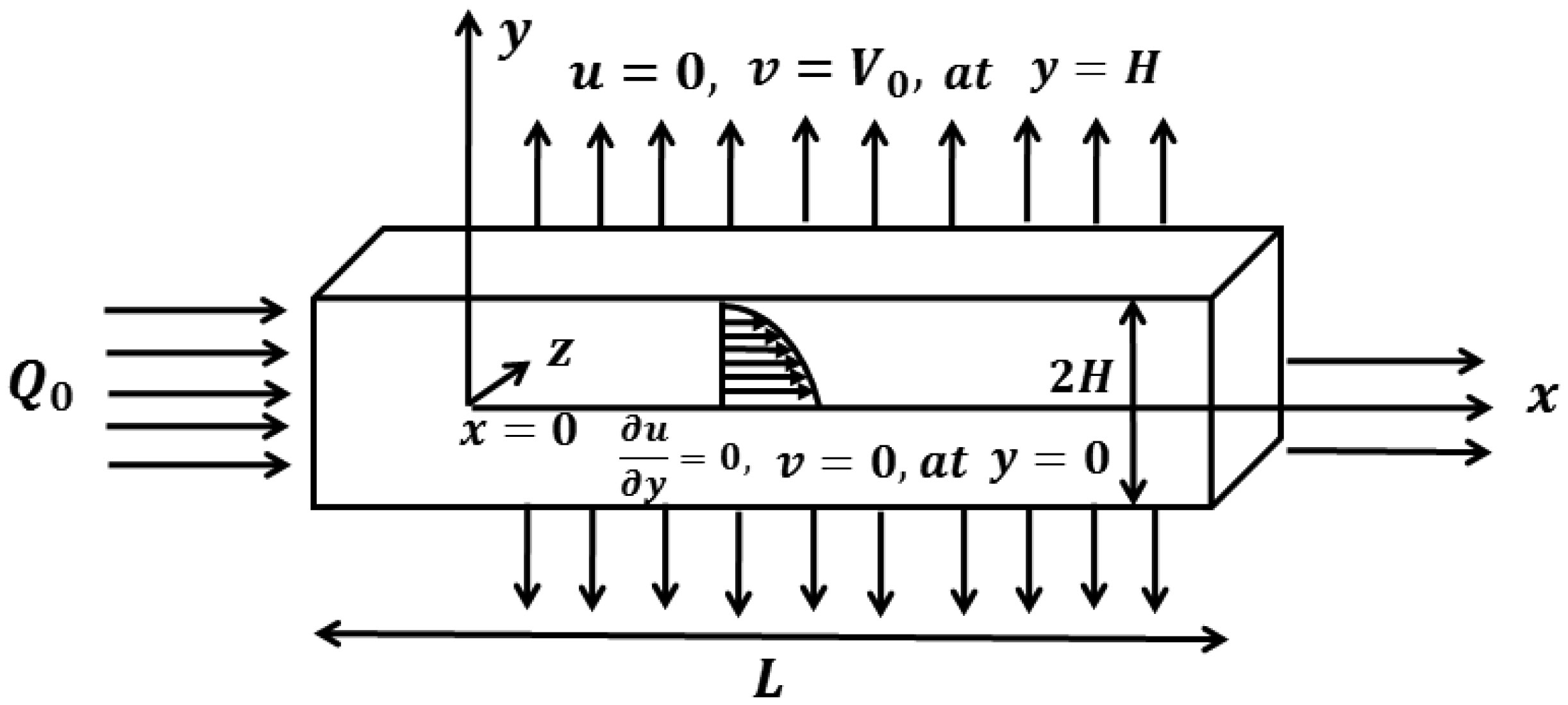
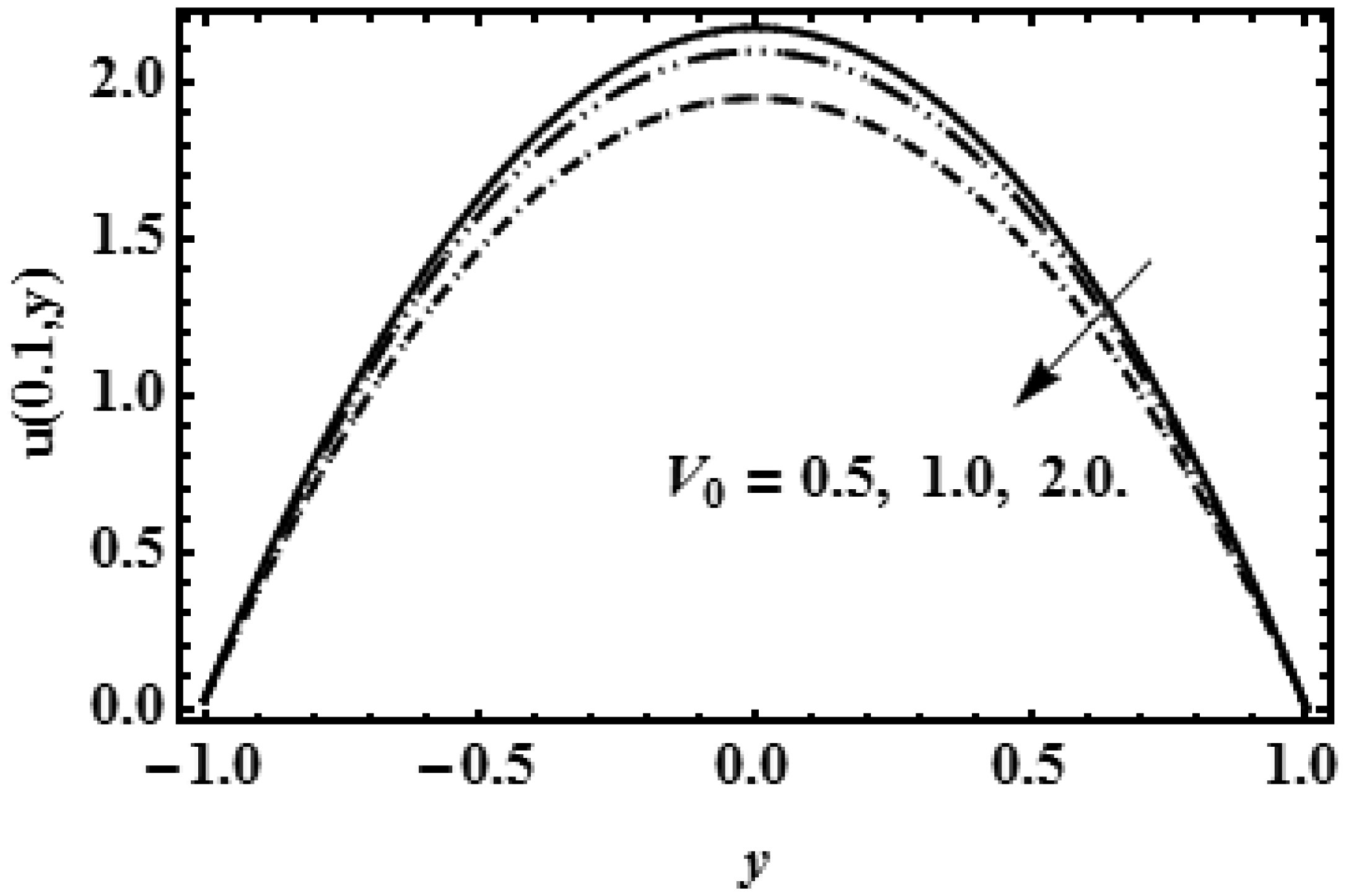
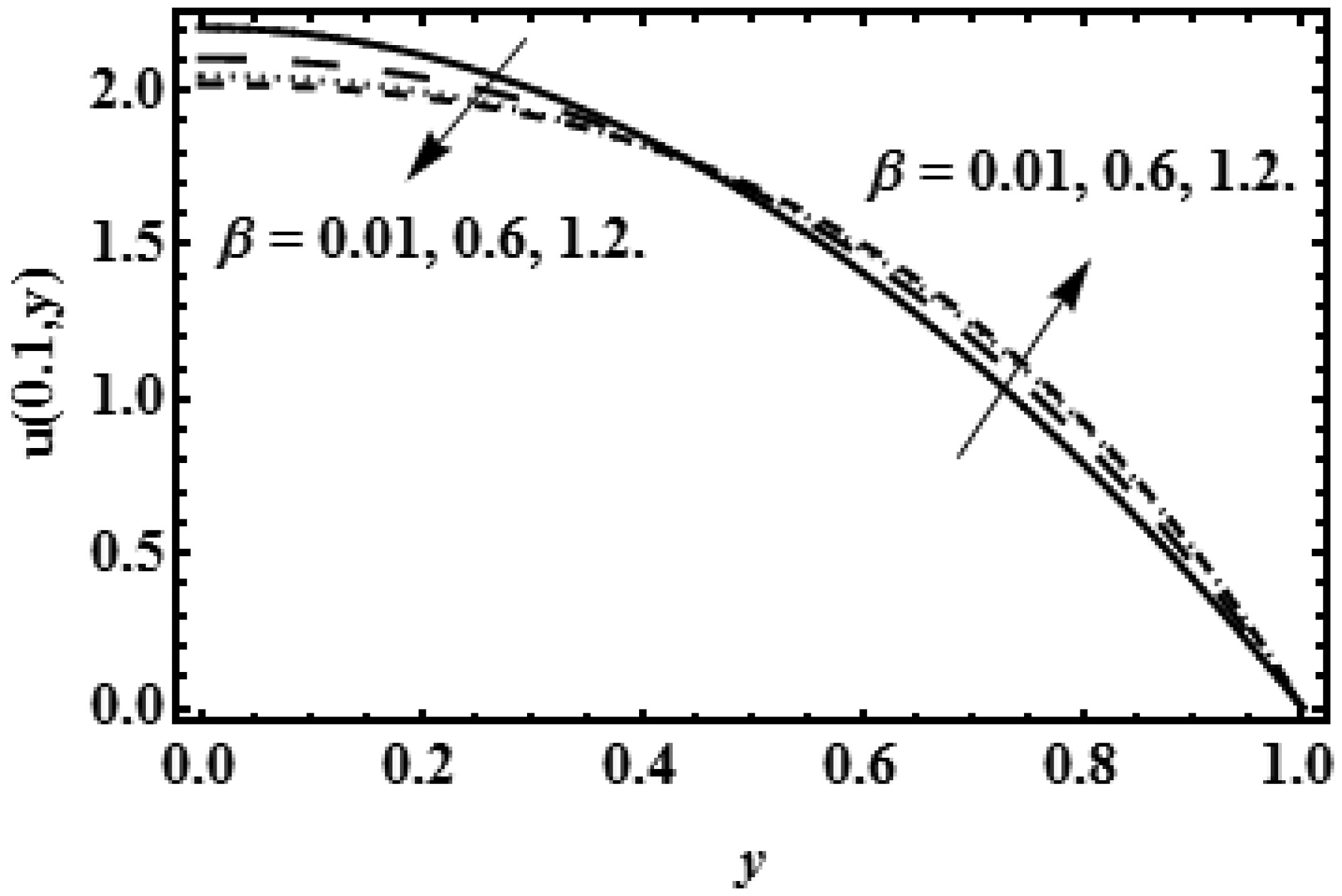
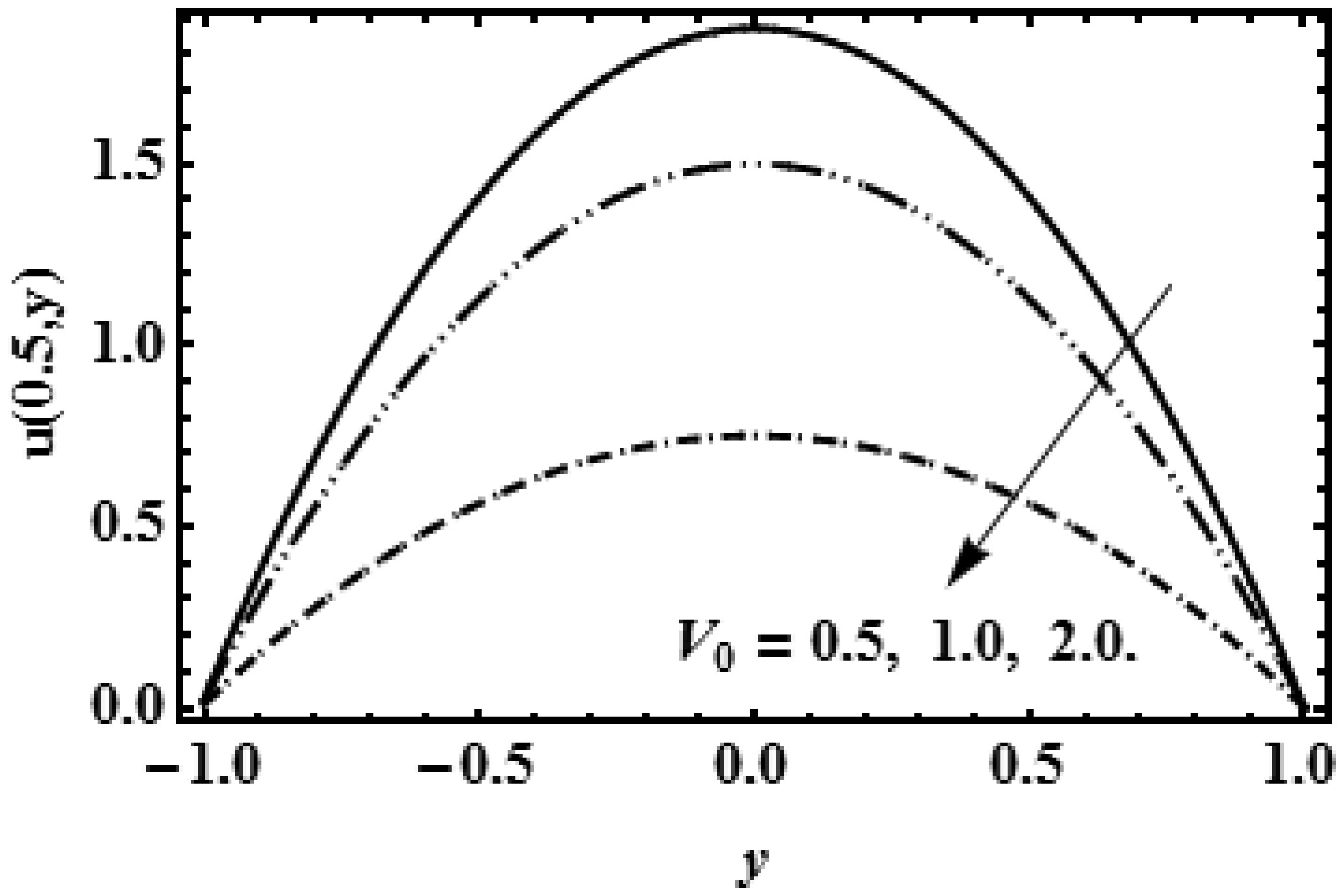
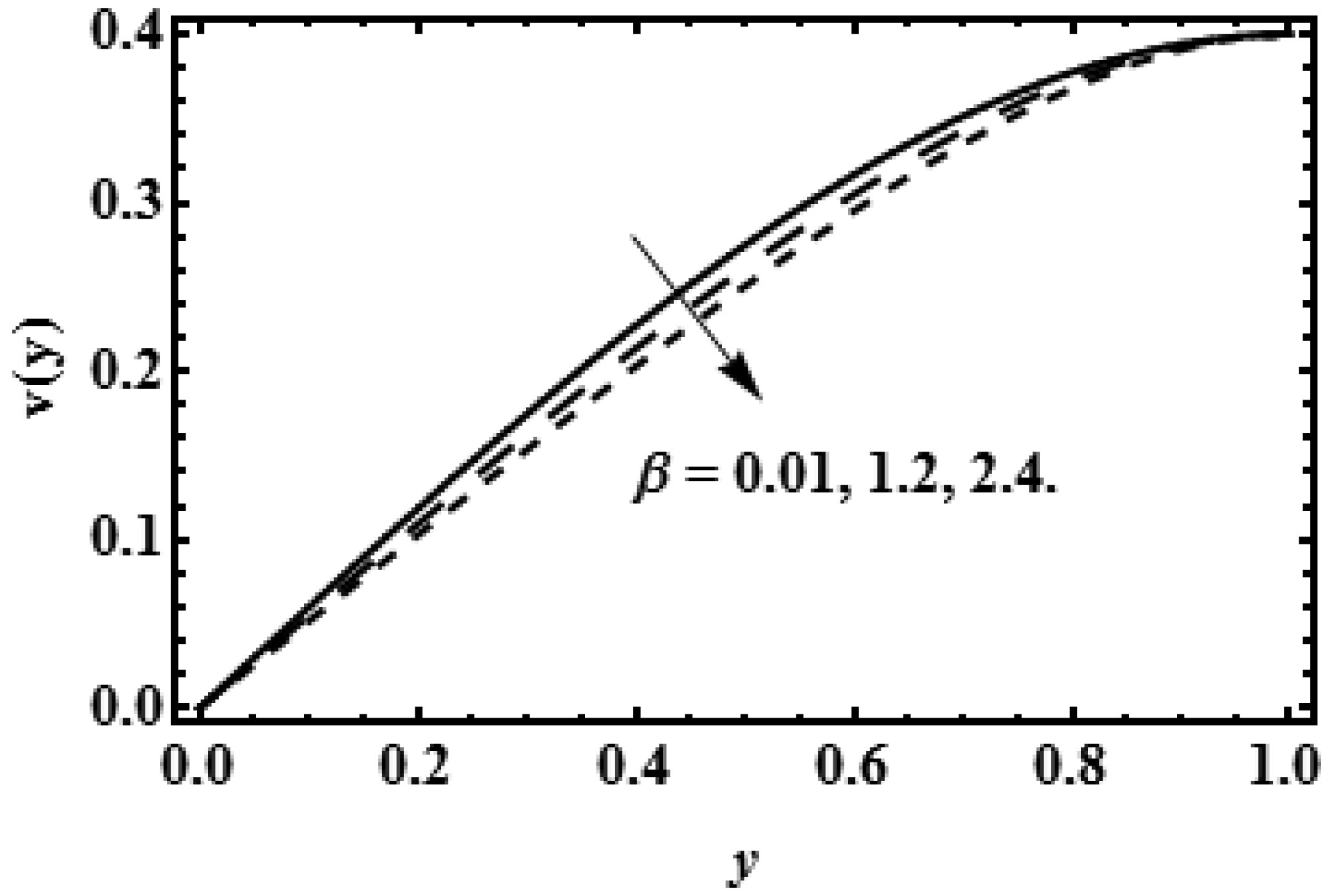
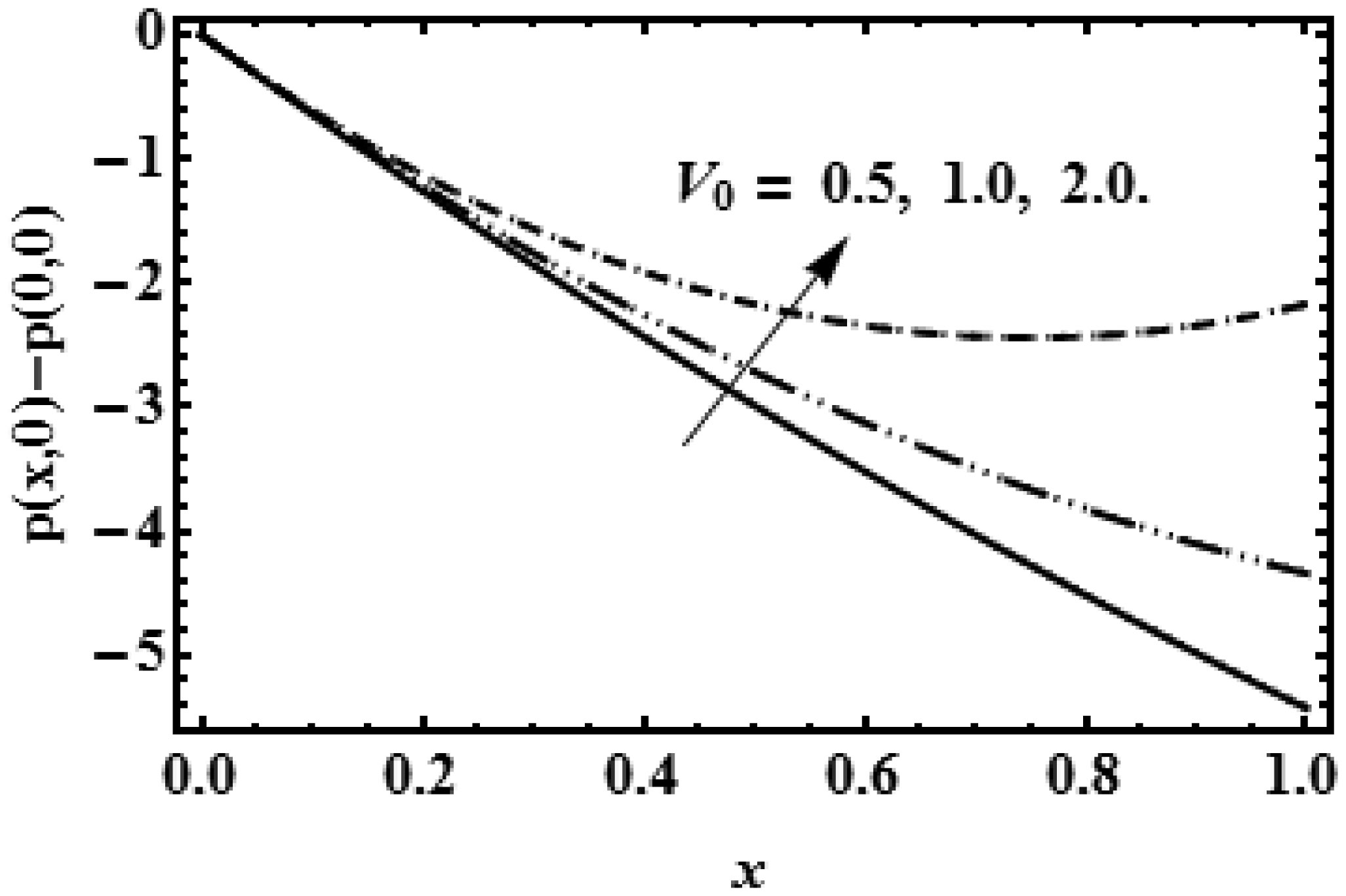
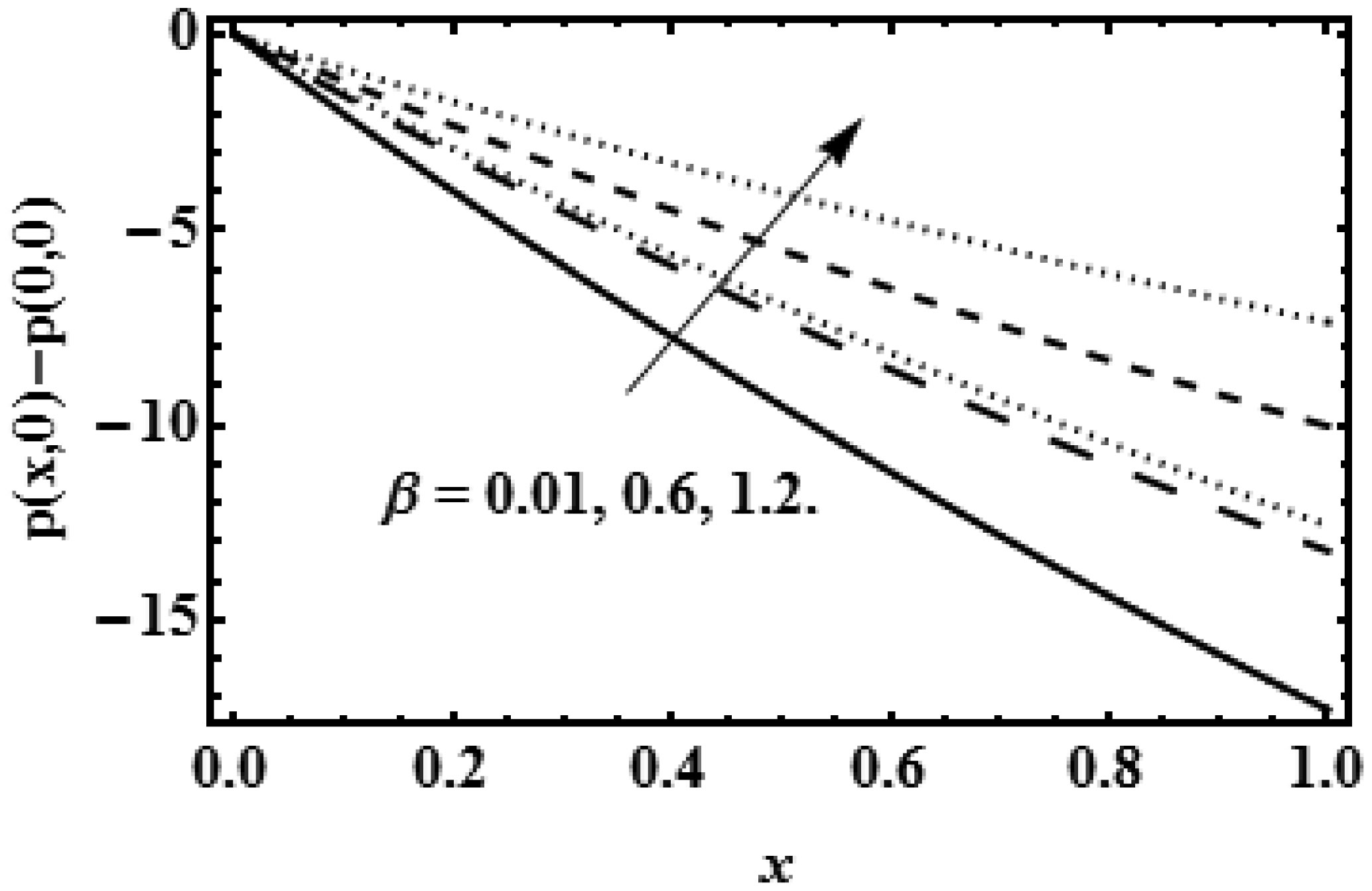
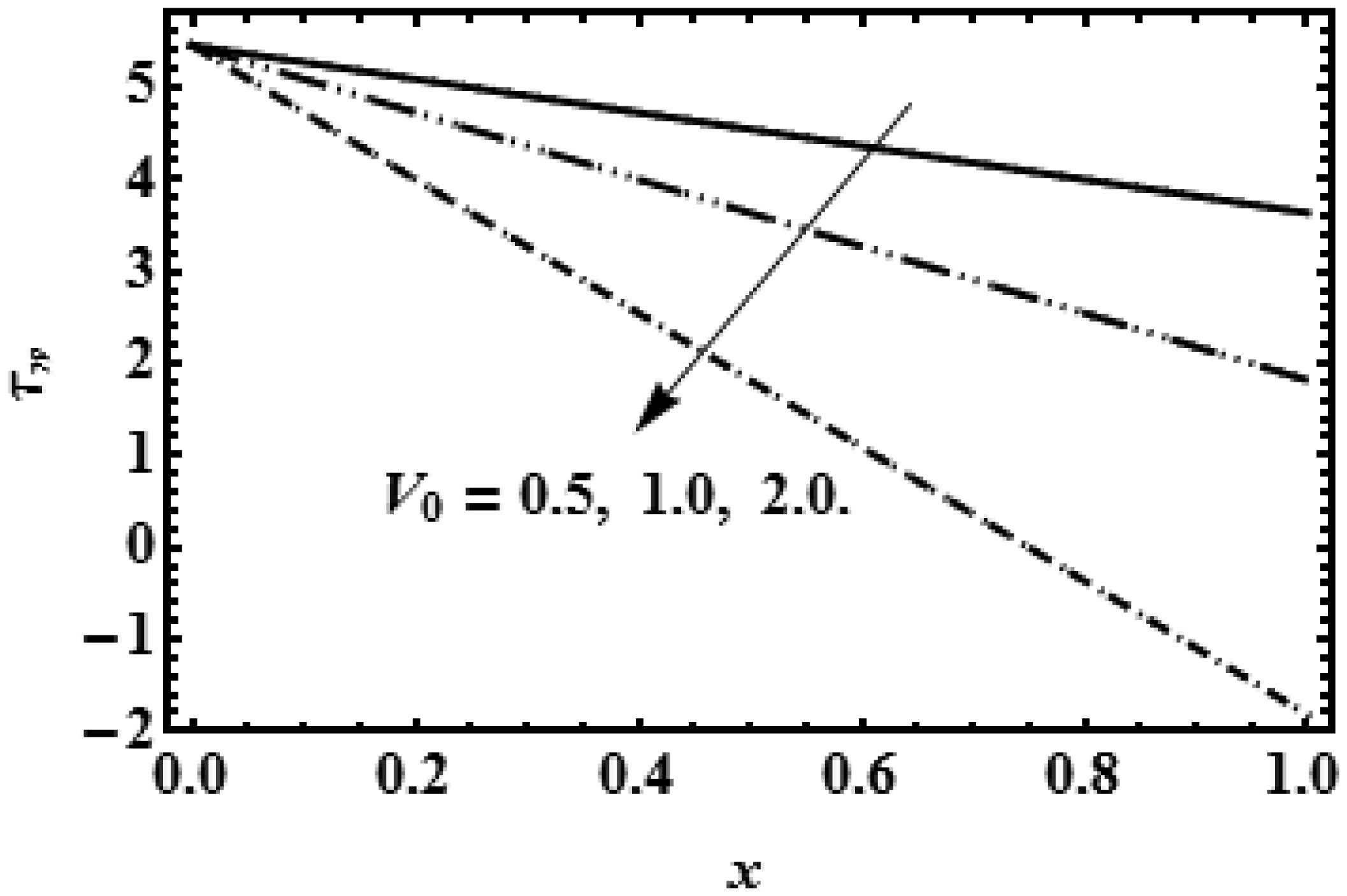
The idea of this study is to present the mathematical model of two-dimensional biofluid flow having variable viscosity along the height of the channel (proximal renal tube of artificial kidney). This research describes that flow resistance is dependent on the height of the channel (proximal renal tube of artificial kidney) which makes the high flow near the centre and slow near the wall. The goal of this research is to provide the formulas to find the flow speed, average pressure, outflow flux and filtration rate of the viscous fluid having variable viscosity. The complex mathematical problem is solved by the Inverse method and results for axial velocity are plotted at the opening, central and departure region of the conduit. The numerical values for constant reabsorption and mean pressure are calculated against the filtration rate for the constant and variable viscosity. The numerical results of pressure rise show that when the viscosity of biofluid varies from centre to the boundary, then high change in pressure is required as compared with the biofluid having constant viscosity along the height of the slit. These mathematical formulas are very useful for the bioengineers to design the portable artificial kidney which works as a mechanical tool to filter the biofluid.
Citation: Khadija Maqbool, Hira Mehboob, Abdul Majeed Siddiqui. Impact of viscosity on creeping viscous fluid flow through a permeable slit: a study for the artificial kidneys[J]. AIMS Biophysics, 2022, 9(4): 308-329. doi: 10.3934/biophy.2022026
The idea of this study is to present the mathematical model of two-dimensional biofluid flow having variable viscosity along the height of the channel (proximal renal tube of artificial kidney). This research describes that flow resistance is dependent on the height of the channel (proximal renal tube of artificial kidney) which makes the high flow near the centre and slow near the wall. The goal of this research is to provide the formulas to find the flow speed, average pressure, outflow flux and filtration rate of the viscous fluid having variable viscosity. The complex mathematical problem is solved by the Inverse method and results for axial velocity are plotted at the opening, central and departure region of the conduit. The numerical values for constant reabsorption and mean pressure are calculated against the filtration rate for the constant and variable viscosity. The numerical results of pressure rise show that when the viscosity of biofluid varies from centre to the boundary, then high change in pressure is required as compared with the biofluid having constant viscosity along the height of the slit. These mathematical formulas are very useful for the bioengineers to design the portable artificial kidney which works as a mechanical tool to filter the biofluid.

| [1] |
Burgen ASV (1956) A theoretical treatment of glucose reabsorption in the kidney. Can J Biochem Phys 34: 466-474. https://doi.org/10.1139/y56-048 
|
| [2] |
Macey RI (1965) Hydrodynamics in the renal tubule. Bull Math Biophys 27: 117-124. https://doi.org/10.1007/BF02498766
|
| [3] |
Marshall EA, Trowbridge EA (1974) Flow of a Newtonian fluid through a permeable tube: the application to the proximal renal tubule. Bull Math Biol 36: 457-476. https://doi.org/10.1007/BF02463260
|
| [4] |
Berkstresser BK, El-Asfouri S, McConnell JR, et al. (1979) Identification techniques for the renal function. Math Biosci 44: 157-165. https://doi.org/10.1016/0025-5564(79)90078-6
|
| [5] |
Tewarson RP (1981) On the use of Simpson's rule in renal models. Math Biosci 55: 1-5. https://doi.org/10.1016/0025-5564(81)90009-2
|
| [6] |
Gupta S, Tewarson RP (1983) On accurate solution of renal models. Math Biosci 65: 199-207. https://doi.org/10.1016/0025-5564(83)90061-5
|
| [7] | Ahmad S, Ahmad N (2011) On flow through renal tubule in case of periodic radial velocity component. Int J Emerg Multidiscip Fluid Res 3: 201-208. https://doi.org/10.1260/1756-8315.3.4.201 |
| [8] |
Muthu P, Berhane T (2011) Flow of Newtonian fluid in non-uniform tubes with application to renal flow: a numerical study. Adv Appl Math Mech 3: 633-648. https://doi.org/10.4208/aamm.10-m1064
|
| [9] |
Koplik J (1982) Creeping flow in two-dimensional networks. J Fluid Mech 119: 219-247. https://doi.org/10.1017/S0022112082001323
|
| [10] |
Pozrikidis C (1987) Creeping flow in two-dimensional channels. J Fluid Mech 180: 495-514. https://doi.org/10.1017/S0022112087001927
|
| [11] |
Kropinski MCA (2001) An efficient numerical method for studying interfacial motion in two-dimensional creeping flows. J Comput Phys 171: 479-508. https://doi.org/10.1006/jcph.2001.6787
|
| [12] | Haroon T, Siddiqui AM, Shahzad A (2016) Creeping flow of viscous fluid through a proximal tubule with uniform reabsorption: a mathematical study. Appl Math Sci 10: 795-807. https://doi.org/10.12988/ams.2016.512739 |
| [13] |
Gilmer GG, Deshpande VG, Chou CL, et al. (2018) Flow resistance along the rat renal tubule. Am J Physiol Renal Physiol 315: F1398-F1405. https://doi.org/10.1152/ajprenal.00219.2018
|
| [14] |
Lamport H (1943) Improvements in calculation of renal resistance to blood flow. charts for osmotic pressure and viscosity of blood. J Clin Invest 22: 461-470. https://doi.org/10.1172/JCI101416
|
| [15] |
Lamport H (1942) The effects on renal resistance to blood flow of renin, angiotonin, pitressin and atropine, hypertension, and toxemia of pregnancy. J Clin Invest 21: 685-695. https://doi.org/10.1172/JCI101345
|
| [16] |
Gaylor JDS (1973) Thin film blood flow in rectangular channels with application to artificial kidney haemodynamics. J Biomech 6: 241-251. https://doi.org/10.1016/0021-9290(73)90046-8
|
| [17] |
Omori T, Wada S, Tsubota KI, et al. (2006) Multi-scale simulation of blood flow with the dynamical behavior of elastic red blood cells. J Biomech 39: S649. http://dx.doi.org/10.1016%2FS0021-9290(06)85706-4
|
| [18] |
Helfenstein C, Gennisson JL, Tanter M, et al. (2015) Effects of pressure on the shear modulus, mass and thickness of the perfused porcine kidney. J Biomech 48: 30-37. https://doi: 10.1016/j.jbiomech.2014.11.011
|
| [19] |
Mukhopadhyay S, Mukhopadhyay A (2021) Hydrodynamic instability and wave formation of a viscous film flowing down a slippery inclined substrate: effect of odd-viscosity. Eur J Mech-B/Fluids 89: 161-170. https://doi.org/10.1016/j.euromechflu.2021.05.013
|
| [20] |
Mukhopadhyay S, Cellier N, Usha R, et al. (2022) Falling film on an anisotropic porous medium. J Fluid Mech 947: A26. https://doi.org/10.1017/jfm.2022.634
|
| [21] |
Mehboob H, Maqbool K, Siddiqui AM, et al. (2021) Mathematical analysis of viscosity and reabsorption on urine flow through a straight narrow tube. Biomed Eng-Appl Basis Commun 33: 2150039. https://doi.org/10.4015/S1016237221500393
|
| [22] |
Layton AT, Layton HE (2019) A computational model of epithelial solute and water transport along a human nephron. PLoS Comput Biol 15: e1006108. https://doi.org/10.1371/journal.pcbi.1006108
|
| [23] |
Tripathi D, Pandey SK, Siddiqui A, et al. (2014) Non-steady peristaltic propulsion with exponential variable viscosity: a study of transport through the digestive system. Computer Methods in Biomechanics and Biomedical Engineering : 591-603. https://doi.org/10.1080/10255842.2012.703660
|
| [24] |
Zhang SY, Mahler GJ (2021) Modelling renal filtration and reabsorption processes in a human glomerulus and proximal tubule microphysiological system. Micromachines 12: 983. https://doi.org/10.3390/mi12080983
|
| [25] |
Korkmaz I, Rogg B (2006) Simulation of urine flow through the male lower urinary tract. J Biomech 39: S389-S390. http://dx.doi.org/10.1016%2FS0021-9290(06)84574-4
|
| [26] |
Herranz B, Álvarez MD, Pérez-Jiménez J (2018) Association of plasma and urine viscosity with cardiometabolic risk factors and oxidative status. a pilot study in subjects with abdominal obesity. PloS One 13: e0204075. https://doi.org/10.1371/journal.pone.0204075
|
| [27] | Tortora GJ, Derrickson BH (2018) Principles of Anatomy and Physiology. John Wiley and Sons. |
Figures(15) / Tables(1)

Khadija Maqbool, Hira Mehboob, Abdul Majeed Siddiqui. Impact of viscosity on creeping viscous fluid flow through a permeable slit: a study for the artificial kidneys[J]. AIMS Biophysics, 2022, 9(4): 308-329. doi: 10.3934/biophy.2022026







 DownLoad:
DownLoad: