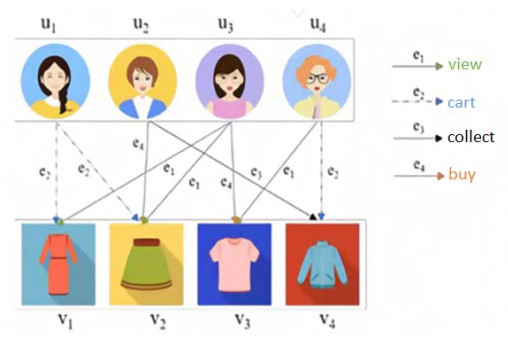
In order to capture the complex dependencies between users and items in a recommender system and to alleviate the smoothing problem caused by the aggregation of multi-layer neighborhood information, a multi-behavior recommendation model (DNCLR) based on dual neural networks and contrast learning is proposed. In this paper, the complex dependencies between behaviors are divided into feature correlation and temporal correlation. First, we set up a personalized behavior vector for users and use a graph-convolution network to learn the features of users and items under different behaviors, and we then combine the features of self-attention mechanism to learn the correlation between behaviors. The multi-behavior interaction sequence of the user is input into the recurrent neural network, and the temporal correlation between the behaviors is captured by combining the attention mechanism. The contrast learning is introduced based on the double neural network. In the graph convolution network layer, the distances between users and similar users and between users and their preference items are shortened, and the distance between users and their short-term preference is shortened in the circular neural network layer. Finally, the personalized behavior vector is integrated into the prediction layer to obtain more accurate user, behavior and item characteristics. Compared with the sub-optimal model, the HR@10 on Yelp, ML20M and Tmall real datasets are improved by 2.5%, 0.3% and 4%, respectively. The experimental results show that the proposed model can effectively improve the recommendation accuracy compared with the existing methods.
Citation: Suqi Zhang, Wenfeng Wang, Ningning Li, Ningjing Zhang. Multi-behavioral recommendation model based on dual neural networks and contrast learning[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19209-19231. doi: 10.3934/mbe.2023849
In order to capture the complex dependencies between users and items in a recommender system and to alleviate the smoothing problem caused by the aggregation of multi-layer neighborhood information, a multi-behavior recommendation model (DNCLR) based on dual neural networks and contrast learning is proposed. In this paper, the complex dependencies between behaviors are divided into feature correlation and temporal correlation. First, we set up a personalized behavior vector for users and use a graph-convolution network to learn the features of users and items under different behaviors, and we then combine the features of self-attention mechanism to learn the correlation between behaviors. The multi-behavior interaction sequence of the user is input into the recurrent neural network, and the temporal correlation between the behaviors is captured by combining the attention mechanism. The contrast learning is introduced based on the double neural network. In the graph convolution network layer, the distances between users and similar users and between users and their preference items are shortened, and the distance between users and their short-term preference is shortened in the circular neural network layer. Finally, the personalized behavior vector is integrated into the prediction layer to obtain more accurate user, behavior and item characteristics. Compared with the sub-optimal model, the HR@10 on Yelp, ML20M and Tmall real datasets are improved by 2.5%, 0.3% and 4%, respectively. The experimental results show that the proposed model can effectively improve the recommendation accuracy compared with the existing methods.

| [1] | G. J. Zhang, F. Z. Zhang, Z. H. Zhang, Y. Xiang, N. J. Yuan, X. Xie, et al., DRN: A deep reinforcement learning framework for news recommendation, in Proceedings of the 2018 World Wide Web Conference, (2018), 167–176. https://doi.org/10.1145/3178876.3185994 |
| [2] | Q. M. Diao, M. H. Qiu, C. Y. Wu, A. J. Smola, J Jiang, C. Wang, Jointly modeling aspects, ratings and sentiments for movie recommendation, in Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2014), 193–202. https://doi.org/10.1145/2623330.2623758 |
| [3] | G. R. Zhou, X. Q. Zhu, C. R. Song, Y. Fan, H. Zhu, X. Ma, et al., Deep interest network for click-through rate prediction, in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, (2018), 1059–1068. https://doi.org/10.1145/3219819.32198234. |
| [4] | R. Ma, Q. Zhang, J. Wang, L. Z. Cui, X. J. Huang, Mention recommendation for multimodal microblog with cross-attention memory network, in Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, (2018), 195–204. |
| [5] | B. Jin, C. Cao, X. He, D. P. Jin, Y. Li, Multi-behavior recommendation with graph convolutional networks, in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, (2020), 659–668. https://doi.org/10.1145/3397271.3401072 |
| [6] | C. Chen, W. Ma, M. Zhang, Z. W. Wang, X. Q. He, C. Y. Wang, et al. Graph heterogeneous multi-relational recommendation, in Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 3958–3966. https://doi.org/10.1609/aaai.v35i5.16515 |
| [7] | Y. Ni, D. Ou, S. Liu, X. Li, W. W. Ou, A. X. Zeng, et al., Perceive your users in depth: Learning universal user representations from multiple e-commerce tasks, in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, (2018), 596–605. |
| [8] | L. Guo, L. Hua, R. Jia, B. Q. Zhao, X. B. Wang, B. Cui, Buying or browsing? Predicting real-time purchasing intent using attention-based deep network with multiple behavior, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, (2019), 1984–1992. https://doi.org/10.1145/3292500.3330670 |
| [9] |
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735 doi: 10.1162/neco.1997.9.8.1735

|
| [10] | Y. Tang, Y. Huang, Z. Wu, H. L. Meng; M. X. Xu; L. H. Cai, et al., Question detection from acoustic features using recurrent neural network with gated recurrent unit, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, (2016), 6125–6129. https://doi.org/10.1109/ICASSP.2016.7472854 |
| [11] | L. Xia, C. Huang, Y. Xu, P. Dai, X. Y. Zhang, H. S. Yang, et al., Knowledge-enhanced hierarchical graph transformer network for multi-behavior recommendation, in Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 4486–4493. https://doi.org/10.1609/aaai.v35i5.16576 |
| [12] | Z. Wang, J. Zhang, J. Feng, Z. Chen, Knowledge graph embedding by translating on hyperplanes, in Proceedings of the AAAI conference on artificial intelligence, 28 (2014). https://doi.org/10.1609/aaai.v28i1.8870 |
| [13] | L. Xia, Y Xu, C Huang, P. Dai, L. f. Bo, Graph meta network for multi-behavior recommendation, in Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, (2021), 757–766. https://doi.org/10.1145/3404835.3462972 |
| [14] | S. Gu, X. Wang, C. Shi, D. Xiao, Self-supervised Graph Neural Networks for Multi-behavior Recommendation, in International Joint Conference on Artificial Intelligence, 2022 (2022). |
| [15] | W. Wei, C. Huang, L. Xia, Y. Xu, J. S. Zhao, D. W. Yin, Contrastive meta learning with behavior multiplicity for recommendation, in Proceedings of the fifteenth ACM international conference on web search and data mining, (2022), 1120–1128. |
| [16] | Y. Wu, R. Xie, Y. Zhu, X. Ao, X. Chen, X. Zhang, et al., Multi-view multi-behavior contrastive learning in recommendation, in Database Systems for Advanced Applications: 27th International Conference, (2022), 166–182. https://doi.org/10.1007/978-3-031-00126-0_11 |
| [17] |
A. Da'u, N. Salim, Recommendation system based on deep learning methods: A systematic review and new directions, Artif. Intell. Rev., 53 (2020), 2709–2748. https://doi.org/10.1007/s10462-019-09744-1 doi: 10.1007/s10462-019-09744-1
|
| [18] |
J. Wei, J. He, K. Chen, Y. Zhou, Z. Y. Tang, et al., Collaborative filtering and deep learning based recommendation system for cold start items, Expert Syst. Appl., 69 (2017), 29–39. https://doi.org/10.1016/j.eswa.2016.09.040 doi: 10.1016/j.eswa.2016.09.040
|
| [19] |
M. Fu, H. Qu, Z. Yi, L. Lu, Y. S. Liu, et al., A novel deep learning-based collaborative filtering model for recommendation system, IEEE Transact. Cybern., 49 (2018), 1084–1096. https://doi.org/10.1109/TCYB.2018.2795041 doi: 10.1109/TCYB.2018.2795041
|
| [20] |
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, G. Monfardini, et al., The graph neural network model, IEEE Transact. Neural Networks, 20 (2008), 61–80. https://doi.org/10.1109/TNN.2008.2005605 doi: 10.1109/TNN.2008.2005605
|
| [21] | C. Zhang, D. Song, C. Huang, A. Swami, N. V. Chawla, et al., Heterogeneous graph neural network, in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, (2019), 793–803. https://doi.org/10.1145/3292500.3330961 |
| [22] |
J Zhou, G Cui, S. Hu, Z. Y. Zhang, C. Yang, Z. Y. Liu, et al., Graph neural networks: A review of methods and applications, AI Open, 1 (2020), 57–81. https://doi.org/10.1016/j.aiopen.2021.01.001 doi: 10.1016/j.aiopen.2021.01.001
|
| [23] | W. Zaremba, I. Sutskever, O. Vinyals, Recurrent neural network regularization, arXiv preprint. 2014 (2014). |











Figures(12) / Tables(5)

Suqi Zhang, Wenfeng Wang, Ningning Li, Ningjing Zhang. Multi-behavioral recommendation model based on dual neural networks and contrast learning[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19209-19231. doi: 10.3934/mbe.2023849







 DownLoad:
DownLoad: