Citation: Shouyun Cheng, Lin Wei, Mustafa Alsowij, Fletcher Corbin, Eric Boakye, Zhengrong Gu, Douglas Raynie. Catalytic hydrothermal liquefaction (HTL) of biomass for bio-crude production using Ni/HZSM-5 catalysts[J]. AIMS Environmental Science, 2017, 4(3): 417-430. doi: 10.3934/environsci.2017.3.417

| [1] |
Li J, Wu L, Yang Z (2008) Analysis and upgrading of bio-petroleum from biomass by direct deoxy-liquefaction. J Anal Appl Pyrolysis 81: 199-204. doi: 10.1016/j.jaap.2007.11.004

|
| [2] |
Qian Y, Zuo C, Tan J, et al. (2007) Structural analysis of bio-oils from sub-and supercritical water liquefaction of woody biomass. Energy 32: 196-202. doi: 10.1016/j.energy.2006.03.027
|
| [3] | Liu Z, Zhang FS (2008) Effects of various solvents on the liquefaction of biomass to produce fuels and chemical feedstocks. Energy Convers Manage 49: 3498-3504. |
| [4] | Vardon DR, Sharma BK, Blazina GV, et al. (2012) Thermochemical conversion of raw and defatted algal biomass via hydrothermal liquefaction and slow pyrolysis. Bioresour Technol 109: 178-187. |
| [5] |
Chen Y, Mu R, Yang M, et al. (2017) Catalytic hydrothermal liquefaction for bio-oil production over CNTs supported metal catalysts. Chem Eng Sci 161: 299-307. doi: 10.1016/j.ces.2016.12.010
|
| [6] |
Wang Y, Wang H, Lin H, et al. (2013) Effects of solvents and catalysts in liquefaction of pinewood sawdust for the production of bio-oils. Biomass Bioenerg 59: 158-167. doi: 10.1016/j.biombioe.2013.10.022
|
| [7] |
Toor SS, Rosendahl L, Rudolf A (2011) Hydrothermal liquefaction of biomass: a review of subcritical water technologies. Energy 36: 2328-2342. doi: 10.1016/j.energy.2011.03.013
|
| [8] | Saber M, Golzary A, Hosseinpour M, et al. (2016) Catalytic hydrothermal liquefaction of microalgae using nanocatalyst. Appl Energy 183: 566-576. |
| [9] | Jiang J, Junming XU, Zhanqian, S (2015) Review of the direct thermochemical conversion of lignocellulosic biomass for liquid fuels. Front Agr Sci Eng 2: 13-27. |
| [10] |
Okuda K, Umetsu M, Takami S, et al. (2004) Disassembly of lignin and chemical recovery-rapid depolymerizatin of lignin without char formation in water-phenol mixtures. Fuel Process Technol 85: 803-813. doi: 10.1016/j.fuproc.2003.11.027
|
| [11] | Yang C, Jia L, Chen C, et al. (2011) Bio-oil from hydro-liquefaction of Dunaliella salina over Ni/REHY catalyst. Bioresour Technol 102: 4580-4584. |
| [12] |
Perego C, Bianchi D (2010) Biomass upgrading through acid–base catalysis. Chem Eng J 161: 314-322. doi: 10.1016/j.cej.2010.01.036
|
| [13] |
Gayubo AG, Alonso A, Valle B, et al. (2010) Hydrothermal stability of HZSM-5 catalysts modified with Ni for the transformation of bioethanol into hydrocarbons. Fuel 89: 3365-3372. doi: 10.1016/j.fuel.2010.03.002
|
| [14] |
Hamelinck CN, Van Hooijdonk G, Faaij AP (2005). Ethanol from lignocellulosic biomass: techno-economic performance in short-, middle-and long-term. Biomass Bioenerg 28: 384-410. doi: 10.1016/j.biombioe.2004.09.002
|
| [15] |
Huang HJ, Yuan XZ, Zeng GM, et al. (2013) Thermochemical liquefaction of rice husk for bio-oil production with sub-and supercritical ethanol as solvent. J Anal Appl Pyrolysis 102: 60-67. doi: 10.1016/j.jaap.2013.04.002
|
| [16] |
Fan SP, Zakaria S, Chia CH, et al. (2011) Comparative studies of products obtained from solvolysis liquefaction of oil palm empty fruit bunch fibres using different solvents. Bioresour Technol 102: 3521-3526. doi: 10.1016/j.biortech.2010.11.046
|
| [17] |
Aysu T, Turhan M, Küçük MM (2012) Liquefaction of Typha latifolia by supercritical fluid extraction. Bioresour Technol 107: 464-470. doi: 10.1016/j.biortech.2011.12.069
|
| [18] |
Huang H, Yuan X, Zeng G, et al. (2011) Thermochemical liquefaction characteristics of microalgae in sub-and supercritical ethanol. Fuel Process Technol 92: 147-153. doi: 10.1016/j.fuproc.2010.09.018
|
| [19] |
Li H, Yuan X, Zeng G, et al. (2010) The formation of bio-oil from sludge by deoxy-liquefaction in supercritical ethanol. Bioresour Technol 101: 2860-2866. doi: 10.1016/j.biortech.2009.10.084
|
| [20] |
Leng S, Wang X, He X, et al. (2013) NiFe/γ-Al 2 O 3: a universal catalyst for the hydrodeoxygenation of bio-oil and its model compounds.Catal Commun 41: 34-37. doi: 10.1016/j.catcom.2013.06.037
|
| [21] |
Vishnevetsky I, Epstein M (2007) Production of hydrogen from solar zinc in steam atmosphere. Int J Hydrogen Energy 32: 2791-2802. doi: 10.1016/j.ijhydene.2007.04.004
|
| [22] |
Brand S, Susanti RF, Kim SK, et al. (2013) Supercritical ethanol as an enhanced medium for lignocellulosic biomass liquefaction: Influence of physical process parameters. Energy 59: 173-182. doi: 10.1016/j.energy.2013.06.049
|
| [23] |
Xu C, Etcheverry T (2008) Hydro-liquefaction of woody biomass in sub-and super-critical ethanol with iron-based catalysts. Fuel 87: 335-345. doi: 10.1016/j.fuel.2007.05.013
|
| [24] |
Zhou C, Zhu X, Qian F, et al. (2016) Catalytic hydrothermal liquefaction of rice straw in water/ethanol mixtures for high yields of monomeric phenols using reductive CuZnAl catalyst. Fuel Process Technol 154: 1-6. doi: 10.1016/j.fuproc.2016.08.010
|
| [25] |
Cheng S, D'cruz I, Wang M, et al. (2010) Highly efficient liquefaction of woody biomass in hot-compressed alcohol− water co-solvents. Energ Fuel 24: 4659-4667. doi: 10.1021/ef901218w
|
| [26] |
Brand S, Hardi F, Kim J, et al. (2014) Effect of heating rate on biomass liquefaction: differences between subcritical water and supercritical ethanol. Energy 68: 420-427. doi: 10.1016/j.energy.2014.02.086
|
| [27] |
Zhai Y, Chen Z, Chen H, et al. (2015) Co-liquefaction of sewage sludge and oil-tea-cake in supercritical methanol: yield of bio-oil, immobilization and risk assessment of heavy metals. Environ Technol 36: 2770-2777. doi: 10.1080/09593330.2015.1049210
|
| [28] |
Cheng S, Wei L, Zhao X, et al. (2016) Conversion of Prairie Cordgrass to Hydrocarbon Biofuel over Co-Mo/HZSM-5 Using a Two-Stage Reactor System. Energy Technol 4: 706-713. doi: 10.1002/ente.201500452
|
| [29] | Maddi B, Viamajala S, Varanasi S (2011) Comparative study of pyrolysis of algal biomass from natural lake blooms with lignocellulosic biomass. Bioresour Technol 102: 11018-11026. |
| [30] | Zhao X, Wei L, Cheng S, et al. (2015) Catalytic cracking of carinata oil for hydrocarbon biofuel over fresh and regenerated Zn/Na-ZSM-5. Appl Catal A 507: 44-55. |
| [31] | Cheng S, Wei L, Alsowij MR, et al.(2017) In-situ hydrodeoxygenation upgrading of pine sawdust bio-oil to hydrocarbon biofuel using Pd/C catalyst. J Energy Inst: In press. |
| [32] |
Cheng S, Wei L, Zhao X, et al. (2016) Hydrodeoxygenation of prairie cordgrass bio-oil over Ni based activated carbon synergistic catalysts combined with different metals. New Biotechnol 33: 440-448. doi: 10.1016/j.nbt.2016.02.004
|
| [33] | Zhao X, Wei L, Cheng S, et al. (2016) Hydroprocessing of carinata oil for hydrocarbon biofuel over Mo-Zn/Al2O3. Appl Catal B 196: 41-49. |
| [34] |
Huang Y, Wei L, Zhao X, et al. (2016) Upgrading pine sawdust pyrolysis oil to green biofuels by HDO over zinc-assisted Pd/C catalyst. Energy Convers Manage 115: 8-16. doi: 10.1016/j.enconman.2016.02.049
|
| [35] |
Cheng S, Wei L, Zhao X, et al. (2015) Directly catalytic upgrading bio-oil vapor produced by prairie cordgrass pyrolysis over Ni/HZSM-5 using a two stage reactor. AIMS Energy 3: 227-240. doi: 10.3934/energy.2015.2.227
|
| [36] |
Wei L, Gao Y, Qu W, et al. (2016) Torrefaction of Raw and Blended Corn Stover, Switchgrass, and Prairie Grass. Trans ASABE 59: 717-726. doi: 10.13031/trans.59.10739
|
| [37] | Zhao X, Wei L, Cheng S, et al. (2015) Catalytic cracking of camelina oil for hydrocarbon biofuel over ZSM-5-Zn catalyst. Fuel Process Technol 139: 117-126. |
| [38] | Zhao X, Wei L, Cheng S, et al. (2015) Optimization of catalytic cracking process for upgrading camelina oil to hydrocarbon biofuel. Ind Crops Prod 77: 516-526. |
| [39] |
Zhao X, Wei L, Cheng S, et al. (2016) Development of hydrocarbon biofuel from sunflower seed and sunflower meat oils over ZSM-5. J Renew Sust Energ 8: 013109. doi: 10.1063/1.4941911
|
| [40] | Xu Y, Zheng X, Yu H, et al. (2014) Hydrothermal liquefaction of Chlorella pyrenoidosa for bio-oil production over Ce/HZSM-5. Bioresour Technol 156: 1-5. |
| [41] | Duan P, Savage PE (2010) Hydrothermal liquefaction of a microalga with heterogeneous catalysts. Ind Eng Chem Res 50: 52-61. |
| [42] |
Akhtar J, Kuang SK, Amin NS (2010) Liquefaction of empty palm fruit bunch (EPFB) in alkaline hot compressed water. Renew Energ 35: 1220-1227. doi: 10.1016/j.renene.2009.10.003
|
| [43] |
Karagöz S, Bhaskar T, Muto A, et al. (2006) Hydrothermal upgrading of biomass: effect of K 2 CO 3 concentration and biomass/water ratio on products distribution. Bioresour Technol 97: 90-98. doi: 10.1016/j.biortech.2005.02.051
|
| [44] |
Bhaskar T, Sera A, Muto A, et al. (2008) Hydrothermal upgrading of wood biomass: influence of the addition of K 2 CO 3 and cellulose/lignin ratio. Fuel 87: 2236-2242. doi: 10.1016/j.fuel.2007.10.018
|
| [45] | Liu HM, Xie XA, Feng B, et al. (2011) Effect of catalysts on 5-lump distribution of cornstalk liquefaction in sub-critical ethanol. BioResour 6: 2592-2604. |
| [46] | Xu CC, Su H, Cang D (2008) Liquefaction of corn distillers dried grains with solubles (DDGS) in hot-compressed phenol. BioResour 3: 363-382. |
| [47] |
Karagöz S, Bhaskar T, Muto A, et al. (2005) Low-temperature catalytic hydrothermal treatment of wood biomass: analysis of liquid products. Chem Eng J 108: 127-137. doi: 10.1016/j.cej.2005.01.007
|
| [48] |
Hammerschmidt A, Boukis N, Hauer E, et al. (2011) Catalytic conversion of waste biomass by hydrothermal treatment. Fuel 90: 555-562. doi: 10.1016/j.fuel.2010.10.007
|
| [49] |
Tymchyshyn M, Xu CC (2010) Liquefaction of bio-mass in hot-compressed water for the production of phenolic compounds. Bioresour Technol 101: 2483-2490. doi: 10.1016/j.biortech.2009.11.091
|
| [50] |
Wang Y, Wang H, Lin H, et al. (2013) Effects of solvents and catalysts in liquefaction of pinewood sawdust for the production of bio-oils. Biomass Bioenergy 59: 158-167. doi: 10.1016/j.biombioe.2013.10.022
|
| [51] | Zhu Z, Toor SS, Rosendahl L, et al. (2014) Analysis of product distribution and characteristics in hydrothermal liquefaction of barley straw in subcritical and supercritical water. Environ Prog Sustain Energy 33: 737-743. |
| [52] |
Xue Y, Chen H, Zhao W, et al. (2016) A review on the operating conditions of producing bio‐oil from hydrothermal liquefaction of biomass. Int J Energy Res 40: 865-877. doi: 10.1002/er.3473
|
| [53] |
Zhang B, von Keitz M, Valentas K (2008) Thermal effects on hydrothermal biomass liquefaction. Appl Biochem Biotechnol 147: 143-150. doi: 10.1007/s12010-008-8131-5
|
| [54] |
Kruse ANDREA, Henningsen T, Sinag A, et al. (2003) Biomass gasification in supercritical water: influence of the dry matter content and the formation of phenols. Ind Eng Chem Res 42: 3711-3717. doi: 10.1021/ie0209430
|
| [55] |
Yang Y, Gilbert A, Xu CC (2009) Production of bio-crude from forestry waste by hydro-liquefaction in sub-/super- critical methanol. AIChE J 55: 807-819. doi: 10.1002/aic.11701
|
| [56] | Zhang J, Chen WT, Zhang P, et al. (2013) Hydrothermal liquefaction of Chlorella pyrenoidosa in sub-and supercritical ethanol with heterogeneous catalysts. Bioresour Technol 133: 389-397. |
| [57] |
Iliopoulou EF, Stefanidis SD, Kalogiannis KG, et al. (2012). Catalytic upgrading of biomass pyrolysis vapors using transition metal-modified ZSM-5 zeolite. Appl Catal B 127: 281-290. doi: 10.1016/j.apcatb.2012.08.030
|
| [58] |
Adjaye JD, Bakhshi NN (1995) Catalytic conversion of a biomass-derived oil to fuels and chemicals I: Model compound studies and reaction pathways. Biomass Bioenerg 8: 131-149. doi: 10.1016/0961-9534(95)00018-3
|
| [59] |
Zhao C, Lercher JA (2012) Upgrading Pyrolysis Oil over Ni/HZSM-5 by Cascade Reactions. Angew Chem 124: 6037-6042. doi: 10.1002/ange.201108306
|
| [60] | Torri C, Fabbri D, Garcia-Alba L, et al. (2013) Upgrading of oils derived from hydrothermal treatment of microalgae by catalytic cracking over H-ZSM-5: A comparative Py–GC–MS study. J Anal Appl Pyrolysis 101: 28-34. |
| [61] |
Huynh TM, Armbruster U, Nguyen LH, et al. (2015) Hydrodeoxygenation of Bio-Oil on Bimetallic Catalysts: From Model Compound to Real Feed. J Sustainable Bioenergy Syst 5: 151-160. doi: 10.4236/jsbs.2015.54014
|
| [62] |
Zhang X, Wang T, Ma L, et al. (2013) Hydrotreatment of bio-oil over Ni-based catalyst. Bioresour Technol 127: 306-311. doi: 10.1016/j.biortech.2012.07.119
|
| [63] |
Thangalazhy-Gopakumar S, Adhikari S, Gupta RB (2012) Catalytic pyrolysis of biomass over H+ ZSM-5 under hydrogen pressure. Energ Fuel 26: 5300-5306. doi: 10.1021/ef3008213
|
| [64] |
Weng Y, Qiu S, Ma L, et al. (2015) Jet-Fuel Range Hydrocarbons from Biomass-Derived Sorbitol over Ni-HZSM-5/SBA-15 Catalyst. Catalysts 5: 2147-2160. doi: 10.3390/catal5042147
|
| [65] |
Li X, Su L, Wang Y, et al. (2012) Catalytic fast pyrolysis of Kraft lignin with HZSM-5 zeolite for producing aromatic hydrocarbons. Front Environ Sci Eng 6: 295-303. doi: 10.1007/s11783-012-0410-2
|
| [66] |
Cheng S, Wei L, Zhao X (2016) Development of a bifunctional Ni/HZSM-5 catalyst for converting prairie cordgrass to hydrocarbon biofuel. Energy Sources Part A 38: 2433-2437. doi: 10.1080/15567036.2015.1065298
|
| [67] | Mortensen PM, Grunwaldt JD, Jensen PA, et al. (2011) A review of catalytic upgrading of bio-oil to engine fuels. Appl Catal A 407: 1-19. |
| [68] |
Ganjkhanlou Y, Groppo E, Bordiga S, et al. (2016) Incorporation of Ni into HZSM-5 zeolites: Effects of zeolite morphology and incorporation procedure. Micropor Mesopor Mat 229: 76-82. doi: 10.1016/j.micromeso.2016.04.002
|
| [69] |
Lv M, Zhou J, Yang W, et al. (2010) Thermogravimetric analysis of the hydrolysis of zinc particles. Int J Hydrogen Energy 35: 2617-2621. doi: 10.1016/j.ijhydene.2009.04.017
|
| [70] |
Balat M (2008) Mechanisms of thermochemical biomass conversion processes. Part 3: reactions of liquefaction. Energy Sources Part A 30: 649-659. doi: 10.1080/10407780600817592
|
| [71] |
Brown TM, Duan P, Savage PE (2010) Hydrothermal liquefaction and gasification of Nannochloropsis sp. Energ Fuel 24: 3639-3646. doi: 10.1021/ef100203u
|
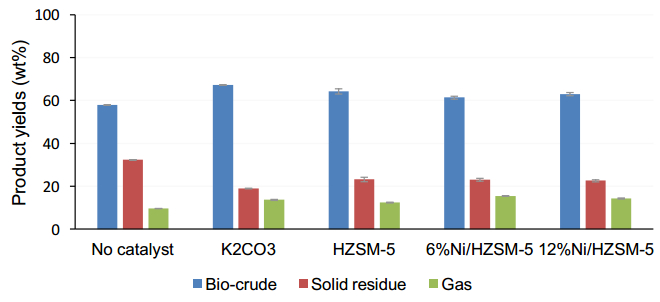
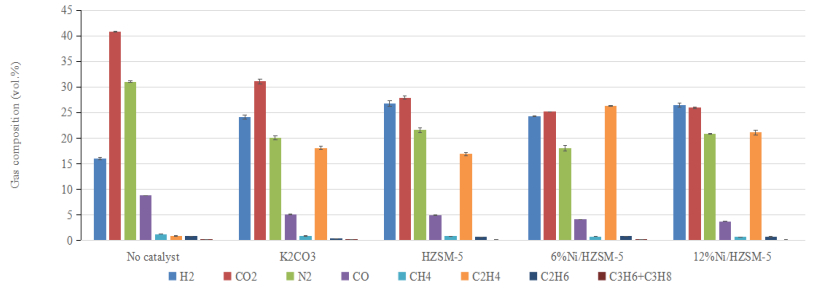
Figures(2) / Tables(4)

Shouyun Cheng, Lin Wei, Mustafa Alsowij, Fletcher Corbin, Eric Boakye, Zhengrong Gu, Douglas Raynie. Catalytic hydrothermal liquefaction (HTL) of biomass for bio-crude production using Ni/HZSM-5 catalysts[J]. AIMS Environmental Science, 2017, 4(3): 417-430. doi: 10.3934/environsci.2017.3.417







 DownLoad:
DownLoad: