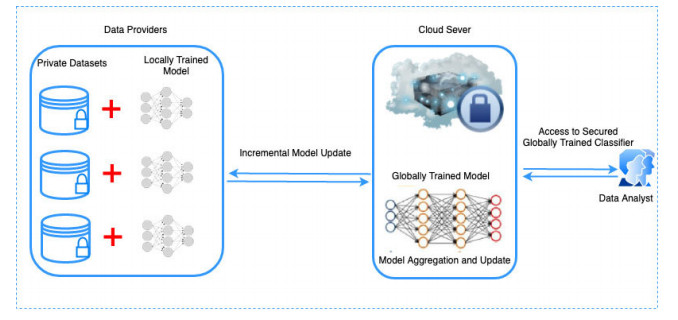
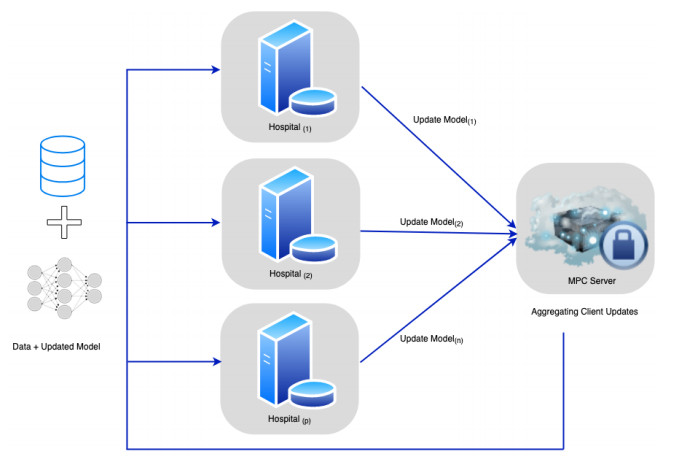
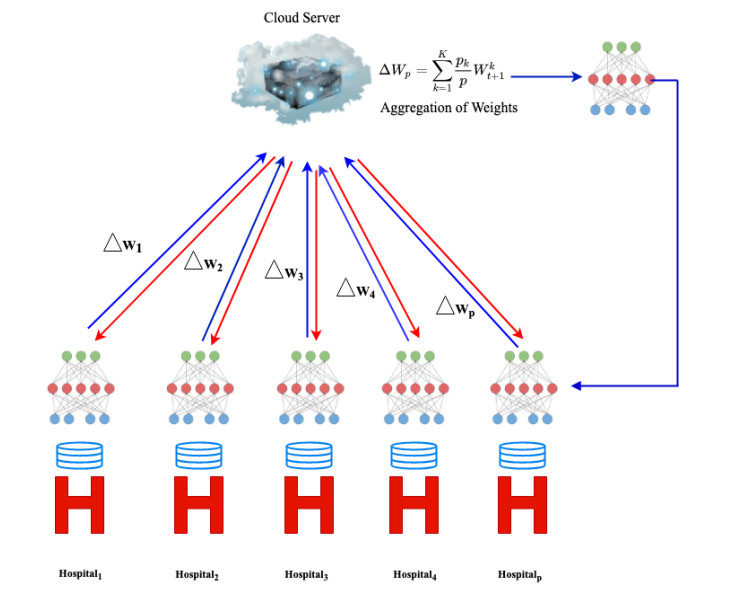
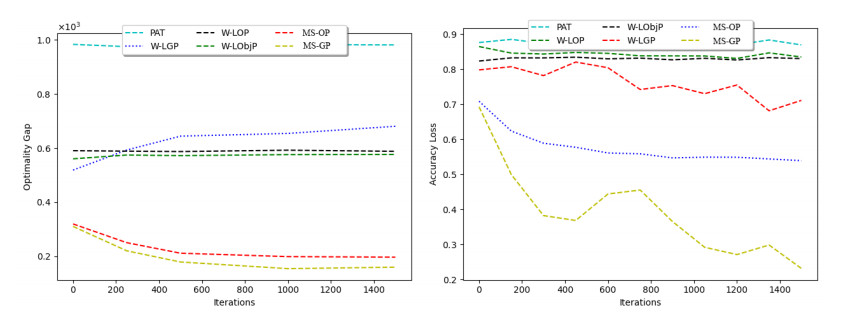
Distributed learning over data from sensor-based networks has been adopted to collaboratively train models on these sensitive data without privacy leakages. We present a distributed learning framework that involves the integration of secure multi-party computation and differential privacy. In our differential privacy method, we explore the potential of output perturbation and gradient perturbation and also progress with the cutting-edge methods of both techniques in the distributed learning domain. In our proposed multi-scheme output perturbation algorithm (MS-OP), data owners combine their local classifiers within a secure multi-party computation and later inject an appreciable amount of statistical noise into the model before they are revealed. In our Adaptive Iterative gradient perturbation (MS-GP) method, data providers collaboratively train a global model. During each iteration, the data owners aggregate their locally trained models within the secure multi-party domain. Since the conversion of differentially private algorithms are often naive, we improve on the method by a meticulous calibration of the privacy budget for each iteration. As the parameters of the model approach the optimal values, gradients are decreased and therefore require accurate measurement. We, therefore, add a fundamental line-search capability to enable our MS-GP algorithm to decide exactly when a more accurate measurement of the gradient is indispensable. Validation of our models on three (3) real-world datasets shows that our algorithm possesses a sustainable competitive advantage over the existing cutting-edge privacy-preserving requirements in the distributed setting.
Citation: Kwabena Owusu-Agyemang, Zhen Qin, Appiah Benjamin, Hu Xiong, Zhiguang Qin. Guaranteed distributed machine learning: Privacy-preserving empirical risk minimization[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4772-4796. doi: 10.3934/mbe.2021243
Distributed learning over data from sensor-based networks has been adopted to collaboratively train models on these sensitive data without privacy leakages. We present a distributed learning framework that involves the integration of secure multi-party computation and differential privacy. In our differential privacy method, we explore the potential of output perturbation and gradient perturbation and also progress with the cutting-edge methods of both techniques in the distributed learning domain. In our proposed multi-scheme output perturbation algorithm (MS-OP), data owners combine their local classifiers within a secure multi-party computation and later inject an appreciable amount of statistical noise into the model before they are revealed. In our Adaptive Iterative gradient perturbation (MS-GP) method, data providers collaboratively train a global model. During each iteration, the data owners aggregate their locally trained models within the secure multi-party domain. Since the conversion of differentially private algorithms are often naive, we improve on the method by a meticulous calibration of the privacy budget for each iteration. As the parameters of the model approach the optimal values, gradients are decreased and therefore require accurate measurement. We, therefore, add a fundamental line-search capability to enable our MS-GP algorithm to decide exactly when a more accurate measurement of the gradient is indispensable. Validation of our models on three (3) real-world datasets shows that our algorithm possesses a sustainable competitive advantage over the existing cutting-edge privacy-preserving requirements in the distributed setting.

| [1] | X. Chen, L. Yu, T. Wang, A. Liu, X. Wu, B. Zhang, et al., Artificial intelligence-empowered path selection: A survey of ant colony optimization for static and mobile sensor networks, IEEE Access, 8 (2020), 71497–71511. |
| [2] | M. A. R. Ahad, A. D. Antar, M. Ahmed, IoT Sensor-Based Activity Recognition - Human Activity Recognition, Intelligent Systems Reference Library, Springer, 173 (2021). |
| [3] |
J. Lin, G. Srivastava, Y. Zhang, Y. Djenouri, M. Aloqaily, Privacy-preserving multiobjective sanitization model in 6G IoT environments, IEEE Int. Things J., 8 (2021), 5340–5349. doi: 10.1109/JIOT.2020.3032896

|
| [4] |
C. Iwendi, S. A. Moqurrab, A. Anjum, S. Khan, S. Mohan, G. Srivastava, N-sanitization: A semantic privacy-preserving framework for unstructured medical datasets, Comput. Commun., 161 (2020), 160–171. doi: 10.1016/j.comcom.2020.07.032
|
| [5] | C. Dwork, F. McSherry, K. Nissim, A. D. Smith, Calibrating noise to sensitivity in private data analysis, J. Priv. Confidentiality, 7 (2016), 17–51. |
| [6] | J. Du, F. Bian, A privacy-preserving and efficient k-nearest neighbor query and classification scheme based on k-dimensional tree for outsourced data, IEEE Access, 8 (2020), 69333–69345. |
| [7] |
J. Liu, Y. Tian, Y. Zhou, Y. Xiao, N. Ansari, Privacy preserving distributed data mining based on secure multi-party computation, Comput. Commun., 153 (2020), 208–216. doi: 10.1016/j.comcom.2020.02.014
|
| [8] | C. Gentry, Fully homomorphic encryption using ideal lattices, in Proceedings of the 41st Annual ACM Symposium on Theory of Computing, ACM, (2009), 169–178. |
| [9] |
H. K. Bhuyan, N. K. Kamila, Privacy preserving sub-feature selection in distributed data mining, Appl. Soft Comput., 36 (2015), 552–569. doi: 10.1016/j.asoc.2015.06.060
|
| [10] | A. Gascón, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, et al., Privacy-preserving distributed linear regression on high-dimensional data, PoPETs, 2017 (2017), 345–364. |
| [11] | K. Chaudhuri, C. Monteleoni, A. D. Sarwate, Differentially private empirical risk minimization, J. Mach. Learn. Res., 12 (2011), 1069–1109. |
| [12] | M. A. Pathak, S. Rane, B. Raj, Multiparty differential privacy via aggregation of locally trained classifiers, in NIPS, (2010), 1876–1884. |
| [13] | B. Jayaraman, L. Wang, D. Evans, Q. Gu, Distributed learning without distress: Privacy-preserving empirical risk minimization, Adv. Neural Inf. Proc. Syst., 6346–6357, 2018. |
| [14] | L. Tian, B. Jayaraman, Q. Gu, D. Evans, Aggregating private sparse learning models using multi-party computation, in NIPS Workshop on Private Multi-Party Machine Learning, 2016. |
| [15] | M. Bun, T. Steinke, Concentrated differential privacy: Simplifications, extensions, and lower bounds, in Theory of Cryptography Conference, Springer, Berlin, Heidelberg, (2016), 635–658. |
| [16] | Y. Chen, Y. Mao, H. Liang, S. Yu, Y. Wei, S. Leng, Data poison detection schemes for distributed machine learning, IEEE Access, 8 (2020), 7442–7454. |
| [17] |
E. Alsuwat, H. Alsuwat, M. Valtorta, C. Farkas, Adversarial data poisoning attacks against the PC learning algorithm, Int. J. Gen. Syst., 49 (2020), 3–31. doi: 10.1080/03081079.2019.1630401
|
| [18] |
M. Aliasgari, M. Blanton, F. Bayatbabolghani, Secure computation of hidden markov models and secure floating-point arithmetic in the malicious model, Int. J. Inf. Sec., 16 (2017), 577–601. doi: 10.1007/s10207-016-0350-0
|
| [19] | O. Catrina, A. Saxena, Secure computation with fixed-point numbers, in International Conference on Financial Cryptography and Data Security, Springer, Berlin, Heidelberg, (2010), 35–50. |
| [20] | A. C. Yao, Protocols for secure computations, in 23rd annual symposium on foundations of computer science (sfcs 1982), IEEE, (1982), 160–164. |
| [21] | O. Goldreich, Secure multi-party computation, Manuscr. Prelim. Version, 78 (1998). |
| [22] | I. Damgård, C. Orlandi, Multiparty computation for dishonest majority: From passive to active security at low cost, in Annual cryptology conference, Springer, Berlin, Heidelberg, (2010), 558–576. |
| [23] | R. Shokri, V. Shmatikov, Privacy-preserving deep learning, in Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, (2015), 1310–1321. |
| [24] | R. Bendlin, I. Damgård, C. Orlandi, S. Zakarias, Semi-homomorphic Encryption and Multiparty Computation, Advances in Cryptology - EUROCRYPT 2011 - 30th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tallinn, Estonia, May 15-19, 2011. Proceedings |
| [25] | J. B. Nielsen, P. S. Nordholt, C. Orlandi, S. S. Burra, A new approach to practical active-secure two-party computation, in Annual Cryptology Conference, Springer, Berlin, Heidelberg, (2012), 681–700. |
| [26] |
A. Bansal, T. Chen, S. Zhong, Privacy preserving back-propagation neural network learning over arbitrarily partitioned data, Neural Comput. Appl., 20 (2011), 143–150. doi: 10.1007/s00521-010-0346-z
|
| [27] | J. Yuan, S. Yu, Privacy preserving back-propagation neural network learning made practical with cloud computing, IEEE Trans. Parallel Distrib. Syst., 25 (2014), 212–221. |
| [28] | W. Zhang, A BGN-type multiuser homomorphic encryption scheme, in 2015 International Conference on Intelligent Networking and Collaborative Systems, IEEE, (2015), 268–271. |
| [29] | E. Hesamifard, H. Takabi, M. Ghasemi, C. Jones, Privacy-preserving machine learning in cloud, in Proceedings of the 2017 on cloud computing security workshop, (2017), 39–43. |
| [30] |
P. Li, J. Li, Z. Huang, T. Li, C. Gao, S. Yiu, et al., Multi-key privacy-preserving deep learning in cloud computing, Future Gener. Comput. Syst., 74 (2017), 76–85. doi: 10.1016/j.future.2017.02.006
|
| [31] | P. Mukherjee, D. Wichs, Two round multiparty computation via multi-key FHE, in Annual International Conference on the Theory and Applications of Cryptographic Techniques, Springer, Berlin, Heidelberg, (2016), 735–763. |
| [32] | R. Agrawal, R. Srikant, Privacy-preserving data mining, in Proceedings of the 2000 ACM SIGMOD international conference on Management of data, (2000), 439–450. |
| [33] | P. K. Fong, J. H. Weber-Jahnke, Privacy preserving decision tree learning using unrealized data sets, IEEE Trans. Knowl. Data Eng., 24 (2012), 353–364. |
| [34] | J. M. Abowd, The US census bureau adopts differential privacy, in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2018), 2867–2867. |
| [35] | F. Liu, Generalized gaussian mechanism for differential privacy, IEEE Trans. Knowl. Data Eng., 31 (2019), 747–756. |
| [36] | C. Dwork, A. Roth, The algorithmic foundations of differential privacy, Found. Trends Theor. Comput. Sci., 9 (2014), 211–407. |
| [37] | C. Dwork, G. N. Rothblum, S. P. Vadhan, Boosting and differential privacy, in 2010 IEEE 51st Annual Symposium on Foundations of Computer Science, IEEE, (2010), 51–60. |
| [38] | O. Kwabena, Z. Qin, T. Zhuang, Z. Qin, Mscryptonet: Multi-scheme privacy-preserving deep learning in cloud computing, IEEE Access, 7 (2019), 29344–29354. |
| [39] | A. Albarghouthi, J. Hsu, Synthesizing coupling proofs of differential privacy, Proc. ACM Program. Lang., 2 (2017), 1–30. |
| [40] | K. Chaudhuri, C. Monteleoni, Privacy-preserving logistic regression, in NIPS, 8 (2008), 289–296. |
| [41] | J. Zhang, T. He, S. Sra, A. Jadbabaie, Why gradient clipping accelerates training: A theoretical justification for adaptivity, preprint, arXiv: 1905.11881. |
| [42] |
S. Alipour, F. Mirzaee, An iterative algorithm for solving two dimensional nonlinear stochastic integral equations: A combined successive approximations method with bilinear spline interpolation, Appl. Math. Comput., 371 (2020), 124947. doi: 10.1016/j.amc.2019.124947
|
| [43] | Y. Wang, D. Kifer, J. Lee, Differentially private confidence intervals for empirical risk minimization, J. Priv. Confidentiality, 9, (2019). |
| [44] | M. Lichman, UCI machine learning repository, 2013. Available from: http://archive.ics.uci.edu/ml. |
| [45] | I. Sharafaldin, A. H. Lashkari, A. A. Ghorbani, Toward generating a new intrusion detection dataset and intrusion traffic characterization, in ICISSp, (2018), 108–116. |
| [46] | S. Mahdavifar, A. F. A. Kadir, R. Fatemi, D. Alhadidi, A. A. Ghorbani, Dynamic android malware category classification using semi-supervised deep learning, in 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), IEEE, (2020), 515–522. |
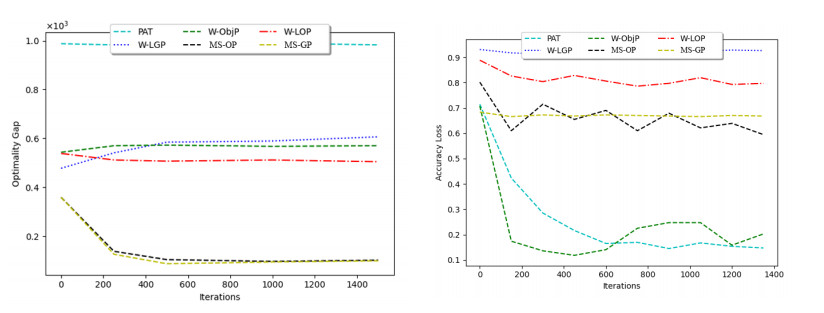
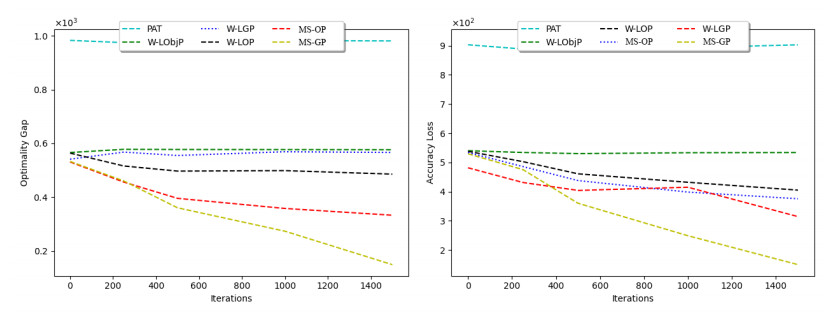
Figures(6) / Tables(4)

Kwabena Owusu-Agyemang, Zhen Qin, Appiah Benjamin, Hu Xiong, Zhiguang Qin. Guaranteed distributed machine learning: Privacy-preserving empirical risk minimization[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4772-4796. doi: 10.3934/mbe.2021243







 DownLoad:
DownLoad: