Feature selection (FS) is a classic and challenging optimization task in the field of machine learning and data mining. Gradient-based optimizer (GBO) is a recently developed metaheuristic with population-based characteristics inspired by gradient-based Newton's method that uses two main operators: the gradient search rule (GSR), the local escape operator (LEO) and a set of vectors to explore the search space for solving continuous problems. This article presents a binary GBO (BGBO) algorithm and for feature selecting problems. The eight independent GBO variants are proposed, and eight transfer functions divided into two families of S-shaped and V-shaped are evaluated to map the search space to a discrete space of research. To verify the performance of the proposed binary GBO algorithm, 18 well-known UCI datasets and 10 high-dimensional datasets are tested and compared with other advanced FS methods. The experimental results show that among the proposed binary GBO algorithms has the best comprehensive performance and has better performance than other well known metaheuristic algorithms in terms of the performance measures.
Citation: Yugui Jiang, Qifang Luo, Yuanfei Wei, Laith Abualigah, Yongquan Zhou. An efficient binary Gradient-based optimizer for feature selection[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 3813-3854. doi: 10.3934/mbe.2021192
Feature selection (FS) is a classic and challenging optimization task in the field of machine learning and data mining. Gradient-based optimizer (GBO) is a recently developed metaheuristic with population-based characteristics inspired by gradient-based Newton's method that uses two main operators: the gradient search rule (GSR), the local escape operator (LEO) and a set of vectors to explore the search space for solving continuous problems. This article presents a binary GBO (BGBO) algorithm and for feature selecting problems. The eight independent GBO variants are proposed, and eight transfer functions divided into two families of S-shaped and V-shaped are evaluated to map the search space to a discrete space of research. To verify the performance of the proposed binary GBO algorithm, 18 well-known UCI datasets and 10 high-dimensional datasets are tested and compared with other advanced FS methods. The experimental results show that among the proposed binary GBO algorithms has the best comprehensive performance and has better performance than other well known metaheuristic algorithms in terms of the performance measures.

| [1] |
M. Chen, S. Mao, Y. Liu, Big data: A Survey, Mobile Netw. Appl., 19 (2014), 171-209. doi: 10.1007/s11036-013-0489-0

|
| [2] | I. Guyon, A. Elisseeff, An introduction of variable and feature selection, J. Mach. Learn Res., 3 (2003), 1157-1182. |
| [3] |
Y. Wan, M. Wang, Z. Ye, X. Lai, A feature selection method based on modified binary coded ant colony optimization algorithm, Appl. Soft Comput., 49 (2016), 248-258. doi: 10.1016/j.asoc.2016.08.011
|
| [4] | H. Liu, H. Motoda, Feature selection for knowledge discovery and data mining, Kluwer Academic, 2012. |
| [5] |
Z. Sun, G. Bebis, R. Miller, Object detection using feature subset selection, Pattern Recogn., 37 (2004), 2165-2176. doi: 10.1016/j.patcog.2004.03.013
|
| [6] | H. Liu, H. Motoda, Feature Extraction, Construction and Selection: A Data Mining Perspective Springer Science & Business Media, Boston, MA, 1998. |
| [7] |
Z. Zheng, X. Wu, R. K. Srihari, Feature selection for text categorization on imbalanced data, ACM Sigkdd Explor. Newsl., 6 (2004), 80-89. doi: 10.1145/1007730.1007741
|
| [8] |
H. Uguz, A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm, Knowl.-Based Syst., 24 (2011), 1024-1032. doi: 10.1016/j.knosys.2011.04.014
|
| [9] |
H. K. Ekenel, B. Sankur, Feature selection in the independent component subspace for face recognition, Pattern Recogn. Lett., 25 (2004), 1377-1388. doi: 10.1016/j.patrec.2004.05.013
|
| [10] | H. R. Kanan, K. Faez, An improved feature selection method based on ant colony optimization (ACO) evaluated on face recognition system, Appl. Math. Comput., 205 (2008), 716-725. |
| [11] |
F. Model, P. Adorjan, A. Olek, C. Piepenbrock, Feature selection for DNA methylation based cancer classification, Bioinformatics, 17 (2001), S157-S164. doi: 10.1093/bioinformatics/17.suppl_1.S157
|
| [12] |
N. Chuzhanova, A. J. Jones, S. Margetts, Feature selection for genetic sequence classification, Bioinformatics, 14 (1998), 139-143. doi: 10.1093/bioinformatics/14.2.139
|
| [13] |
S. Tabakhi, A. Najafi, R. Ranjbar, P. Moradi, Gene selection for microarray data classification using a novel ant colony optimization, Neurocomputing, 168 (2015), 1024-1036. doi: 10.1016/j.neucom.2015.05.022
|
| [14] |
D. Liang, C. F. Tsai, H. T. Wu, The effect of feature selection on financial distress prediction, Knowl.-Based Syst., 73 (2015), 289-297. doi: 10.1016/j.knosys.2014.10.010
|
| [15] | M. Ramezani, P. Moradi, F. A. Tab, Improve performance of collaborative filtering systems using backward feature selection, in The 5th Conference on Information and Knowledge Technology, (2013), 225-230. |
| [16] |
B. Tseng, Tzu Liang Bill, C. C. Huang, Rough set-based approach to feature selection in customer relationship management, Omega, 35 (2007), 365-383. doi: 10.1016/j.omega.2005.07.006
|
| [17] | R. Sawhney, P. Mathur, R. Shankar, A firefly algorithm based wrapper-penalty feature selection method for cancer diagnosis, in International Conference on Computational Science and Its Applications, Springer, Cham, (2018), 438-449. |
| [18] |
B. Guo, R. I. Damper, S. R. Gunn, J. D. B. Nelson, A fast separability-based feature-selection method for high-dimensional remotely sensed image classification, Pattern Recogn., 41 (2008), 1653-1662. doi: 10.1016/j.patcog.2007.11.007
|
| [19] | R. Abraham, J. B. Simha, S. S. Iyengar, Medical datamining with a new algorithm for feature selection and naive bayesian classifier, in 10th International Conference on Information Technology (ICIT 2007), IEEE, 2007, 44-49. |
| [20] | L. Yu, H. Liu, Feature selection for high-dimensional data: A fast correlation-based filter solution, in Proceedings of the 20th international conference on machine learning (ICML-03), (2003), 856-863. |
| [21] |
L. Cosmin, J. Taminau, S. Meganck, D. Steenhoff, A survey on filter techniques for feature selection in gene expression microarray analysis, IEEE/ACM Trans. Comput. Biol. Bioinf., 9 (2012), 1106-1119. doi: 10.1109/TCBB.2012.33
|
| [22] |
S. Maldonado, R. Weber, A wrapper method for feature selection using support vector machines, Inform. Sci., 179 (2009), 2208-2217. doi: 10.1016/j.ins.2009.02.014
|
| [23] |
J. Huang, Y. Cai, X. Xu, A hybrid genetic algorithm for feature selection wrapper based on mutual information, Pattern Recogn. Lett., 28 (2007), 1825-1844. doi: 10.1016/j.patrec.2007.05.011
|
| [24] | C. Tang, X. Liu, X. Zhu, J. Xiong, M. Li, J. Xia, et al., Feature selective projection with low-rank embedding and dual laplacian regularization, IEEE Trans. Knowl. Data. Eng., 32 (2019), 1747-1760. |
| [25] |
C. Tang, M. Bian, X. Liu, M. Li, H. Zhou, P. Wang, et al., Unsupervised feature selection via latent representation learning and manifold regularization, Neural Networks, 117 (2019), 163-178. doi: 10.1016/j.neunet.2019.04.015
|
| [26] | S. Sharifzadeh, L. Clemmensen, C. Borggaard, S. Støier, B. K. Ersbøll, Supervised feature selection for linear and non-linear regression of L*a*b color from multispectral images of meat, Eng. Appl. Artif. Intel., 27 (2013), 211-227. |
| [27] | C. Tang, X. Zheng, X. Liu, L. Wang, Cross-view locality preserved diversity and consensus learning for multi-view unsupervised feature selection, IEEE Trans. Knowl. Data. Eng., 2021. |
| [28] | C. Tang, X. Zhu, X. Liu, L. Wang, Cross-View local structure preserved diversity and consensus learning for multi-view unsupervised feature selection, in Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019), 5101-5108. |
| [29] | M. Dorigo, Optimization, Learning and Natural Algorithms, Phd Thesis Politecnico Di Milano, 1992. |
| [30] |
C. Lai, M. J. T. Reinders, L. Wessels, Random subspace method for multivariate feature selection, Pattern Recogn. Lett., 27 (2006), 1067-1076. doi: 10.1016/j.patrec.2005.12.018
|
| [31] |
B. Xue, M. Zhang, W. N. Browne, X. Yao, A survey on evolutionary computation approaches to feature selection, IEEE Trans. Evol. Comput., 20 (2016), 606-626. doi: 10.1109/TEVC.2015.2504420
|
| [32] |
J. J. Grefenstette, Optimization of control parameters for genetic algorithms, IEEE Trans. Syst. Man Cybern., 16 (1986), 122-128. doi: 10.1109/TSMC.1986.289288
|
| [33] | B. G. Obaiahnahatti, J. Kennedy, A new optimizer using particle swarm theory, in MHS'95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science, IEEE, (1995), 39-43. |
| [34] |
K. Chen, F. Y. Zhou, X. F. Yuan, Hybrid particle swarm optimization with spiral-shaped mechanism for feature selection, Expert Syst. Appl., 128 (2019), 140-156. doi: 10.1016/j.eswa.2019.03.039
|
| [35] |
S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Softw., 95 (2016), 51-67. doi: 10.1016/j.advengsoft.2016.01.008
|
| [36] |
S. Mirjalili, S.M. Mirjalili, A. Lewis, Grey wolf optimizer, Adv. Eng. Softw., 69 (2014), 46-61. doi: 10.1016/j.advengsoft.2013.12.007
|
| [37] |
S. Shahrzad, S. Mirjalili, A. Lewis, Grasshopper optimisation algorithm: Theory and application, Adv. Eng. Softw., 105 (2017), 30-47. doi: 10.1016/j.advengsoft.2017.01.004
|
| [38] |
E. Rashedi, H. Nezamabadi-Pour, S. Saryazdi, GSA: a gravitational search algorithm, Inform. Sci., 179 (2009), 2232-2248. doi: 10.1016/j.ins.2009.03.004
|
| [39] |
S. Li, H. Chen, M. Wang, A. A. Heidari, S. Mirjalili, Slime mould algorithm: A new method for stochastic optimization, Future Gener. Comput. Syst., 111 (2020), 300-323. doi: 10.1016/j.future.2020.03.055
|
| [40] | Y. Yang, H. Chen, A. A. Heidari, A. H. Gandomi, Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts, Expert Syst. Appl., 171 (2021), 114864. |
| [41] |
I. Ahmadianfar, O. Bozorg-Haddad, X. Chu, Gradient-based optimizer: A new metaheuristic optimization algorithm, Inform. Sci., 540 (2020), 131-159. doi: 10.1016/j.ins.2020.06.037
|
| [42] |
S. Mirjalili, Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems, Neural Comput. Appl., 27 (2016), 1053-1073. doi: 10.1007/s00521-015-1920-1
|
| [43] |
T. J. Ypma, Historical development of the Newton-Raphson method, SIAM Rev., 37 (1995), 531-551. doi: 10.1137/1037125
|
| [44] |
S. Mirjalili, A. Lewis, S-shaped versus V-shaped transfer functions for binary particle swarm optimization, Swarm Evol. Comput., 9 (2013), 1-14. doi: 10.1016/j.swevo.2012.09.002
|
| [45] | H. Liu, J. Li, L. Wong, A comparative study on feature selection and classification methods using gene expression profiles and proteomic patterns, Genome Inform., 13 (2002), 51-60. |
| [46] |
M. Dash, H. Liu, Feature selection for classification, Intell. Data Anal., 1 (1997), 131-156. doi: 10.3233/IDA-1997-1302
|
| [47] |
W. Siedlecki, J. Sklansky, A note on genetic algorithms for large-scale feature selection, Pattern Recogn. Lett., 10 (1989), 335-347. doi: 10.1016/0167-8655(89)90037-8
|
| [48] |
R. Leardi, R. Boggia, M. Terrile, Genetic algorithms as a strategy for feature selection, J. Chemom., 6 (1992), 267-281. doi: 10.1002/cem.1180060506
|
| [49] |
I. S. Oh, J. S. Lee, B. R. Moon, Hybrid genetic algorithms for feature selection, IEEE Trans. Pattern Anal., 26 (2004), 1424-1437. doi: 10.1109/TPAMI.2004.105
|
| [50] |
R. Storn, K. Price, Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces, J. Global Optim., 11 (1997), 341-359. doi: 10.1023/A:1008202821328
|
| [51] | B. Xue, W. Fu, M. Zhang, Differential evolution (DE) for multi-objective feature selection in classification, in Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, (2014), 83-84. |
| [52] | D. Karaboga, B. Akay, A comparative study of artificial bee colony algorithm, Appl. Math. Comput., 214 (2009), 108-132. |
| [53] |
A. A. Heidari, S. Mirjalili, H. Faris, I. Aljarah, M. Mafarja, H. Chen, Harris hawks optimization: Algorithm and applications, Future Gener. Comput. Syst., 97 (2019), 849-872. doi: 10.1016/j.future.2019.02.028
|
| [54] |
A. Faramarzi, M. Heidarinejad, S. Mirjalili, A. H. Gandomi, Marine predators algorithm: A nature-inspired metaheuristic, Expert Syst. Appl., 152 (2020), 113377. doi: 10.1016/j.eswa.2020.113377
|
| [55] |
O. S. Qasim, Z. Algamal, Feature selection using particle swarm optimization-based logistic regression model, Chemom. Intell. Lab. Syst., 182 (2018), 41-46. doi: 10.1016/j.chemolab.2018.08.016
|
| [56] |
K. Chen, F. Y. Zhou, X. F. Yuan, Hybrid particle swarm optimization with spiral-shaped mechanism for feature selection, Expert Syst. Appl., 128 (2019), 140-156. doi: 10.1016/j.eswa.2019.03.039
|
| [57] |
B. Xue, M. Zhang, W. N. Browne, Particle swarm optimization for feature selection in classification: a multi-objective approach, IEEE Trans. Cybern., 43 (2013), 1656-1671. doi: 10.1109/TSMCB.2012.2227469
|
| [58] |
E. Emary, H. M. Zawbaa, A. E. Hassanien, Binary grey wolf optimization approaches for feature selection, Neurocomputing, 172 (2016), 371-381. doi: 10.1016/j.neucom.2015.06.083
|
| [59] |
P. Hu, J. S. Pan, S. C. Chu, Improved binary grey wolf optimizer and its application for feature selection, Knowl.-Based Syst., 195 (2020), 105746. doi: 10.1016/j.knosys.2020.105746
|
| [60] |
T. Qiang, X. Chen, X. Liu, Multi-strategy ensemble grey wolf optimizer and its application to feature selection, Appl. Soft Comput., 76 (2019), 16-30. doi: 10.1016/j.asoc.2018.11.047
|
| [61] |
M. M. Mafarja, S. Mirjalili, Whale optimization approaches for wrapper feature selection, Appl. Soft Comput., 62 (2018), 441-453. doi: 10.1016/j.asoc.2017.11.006
|
| [62] |
M. M. Mafarja, S. Mirjalili, Hybrid whale optimization algorithm with simulated annealing for feature selection, Neurocomputing, 260 (2017), 302-312. doi: 10.1016/j.neucom.2017.04.053
|
| [63] |
R. K. Agrawal, B. Kaur, S. Sharma, Quantum based whale optimization algorithm for wrapper feature selection, Appl. Soft Comput., 89 (2020), 106092. doi: 10.1016/j.asoc.2020.106092
|
| [64] | C. R. Hwang, Simulated annealing: Theory and applications, Acta. Appl. Math., 12 (1988), 108-111. |
| [65] |
H. Shareef, A. A. Ibrahim, A. H. Mutlag, Lightning search algorithm, Appl. Soft Comput., 36 (2015), 315-333. doi: 10.1016/j.asoc.2015.07.028
|
| [66] |
S. Mirjalili, S. M. Mirjalili, A. Hatamlou, Multi-verse optimizer: a nature-inspired algorithm for global optimization, Neural Comput. Appl., 27 (2016), 495-513. doi: 10.1007/s00521-015-1870-7
|
| [67] |
H. Abedinpourshotorban, S. M. Shamsuddin, Z. Beheshti, D. N. A. Jawawib, Electromagnetic field optimization: A physics-inspired metaheuristic optimization algorithm, Swarm Evol. Comput., 26 (2016), 8-22. doi: 10.1016/j.swevo.2015.07.002
|
| [68] | A. Y. S. Lam, V. O. K. Li, Chemical-reaction-inspired metaheuristic for optimization, IEEE Trans. Evol. Comput., 14 (2009), 381-399. |
| [69] |
F. A. Hashim, E. H. Houssein, M. S. Mabrouk, W. Al-Atabany, S. Mirjalili, Henry gas solubility optimization: A novel physics-based algorithm, Future Gener. Comp. Syst., 101 (2019), 646-667. doi: 10.1016/j.future.2019.07.015
|
| [70] |
R. Meiri, J. Zahavi, Using simulated annealing to optimize the feature selection problem in marketing applications, Eur. J. Oper. Res., 171 (2006), 842-858. doi: 10.1016/j.ejor.2004.09.010
|
| [71] |
S. W. Lin, Z. J. Lee, S. C. Chen, T. Y. Tseng, Parameter determination of support vector machine and feature selection using simulated annealing approach, Appl. Soft Comput., 8 (2008), 1505-1512. doi: 10.1016/j.asoc.2007.10.012
|
| [72] |
E. Rashedi, H. Nezamabadi-Pour, S. Saryazdi, BGSA: Binary gravitational search algorithm, Nat. Comput., 9 (2010), 727-745. doi: 10.1007/s11047-009-9175-3
|
| [73] |
S. Nagpal, S. Arora, S. Dey, Feature selection using gravitational search algorithm for biomedical data, Procedia Comput. Sci., 115 (2017), 258-265. doi: 10.1016/j.procs.2017.09.133
|
| [74] |
P. C. S. Rao, A. J. S. Kumar, Q. Niyaz, P. Sidike, V. K. Devabhaktuni, Binary chemical reaction optimization based feature selection techniques for machine learning classification problems, Expert Syst. Appl., 167 (2021), 114169. doi: 10.1016/j.eswa.2020.114169
|
| [75] |
N. Neggaz, E. H. Houssein, K. Hussain, An efficient henry gas solubility optimization for feature selection, Expert Syst. Appl., 152 (2020), 113364. doi: 10.1016/j.eswa.2020.113364
|
| [76] |
R. V. Rao, V. J. Savsani, D. P. Vakharia, Teaching-learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput. Aided Design, 43 (2011), 303-315. doi: 10.1016/j.cad.2010.12.015
|
| [77] |
S. Hosseini, A. A. Khaled, A survey on the imperialist competitive algorithm metaheuristic: implementation in engineering domain and directions for future research, Appl. Soft Comput., 24 (2014), 1078-1094. doi: 10.1016/j.asoc.2014.08.024
|
| [78] | R. Moghdani, K. Salimifard, Volleyball premier league algorithm, Appl. Soft Comput., 64 (2017), 161-185. |
| [79] |
H. C. Kuo, C. H. Lin, Cultural evolution algorithm for global optimizations and its applications, J. Appl. Res. Technol., 11 (2013), 510-522. doi: 10.1016/S1665-6423(13)71558-X
|
| [80] | M. Allam, M. Nandhini, Optimal feature selection using binary teaching learning based optimization algorithm, J. King Saud Univ.-Comput. Inform. Sci., 10 (2018). |
| [81] | S. J. Mousavirad, H. Ebrahimpour-Komleh, Feature selection using modified imperialist competitive algorithm, in ICCKE 2013, IEEE, (2013), 400-405. |
| [82] | A. Keramati, M. Hosseini, M. Darzi, A. A. Liaei, Cultural algorithm for feature selection, in The 3rd International Conference on Data Mining and Intelligent Information Technology Applications, IEEE, (2011), 71-76. |
| [83] |
D. H. Wolpert, W. G. Macready, No free lunch theorems for optimization, IEEE Trans. Evol. Comput., 1 (1997), 67-82. doi: 10.1109/4235.585893
|
| [84] |
A. Fink, S. Vo, Solving the continuous flow-shop scheduling problem by metaheuristics, Eur. J. Oper. Res., 151 (2003), 400-414. doi: 10.1016/S0377-2217(02)00834-2
|
| [85] | J. Kennedy, R. C. Eberhart, A discrete binary version of the particle swarm algorithm, in 1997 IEEE International conference on systems, man, and cybernetics. Computational cybernetics and simulation, IEEE, 5 (1997), 4104-4108. |
| [86] |
E. Rashedi, H. Nezamabadi-Pour, S. Saryazdi, BGSA: binary gravitational search algorithm, Nat. Comput., 9 (2010), 727-745. doi: 10.1007/s11047-009-9175-3
|
| [87] | N. S. Altman, An introduction to kernel and nearest-neighbor nonparametric regression, Am. Stat., 46 (1992), 175-185. |
| [88] |
F. Pernkopf, Bayesian network classifiers versus selective k-NN classifier, Pattern Recogn., 38 (2005), 1-10. doi: 10.1016/j.patcog.2004.05.012
|
| [89] | A. Asuncion, D. Newman, UCI Machine Learning Repository, University of California, 2007. |
| [90] |
E. Emary, H. M. Zawbaa, A. E. Hassanien, Binary ant lion approaches for feature selection, Neurocomputing, 213 (2016), 54-65. doi: 10.1016/j.neucom.2016.03.101
|
| [91] | Arizona State University's (ASU) repository, Available from: http://featureselection.asu.edu/datasets.php. |
| [92] |
A. I. Hammouri, M. Mafarja, M. A. Al-Betar, M. A. Awadallah, I. Abu-Doush, An improved Dragonfly Algorithm for feature selection, Knowl.-Based Syst., 203 (2020), 106131. doi: 10.1016/j.knosys.2020.106131
|
| [93] |
H. Faris, M. M. Mafarja, A. A. Heidari, I. Aljarah, A. M. Al-Zoubi, S. Mirjalili, et al., An Efficient Binary Salp Swarm Algorithm with Crossover Scheme for Feature Selection Problems, Knowl.-Based Syst., 154 (2018), 43-67. doi: 10.1016/j.knosys.2018.05.009
|
| [94] |
M. Mafarja, S.Mirjalili, Whale optimization approaches for wrapper feature selection, Appl. Soft Comput., 62 (2018), 441-453. doi: 10.1016/j.asoc.2017.11.006
|
| [95] |
M. Mafarja, I. Aljarah, H. Faris, A. I. Hammouri, A. M. Al-Zoubi, S. Mirjalili, Binary grasshopper optimisation algorithm approaches for feature selection problems, Expert Syst. Appl., 117 (2019), 267-286. doi: 10.1016/j.eswa.2018.09.015
|
| [96] |
E. Emary, H. M. Zawbaa, A. E. Hassanien, Binary grey wolf optimization approaches for feature selection, Neurocomputing, 172 (2016), 371-381. doi: 10.1016/j.neucom.2015.06.083
|
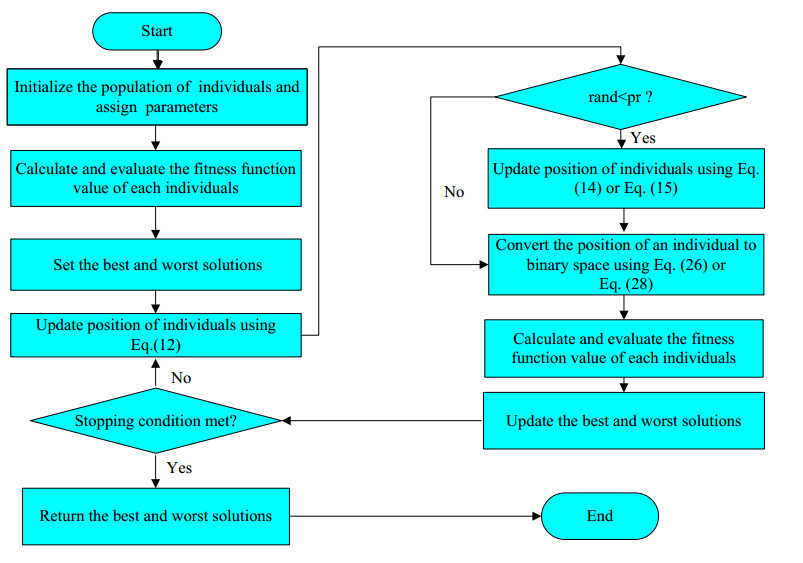
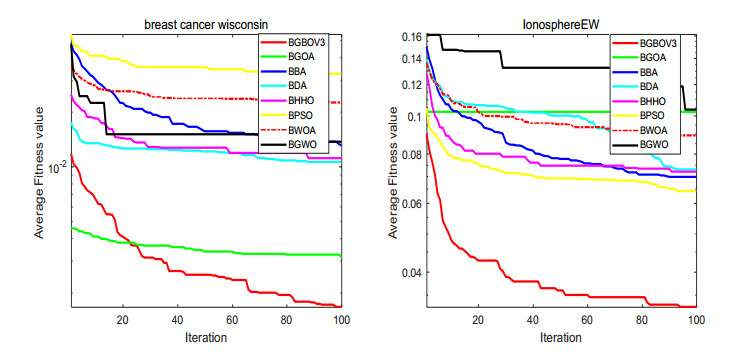
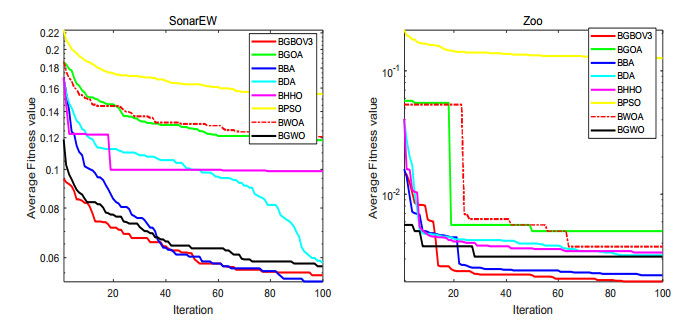
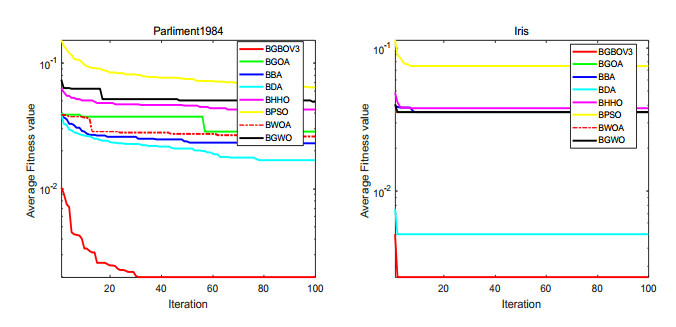
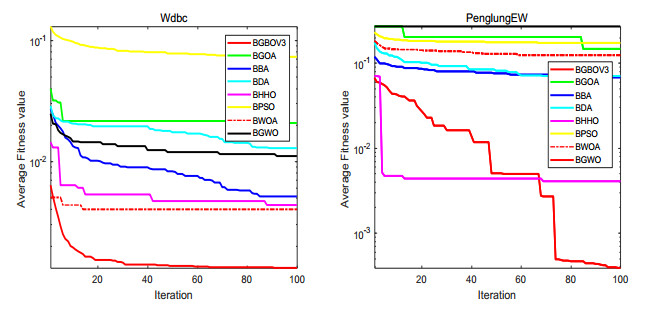
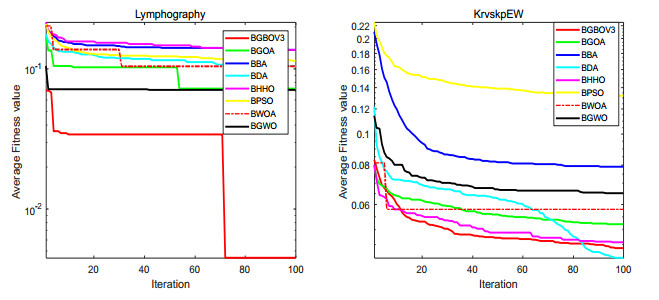
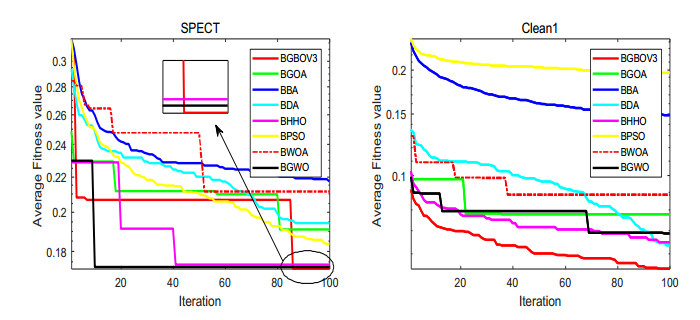
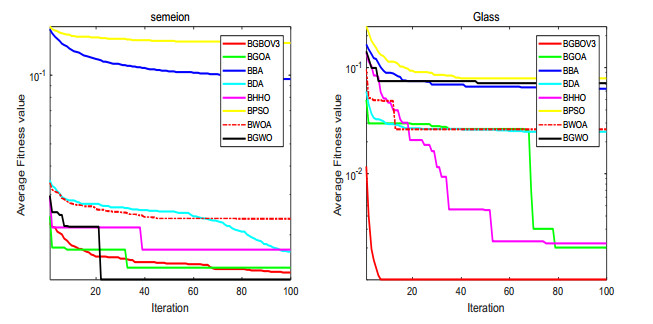
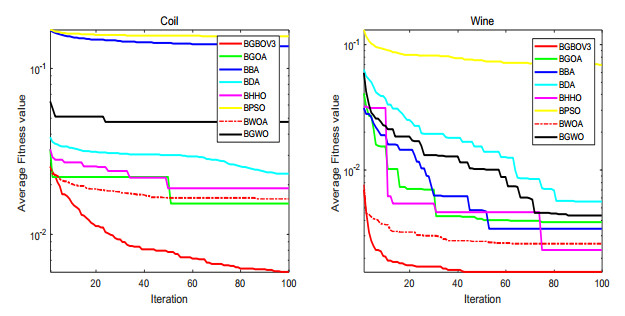
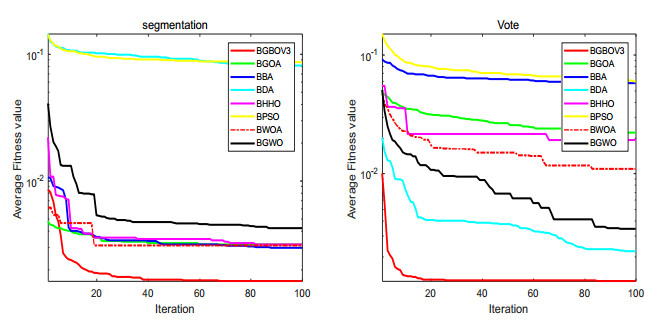
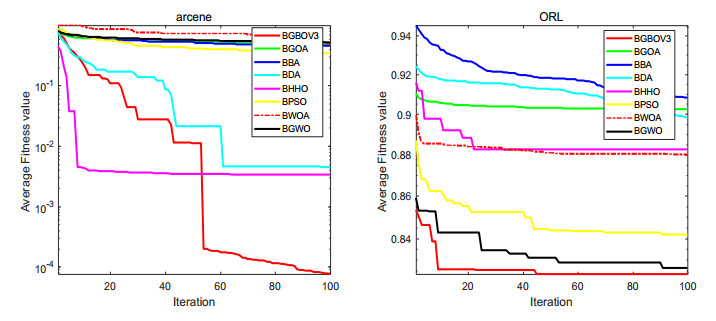
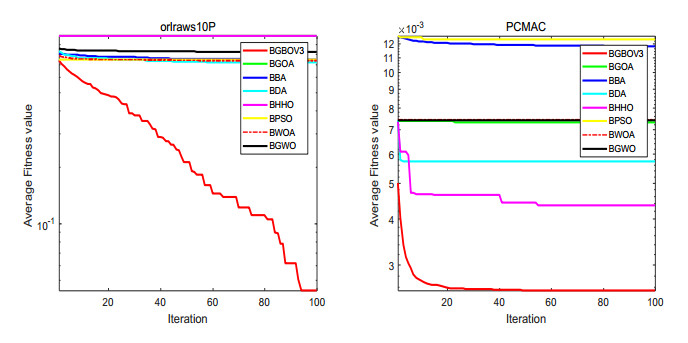
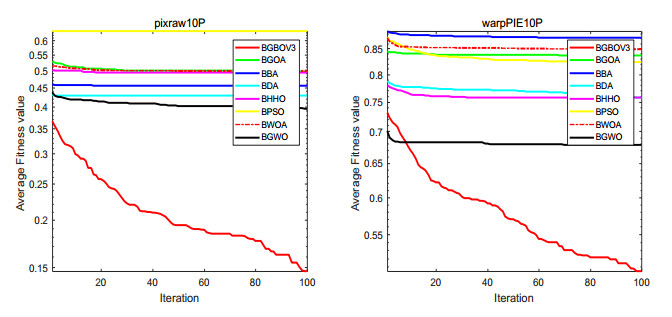
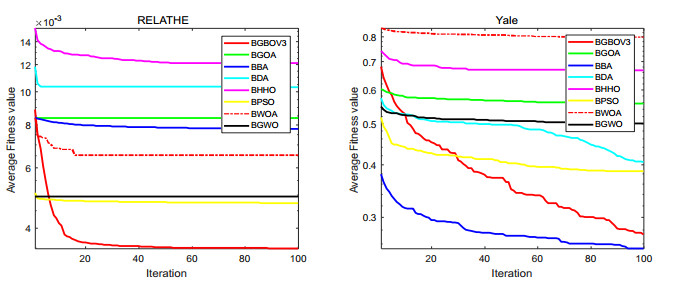
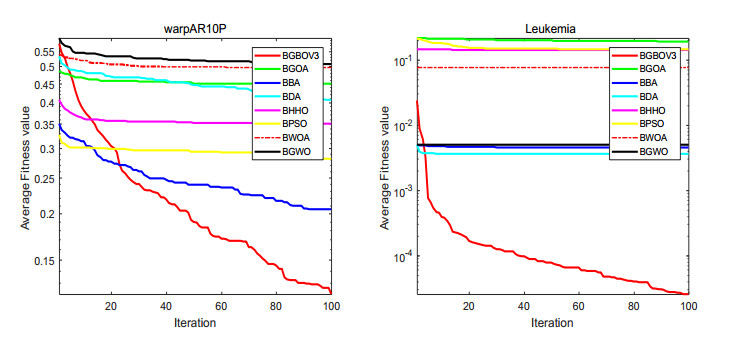
Figures(15) / Tables(18)

Yugui Jiang, Qifang Luo, Yuanfei Wei, Laith Abualigah, Yongquan Zhou. An efficient binary Gradient-based optimizer for feature selection[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 3813-3854. doi: 10.3934/mbe.2021192







 DownLoad:
DownLoad: