Citation: Vikas Kumar, Nitu Kumari. Controlling chaos in three species food chain model with fear effect[J]. AIMS Mathematics, 2020, 5(2): 828-842. doi: 10.3934/math.2020056

| [1] |
A. Hastings, T. Powell, Chaos in a three-species food chain, Ecol., 72 (1991), 896-903. doi: 10.2307/1940591

|
| [2] |
J. N. Eisenberg, D. R. Maszle, The structural stability of a three-species food chain model, J. Theor. Biol., 176 (1995), 501-510. doi: 10.1006/jtbi.1995.0216
|
| [3] |
B. Sahoo, S. Poria, The chaos and control of a food chain model supplying additional food to top-predator, Chaos. Solitons Fractals., 58 (2014), 52-64. doi: 10.1016/j.chaos.2013.11.008
|
| [4] | P. Panday, N. Pal, S. Samanta, et al. Stability and bifurcation analysis of a three-species food chain model with fear, Internat. J. Bifur. Chaos Appl. Sci. Engrg., 28 (2018), 1850009. |
| [5] | B. Nath, N. Kumari, V. Kumar, et al. Refugia and allee effect in prey species stabilize chaos in a tri-trophic food chain model, Differ. Equ. Dyn. Syst., (2019), 1-27. |
| [6] | R. J. Taylor, Predation, New York: Chapman and Hall Press, (1984). |
| [7] |
S. L. Lima, L. M. Dill, Behavioral decisions made under the risk of predation: A review and prospectus, Can. J. Zool., 68 (1990), 619-640. doi: 10.1139/z90-092
|
| [8] |
O. J. Schmitz, A. P. Beckerman, K. M. O'Brien, Behaviorally mediated trophic cascades: Effects of predation risk on food web interactions, Ecol., 78 (1997), 1388-1399. doi: 10.1890/0012-9658(1997)078[1388:BMTCEO]2.0.CO;2
|
| [9] |
L. Y. Zanette, A. F. White, M. C. Allen, et al. Perceived predation risk reduces the number of offspring songbirds produce per year, Sci., 334 (2011), 1398-1401. doi: 10.1126/science.1210908
|
| [10] |
W. Cresswell, Predation in bird populations, J. Ornitho., 152 (2011), 251-263. doi: 10.1007/s10336-010-0638-1
|
| [11] |
K. B. Altendorf, J. W. Laundré, C. A. López González, et al. Assessing effects of predation risk on foraging behavior of mule deer, J. Mammal., 82 (2001), 430-439. doi: 10.1644/1545-1542(2001)082<0430:AEOPRO>2.0.CO;2
|
| [12] |
X. Wang, L. Zanette, X. Zou, Modelling the fear effect in predator-prey interactions, J. Math. Biol., 73 (2016), 1179-1204. doi: 10.1007/s00285-016-0989-1
|
| [13] |
S. K. Sasmal, Population dynamics with multiple allee effects induced by fear factors-a mathematical study on prey-predator interactions, Appl. Math. Model., 64 (2018), 1-14. doi: 10.1016/j.apm.2018.07.021
|
| [14] |
H. Zhang, Y. Cai, S. Fu, et al. Impact of the fear effect in a prey-predator model incorporating a prey refuge, Appl. Math. Computation, 356 (2019), 328-337. doi: 10.1016/j.amc.2019.03.034
|
| [15] | K. Kundu, S. Pal, S. Samanta, et al. Impact of fear effect in a discrete-time predator-prey system, Bull. Calcutta Math. Soc., 110 (2018), 245-264. |
| [16] |
S. Mondal, A. Maiti, G. Samanta, Effects of fear and additional food in a delayed predator-prey model, Biophys. Rev. Lett., 13 (2018), 157-177. doi: 10.1142/S1793048018500091
|
| [17] |
D. Duan, B. Niu, J. Wei, Hopf-hopf bifurcation and chaotic attractors in a delayed diffusive predator-prey model with fear effect, Chaos. Solitons Fractals., 123 (2019), 206-216. doi: 10.1016/j.chaos.2019.04.012
|
| [18] | X. Wang, X. Zou, Pattern formation of a predator-prey model with the cost of anti-predator behaviors, Math. Biosci. Eng., 15 (2017), 775-805. |
| [19] | S. Chen, Z. Liu, J. Shi, Nonexistence of nonconstant positive steady states of a diffusive predatorprey model with fear effect, J. Nonlinear Model. Anal., 1 (2019), 47-56. |
| [20] |
A. Sha, S. Samanta, M. Martcheva, et al. Backward bifurcation, oscillations and chaos in an ecoepidemiological model with fear effect, J. Biol. Dyn., 13 (2019), 301-327. doi: 10.1080/17513758.2019.1593525
|
| [21] | S. Pal, S. Majhi, S. Mandal, et al. Role of fear in a predator-prey model with beddington-deangelis functional response, Z. für Naturforsch. A., 74 (2019), 581-595. |
| [22] |
V. Rai, R. K. Upadhyay, Chaotic population dynamics and biology of the top-predator, Chaos, Solitons Fractals., 21 (2004), 1195-1204. doi: 10.1016/j.chaos.2003.12.065
|
| [23] |
R. Upadhyay, R. Naji, N. Kumari, Dynamical complexity in some ecological models: Effect of toxin production by phytoplankton, Nonlinear Anal. Model Control., 12 (2007), 123-138. doi: 10.15388/NA.2007.12.1.14726
|
| [24] | M. A. Aziz-Alaoui, Study of a Leslie-Gower-type tritrophic population model. Chaos Solitons Fractals., 14 (2002), 1275-1293. |
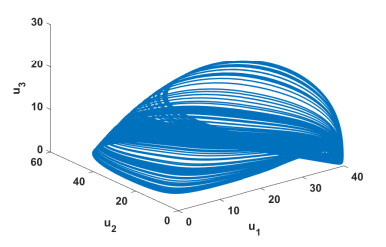
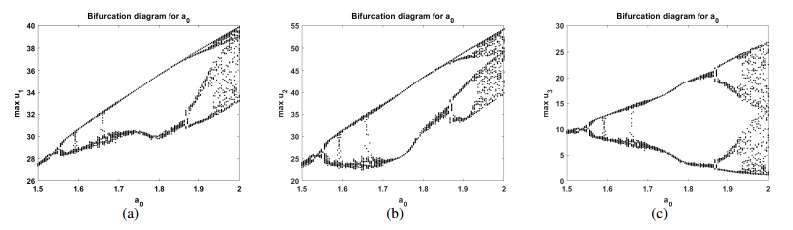
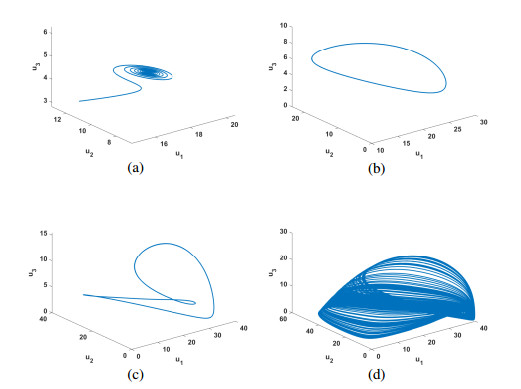
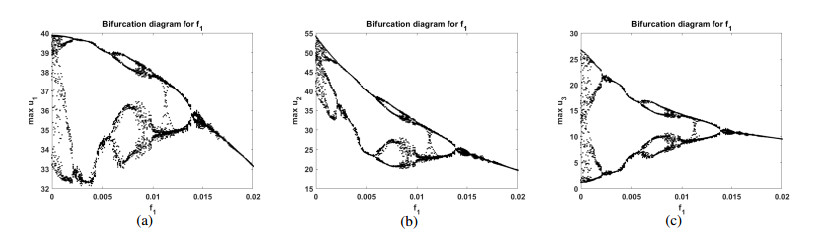
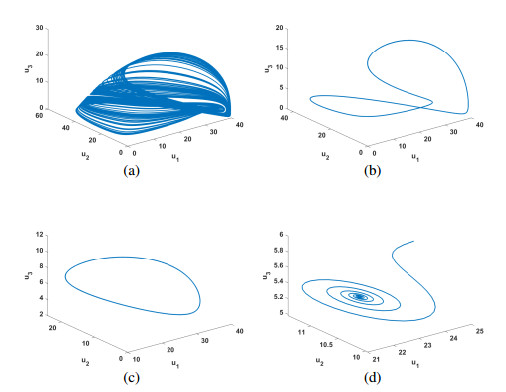
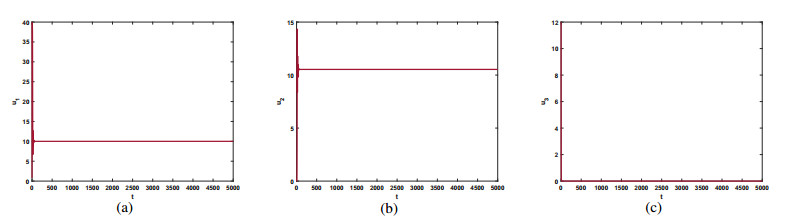
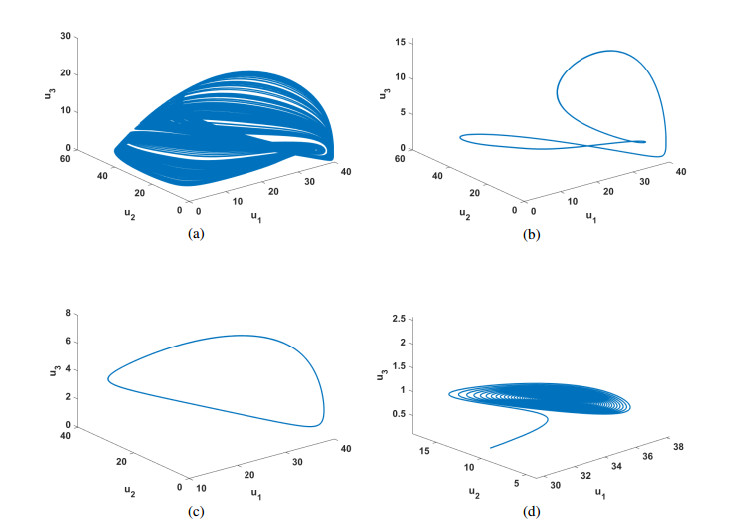
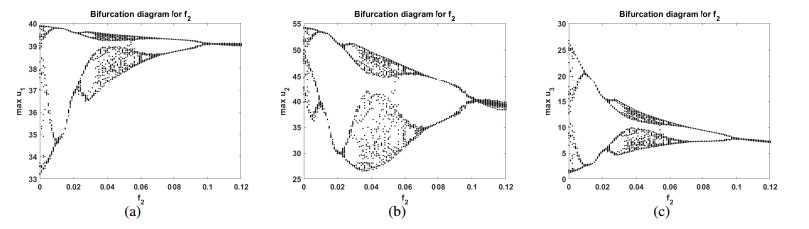
Figures(10)

Vikas Kumar, Nitu Kumari. Controlling chaos in three species food chain model with fear effect[J]. AIMS Mathematics, 2020, 5(2): 828-842. doi: 10.3934/math.2020056







 DownLoad:
DownLoad: