Citation: Minglong Zhang, Iek Cheong Lam, Arun Kumar, Kin Kee Chow, Peter Han Joo Chong. Optical environmental sensing in wireless smart meter network[J]. AIMS Electronics and Electrical Engineering, 2018, 2(3): 103-116. doi: 10.3934/ElectrEng.2018.3.103

| [1] |
Mahmood A, Javaid N and Razzaq S (2015) A review of wireless communications for smart grid. Renew Sust Energ Rev 41: 248–260. doi: 10.1016/j.rser.2014.08.036

|
| [2] |
Yick J, Mukherjee B, Ghosal D (2008) Wireless sensor network survey. Comput Netw 52: 2292–2330. doi: 10.1016/j.comnet.2008.04.002
|
| [3] |
Pakzad SN, Fenves GL, Kim S, et al. (2008) Design and Implementation of Scalable Wireless Sensor Network for Structural Monitoring. J Infrastruct Syst 14: 89–101. doi: 10.1061/(ASCE)1076-0342(2008)14:1(89)
|
| [4] |
Li X, Cheng X, Yan K, et al. (2010) A Monitoring System for Vegetable Greenhouses based on a Wireless Sensor Network. Sensors 10: 8963–8980. doi: 10.3390/s101008963
|
| [5] |
Yeo TL, Sun T, Grattan KTV (2008) Fiber-optic sensor technologies for humidity and moisture measurement. Sensor Actuat A-Phys 144: 280–295. doi: 10.1016/j.sna.2008.01.017
|
| [6] |
Culshaw B (2004) Optical Fiber Sensor Technologies: Opportunities and Perhaps Pitfalls. J Lightwave Technol 22: 39–50. doi: 10.1109/JLT.2003.822139
|
| [7] | O'Connell E, Healy M, OKeeffe S, et al. (2013) A Mote Interface for Fiber Optic Spectral Sensing With Real-Time Monitoring of the Marine Environment. IEEE Sens J 13: 2619–2625. |
| [8] |
Lloyd SW, Newman JA, Wilding DR, et al. (2007) Compact optical fiber sensor smart node. Rev Sci Instrum 78: 35108. doi: 10.1063/1.2715994
|
| [9] | Kuang KSC, Quek ST, Maalej M (2008) Remote flood monitoring system based on plastic optical fibers and wireless motes. Sensor Actuat A-Phys 147: 449–455. |
| [10] |
Pang C, Yu M, Zhang XM, et al. (2012) Multifunctional optical MEMS sensor platform with heterogeneous fiber optic Fabry–Pérot sensors for wireless sensor networks. Sensor Actuat A-Phys 188: 471–480. doi: 10.1016/j.sna.2012.03.016
|
| [11] | Tan YC, Ji WB, Mamidala V, et al. (2014) Carbon-nanotube-deposited long period fiber grating for continuous refractive index sensor applications. Sensor Actuat B-Chem 196: 260–264. |
| [12] | Tan YC, Tou ZQ, Mamidala V, et al. (2014) Continuous refractive index sensing based on carbon-nanotube-deposited photonic crystal fibers. Sensor Actuat B-Chem 202: 1097–1102. |
| [13] |
Tan YC, Tou ZQ, Chow KK, et al. (2015) Graphene-deposited photonic crystal fibers for continuous refractive index sensing applications. Opt Express 23: 31286–31294. doi: 10.1364/OE.23.031286
|
| [14] |
Nicholson JW, Windeler RS, DiGiovanni DJ (2007) Optically driven deposition of single-walled carbon-nanotube saturable absorbers on optical fiber end-faces. Opt Express 15: 9176–9183. doi: 10.1364/OE.15.009176
|
| [15] | Kashiwagi K, Yamashita S, Set SY (2009) In-situ monitoring of optical deposition of carbon nanotubes onto fiber end. Opt Express 17: 5711–5715. |
| [16] |
Yamashita S (2012) A Tutorial on Nonlinear Photonic Applications of Carbon Nanotube and Graphene. J Lightwave Technol 30: 427–447. doi: 10.1109/JLT.2011.2172574
|
| [17] | Lee H, Shaker G, Naishadham K, et al. (2011) Carbon-nanotube loaded antenna-based ammonia gas sensor. IEEE T Microw Theory 59: 2665–2673. |
| [18] |
Kruss S, Hilmer AJ, Zhang JQ, et al. (2013) Carbon nanotubes as optical biomedical sensors. Adv Drug Deliver Rev 65: 1933–1950. doi: 10.1016/j.addr.2013.07.015
|
| [19] | The Network Simulator tool: ns-3. Available from: https://www.nsnam.org/. |
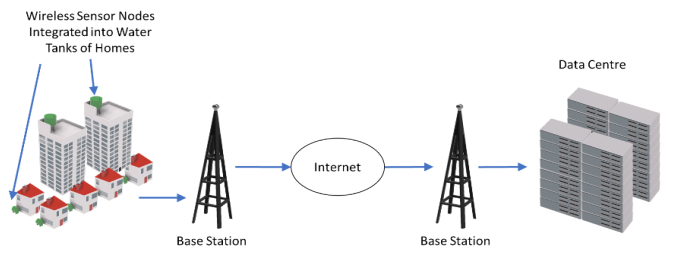
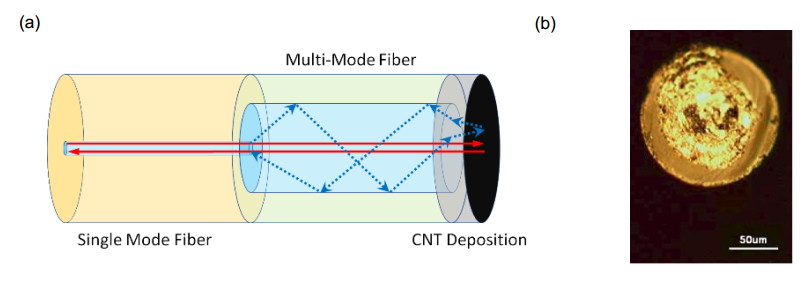
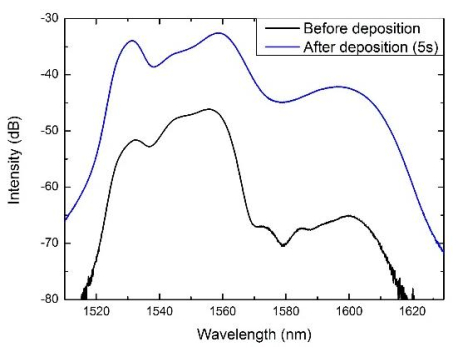
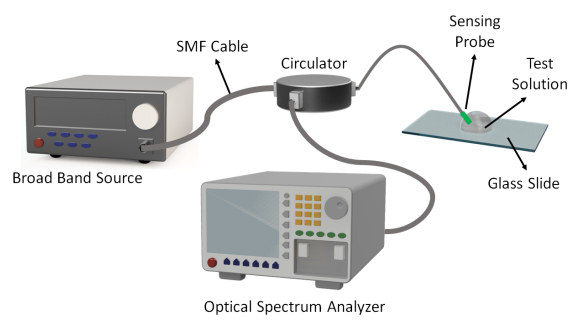
Figures(10) / Tables(1)

Minglong Zhang, Iek Cheong Lam, Arun Kumar, Kin Kee Chow, Peter Han Joo Chong. Optical environmental sensing in wireless smart meter network[J]. AIMS Electronics and Electrical Engineering, 2018, 2(3): 103-116. doi: 10.3934/ElectrEng.2018.3.103







 DownLoad:
DownLoad: