Citation: Raili Kajaste, Markku Hurme, Pekka Oinas. Methanol-Managing greenhouse gas emissions in the production chain by optimizing the resource base[J]. AIMS Energy, 2018, 6(6): 1074-1102. doi: 10.3934/energy.2018.6.1074

| [1] |
Räuchle K, Plass L, Wernicke HJ, et al. (2016) Methanol for renewable energy storage and utilization. Energ Technol 4: 193–200. doi: 10.1002/ente.201500322

|
| [2] |
Su LW, Li XR, Sun ZY (2013) Flow chart of methanol in China. Renew Sust Energ Rev 28: 541–550. doi: 10.1016/j.rser.2013.08.020
|
| [3] | MCGroup (2018) Methanol: 2018 World Market Outlook and Forecast up to 2027. Available from: https://mcgroup.co.uk/researches/methanol. |
| [4] | IHS. Methanol, Marc Alvarado, February 2016. Available from: http://www.methanol.org/wp-content/uploads/2016/07/Marc-Alvarado-Global-Methanol-February-2016-IMPCA-for-upload-to-website.pdf. |
| [5] |
Brynolf S, Fridell E, Andersson K (2014) Environmental assessment of marine fuels: Liquefied natural gas, liquefied biogas, methanol and bio-methanol. J Clean Prod 74: 86–95. doi: 10.1016/j.jclepro.2014.03.052
|
| [6] |
Pontzen F, Liebner W, Gronemann V, et al. (2011) CO2-based methanol and DME-Efficient technologies for industrial scale production. Catal Today 171: 242–250. doi: 10.1016/j.cattod.2011.04.049
|
| [7] | Bermúdez JM, Ferrera-Lorenzo N, Luque S, et al. (2013) New process for producing methanol from coke oven gas by means of CO2 reforming. Comparison with conventional process. Fuel Process Technol 115: 215–221. |
| [8] | Saunois M, Jackson RB, Bousquet P, et al. (2016) The growing role of methane in anthropogenic climate change. Environ Res Lett 11: 1–5. |
| [9] |
Riaz A, Zahedi G, Klemes JJ (2013) A review of cleaner production methods for the manufacture of methanol. J Clean Prod 57: 19–37. doi: 10.1016/j.jclepro.2013.06.017
|
| [10] |
Anicic B, Trop P, Goricanec D (2014) Comparison between two methods of methanol production from carbon dioxide. Energy 77: 279–289. doi: 10.1016/j.energy.2014.09.069
|
| [11] |
Tidona B, Koppold C, Bansode A, et al. (2013) CO2 hydrogenation to methanol at pressures up to 950 bar. J Supercrit Fluid 78: 70–77. doi: 10.1016/j.supflu.2013.03.027
|
| [12] |
Narvaez A, Chadwick D, Kershenbaum L (2014) Small-medium scale polygeneration systems: Methanol and power production. Appl Energy 113: 1109–1117. doi: 10.1016/j.apenergy.2013.08.065
|
| [13] |
Soltanieh M, Azar KM, Saber M (2012) Development of a zero emission integrated system for co-production of electricity and methanol through renewable hydrogen and CO2 capture. Int J Greenhouse Gas Control 7: 145–152. doi: 10.1016/j.ijggc.2012.01.008
|
| [14] |
Zhang Y, Cruz J, Zhang S, et al. (2013) Process simulation and optimization of methanol production coupled to tri-reforming process. Int J Hydrogen Energ 38: 13617–13630. doi: 10.1016/j.ijhydene.2013.08.009
|
| [15] | Minutillo M, Perna A (2010) A novel approach for treatment of CO2 from fossil fired power plants. Part B: The energy suitability of integrated tri-reforming power plants (ITRPPs) for methanol production. Int J Hydrogen Energ 35: 7012–7020. |
| [16] |
Matzen M, Demirel Y (2016) Methanol and dimethyl ether from renewable hydrogen and carbon dioxide: Alternative fuels production and life-cycle assessment. J Clean Prod 139: 1068–1077. doi: 10.1016/j.jclepro.2016.08.163
|
| [17] | Meerman JC, Ramírez A, Turkenburg WC, et al. (2011) Performance of simulated flexible integrated gasification polygeneration facilities. Part A: A technical-energetic assessment. Renew Sust Energ Rev 15: 2563–2587. |
| [18] |
Van Rens G, Huisman G, De Lathouder H, et al. (2011) Performance and exergy analysis of biomass-to-fuel plants producing methanol, dimethylether or hydrogen. Biomass Bioenerg 35: S145–S154. doi: 10.1016/j.biombioe.2011.05.020
|
| [19] |
Melin K, Kohl T, Koskinen J, et al. (2015) Performance of biofuel process utilising separate lignin and carbohydrate processing. Bioresource Technol 192: 397–409. doi: 10.1016/j.biortech.2015.05.022
|
| [20] | Melin K, Kohl T, Koskinen J, et al. (2016) Enhanced biofuel processes utilizing separate lignin and carbohydrate processing of lignocellulose. Biofuels 7: 31–54. |
| [21] |
Trop P, Anicic B, Goricanec D (2014) Production of methanol from a mixture of torrefied biomass and coal. Energy 77: 125–132. doi: 10.1016/j.energy.2014.05.045
|
| [22] |
Holmgren KM, Berntsson T, Andersson E, et al. (2012) System aspects of biomass gasification with methanol synthesis-process concepts and energy analysis. Energy 45: 817–828. doi: 10.1016/j.energy.2012.07.009
|
| [23] |
Holmgren KM, Andersson E, Berntsson T, et al. (2014) Gasification-based methanol production from biomass in industrial clusters: Characterisation of energy balances and greenhouse gas emissions. Energy 69: 622–637. doi: 10.1016/j.energy.2014.03.058
|
| [24] |
Andersson J, Lundgren J, Marklund M (2014) Methanol production via pressurized entrained flow biomass gasification-Techno-economic comparison of integrated vs. stand-alone production. Biomass Bioenerg 64: 256–268. doi: 10.1016/j.biombioe.2014.03.063
|
| [25] |
Ortiz FJG, Serrera A, Galera S, et al. (2013) Methanol synthesis from syngas obtained by supercritical water reforming of glycerol. Fuel 105: 739–751. doi: 10.1016/j.fuel.2012.09.073
|
| [26] |
Bludowsky T, Agar DW (2009) Thermally integrated bio-syngas-production for biorefineries. Chem Eng Res Des 87: 1328–1339. doi: 10.1016/j.cherd.2009.03.012
|
| [27] |
Boretti A (2013) Renewable hydrogen to recycle CO2 to methanol. Int J Hydrogen Energ 38: 1806–1812. doi: 10.1016/j.ijhydene.2012.11.097
|
| [28] | Trudewind CA, Schreiber A, Haumann D (2014) Photocatalytic methanol and methane production using captured CO2 from coal-fired power plants. Part I-a Life Cycle Assessment. J Clean Prod 70: 27–37. |
| [29] | Bai Z, Liu Q, Lei J, et al. (2015)>A polygeneration system for the methanol production and the power generation with the solar-biomass thermal gasification. Energ Convers Manage 102: 190–201. |
| [30] | Bertau H, Offermanns H, Plass L, et al. (2014) Methanol: The Basic Chemical and Energy Feedstock of the Future. Heidelberg: Springer. |
| [31] | ISO (2006a) Environmental Management-Life Cycle Assessment-Principles and Framework. ISO 14040:2006. ISO/IEC. |
| [32] | ISO (2006b) Environmental Management-Life Cycle Assessment-Requirements and Guidelines. ISO 14044:2006. ISO/IEC. |
| [33] |
Cherubini F, Jungmeier G (2010) LCA of a biorefinery concept producing bio-ethanol, bioenergy, and chemicals from switchgrass. Int J Life Cycle Assess 15: 53–66. doi: 10.1007/s11367-009-0124-2
|
| [34] |
Kajaste R (2014) Chemicals from biomass-managing greenhouse gas emissions in biorefinery production chains-a review. J Clean Prod 75: 1–10. doi: 10.1016/j.jclepro.2014.03.070
|
| [35] |
Matzen M, Alhajji M, Demirel Y (2015) Chemical storage of wind energy by renewable methanol production: Feasibility analysis using a multi-criteria decision matrix. Energy 93: 343–353. doi: 10.1016/j.energy.2015.09.043
|
| [36] |
Minutillo A, Perna A (2009) A novel approach for treatment of CO2 from fossil fired power plants, Part A: The integrated systems ITRPP. Int J Hydrogen Energ 34: 4014–4020. doi: 10.1016/j.ijhydene.2009.02.069
|
| [37] |
Barkley ZR, Lauvaux T, Davis KJ, et al. (2017) Quantifying methane emissions from natural gas production in north-eastern Pennsylvania. Atmos Chem Phys 17: 13941–13966. doi: 10.5194/acp-17-13941-2017
|
| [38] | Moro A, Lonza L (2017) Electricity carbon intensity in European Member States: Impacts on GHG emissions of electric vehicles. Transport Res D-Tr E 64: 5–14. |
| [39] |
Moretti C, Moro A, Edwards R, et al. (2017) Analysis of standard and innovative methods for allocating upstream and refinery GHG emissions to oil products. Appl Energy 206: 372–381. doi: 10.1016/j.apenergy.2017.08.183
|
| [40] |
Zhang C, Jun KW, Gao R, et al. (2017) Carbon dioxide utilization in a gas-to-methanol process combined with CO2/Steam-mixed reforming: Techno-economic analysis. Fuel 190: 303–311. doi: 10.1016/j.fuel.2016.11.008
|
| [41] |
Di X, Liping L, Weifeng S, et al. (2017) Life cycle sustainability assessment of chemical processes: A vector based three-dimensional algorithm coupled with AHP. Ind Eng Chem Res 56: 11216–11227. doi: 10.1021/acs.iecr.7b02041
|
| [42] |
Van-Dal ÉS, Bouallou C (2013) Design and simulation of a methanol production plant from CO2 hydrogenation. J Clean Prod 57: 38–45. doi: 10.1016/j.jclepro.2013.06.008
|
| [43] |
Dumont MN, von der Assen N, Sternberg A, et al. (2012) Assessing the environmental potential of carbon dioxide utilization: A graphical targeting approach. Comput Aided Chem Eng 31: 1407–1411. doi: 10.1016/B978-0-444-59506-5.50112-7
|
| [44] |
Yu Y, Jing L, Weifeng S, et al. (2018) High-efficiency utilization of CO2 in the methanol production by a novel parallel-series system combining steam and dry methane reforming. Energy 158: 820–829. doi: 10.1016/j.energy.2018.06.061
|
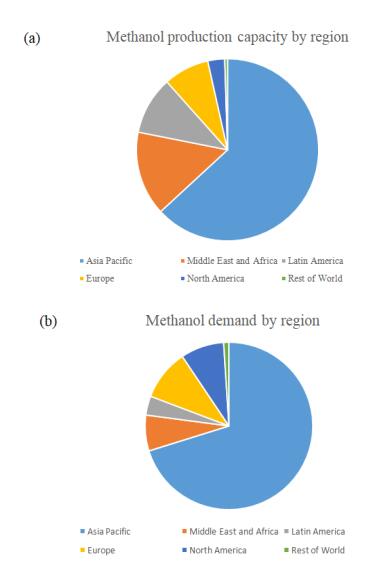
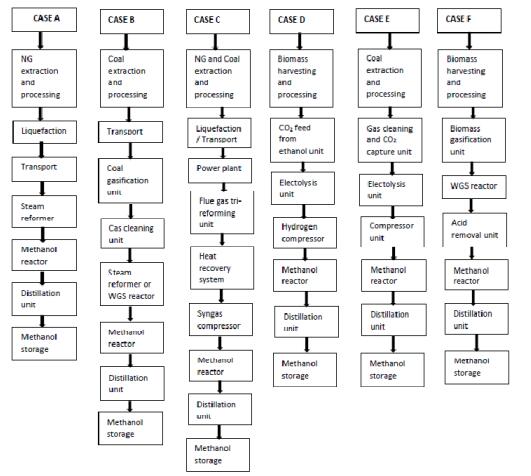
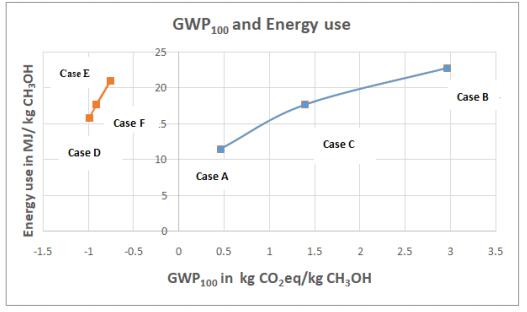
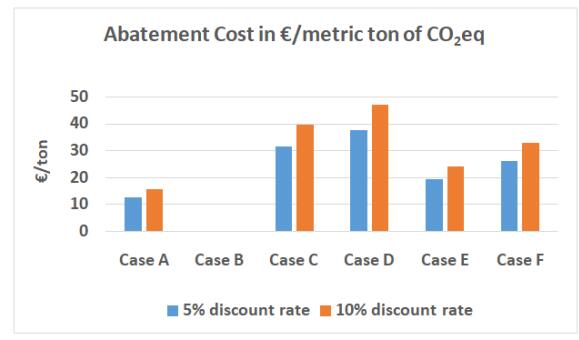
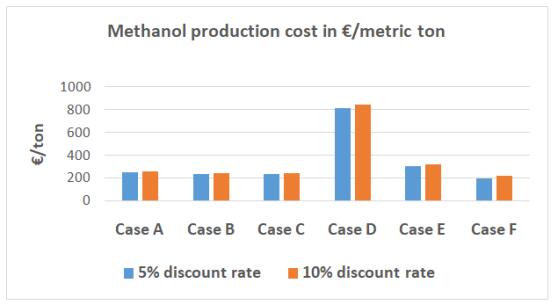
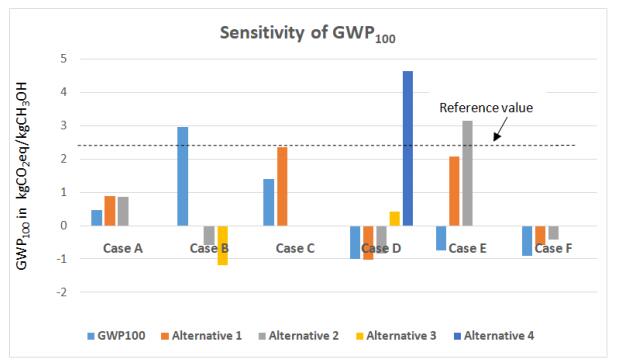
Figures(6) / Tables(15)

Raili Kajaste, Markku Hurme, Pekka Oinas. Methanol-Managing greenhouse gas emissions in the production chain by optimizing the resource base[J]. AIMS Energy, 2018, 6(6): 1074-1102. doi: 10.3934/energy.2018.6.1074







 DownLoad:
DownLoad: