Citation: Ming Wei, Bo Sun, Wei Wu, Binbin Jing. A multiple objective optimization model for aircraft arrival and departure scheduling on multiple runways[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5545-5560. doi: 10.3934/mbe.2020298

| [1] | B. Sun, M. Wei, W. Wu, B. B. Jing. A novel group decision making method for airport operational risk management, Math. Biosci. Eng., 17 (2020), 2402-2417. |
| [2] | S. L. Wu, P. C. Chen, K. Y. Chang, C. C. Huang, Robust gain-scheduled control for vertical/short take-off and landing aircraft in hovering with time-varying mass and moment of inertia, Proc. Inst. Mech. Eng. Part G., 222 (2008), 473-482. |
| [3] | H. Nazini, T. Sasikala, Simulating aircraft landing and takeoff scheduling in distributed framework environment using Hadoop file system, Cluster. Comput., 22 (2019), 13463-13471. |
| [4] | Y. Ding, J. Valasek, Aircraft landing scheduling optimization for single runway noncontrolled airports: Static Case, J. Guid. Control Dynam., 30 (2007), 252-255. |
| [5] | M. Ahmed, S Alam, M. Barlow, A cooperative co-evolutionary optimization model for best-fit aircraft sequence and feasible runway configuration in a multi-runway airport, Aerospace, 5 (2018), 345-353. |
| [6] | L. Bianco, P. Dell'Olmo, S. Giordani, Scheduling models for air trafic control in terminal areas, J. Scheduling, 9 (2006), 180-197. |
| [7] | D. Briskorn, R. Stolletz, A dynamic programming approach for the aircraft landing problem with aircraft classes, Eur. J. Oper. Res., 43 (2015), 61-69. |
| [8] | R. G. Dear, The dynamic scheduling of aircraft in the near terminal area, MIT Libraries, (1976). |
| [9] | H. N. Psaraftis, A dynamic programming approach for sequencing identical groups of jobs, Oper. Res., 28 (1980), 1347-1359. |
| [10] | V. J. Hansen, Genetic search methods in air traffic control, Comput. Oper. Res., 31 (2004), 445- 459. |
| [11] | H. Pinol, J. E. Beasley, Scatter search and bionomic algorithms for the aircraft landing problem, Eur. J. Oper. Res., 171 (2006), 439-462. |
| [12] | A. Salehipour, L. M. Naeni, H. Kazemipoor, Scheduling aircraft landings by applying a variable neighborhood descent algorithm: runway-dependent landing time case, J. Appl. Oper. Res., 1 (2009), 39-49. |
| [13] | Y. H. Liu, A genetic local search algorithm with a threshold accepting mechanism for solving the runway dependent aircraft landing problem, Optim. Lett., 5 (2011), 229-245. |
| [14] | G. Bencheikh, J. Boukachour, A. E. H. Alaoui, Improved ant colony algorithm to solve the aircraft landing problem, Int. J. Comput. Theory Eng., 3 (2011), 224-233. |
| [15] | A. Salehipour, M. Modarres, L. Moslemi Naeni, An efficient hybrid meta-heuristic for aircraft landing problem, Comput. Oper. Res., 40 (2013), 207-213. |
| [16] | A. Faye, Solving the aircraft landing problem with time discretization approach, Eur. J. Oper. Res., 242 (2015), 1028-1038. |
| [17] | A. T. Ernst, M. Krishnamoorthy, R. H. Storer, Heuristic and exact algorithms for scheduling aircraft landings, Networks, 34 (1999), 229-241. |
| [18] | J. E. Beasley, M. Krishnamoorthy, Y. M. Sharaiha, D. Abramson, Scheduling aircraft landings - The static case, Transport. Sci., 34 (2000), 180-197. |
| [19] | H. N. Psaraftis, A dynamic programming approach for sequencing groups of identical jobs, Oper. Res., 28 (1980), 1347-1359. |
| [20] | C. S. Venkatakrishnan, A. Barnett, A. M. Odoni, Landings at Logan airport: Describing and increasing airport capacity, Transport. Sci., 27 (1993), 211-227. |
| [21] | F. Farhadi, A. Ghoniem, M. Al-Salem, Runway capacity management - an empiricalstudy with application to Doha international airport, Transp. Res. Part E: Logist. Transp. Rev., 68 (2014), 53-63. |
| [22] | F. Furini, M. P. Kidd, C. A. Persiani, P. Toth, State space reduced dynamic programming for the aircraft sequencing problem with constrained position shifting, Int. Symp. Comb. Optim. (ISCO), 2014 (2014), 267-279. |
| [23] | A. Ghoniem, F. Farhadi, M. Reihaneh, An accelerated branch-and-price algorithm for multiple-runway aircraft sequencing problems, Eur. J. Oper. Res., 246 (2015), 34-43. |
| [24] | A. Ghoniem, F. Farhadi, A column generation approach for aircraft sequencing problems: A computational study, J. Oper. Res. Soc., 66 (2015), 1717-1729. |
| [25] | H. Balakrishnan, B. Chandran, Algorithms for scheduling runway operations under constrained position shifting, Oper. Res., 58 (2010), 1650-1665. |
| [26] | D. Harikiopoulo, N. Neogi, Polynomial-time feasibility condition for multiclass aircraft sequencing on a single-runway airport, IEEE Trans. Intell. Transp. Syst., 12 (2011), 2-14. |
| [27] | A. Lieder. R. Stolletz, Scheduling aircraft take-offs and landings on interdependent and heterogeneous runways, Transport. Res. E-Log., 88 (2016), 67-188. |
| [28] | M. Samà, A. D'Ariano, F. Corman, D. Pacciarelli, Coordination of scheduling decisions in the management of airport airspace and taxiway operations. Transport. Res. Pro., 23 (2017), 246- 262. |
| [29] | J. Jemai M. Zekri K. Mellouli, An NSGA-II algorithm for the green vehicle routing problem, Evo. Comput. Com. Opt., 2012 (2012), 37-48. |
| [30] | M. Wei, T. Liu, B. Sun, B. B. Jing, Optimal integrated model for feeder transit route design and frequency-setting problem with stop selection, J. Adv. Transport., 2020 (20200. |
| [31] | A. Slowik, H. Kwasnicka, Nature inspired methods and their industry Applications-Swarm intelligence algorithms, IEEE T. Ind. Inform., 14 (2018), 1004-1015. |
| [32] | M. A. Dulebenets, A comprehensive evaluation of weak and strong mutation mechanisms in evolutionary algorithms for truck scheduling at cross-docking terminals, IEEE Access, 6 (2018). |
| [33] | X. Zhao, C. Wang, J. Su, J. Wang, Research and application based on the swarm intelligence algorithm and artificial intelligence for wind farm decision system, Renew. Energ., 134 (2019), 681-697. |
| [34] | L. Brezonik, I. Fister, V. Podgorelec, Swarm intelligence algorithms for feature selection: A review, Appl. Sci., 8 (2018), 1521. |
| [35] | M. A. Dulebenets, A delayed start parallel evolutionary algorithm for just-in-time truck scheduling at a cross-docking facility, Int. J. Prod. Econ., 212 (2019), 236-258. |
| [36] | H. Anandakumar, K. Umamaheswari, A bio-inspired swarm intelligence technique for social aware cognitive radio handovers, Comput. Electr. Eng., 71 (2018), 925-937. |
| [37] | T. Li, G. Kou, Y. Peng, Y. Shi, Classifying with adaptive hyper-spheres: An incremental classifier based on competitive learning, IEEE Trans. Syst. Man Cybern. Syst., 50 (2020), 1218-1229. |
| [38] | G. Kou, C. S. Lin, A cosine maximization method for the priority vector derivation in AHP, Eur. J. Oper. Res., 235 (2014), 225-232. |
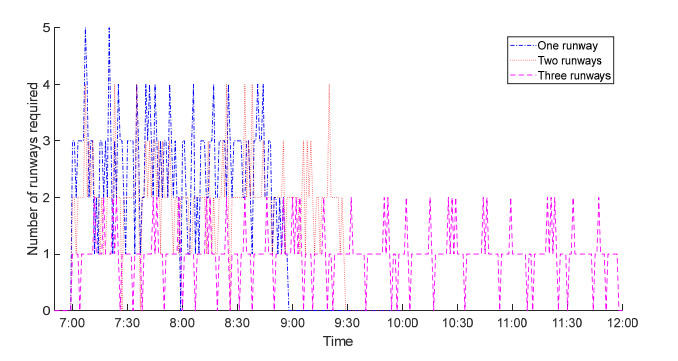
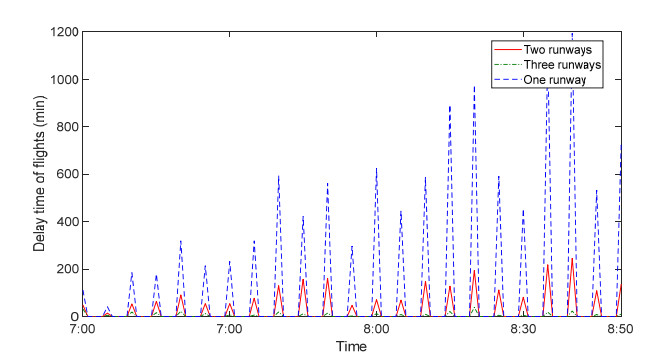
Figures(6) / Tables(4)

Ming Wei, Bo Sun, Wei Wu, Binbin Jing. A multiple objective optimization model for aircraft arrival and departure scheduling on multiple runways[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5545-5560. doi: 10.3934/mbe.2020298







 DownLoad:
DownLoad: