Citation: Jinhua Zou, Yonghui Huang, Wenxian Feng, Yanhua Chen, Yue Huang. Experimental study on flexural behavior of concrete T-beams strengthened with externally prestressed tendons[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6962-6974. doi: 10.3934/mbe.2019349

| [1] | A. Naaman and J. Breen, External prestressing in bridges. SP-120, American Concrete Institute. Farmington Hills, MI, (1990). |
| [2] | A. Picard, B. Massicotte and J. Bastien, Relative efficiency of external prestressing, J. Struct. Eng., 121 (1995), 1832–1841. |
| [3] | N. Hakan, Strengthening structures with externally prestressed tendons-literature review, technical report, Lulea University of Technology, (2005). |
| [4] | H. B. Jiang, Q. Cao, A. R. Liu, et al., Flexural behavior of precast concrete segmental beams with hybrid, Constr. Build. Mater., 110 (2016), 1–7. |
| [5] | H. B. Jiang, Y. H. Li, A. R. Liu, et al., Shear behavior of precast concrete segmental beams with external tendons, J. Bridge Eng., 23 (2018), 04018049. |
| [6] | R. A. Hawileh, H. A. Rasheed, J. A. Abdalla, et al., Behavior of reinforced concrete beams strengthened with externally bonded hybrid fiber reinforced polymer systems, Mater. Design., 53 (2014), 972–982. |
| [7] | R. A. Hawileh, M. Z. Naser and J. A. Abdalla, Finite element simulation of reinforced concrete beams externally strengthened with short-length CFRP plates, Compos. Part B-Eng., 45 (2013), 1722–1730. |
| [8] | R. A. Hawileh, W. Nawaz and J. A. Abdalla, Flexural behavior of reinforced concrete beams externally strengthened with Hardwire Steel-Fiber sheets, Constr. Build. Mater., 172 (2018), 562–573. |
| [9] | F. M. Alkhairi and A. E. Naaman, Analysis of beams prestressed with unbonded internal or external tendons, J. Struct. Eng., 119 (1993), 2681–2700. |
| [10] | P. S. Rao and G. Mathew, Behavior of externally prestressed concrete beams with multiple deviators, ACI Struct. J., 93 (1996), 387–396. |
| [11] | T. J. Lou and Y. Q. Xiang, finite element modeling of concrete beams prestressed with external tendons. Eng. Struct., 28 (2006), 1919–1926. |
| [12] | B. K. Diep, H. Umehara and T. A. Tanabe, Numerical analysis of externally presressed concrete beams considering friction at deviators, J. Materials. Conc. Struct. Pavements, JSCE., 718 (2002), 107–119. |
| [13] | A. Zona, L. Ragni and A. Dall'Asta, Finite element formulation for geometric and material nonlinear analysis of beams prestressed with external slipping tendons, Finite Elem. Anal. Des., 44 (2008), 910–919. |
| [14] | A. R. C. Murthy, S. C. Ganapathi, S. Saibabu, et al., Numerical simulation of an external prestressing technique for prestressed concrete end block, Struct. Eng. Mech., 33 (2009), 605–619. |
| [15] | Z. C. Yang, Y. H. Huang, A. R. Liu, et al., Nonlinear in-plane buckling of fixed shallow functionally graded grapheme reinforced composite arches subjected to mechanical and thermal loading, Appl. Math. Model., 70 (2019), 315–327. |
| [16] | R. Z. Ai-Rousan, Shear behavior of RC beams externally strengthened and anchored with CFRP composites, Struct. Eng. Mech., 63 (2017), 447–456. |
| [17] | K. Tan and C. K. Ng, Effects of deviators and tendon configuration on behaviour of externally prestressed beams, ACI Struct. J., 94 (1997), 13–22. |
| [18] | M. Harajli, N. Khairallah and H. Nassif, Externally prestressed members: evaluation of second-order effects, J. Struct. Eng., 125 (1999), 1151–1161. |
| [19] | S. Matupayont, H. Mutsuyoshi, K. Tsuchida, et al., Loss of tendon's eccentricity in externally prestressed concrete beam, Transactions of the Japan Concrete Institute, 16 (1994), 1–7. |
| [20] | H. Mutsuyoshi, K. Tsuchida, A. Machida, et al., Flexural behavior and proposal of design equation for flexural strength of externally PC members journal of materials, concrete structures, and pavements, Japan Soc. Civil Eng., 508 (1995), 67–76. |
| [21] | J. L. Trinh, Structural strengthening by external prestressing, Proceedings, U.S.-European Workshop on Bridge Evaluation, Repair, and Rehabilitation, Maryland, Kluwer Academic Publishers, (1990), 513–523. |
| [22] | S. J. Kwon, K. H. Yang and J. H. Mun, Flexural tests on externally post-tensioned lightweight concrete beams, Eng. Struct., 164 (2018), 128–140. |
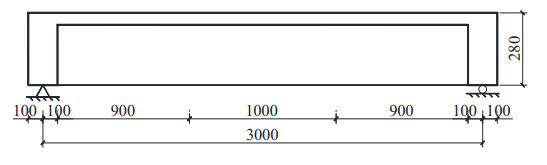
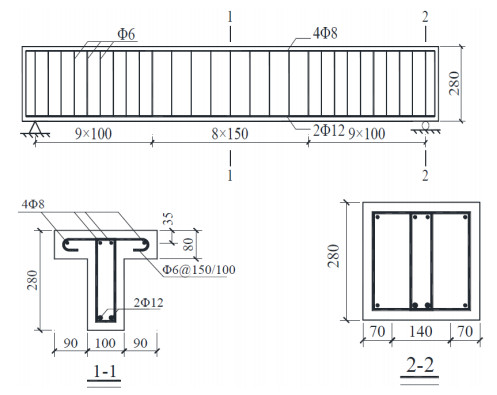
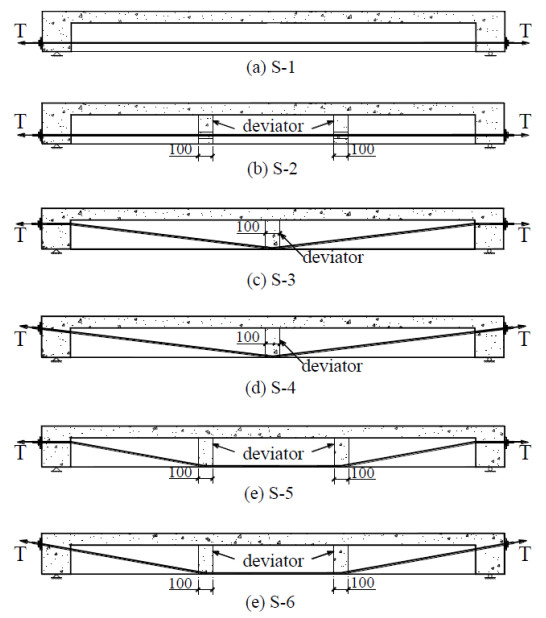



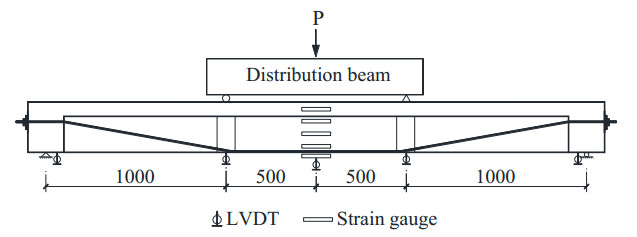


Figures(11) / Tables(4)

Jinhua Zou, Yonghui Huang, Wenxian Feng, Yanhua Chen, Yue Huang. Experimental study on flexural behavior of concrete T-beams strengthened with externally prestressed tendons[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6962-6974. doi: 10.3934/mbe.2019349







 DownLoad:
DownLoad: