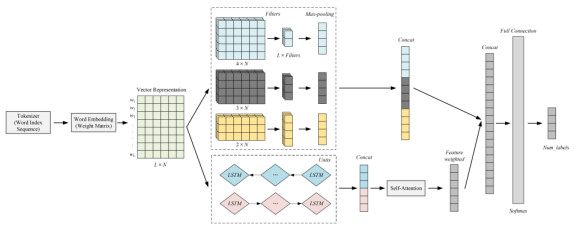
Text classification is a fundamental task in natural language processing. The Chinese text classification task suffers from sparse text features, ambiguity in word segmentation, and poor performance of classification models. A text classification model is proposed based on the self-attention mechanism combined with CNN and LSTM. The proposed model uses word vectors as input to a dual-channel neural network structure, using multiple CNNs to extract the N-Gram information of different word windows and enrich the local feature representation through the concatenation operation, the BiLSTM is used to extract the semantic association information of the context to obtain the high-level feature representation at the sentence level. The output of BiLSTM is feature weighted with self-attention to reduce the influence of noisy features. The outputs of the dual channels are concatenated and fed into the softmax layer for classification. The results of the multiple comparison experiments showed that the DCCL model obtained 90.07% and 96.26% F1-score on the Sougou and THUNews datasets, respectively. Compared to the baseline model, the improvement was 3.24% and 2.19%, respectively. The proposed DCCL model can alleviate the problem of CNN losing word order information and the gradient of BiLSTM when processing text sequences, effectively integrate local and global text features, and highlight key information. The classification performance of the DCCL model is excellent and suitable for text classification tasks.
Citation: Chaofan Li, Qiong Liu, Kai Ma. DCCL: Dual-channel hybrid neural network combined with self-attention for text classification[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1981-1992. doi: 10.3934/mbe.2023091
Text classification is a fundamental task in natural language processing. The Chinese text classification task suffers from sparse text features, ambiguity in word segmentation, and poor performance of classification models. A text classification model is proposed based on the self-attention mechanism combined with CNN and LSTM. The proposed model uses word vectors as input to a dual-channel neural network structure, using multiple CNNs to extract the N-Gram information of different word windows and enrich the local feature representation through the concatenation operation, the BiLSTM is used to extract the semantic association information of the context to obtain the high-level feature representation at the sentence level. The output of BiLSTM is feature weighted with self-attention to reduce the influence of noisy features. The outputs of the dual channels are concatenated and fed into the softmax layer for classification. The results of the multiple comparison experiments showed that the DCCL model obtained 90.07% and 96.26% F1-score on the Sougou and THUNews datasets, respectively. Compared to the baseline model, the improvement was 3.24% and 2.19%, respectively. The proposed DCCL model can alleviate the problem of CNN losing word order information and the gradient of BiLSTM when processing text sequences, effectively integrate local and global text features, and highlight key information. The classification performance of the DCCL model is excellent and suitable for text classification tasks.

| [1] |
S. Al, S. Andrew, Short text classification using contextual analysis, IEEE Access, 9 (2021), 149619–149629. https://doi.org/10.1109/ACCESS.2021.3125768 doi: 10.1109/ACCESS.2021.3125768

|
| [2] | X. Zhang, J. B. Zhao, L. C. Yann, Character-level convolutional networks for text classification, Adv. Neural. Inf. Process. Syst., 28 (2015), 649–657. |
| [3] |
Y. Lin, J. P. Li, L. Yang, K. Xu, H. F. Lin, Sentiment analysis with comparison enhanced deep neural network, IEEE Access, 8 (2020), 78378–78384. https://doi.org/10.1109/ACCESS.2020.2989424 doi: 10.1109/ACCESS.2020.2989424
|
| [4] |
R. Sharma, M. Kim, A. Gupta, Motor imagery classification in brain-machine interface with machine learning algorithms: Classical approach to multi-layer perceptron model, Biomed. Signal Process. Control, 71 (2022). https://doi.org/10.1016/j.bspc.2021.103101 doi: 10.1016/j.bspc.2021.103101
|
| [5] |
D. Kapgate, Efficient quadcopter flight control using hybrid SSVEP+P300 visual brain computer interface, Int. J. Human-Comput. Interact., 38 (2021), 42–52. https://doi.org/10.1080/10447318.2021.1921482 doi: 10.1080/10447318.2021.1921482
|
| [6] | A. M. Roy, A multi-scale fusion CNN model based on adaptive transfer learning for multi-class MI-classification in BCI system, (2022). https://doi.org/10.1101/2022.03.17.481909 |
| [7] |
K. Shah, H. Patel, D. Sanghvi, M. Shah, A comparative analysis of logistic regression, random forest and knn models for the text classification, Augm. Human Res., 5 (2020), 5–12. https://doi.org/10.1007/s41133-020-00032-0 doi: 10.1007/s41133-019-0023-4
|
| [8] |
J. N. Chen, Z. B. Dai, J. T. Duan, H. Matzinger, I. Popescu, Improved Naive Bayes with optimal correlation factor for text classification, SN Appl. Sci., 1 (2019), 1–10. https://doi.org/10.1007/s42452-019-1153-5 doi: 10.1007/s42452-019-1153-5
|
| [9] | J. Liu, T. Jin, K. Pan, Y. Yang, Y. Wu, X. Wang, et al, An improved KNN text classification algorithm based on Simhash, IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing, (2017), 92–95. |
| [10] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, Comput Sci., (2013). https://arXiv.org/abs/1301.3781 |
| [11] | T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed representations of words and phrasesand their compositionality, Neural Inform. Process. Syst., 26 (2013), 3111–3119. https://arXiv.org/abs/1310.4546v1 |
| [12] | Y. Kim, Convolutional neural networks for sentence classification, EMNLP, (2014). https://arXiv.org/abs/1408.5882 |
| [13] |
A. U. Rehman, A. K. Malik, B. Raza, W. Ali, A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis, Multimed. Tools Appl., 78 (2019), 26597–26613. https://doi.org/10.1007/s11042-019-07788-7 doi: 10.1007/s11042-019-07788-7
|
| [14] |
Z. W. Gao, Z. Y. Li, J. Y. Luo, X. L. Li, Short text aspect-based sentiment analysis based on CNN + BiGRU, Appl. Sci., 12 (2022). https://doi.org/10.3390/app12052707 doi: 10.3390/app12052707
|
| [15] |
P. Bhuvaneshwari, A. N. Rao, Y. H. Robinson, M. N. Thippeswamy, Sentiment analysis for user reviews using Bi-LSTM self-attention based CNN model, Multimed. Tools Appl., 81 (2022), 12405–12419. https://doi.org/10.1007/s11042-022-12410-4 doi: 10.1007/s11042-022-12410-4
|
| [16] |
W. Wang, Y. X. Sun, Q. J. Qi, X. F. Meng, Text sentiment classification model based on BiGRU-attention neural network, Appl. Res. Comput., 36 (2019), 3558–3564. https://doi.org/10.19734/j.issn.1001-3695.2018.07.0413 doi: 10.19734/j.issn.1001-3695.2018.07.0413
|
| [17] |
J. F. Deng, L. L. Cheng, Z. W. Wang, Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification, Comput. Speech Lang., 68 (2021). https://doi.org/10.1016/J.CSL.2020.101182 doi: 10.1016/J.CSL.2020.101182
|
| [18] |
J. B. Xie, J. H. Li, S. Q. Kang, Q. Y. Wang, Y. J. Wang, A multi-domain text classification method based on recurrent convolution multi-task learning, J. Electron. Inform. Technol., 43 (2021), 2395–2403. https://doi.org/10.11999/JEIT200869 doi: 10.11999/JEIT200869
|
| [19] |
H. Y. Wu, J. Yan, S. B. Huang, R. S. Li, M. Q. Jiang, CNN-BiLSTM-Attention Hybrid Model for Text Classification, Computer Sci., 47 (2020), 23–27. https://doi.org/10.11896/jsjkx.200400116 doi: 10.11896/jsjkx.200400116
|
| [20] |
G. Liu, J. B. Guo, Bidirectional LSTM with attention mechanism and convolutional layer for text classification, Neurocomputing, 337 (2019), 325–338. https://doi.org/10.1016/j.neucom.2019.01.078 doi: 10.1016/j.neucom.2019.01.078
|
| [21] |
G. X. Xu, Z. X. Zhang, T. Zhang, S. A. Yu, Y. T. Meng, S. J. Chen, Aspect-level sentiment classification based on attention-BiLSTM model and transfer learning, Knowledge-based Syst., 245 (2022). https://doi.org/10.1016/j.knosys.2022.108586 doi: 10.1016/j.knosys.2022.108586
|
| [22] |
P. Kumar, B. Raman, A BERT based dual-channel explainable text emotion recognition system, Neural Networks, 150 (2022), 392–407. https://doi.org/10.1016/j.neunet.2022.03.017 doi: 10.1016/j.neunet.2022.03.017
|
| [23] |
C. Yan, J. H. Liu, W. Liu, X. H. Liu, Research on public opinion sentiment classification based on attention parallel dual-channel deep learning hybrid model, Eng. Appl. Artif. Intell., 116 (2022). https://doi.org/10.1016/j.engappai.2022.105448 doi: 10.1016/j.engappai.2022.105448
|
| [24] |
F. Zhao, X. N. Li, Y. T. Gao, Y. Li, Z. Q. Feng, C. M. Zhang, Multi-layer features ablation of BERT model and its application in stock trend prediction, Expert Syst. Appl., 207 (2022). https://doi.org/10.1016/j.eswa.2022.117958 doi: 10.1016/j.eswa.2022.117958
|
| [25] | J. Devlin, M. W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, (2018). https://arXiv.org/abs/1810.04805v1 |
| [26] |
A. Alhanouf, A. Abdulrahman, AraXLNet: Pre-trained language model for sentiment analysis of Arabic, J. Big Data, 9 (2022). https://doi.org/10.1186/s40537-022-00625-z doi: 10.1186/s40537-022-00625-z
|
| [27] |
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735–1780. https://doi.org/10.1162/NECO.1997.9.8.1735 doi: 10.1162/NECO.1997.9.8.1735
|
| [28] |
Q. N. Zhu, X. F. Jiang, R. Z. Ye, Sentiment analysis of review text based on BiGRU-attention and hybrid CNN, IEEE Access, 9 (2021), 149077–149088. https://doi.org/10.1109/ACCESS.2021.3118537 doi: 10.1109/ACCESS.2021.3118537
|







Figures(8) / Tables(2)

Chaofan Li, Qiong Liu, Kai Ma. DCCL: Dual-channel hybrid neural network combined with self-attention for text classification[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1981-1992. doi: 10.3934/mbe.2023091







 DownLoad:
DownLoad: