Citation: Cemil Tunç, Alireza Khalili Golmankhaneh. On stability of a class of second alpha-order fractal differential equations[J]. AIMS Mathematics, 2020, 5(3): 2126-2142. doi: 10.3934/math.2020141

| [1] | B. B. Mandelbrot, The Fractal Geometry of Nature, New York: WH freeman, 1983. |
| [2] | M. F. Barnsley, Fractals Everywhere, Academic press, 2014. |
| [3] | C. Cattani, Fractals and hidden symmetries in DNA, Math. Probl. Eng., 2010, 2010. |
| [4] | S. Kumari, R. Chugh, J. Cao, et al. Multi fractals of generalized multivalued iterated function systems in b-metric spaces with applications, Math., 7 (2019), 967. |
| [5] |
M. S. Tavazoei, M. Haeri, An optimization algorithm based on chaotic behavior and fractal nature, J. Comput. Appl. Math., 206 (2007), 1070-1081. doi: 10.1016/j.cam.2006.09.008

|
| [6] | E. Nakaguchi, M. Efendiev, On a new dimension estimate of the global attractor for chemotaxisgrowth systems, Osaka J. Math., 45 (2008), 273-281. |
| [7] |
M. Efendiev, S. Zelik, Finite- and infinite-dimensional attractors for porous media equations, P. Lond. Math. Soc., 96 (2008), 51-77. doi: 10.1112/plms/pdm026
|
| [8] |
I. Chitescu, H. Georgescu, R.Miculescu, Approximation of infinite dimensional fractals generated by integral equations, J. Comput. Appl. Math., 234 (2010), 1417-1425. doi: 10.1016/j.cam.2010.02.017
|
| [9] | S. Ree, L. E. Reichl, Fractal analysis of chaotic classical scattering in a cut-circle billiard with two openings, Phys. Rev. E, 65 (2002), 055205. |
| [10] |
E. de Amo, I. Chitescu, M. D. Carrillo, et al. A new approximation procedure for fractals, J. Comput. Appl. Math., 151 (2003), 355-370. doi: 10.1016/S0377-0427(02)00752-5
|
| [11] |
L. Nottale, J. Schneider, Fractals and nonstandard analysis, J. Math. Phys., 25 (1984), 1296-1300. doi: 10.1063/1.526285
|
| [12] |
M. Czachor, Waves along fractal coastlines: From fractal arithmetic to wave equations, Acta Phys. Pol. B, 50 (2019), 813-831. doi: 10.5506/APhysPolB.50.813
|
| [13] | M. N. Célérier, L. Nottale, Quantum-classical transition in scale relativity, J. Phys. A: Math. Gen., 37 (2004), 931. |
| [14] | K. Falconer, Fractal Geometry: Mathematical Foundations and Applications, John Wiley Sons, 2004. |
| [15] | K. Falconer, Techniques in Fractal Geometry, Chichester (W. Sx.): Wiley, 1997. |
| [16] | G. Edgar, Measure, Topology, and Fractal Geometry, Springer Science Business Media, 2007. |
| [17] | J. Kigami, Analysis on Fractals, Cambridge University Press, 2001. |
| [18] |
F. H. Stillinger, Axiomatic Basis for Spaces with Noninteger Dimension, J. Math. Phys., 18 (1977), 1224-1234. doi: 10.1063/1.523395
|
| [19] | V. E. Tarasov, Fractional Dynamics: Applications of Fractional Calculus to Dynamics of Particles, Fields and Media, Springer Science Business Media, 2011. |
| [20] | M. Zubair, M. J. Mughal, Q. A. Naqvi, Electromagnetic Fields and Waves in Fractional Dimensional Space, Springer Science Business Media, 2012. |
| [21] |
W. Chen Y. Liang, New methodologies in fractional and fractal derivatives modeling, Chaos Soliton. Fract., 102 (2017), 72-77. doi: 10.1016/j.chaos.2017.03.066
|
| [22] |
Y. Liang, Q. Y. Allen, W. Chen, et al. A fractal derivative model for the characterization of anomalous diffusion in magnetic resonance imaging, Commun. Nonlinear Sci., 39 (2016), 529-537. doi: 10.1016/j.cnsns.2016.04.006
|
| [23] | H. Richard, Fractional Calculus: an Introduction for Physicists, World Scientific, 2014. |
| [24] | S. Das, Functional Fractional Calculus, Springer Science Business Media, 2011. |
| [25] | C. Song, S. Fei, J. Cao, et al. Robust synchronization of fractional-order uncertain chaotic systems based on output feedback sliding mode control, Math., 7 (2019), 599. |
| [26] | G. Rajchakit, A. Pratap, R. Raja, et al. Hybrid control scheme for projective lag synchronization of Riemann-Liouville sense fractional order memristive BAM neuralnetworks with mixed delays, Math., 7 (2019), 759. |
| [27] |
Y. Wei, L. Yin, X. Long, The coupling integrable couplings of the generalized coupled Burgers equation hierarchy and its Hamiltonian structure, Adv. Differ. Equ., 2019 (2019), 1-17. doi: 10.1186/s13662-018-1939-6
|
| [28] |
X. Li, Z. Liu, J. Li, et al. Existence and controllability for nonlinear fractional control systems with damping in Hilbert spaces, Acta Math. Sci., 39 (2019), 229-242. doi: 10.1007/s10473-019-0118-5
|
| [29] |
X. Li, Y. Li, Z. Liu, et al. Sensitivity analysis for optimal control problems described by nonlinear fractional evolution inclusions, Fract. Calc. Appl. Anal., 21 (2018), 1439-1470. doi: 10.1515/fca-2018-0076
|
| [30] |
K. M. Kolwankar, A. D. Gangal, Fractional differentiability of nowhere differentiable functions and dimensions, Chaos, 6 (1996), 505-513. doi: 10.1063/1.166197
|
| [31] | K. M. Kolwankar, A. D. Gangal, Local fractional Fokker-Planck equation, Phys. Rev. Lett., 80 (1998), 214. |
| [32] |
A. Parvate, A. D. Gangal, Calculus on fractal subsets of real line-I: Formulation, Fract., 17 (2009), 53-148. doi: 10.1142/S0218348X09004181
|
| [33] |
A. Parvate, A. D. Gangal, Calculus on fractal subsets of real line-II: Conjugacy with ordinary calculus, Fract., 19 (2011), 271-290. doi: 10.1142/S0218348X11005440
|
| [34] |
A. Parvate, S. Satin, A. D. Gangal, Calculus on fractal curves in Rn, Fract., 19 (2011), 15-27. doi: 10.1142/S0218348X1100518X
|
| [35] | A. K. Golmankhaneh, A. Fernandez, A. K. Golmankhaneh, et al. Diffusion on middle-ξ Cantor sets, Entropy, 20 (2018), 1-13. |
| [36] |
A. K. Golmankhaneh, A. S. Balankin, Sub-and super-diffusion on Cantor sets: Beyond the paradox, Phys. Lett. A, 382 (2018), 960-967. doi: 10.1016/j.physleta.2018.02.009
|
| [37] | A. K. Golmankhaneh, U. Branch, Quantum mechanics on the fractal time-space, In: Proceedings of the 8th International Conference on Fractional Differentiation and its Applications, 2016, 677-687. |
| [38] | A. K. Golmankhaneh, C. Tunç, Sumudu transform in fractal calculus, Appl. Math. Comput., 350 (2019), 386-401. |
| [39] |
A. K. Golmankhaneh, C. Tunç, On the Lipschitz condition in the fractal calculus, Chaos, Soliton Fract., 95 (2017), 140-147. doi: 10.1016/j.chaos.2016.12.001
|
| [40] |
C. Tunç, S. A. Mohammed, On the asymptotic analysis of bounded solutions to nonlinear differential equations of second order, Adv. Differ. Equ., 2019 (2019), 1-19. doi: 10.1186/s13662-018-1939-6
|
| [41] | G. C. Wu, D. Baleanu, W. H. Luo, Lyapunov functions for Riemann-Liouville-like fractional difference equations, Appl. Math. Comput., 314 (2017), 228-236. |
| [42] | M. Rivero, S. V. Rogosin, J. A. T. Machado, et al. Stability of fractional order systems, Math. Probl. Eng., 2013 (2013). |
| [43] | R. Agarwal, S. Hristova, D. O'Regan, A survey of Lyapunov functions, stability and impulsive Caputo fractional differential equations, Fract. Calc. Appl. Anal., 19 (2016), 290-318. |
| [44] | A. Q. M. Khaliq, X. Liang, K. M. Furati, A fourth-order implicit-explicit scheme for the space fractional nonlinear Schrödinger equations, Numer. Algorithms, 75 (2016), 147-172. |
| [45] | C. Tunç, Uniformly stability and boundedness of solutions of second order nonlinear delay differential equations, Appl. Comput. Math., 10 (2011), 449-462. |
| [46] |
C. Tunç, E. Tunç, On the asymptotic behavior of solutions of certain second-order differential equations, J. Franklin I., 344 (2007), 391-398. doi: 10.1016/j.jfranklin.2006.02.011
|
| [47] | T. Yoshizawa, Stability Theory by Liapunov's Second Method, 1966. |
| [48] | T. Hara, On the asymptotic behavior of the solutions of some third and fourth order nonautonomous differential equations, Publ. Res. I. Math. Sci., 9 (1974), 649-673. |
| [49] | R. DiMartino, W. Urbina, On Cantor-Like Sets and Cantor-Lebesgue Singular Functions, arXiv preprint arXiv:1403.6554, 2014. |
| [50] | G. Braden, Fractal Time: The Secret of 2012 and a New World Age, Hay House Inc, 2010. |
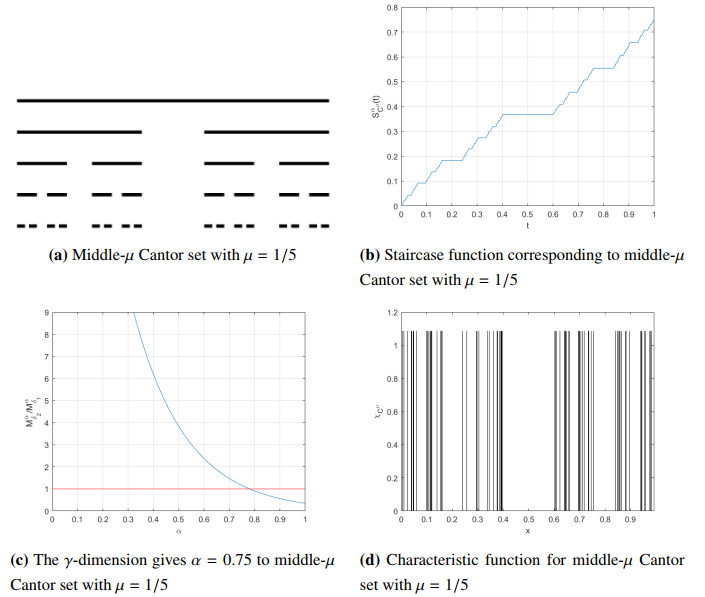
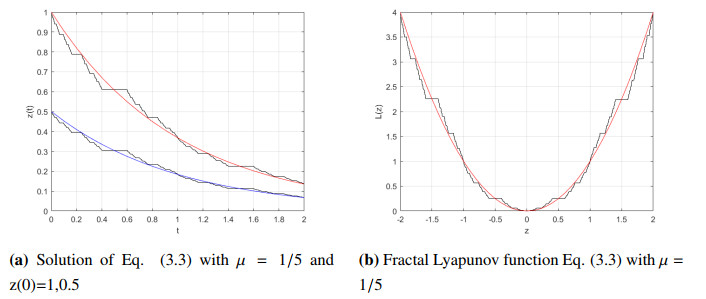
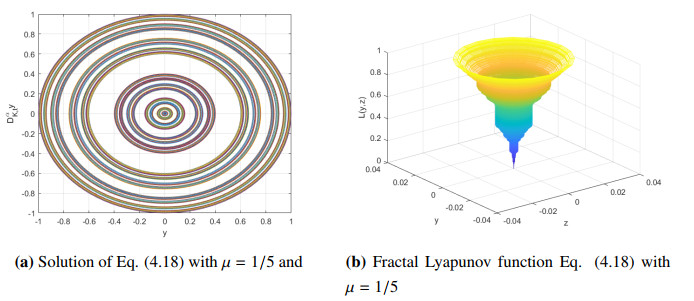
Figures(3)

Cemil Tunç, Alireza Khalili Golmankhaneh. On stability of a class of second alpha-order fractal differential equations[J]. AIMS Mathematics, 2020, 5(3): 2126-2142. doi: 10.3934/math.2020141







 DownLoad:
DownLoad: