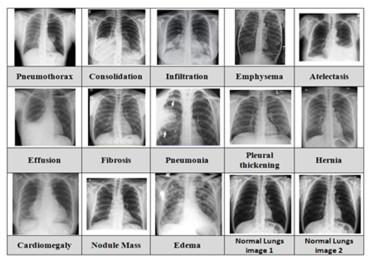
The utilization of computational models in the field of medical image classification is an ongoing and unstoppable trend, driven by the pursuit of aiding medical professionals in achieving swift and precise diagnoses. Post COVID-19, many researchers are studying better classification and diagnosis of lung diseases particularly, as it was reported that one of the very few diseases greatly affecting human beings was related to lungs. This research study, as presented in the paper, introduces an advanced computer-assisted model that is specifically tailored for the classification of 13 lung diseases using deep learning techniques, with a focus on analyzing chest radiograph images. The work flows from data collection, image quality enhancement, feature extraction to a comparative classification performance analysis. For data collection, an open-source data set consisting of 112,000 chest X-Ray images was used. Since, the quality of the pictures was significant for the work, enhanced image quality is achieved through preprocessing techniques such as Otsu-based binary conversion, contrast limited adaptive histogram equalization-driven noise reduction, and Canny edge detection. Feature extraction incorporates connected regions, histogram of oriented gradients, gray-level co-occurrence matrix and Haar wavelet transformation, complemented by feature selection via regularized neighbourhood component analysis. The paper proposes an optimized hybrid model, improved Aquila optimization convolutional neural networks (CNN), which is a combination of optimized CNN and DENSENET121 with applied batch equalization, which provides novelty for the model compared with other similar works. The comparative evaluation of classification performance among CNN, DENSENET121 and the proposed hybrid model is also done to find the results. The findings highlight the proposed hybrid model's supremacy, boasting 97.00% accuracy, 94.00% precision, 96.00% sensitivity, 96.00% specificity and 95.00% F1-score. In the future, potential avenues encompass exploring explainable machine learning for discerning model decisions and optimizing performance through strategic model restructuring.
Citation: Binju Saju, Neethu Tressa, Rajesh Kumar Dhanaraj, Sumegh Tharewal, Jincy Chundamannil Mathew, Danilo Pelusi. Effective multi-class lungdisease classification using the hybridfeature engineering mechanism[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20245-20273. doi: 10.3934/mbe.2023896
The utilization of computational models in the field of medical image classification is an ongoing and unstoppable trend, driven by the pursuit of aiding medical professionals in achieving swift and precise diagnoses. Post COVID-19, many researchers are studying better classification and diagnosis of lung diseases particularly, as it was reported that one of the very few diseases greatly affecting human beings was related to lungs. This research study, as presented in the paper, introduces an advanced computer-assisted model that is specifically tailored for the classification of 13 lung diseases using deep learning techniques, with a focus on analyzing chest radiograph images. The work flows from data collection, image quality enhancement, feature extraction to a comparative classification performance analysis. For data collection, an open-source data set consisting of 112,000 chest X-Ray images was used. Since, the quality of the pictures was significant for the work, enhanced image quality is achieved through preprocessing techniques such as Otsu-based binary conversion, contrast limited adaptive histogram equalization-driven noise reduction, and Canny edge detection. Feature extraction incorporates connected regions, histogram of oriented gradients, gray-level co-occurrence matrix and Haar wavelet transformation, complemented by feature selection via regularized neighbourhood component analysis. The paper proposes an optimized hybrid model, improved Aquila optimization convolutional neural networks (CNN), which is a combination of optimized CNN and DENSENET121 with applied batch equalization, which provides novelty for the model compared with other similar works. The comparative evaluation of classification performance among CNN, DENSENET121 and the proposed hybrid model is also done to find the results. The findings highlight the proposed hybrid model's supremacy, boasting 97.00% accuracy, 94.00% precision, 96.00% sensitivity, 96.00% specificity and 95.00% F1-score. In the future, potential avenues encompass exploring explainable machine learning for discerning model decisions and optimizing performance through strategic model restructuring.

| [1] | A. Sinha, A. R P, M. Suresh, N. M. R, A. D, A. G. Singerji, Brain tumour detection using deep learning, in 2021 Seventh International conference on Bio Signals, Images, and Instrumentation (ICBSII), (2021), 1–5. https://doi.org/10.1109/ICBSII51839.2021.9445185 |
| [2] | B. Saju, V. Asha, A. Prasad, V. A, A. S, S. P. Sreeja, Prediction analysis of hypothyroidism by association, in 2023 Third International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), (2023), 1–6. https://doi.org/10.1109/ICAECT57570.2023.10117641 |
| [3] |
H. Tang, Z. Hu, Research on medical image classification based on machine learning, IEEE Access, 8 (2020), 93145–93154. https://doi.org/10.1109/ACCESS.2020.2993887 doi: 10.1109/ACCESS.2020.2993887

|
| [4] |
S. K. Zhou, H. Greenspan, C. Davatzikos, J. S. Duncan, B. V. Ginneken, A. Madabhushi, et al., A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises, Proc. IEEE, 109 (2021), 820–838. https://doi.org/10.1109/JPROC.2021.3054390 doi: 10.1109/JPROC.2021.3054390
|
| [5] |
P. Uppamma, S. Bhattacharya, Deep learning and medical image processing techniques for diabetic retinopathy: A survey of applications, challenges, and future trends, J. Healthcare Eng., 2023 (2023), 2728719. https://doi.org/10.1155/2023/2728719 doi: 10.1155/2023/2728719
|
| [6] | Z. Shi, L. He, Application of neural networks in medical image processing, in Proceedings of the Second International Symposium on Networking and Network Security, (2010), 23–26. |
| [7] |
L. Abualigah, D. Yousri, M. A. Elaziz, A. A. Ewees, M. A. A. Al-qaness, A. H. Gandomi, Aquila optimizer: A novel meta-heuristic optimization algorithm, Comput. Ind. Eng., 157 (2021), 107250. https://doi.org/10.1016/j.cie.2021.107250 doi: 10.1016/j.cie.2021.107250
|
| [8] |
H. Chen, M. M. Rogalski, J. N. Anker, Advances in functional X-ray imaging techniques and contrast agents, Phys. Chem. Chem. Phys., 14 (2012), 13469–13486. https://doi.org/10.1039/c2cp41858d doi: 10.1039/c2cp41858d
|
| [9] |
M. E. H. Chowdhury, T. Rahman, A. Khandakar, R. Mazhar, M. A. Kadir, Z. B. Mahbub, et al., Can AI help in screening viral and COVID-19 pneumonia?, IEEE Access, 8 (2020), 132665–132676. https://doi.org/10.1109/ACCESS.2020.3010287 doi: 10.1109/ACCESS.2020.3010287
|
| [10] | S. P. Sreeja, V. Asha, B. Saju, P. K. C, P. Manasa, V. C. R, Classifying chest X-rays for COVID-19 using deep learning, in 2023 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), (2023), 1084–1089. https://doi.org/10.1109/IITCEE57236.2023.10090915 |
| [11] |
M. Soni, S. Gomathi, P. Kumar, P. P. Churi, M. A. Mohammed, A. O. Salman, Hybridizing convolutional neural network for classification of lung diseases, Int. J. Swarm Intell. Res., 13 (2022), 1–15. https://doi.org/10.4018/IJSIR.287544 doi: 10.4018/IJSIR.287544
|
| [12] |
V. Indumathi, R. Siva, An efficient lung disease classification from X-ray images using hybrid Mask-RCNN and BiDLSTM, Biomed. Signal Process. Control, 81 (2023), 104340. https://doi.org/10.1016/j.bspc.2022.104340 doi: 10.1016/j.bspc.2022.104340
|
| [13] |
F. M. J. M. Shamrat, S. Azam, A. Karim, R. Islam, Z. Tasnim, P. Ghosh, et al., LungNet22: A fine-tuned model for multiclass classification and prediction of lung disease using X-ray images, J. Pers. Med., 12 (2022), 680. https://doi.org/10.3390/jpm12050680 doi: 10.3390/jpm12050680
|
| [14] |
R. Rajagopal, R. Karthick, P. Meenalochini, T. Kalaichelvi, Deep Convolutional Spiking Neural Network optimized with Arithmetic optimization algorithm for lung disease detection using chest X-ray images, Biomed. Signal Process. Control, 79 (2023), 104197. https://doi.org/10.1016/j.bspc.2022.104197 doi: 10.1016/j.bspc.2022.104197
|
| [15] |
S. Kim, B. Rim, S. Choi, A. Lee, S. Min, M. Hong, Deep learning in multi-class lung diseases' classification on chest X-ray images, Diagnostics, 12 (2022), 915. https://doi.org/10.3390/diagnostics12040915 doi: 10.3390/diagnostics12040915
|
| [16] |
A. M. Q. Farhan, S. Yang, Automatic lung disease classification from the chest X-ray images using hybrid deep learning algorithm, Multimed. Tools Appl., (2023), 38561–38587. https://doi.org/10.1007/s11042-023-15047-z doi: 10.1007/s11042-023-15047-z
|
| [17] |
S. Buragadda, K. S. Rani, S. V. Vasantha, M. K. Chakravarthi, HCUGAN: Hybrid cyclic UNET GAN for generating augmented synthetic images of chest X-Ray images for multi classification of lung diseases, Int. J. Eng. Trends Technol., 70 (2020), 249–253. http://doi.org/10.14445/22315381/IJETT-V70I2P227 doi: 10.14445/22315381/IJETT-V70I2P227
|
| [18] |
V. Ravi, V. Acharya, M. Alazab, A multichannel Efficient Net deep learning-based stacking ensemble approach for lung disease detection using chest X-ray images, Cluster Comput., 26 (2023), 1181–1203. https://doi.org/10.1007/s10586-022-03664-6 doi: 10.1007/s10586-022-03664-6
|
| [19] |
A. M. Ismael, A. Şengür, Deep learning approaches for COVID-19 detection based on chest X-ray images, Expert Syst. Appl., 164 (2021), 114054. https://doi.org/10.1016/j.eswa.2020.114054 doi: 10.1016/j.eswa.2020.114054
|
| [20] |
M. Blain, M. T. Kassin, N. Varble, X. Wang, Z. Xu, D. Xu, et al., Determination of disease severity in COVID-19 patients using deep learning in chest X-ray images, Diagn. Interv. Radiol., 27 (2021), 20–27. https://doi.org/10.5152/dir.2020.20205 doi: 10.5152/dir.2020.20205
|
| [21] |
E. H. Houssein, Z. Abohashima, M. Elhoseny, W. M. Mohamed, Hybrid quantum-classical convolutional neural network model for COVID-19 prediction using chest X-ray images, J. Comput. Design Eng., 9 (2022), 343–363. https://doi.org/10.1093/jcde/qwac003 doi: 10.1093/jcde/qwac003
|
| [22] |
W. A. Shalaby, W. Saad, M. Shokair, F. E. A. El-Samie, M. I. Dessouky, COVID-19 classification based on deep convolutional neural networks over a wireless network, Wireless Pers. Commun., 120 (2021), 1543–1563. https://doi.org/10.1007/s11277-021-08523-y doi: 10.1007/s11277-021-08523-y
|
| [23] |
W. Saad, W. A. Shalaby, M. Shokair, F. A. El-Samie, M. Dessouky, E. Abdellatef, COVID-19 classification using deep feature concatenation technique, J. Ambient Intell. Human. Comput., 13 (2022), 2025–2043. https://doi.org/10.1007/s12652-021-02967-7 doi: 10.1007/s12652-021-02967-7
|
| [24] |
S. Sheykhivand, Z. Mousavi, S. Mojtahedi, T. Y. Rezaii, A. Farzamnia, S. Meshgini, et al., Developing an efficient deep neural network for automatic detection of COVID-19 using chest X-ray images, Alexandria Eng. J., 60 (2021), 2885–2903. https://doi.org/10.1016/j.aej.2021.01.011 doi: 10.1016/j.aej.2021.01.011
|
| [25] | V. Agarwal, M. C. Lohani, A. S. Bist, D. Julianingsih, Application of voting based approach on deep learning algorithm for lung disease classification, in 2022 International Conference on Science and Technology (ICOSTECH), (2022), 1–7. https://doi.org/10.1109/ICOSTECH54296.2022.9828806 |
| [26] |
A. Narin, C. Kaya, Z. Pamuk, Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks, Pattern Anal. Appl., 24 (2021), 1207–1220. https://doi.org/10.1007/s10044-021-00984-y doi: 10.1007/s10044-021-00984-y
|
| [27] |
V. Kumar, A. Zarrad, R. Gupta, O. Cheikhrouhou, COV-DLS: Prediction of COVID-19 from X-rays using enhanced deep transfer learning techniques, J. Healthcare Eng., 2022 (2022), 6216273. https://doi.org/10.1155/2022/6216273 doi: 10.1155/2022/6216273
|
| [28] |
Q. Lv, S. Zhang, Y. Wang, Deep learning model of image classification using machine learning, Adv. Multimedia, 2022 (2022), 3351256. https://doi.org/10.1155/2022/3351256 doi: 10.1155/2022/3351256
|
| [29] |
M. Xin, Y. Wang, Research on image classification model based on deep convolutional neural network, J. Image Video Process., 2019 (2019). https://doi.org/10.1186/s13640-019-0417-8 doi: 10.1186/s13640-019-0417-8
|
| [30] | A. H. Setianingrum, A. S. Rini, N. Hakiem, Image segmentation using the Otsu method in Dental X-rays, in 2017 Second International Conference on Informatics and Computing (ICIC), (2017), 1–6. https://doi.org/10.1109/IAC.2017.8280611 |
| [31] |
S. Sahu, A. K. Singh, S. P. Ghrera, M. Elhoseny, An approach for de-noising and contrast enhancement of retinal fundus image using CLAHE, Opt. Laser Technol., 110 (2019), 87–98. https://doi.org/10.1016/j.optlastec.2018.06.061 doi: 10.1016/j.optlastec.2018.06.061
|
| [32] |
S. K. Jadwaa, X-Ray lung image classification using a canny edge detector, J. Electr. Comput. Eng., 2022 (2022), 3081584. https://doi.org/10.1155/2022/3081584 doi: 10.1155/2022/3081584
|
| [33] | P. G. Bhende, A. N. Cheeran, A novel feature extraction scheme for medical X-ray images, Int. J. Eng. Res. Appl., 6 (2016), 53–60. |
| [34] | P. K. Mall, P. K. Singh, D. Yadav, GLCM based feature extraction and medical X-ray image classification using machine learning techniques, in 2019 IEEE Conference on Information and Communication Technology, (2019), 1–6. https://doi.org/10.1109/CICT48419.2019.9066263 |
| [35] | S. Gunasekaran, S. Rajan, L. Moses, S. Vikram, M. Subalakshmi, B. Shudhersini, Wavelet based CNN for diagnosis of COVID 19 using chest X ray, in First International Conference on Circuits, Signals, Systems and Securities, 1084 (2021). https://doi.org/10.1088/1757-899X/1084/1/012015 |
| [36] | W. Yang, K. Wang, W. Zuo, Neighborhood component feature selection for high-dimensional data, J. Comput., 7 (2012), 161–168. |
| [37] | M. Ramprasath, M. V. Anand, S. Hariharan, Image classification using convolutional neural networks, Int. J. Pure Appl. Math., 119 (2018), 1307–1319. |
| [38] |
G. Wang, Z. Guo, X. Wan, X. Zheng, Study on image classification algorithm based on improved DENSENET, J. Phys.: Conf. Ser., 1952 (2021), 022011. http://doi.org/10.1088/1742-6596/1952/2/022011 doi: 10.1088/1742-6596/1952/2/022011
|
| [39] |
N. Hasan, Y. Bao, A. Shawon, Y. Huang, DENSENET convolutional neural networks application for predicting COVID-19 using CT image, SN Comput. Sci., 2 (2021), 389. https://doi.org/10.1007/s42979-021-00782-7 doi: 10.1007/s42979-021-00782-7
|
| [40] |
B. Sasmal, A. G. Hussien, A. Das, K. G. Dhal, A comprehensive survey on aquila optimizer, Arch. Comput. Methods Eng., 30 (2023), 4449–4476. https://doi.org/10.1007/s11831-023-09945-6 doi: 10.1007/s11831-023-09945-6
|
| [41] |
S. Ekinci, D. Izci, E. Eker, L. Abualigah, An effective control design approach based on novel enhanced aquila optimizer for automatic voltage regulator, Artif. Intell. Rev., 56 (2023), 1731–1762. https://doi.org/10.1007/s10462-022-10216-2 doi: 10.1007/s10462-022-10216-2
|
| [42] |
M. H. Nadimi-Shahraki, S. Taghian, S. Mirjalili, L. Abualigah, Binary aquila optimizer for selecting effective features from medical data: A COVID-19 case study, Mathematics, 10 (2022), 1929. https://doi.org/10.3390/math10111929 doi: 10.3390/math10111929
|
| [43] |
A. A. Ewees, Z. Y. Algamal, L. Abualigah, M. A. A. Al-qaness, D. Yousri, R. M. Ghoniem, et al., A cox proportional-hazards model based on an improved aquila optimizer with whale optimization algorithm operators, Mathematics, 10 (2022), 1273. https://doi.org/10.3390/math10081273 doi: 10.3390/math10081273
|
| [44] |
F. Gul, I. Mir, S. Mir, Aquila Optimizer with parallel computation application for efficient environment exploration, J. Ambient Intell. Human. Comput., 14 (2023), 4175–4190. https://doi.org/10.1007/s12652-023-04515-x doi: 10.1007/s12652-023-04515-x
|
| [45] |
S. Akyol, A new hybrid method based on Aquila optimizer and tangent search algorithm for global optimization, J. Ambient Intell. Human. Comput., 14 (2023), 8045–8065. https://doi.org/10.1007/s12652-022-04347-1 doi: 10.1007/s12652-022-04347-1
|
| [46] |
K. G. Dhal, R. Rai, A. Das, S. Ray, D. Ghosal, R. Kanjilal, Chaotic fitness-dependent quasi-reflected Aquila optimizer for superpixel based white blood cell segmentation, Neural Comput. Appl., 35 (2013), 15315–15332. https://doi.org/10.1007/s00521-023-08486-0 doi: 10.1007/s00521-023-08486-0
|
| [47] |
A. Ait-Saadi, Y. Meraihi, A. Soukane, A. Ramdane-Cherif, A. B. Gabis, A novel hybrid chaotic Aquila optimization algorithm with simulated annealing for unmanned aerial vehicles path planning, Comput. Electr. Eng., 104 (2022), 108461. https://doi.org/10.1016/j.compeleceng.2022.108461 doi: 10.1016/j.compeleceng.2022.108461
|
| [48] |
S. Wang, H. Jia, L. Abualigah, Q. Liu, R. Zheng, An improved hybrid aquila optimizer and harris hawks algorithm for solving industrial engineering optimization problems, Processes, 9 (2021), 1551. https://doi.org/10.3390/pr9091551 doi: 10.3390/pr9091551
|
| [49] |
Y. Zhang, Y. Yan, J. Zhao, Z. Gao, AOAAO: The hybrid algorithm of arithmetic optimization algorithm with aquila optimizer, IEEE Access, 10 (2022), 10907–10933. https://doi.org/10.1109/ACCESS.2022.3144431 doi: 10.1109/ACCESS.2022.3144431
|
| [50] | J. Zhong, H. Chen, W. Chao, Making batch normalization great in federated deep learning, preprint, arXiv: 2303.06530. |
| [51] |
M. Segu, A. Tonioni, F. Tombari, Batch normalization embeddings for deep domain generalization, Pattern Recognit., 135 (2023), 109115. https://doi.org/10.1016/j.patcog.2022.109115 doi: 10.1016/j.patcog.2022.109115
|
| [52] |
N. Talat, A. Alsadoon, P. W. C. Prasad, A. Dawoud, T. A. Rashid, S. Haddad, A novel enhanced normalization technique for a mandible bones segmentation using deep learning: batch normalization with the dropout, Multimed. Tools Appl., 82 (2023), 6147–6166. https://doi.org/10.1007/s11042-022-13399-6 doi: 10.1007/s11042-022-13399-6
|
| [53] |
G. M. M. Alshmrani, Q. Ni, R. Jiang, H. Pervaiz, N. M. Elshennawy, A deep learning architecture for multi-class lung diseases classification using chest X-ray (CXR) images, Alexandria Eng. J., 64 (2023), 923–935. https://doi.org/10.1016/j.aej.2022.10.053 doi: 10.1016/j.aej.2022.10.053
|
| [54] |
F. J. M. Shamrat, S. Azam, A. Karim, K. Ahmed, F. M. Bui, F. De Boer, High-precision multiclass classification of lung disease through customized MobileNetV2 from chest X-ray images, Comput. Biol. Med., 155 (2023), 106646. https://doi.org/10.1016/j.compbiomed.2023.106646 doi: 10.1016/j.compbiomed.2023.106646
|
| [55] |
K. Subramaniam, N. Palanisamy, R. A. Sinnaswamy, S. Muthusamy, O. P. Mishra, A. K. Loganathan, et al., A comprehensive review of analyzing the chest X-ray images to detect COVID-19 infections using deep learning techniques, Soft Comput., 27 (2023), 14219–14240. https://doi.org/10.1007/s00500-023-08561-7 doi: 10.1007/s00500-023-08561-7
|
| [56] |
S. Sharma, K. Guleria, A deep learning based model for the detection of pneumonia from chest X-Ray images using VGG-16 and neural networks, Procedia Comput. Sci., 218 (2023), 357–366. https://doi.org/10.1016/j.procs.2023.01.018 doi: 10.1016/j.procs.2023.01.018
|
| [57] |
V. T. Q. Huy, C. Lin, An improved DENSENET deep neural network model for tuberculosis detection using chest X-Ray images, IEEE Access, 11 (2023), 42839–42849. https://doi.org/10.1109/ACCESS.2023.3270774 doi: 10.1109/ACCESS.2023.3270774
|
| [58] |
V. Sreejith, T. George, Detection of COVID-19 from chest X-rays using ResNet-50, J. Phys.: Conf. Ser., 1937 (2021), 012002. https://doi.org/10.1088/1742-6596/1937/1/012002 doi: 10.1088/1742-6596/1937/1/012002
|
















Figures(17) / Tables(5)

Binju Saju, Neethu Tressa, Rajesh Kumar Dhanaraj, Sumegh Tharewal, Jincy Chundamannil Mathew, Danilo Pelusi. Effective multi-class lungdisease classification using the hybridfeature engineering mechanism[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20245-20273. doi: 10.3934/mbe.2023896







 DownLoad:
DownLoad: