Citation: Romain Breuneval, Guy Clerc, Babak Nahid-Mobarakeh, Badr Mansouri. Classification with automatic detection of unknown classes based on SVM and fuzzy MBF: Application to motor diagnosis[J]. AIMS Electronics and Electrical Engineering, 2018, 2(3): 59-84. doi: 10.3934/ElectrEng.2018.3.59

| [1] | Polo G (2011) On maritime transport costs, evolution, and forecast. Ship Science and Technology, 5: 19–31. |
| [2] | Operations and Maintenance (O&M) Costs Technical Memorandum, 2015. PARSONS BRINCKERHOFF –AECOM. Available from:https://www.fra.dot.gov/necfuture/pdfs/feis/volume_2/appendix/app_b09.pdf. |
| [3] | Markou C, Cros G, Sng A (2015) Airline Maintenance Cost Executive Commentary. IATA. Available from:https://www.iata.org/whatwedo/workgroups/Documents/MCTF/AMC-Exec-Comment-FY14.pdf. |
| [4] | Thomson R, Edwards M, Britton E, et al. (2014) Predictive Maintenance : Is the timing right for predictive maintenance in the manufacturing sector ? Roland Berger Strategy Consultants. |
| [5] | Fumera G, Roli F (2002) Support vector machines with embedded reject option, In: Pattern Recognition with Support Vector Machines. Springer, 68–82. |
| [6] | Grandvalet Y, Rakotomamonjy A, Keshet J, et al. (2009) Support vector machines with a reject option, In: Advances in Neural Information Processing Systems. 537–544. |
| [7] |
Wegkamp M, Yuan M (2011) Support vector machines with a reject option. Bernoulli 17: 1368–1385. Available from: https://projecteuclid.org/euclid.bj/1320417508. doi: 10.3150/10-BEJ320

|
| [8] | Abe S, Inoue T (2002) Fuzzy Support Vector Machines for Multiclass Problems. European Symposium on Artificial Neural Networks, Bruges (Belgium). |
| [9] |
Lin CF, Wang SD (2002) Fuzzy support vector machines. IEEE Transaction on Neural Network 13: 464–471. doi: 10.1109/72.991432
|
| [10] | Ma H, Xiong Y, Fang H, et al. (2015) Fault diagnosis of bearing based on fuzzy support vector machine, In: 2015 Prognostics and System Health Management Conference (PHM), 1–4. |
| [11] |
Ebrahimi H, Gatabi JR, El-Kishky H (2015) An auxiliary power unit for advanced aircraft electric power systems. Electr Pow Syst Res 119: 393–406. doi: 10.1016/j.epsr.2014.10.023
|
| [12] |
Guan Y, Zhu ZQ, Afinowi IAA, et al. (2016) Difference in maximum torque-speed characteristics of induction machine between motor and generator operation modes for electric vehicle application. Electr Pow Syst Res 136: 406–414. doi: 10.1016/j.epsr.2016.03.027
|
| [13] | Wu Y, Jiang B, Lu N, et al. (2016) Multiple incipient sensor faults diagnosis with application to high-speed railway traction devices. ISA T 67:183–192. |
| [14] |
Baraldi P, Cannarile F, Maio FD, et al. (2016) Hierarchical k-nearest neighbours classification and binary differential evolution for fault diagnostics of automotive bearings operating under variable conditions. Eng Appl Artif Intel 56: 1–13. doi: 10.1016/j.engappai.2016.08.011
|
| [15] |
Bessam B, Menacer A, Boumehraz M, et al. (2016) Detection of broken rotor bar faults in induction motor at low load using neural network. ISA T 64: 241–246. doi: 10.1016/j.isatra.2016.06.004
|
| [16] |
Ferracuti F, Giantomassi A, Iarlori S, et al. (2015) Electric motor defects diagnosis based on kernel density estimation and Kullback–Leibler divergence in quality control scenario. Eng Appl Artif Intel 44: 25–32. doi: 10.1016/j.engappai.2015.05.004
|
| [17] |
Glowacz A, Glowacz Z (2017) Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys Techn 81: 7–16. doi: 10.1016/j.infrared.2016.12.003
|
| [18] | Vapnik VN (1995) The Nature of Statistical Learning Theory. Springer-Verlag New York, Inc., New York, NY, USA. |
| [19] | Han G, Meng-Kun L (2018) Induction motor faults diagnosis using support vector machine to the motor current signature. IEEE Industrial Cyber-Physical Systems (ICPS), 417–421. |
| [20] | Camarena-Martinez D, Valtierra-Rodriguez M, Amezquita-Sanchez JP, et al. (2016) Shannon Entropy and K-Means Method for Automatic Diagnosis of Broken Rotor Bars in Induction Motors Using Vibration Signals. Shock Vib Article ID: 4860309. |
| [21] |
Burges CJC (1998) A Tutorial on Support Vector Machines for Pattern Recognition. Data Min Knowl Disc 2: 121–167. doi: 10.1023/A:1009715923555
|
| [22] | Bottou L, Lin CJ (2007) Support vector machine solvers. Large scale kernel machines 3: 301–320. |
| [23] |
Zadeh LA (1965) Fuzzy sets. Information and Control 8: 338–353. doi: 10.1016/S0019-9958(65)90241-X
|
| [24] | Gassert H (2004) Operators on Fuzzy Sets: Zadeh and Einstein. Seminar Paper, Department of Computer Science Information Systems Group, University of Fribourg. |
| [25] |
Mizumoto M, Tanaka K (1981) Fuzzy sets and their operations. Information and Control 48: 30–48. doi: 10.1016/S0019-9958(81)90578-7
|
| [26] |
Ondel O, Clerc G, Boutleux E, et al. (2009) Fault Detection and Diagnosis in a Set "Inverter–Induction Machine" Through Multidimensional Membership Function and Pattern Recognition. IEEE Transaction on Energy Conversion 24: 431–441. doi: 10.1109/TEC.2008.921559
|
| [27] | Ondel O (2006) Diagnosis by Pattern Recognition: application on a set inverter – induction machine. Ecole Centrale de Lyon. |
| [28] | Bolander N, Qiu H, Eklund N, et al. (2009) Physics-based Remaining Useful Life Prediction for Aircraft Engine Bearing Prognosis. Annual Conference of the Prognostics and Health Management Society. |
| [29] | Deleroi W (1982) Squirrel cage motor with broken bar in the rotor-Physical phenomena and their experimental assessment. Proc of Int Conf on Electrical Machines (ICEM), Budapest, Hungary, 767–771. |
| [30] |
Venet P, Lahyani A, Grellet G, et al. (1999) Influence of aging on electrolytic capacitors function in static converters: Fault prediction method. Eur Phys J-Appl Phys 5: 71–83. doi: 10.1051/epjap:1999112
|
| [31] | Schoen RR, Habetler TG, Kamran F, et al (1994) Motor bearing damage detection using stator current monitoring, In: Proceedings of 1994 IEEE Industry Applications Society Annual Meeting 1: 110–116. |
| [32] | Schoen RR, Habetler TG (1993) Effects of time-varying loads on rotor fault detection in induction machines, In: Conference Record of the 1993 IEEE Industry Applications Conference Twenty-Eighth IAS Annual Meeting 1: 324–330. |
| [33] | Vas P (1992) Electrical machines and drives: a space-vector theory approach, Monographs in electrical and electronic engineering. Clarendon Press. |
| [34] | Casimir R, Boutleux E, Clerc G, et al. (2003) Broken bars detection in an induction motor by pattern recognition, In: IEEE Bologna Power Tech Conference Proceedings 2: 313–319. |
| [35] |
Kudo M, Sklansky J (2000) Comparison of algorithms that select features for pattern classifiers. Pattern Recogn 33: 25–41. doi: 10.1016/S0031-3203(99)00041-2
|
| [36] | Larsen J, Goutte C (1999) On optimal data split for generalization estimation and model selection, In: Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop, 225–234. |
| [37] | Zalila Z, Cuquemelle J, Penet C, et al. (2006) Is your accurate model actually robust ? Regulation and validation methods by xtractis. Sensometrics 2006–Imagine the Senses, Norway. |
| [38] | Plutowski ME (1996) Survey : Cross-validation in theory and practise (Research Report). David Sarnoff Research Center - Princeton. |
| [39] |
Shao J (1993) Linear model selection by cross-validation. J Am Stat Assoc 88: 486–494. doi: 10.1080/01621459.1993.10476299
|
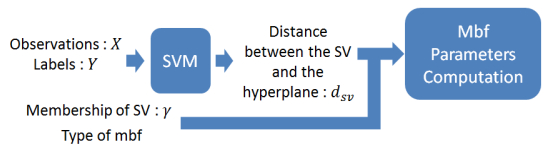
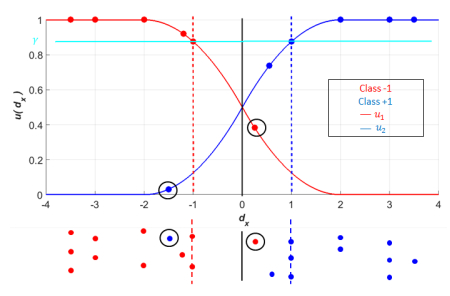


Figures(16) / Tables(19)

Romain Breuneval, Guy Clerc, Babak Nahid-Mobarakeh, Badr Mansouri. Classification with automatic detection of unknown classes based on SVM and fuzzy MBF: Application to motor diagnosis[J]. AIMS Electronics and Electrical Engineering, 2018, 2(3): 59-84. doi: 10.3934/ElectrEng.2018.3.59







 DownLoad:
DownLoad: