interface., 4 (2007), 155-166. doi: 10.1098/rsif.2006.0161
|
| [28] | S. Paine, G. Mercer, P. Kelly, D. Bandaranayake, M. Baker, W. Huang, et al., Transmissibility of 2009 pandemic influenza A(H1N1) in New Zealand: effective reproduction number and influence of age, ethnicity and importations, Euro. Surveill., 15 (2010), pii = 19591. |
| [29] | S. Park, B. Bolker, D. Champredon, D. Earn, M. Li, J. Weitz, et al., Reconciling early-outbreak estimates of the basic reproductive number and its uncertainty: framework and applications to the novel coronavirus (2019-nCoV) outbreak, medRxiv (2020). |
| [30] | A. Kucharski, T. Russell, C. Diamond, Y. Liu, J. Edmunds, S. Funk, et al., Early dynamics of transmission and control of COVID-19: a mathematical modelling study, medRxiv (2020). |
| [31] | Y. Liu, A. Gayle, A. Wilder-Smith, J. Rocklöv, The reproductive number of COVID-19 is higher compared to SARS coronavirus, J. Travel. Med., (2020), 1-4. |
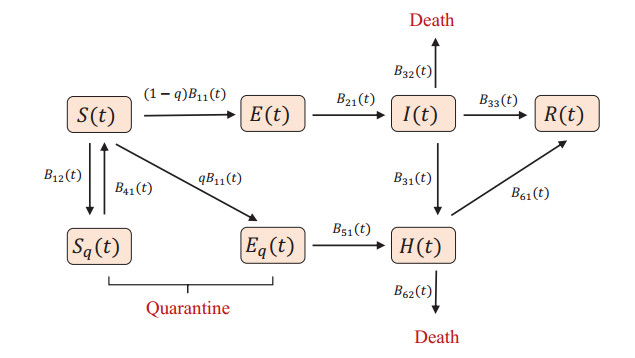
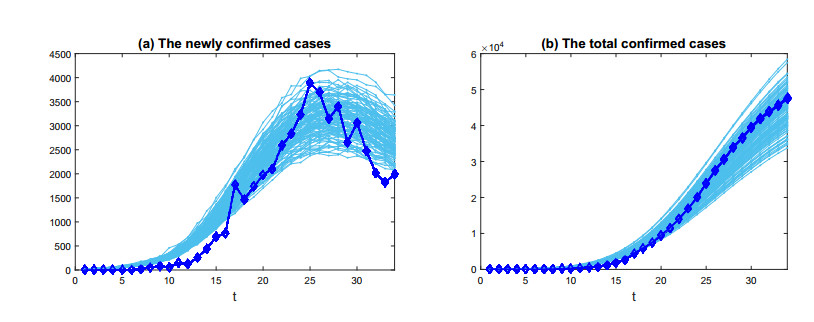
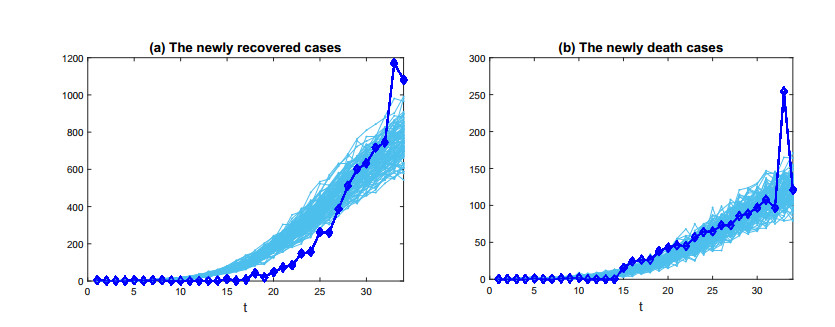

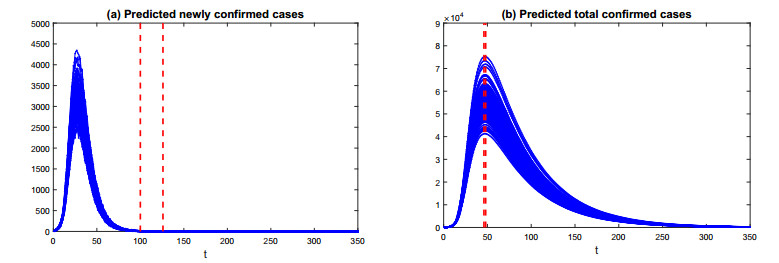
Figures(6) / Tables(1)

Sha He, Sanyi Tang, Libin Rong. A discrete stochastic model of the COVID-19 outbreak: Forecast and control[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 2792-2804. doi: 10.3934/mbe.2020153







 DownLoad:
DownLoad: