Citation: Damilola Olabode, Libin Rong, Xueying Wang. Optimal control in HIV chemotherapy with termination viral load and latent reservoir[J]. Mathematical Biosciences and Engineering, 2019, 16(2): 619-635. doi: 10.3934/mbe.2019030

| [1] | B. M. Adams, H. T. Banks, M. Davidian, H. D. Kwon, H. T. Tran, S. N. Wynne and E. S. Rosenberg, HIV dynamics: modeling, data analysis, and optimal treatment protocols, J. Comput. Appl. Math., 185 (2005), 10–49. |
| [2] | S. Alizon and C. Magnus, Modeling the course of HIV infection: Insight from ecology and evolution, Viruses, 4 (2012), 1984–2013. |
| [3] | E. J. Arts and D. J. Hazuda, HIV-1 antiretroviral drug therapy, Cold Spring Harb. Perspect. Med., 2 (2012), a007161. |
| [4] | E. Asano, L. J. Gross, S. Lenhart and L. A. Real, Optimal control of vaccine distribution in a rabies metapopulation model, Math. Biosci. Eng., 5 (2008), 219–238. |
| [5] | K. Brinkman, H. J. M.Ter Hofstede, D. M. Burger, J. A. M. Smeitink and P. P. Koopmans, Adverse effects of reverse transcriptase inhibitors: mitochondrial toxicity as common pathway, AIDS, 12 (1998), 1735–1744. |
| [6] | D. S. Callaway and A. S. Perelson, HIV-1 infection and low steady state viral loads, Bull. Math. Biol., 64 (2002), 29–64. |
| [7] | T. W. Chun, L. Stuyver, S. B. Mizell, L. A. Ehler, J. A. Mican, M. Baseler, A. L. Lloyd, M. A. Nowak and A. S. Fauci, Presence of an inducible HIV-1 latent reservoir during highly active antiretroviral therapy, Proc. Natl. Acad. Sci. USA, 94 (1997), 13193–13197. |
| [8] | J. M. Conway and A. S. Perelson, Post-treatment control of HIV infection, Proc. Natl. Acad. Sci. USA, 112 (2015), 5467–5472. |
| [9] | A. M. Croicu, Short and long term optimal control of a mathematical model for HIV infection of CD4+ T cells, Bull. Math. Biol., 77 (2015), 2035–2071. |
| [10] | N. Dorratoltaj, R. Nikin-Beers, S. M. Ciupe, S. G. Eubank and K. M. Abbas, Multi-scale immunoepidemiological modeling of within-host and between-host HIV dynamics: systematic review of math model, Peer J, 5 (2017), e3877. |
| [11] | D. Finzi, M. Hermankova, T. Pierson, L. M. Carruth, C. Buck, R. E. Chaisson, T. C. Quinn, K. Chadwick, J. Margolick, R. Brookmeyer, J. Gallant, M. Markowitz, D. D. Ho, D. D. Richman and R. F. Siliciano, Identification of a reservoir for HIV-1 in patients on highly active antiretroviral therapy, Science, 278 (1997), 1295–1300. |
| [12] | K. R. Fister, S. Lenhart and J. McNally, Optimizing chemotherapy in an HIV model, Electron. J. Differ. Equ., 32 (1998), 1–12. |
| [13] | W. H. Fleming and R. W. Rishel, Deterministic and stochastic optimal control, 1st edition, Springer-Verlag, New York, 1975. |
| [14] | W. K. Hackbush, A numerical method for solving parabolic equations in opposite orientations, Computing, 20 (1978), 229–240. |
| [15] | H. R. Joshi, Optimal control of an HIV immunology model, Optim. Control Appl. Methods, 23 (2002), 199–213. |
| [16] | J. Karrakchou, M. Rachik and S. Gourari, Optimal control and infectiology: Application to an HIV/AIDS model, Appl. Math. Comput., 177 (2006), 807–818. |
| [17] | D. Kirshner, S. Lenhart and S. Serbin, Optimal control of the chemotherapy of HIV, J. Math. Biol., 35 (1997), 775–792. |
| [18] | H. Mohri, S. Bonhoeffer, S. Monard, A. S. Perelson and D. D. Ho, Rapid turnover of T lymphocytes in SIV-infected rhesus macaques, Science 279 (1998), 1223–1227. |
| [19] | D. Morgan, C. Mahe, B. Mayanja, J. Okongo and R. Lubega, HIV-1 infection in rural Africa: Is there a difference in median time to aids and survival compared with that in industrialized countries?, AIDS, 16 (2002), 597–632. |
| [20] | M. J. Pace, L. Agosto, E. H. Graf and U. O'Doherty, HIV reservoirs and latency models, Virology, 411 (2011), 344–354. |
| [21] | S. Pankavish, The effects of latent Infection on the dynamics of HIV, Differ. Equ. Dyn. Syst., 24 (2016), 281–303. |
| [22] | A. Pegu, M. Asokan, L. Wu, K. Wang, Activation and lysis of Human CD4 cells latently infected with HIV-1, Nat. Commun., 6 (2015). |
| [23] | A. S. Perelson and P. Nelson, Mathematical analysis of HIV–1 in vivo, SIAM Rev., 41 (1998), 3–44. |
| [24] | A. S. Perelson, D. E. Kirschner and R. D. Boer, Dynamics of HIV infection CD4 T cells, Math. Biosci., 114 (1993), 81–125. |
| [25] | N. Perera, Deterministic and stochastic models of virus dynamics, Ph.D. Thesis, Texas Tech University, 2003. |
| [26] | L. S. Pontryagin, V. G. Boltyanskii, R. V. Gamkrelidze and E. F. Mishchenko, The mathematical theory of optimal processes, 1st edition, John Wiley, 1962. |
| [27] | L. Rong and A. S. Perelson, Modeling latently infected cell activation: Viral and latent reservoir persistence, and viral blips in HIV-infected patients on potent therapy, PLoS Comput. Biol., 5(10) (2009), 1000533. |
| [28] | L. Rong and A. S. Perelson, Modeling HIV persistence, the latent reservoir, and viral blips, J. Theort. Biol., 260 (2009), 308–331. |
| [29] | L. Rong and A. S. Perelson, Asymmetric division of activated latently infected cells may explain the decay kinetics of the HIV-1 latent reservoir and intermittent viral blip, Math. Biosci., 217 (2009), 77–87. |
| [30] | M. Roshanfekr, M. H. Farahi and R. Rahbarian, A different approach of optimal control on an HIV immunology model, Ain. Shams. Eng. J., 5 (2014), 213–219. |
| [31] | R. F. Siliciano and W. C. Greene, HIV latency, Cold Spring Harb. Perspect. Med., 1 (2011), a007096. |
| [32] | L. E. Jones, A. S. Perelson, Transient viremia, plasma viral load, and reservoir replenishment in HIV-infected patients on antiretroviral therapy. J Acquir. Immune. Defic. Syndr., 45 (2007), 483–493. |
| [33] | U.S. Department of health and human services AIDSinfo, Antiretroviral Therapy-Associated Common and/or Severe Adverse Effects, Available from: https://aidsinfo.nih.gov/ guidelines/htmltables/1/5551 |
| [34] | X. Wang, S. Tang, X. Song and L. Rong, Mathematical analysis of an HIV latent infection model including both virus-to-cell infection and cell-to-cell transmission, J. Biol. Dynam., 11(sup2) (2016), 455–483. |
| [35] | M. Markowitz, M. Louie, A. Hurley, E. Sun, M. Di Mascio, A. S. Perelson and D. D. Ho, A novel antiviral intervention results in more accurate assessment of human immunodeficiency virus type 1 replication dynamics and T-cell decay in vivo, J. Virol., 77 (2003), 5037–5038. |
| [36] | B. Ramratnam, S. Bonhoeffer, J. Binley, A. Hurley, L. Zhang, J. E. Mittler, M. Markowitz, J. P. Moore, A. S. Perelson and D. D. Ho, Rapid production and clearance of HIV-1 and hepatitis C virus assessed by large volume plasma apheresis. Lancet, 354 (1999), 1782–1785. |
| [37] | H. Kim and A. S. Perelson. Viral and latent reservoir persistence in HIV-1- infected patients on therapy, PLoS Comput. Biol., 2 (2006), e135. |
| [38] | J. K. Wong, M. Hezareh, H. F. Gunthard, D. V. Havlir, C. C. Ignacio, C. A. Spina and D. D. Richman, Recovery of replication-competent HIV despite prolonged suppression of plasma viremia, Science, 278 (1997), 1291–1295. |
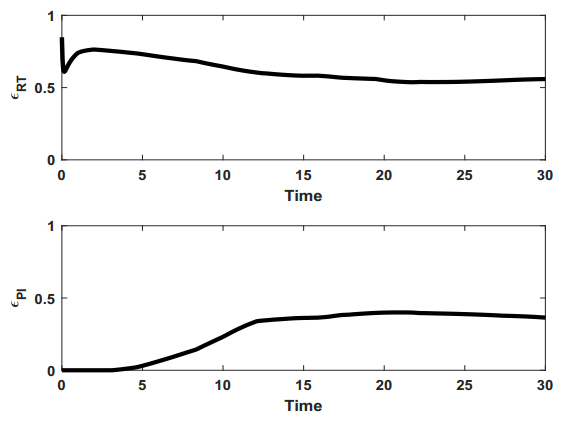
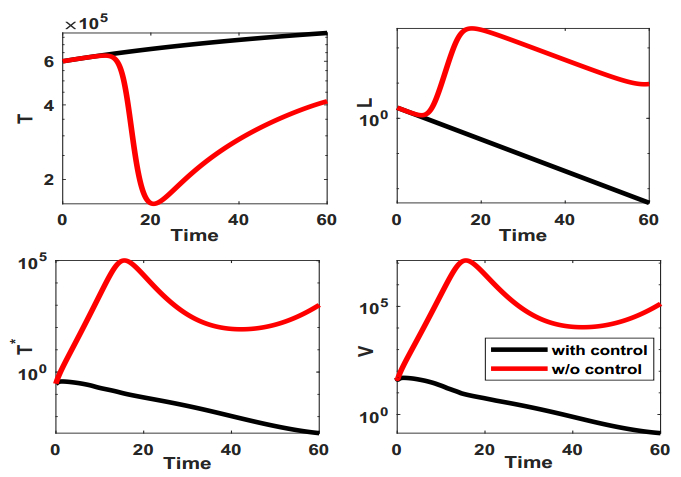
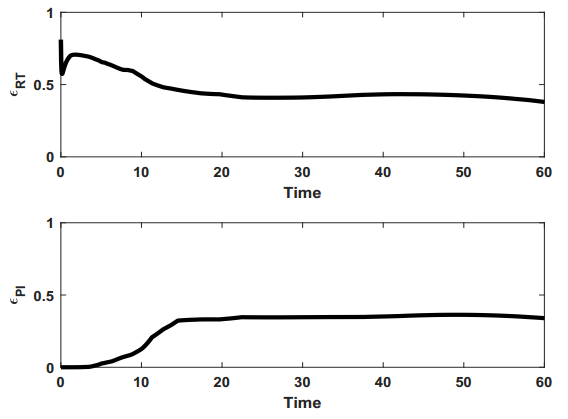
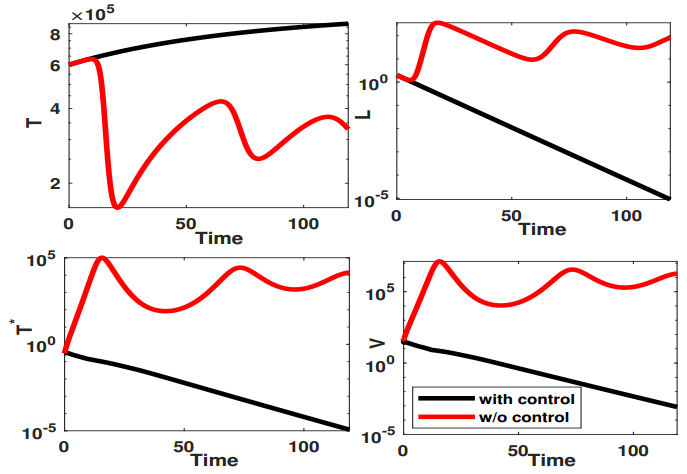
Figures(9) / Tables(1)

Damilola Olabode, Libin Rong, Xueying Wang. Optimal control in HIV chemotherapy with termination viral load and latent reservoir[J]. Mathematical Biosciences and Engineering, 2019, 16(2): 619-635. doi: 10.3934/mbe.2019030







 DownLoad:
DownLoad: