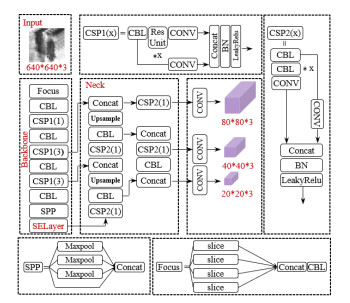
To address the challenge of achieving a balance between efficiency and performance in steel surface defect detection, this paper presents a novel algorithm that enhances the YOLOv5 defect detection model. The enhancement process begins by employing the K-means++ algorithm to fine-tune the location of the prior anchor boxes, improving the matching process. Subsequently, the loss function is transitioned from generalized intersection over union (GIOU) to efficient intersection over union (EIOU) to mitigate the former's degeneration issues. To minimize information loss, Carafe upsampling replaces traditional upsampling techniques. Lastly, the squeeze and excitation networks (SE-Net) module is incorporated to augment the model's sensitivity to channel features. Experimental evaluations conducted on a public defect dataset reveal that the proposed method elevates the mean average precision (mAP) by seven percentage points compared to the original YOLOv5 model, achieving an mAP of 83.3%. Furthermore, our model's size is significantly reduced compared to other advanced algorithms, while maintaining a processing speed of 47 frames per second. This performance demonstrates the effectiveness of the proposed enhancements in improving both accuracy and efficiency in defect detection.
Citation: Yiwen Jiang. Surface defect detection of steel based on improved YOLOv5 algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19858-19870. doi: 10.3934/mbe.2023879
To address the challenge of achieving a balance between efficiency and performance in steel surface defect detection, this paper presents a novel algorithm that enhances the YOLOv5 defect detection model. The enhancement process begins by employing the K-means++ algorithm to fine-tune the location of the prior anchor boxes, improving the matching process. Subsequently, the loss function is transitioned from generalized intersection over union (GIOU) to efficient intersection over union (EIOU) to mitigate the former's degeneration issues. To minimize information loss, Carafe upsampling replaces traditional upsampling techniques. Lastly, the squeeze and excitation networks (SE-Net) module is incorporated to augment the model's sensitivity to channel features. Experimental evaluations conducted on a public defect dataset reveal that the proposed method elevates the mean average precision (mAP) by seven percentage points compared to the original YOLOv5 model, achieving an mAP of 83.3%. Furthermore, our model's size is significantly reduced compared to other advanced algorithms, while maintaining a processing speed of 47 frames per second. This performance demonstrates the effectiveness of the proposed enhancements in improving both accuracy and efficiency in defect detection.

| [1] |
Q. Luo, X. Fang, L. Liu, C. Yang, Y. Sun, Automated visual defect detection for flat steel surface: A survey, IEEE Trans. Instrum. Meas., 69 (2020), 626–644. https://doi.org/10.1109/TIM.2019.2963555 doi: 10.1109/TIM.2019.2963555

|
| [2] |
R. Mordia, A. K. Verma, Visual techniques for defects detection in steel products: A comparative study, Eng. Failure Anal., 134 (2022), 106047. https://doi.org/10.1016/j.engfailanal.2022.106047 doi: 10.1016/j.engfailanal.2022.106047
|
| [3] |
B. Tang, L. Chen, W. Sun, Z. Lin, Review of surface defect detection of steel products based on machine vision, IET Image Process., 17 (2023), 303–322. https://doi.org/10.1049/ipr2.12647 doi: 10.1049/ipr2.12647
|
| [4] |
H. Wang, J. Zhang, Y. Tian, H. Chen, H. Sun, K. Liu, A simple guidance template-based defect detection method for strip steel surfaces, IEEE Trans. Ind. Inform., 15 (2018), 2798–2809. https://doi.org/10.1109/TII.2018.2887145 doi: 10.1109/TII.2018.2887145
|
| [5] | G. K. Nand, Noopur, N. Neogi,, Defect detection of steel surface using entropy segmentation, in 2014 Annual IEEE India Conference (INDICON), (2014), 1–6. https://doi.org/10.1109/INDICON.2014.7030439 |
| [6] |
G. H. Hu, Automated defect detection in textured surfaces using optimal elliptical Gabor filters, Optik, 126 (2015), 1331–1340. https://doi.org/10.1016/j.ijleo.2015.04.017 doi: 10.1016/j.ijleo.2015.04.017
|
| [7] |
X. Xu, Y. Lei, F. Yang, Railway subgrade defect automatic recognition method based on improved faster R-CNN, Sci. Program., 2018 (2018). https://doi.org/10.1155/2018/4832972 doi: 10.1155/2018/4832972
|
| [8] |
S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, Adv. Neural Inform. Process. Syst., 28 (2015). https://doi.org/10.48550/arXiv.1506.01497 doi: 10.48550/arXiv.1506.01497
|
| [9] | M. Abu, A. Amir, Y. H. Lean, N. A. H. Zahri, S. A. Azemi, The performance analysis of transfer learning for steel defect detection by using deep learning, in Journal of Physics: Conference Series, 1755 (2021), 012041. https://doi.org/10.1088/1742-6596/1755/1/012041 |
| [10] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [11] |
S. Tammina, Transfer learning using vgg-16 with deep convolutional neural network for classifying images, Int. J. Sci. Res. Publ., 9 (2019), 143–150. https://doi.org/10.29322/IJSRP.9.10.2019.p9420 doi: 10.29322/IJSRP.9.10.2019.p9420
|
| [12] |
Y. Li, H. Huang, Q. Xie, L. Yao, Q. Chen, Research on a surface defect detection algorithm based on MobileNet-SSD, Appl. Sci., 8 (2018), 1678. https://doi.org/10.3390/app8091678 doi: 10.3390/app8091678
|
| [13] |
Y. He, K. Song, Q. Meng, Y. Yan, An end-to-end steel surface defect detection approach via fusing multiple hierarchical features, IEEE Trans. Instrum. Meas., 69 (2019), 1493–1504. https://doi.org/10.1109/TIM.2019.2915404 doi: 10.1109/TIM.2019.2915404
|
| [14] |
C. Zhao, X. Shu, X. Yan, X. Zuo, F. Zhu, RDD-YOLO: A modified YOLO for detection of steel surface defects, Measurement, 214 (2023), 112776. https://doi.org/10.1016/j.measurement.2023.112776 doi: 10.1016/j.measurement.2023.112776
|
| [15] |
B. Zhu, G. Xiao, Y. Zhang, H. Gao, Multi-classification recognition and quantitative characterization of surface defects in belt grinding based on YOLOv7, Measurement, 216 (2023), 112937. https://doi.org/10.1016/j.measurement.2023.112937 doi: 10.1016/j.measurement.2023.112937
|
| [16] |
Z. Ma, Y. Li, M. Huang, J. Cheng, S. Tang, A lightweight detector based on attention mechanism for aluminum strip surface defect detection, Comput. Ind., 136 (2022), 103585. https://doi.org/10.1016/j.compind.2022.103585 doi: 10.1016/j.compind.2022.103585
|
| [17] |
Y. Li, M. Ni, Y. Lu, Insulator defect detection for power grid based on light correction enhancement and YOLOv5 model, Energy Rep., 8 (2022), 807–814. https://doi.org/10.1016/j.egyr.2022.08.007 doi: 10.1016/j.egyr.2022.08.007
|
| [18] |
P. Jiang, D. Ergu, F. Liu, Y. Cai, B. Ma, A Review of Yolo algorithm developments, Proc. Comput. Sci., 199 (2022), 1066–1073. https://doi.org/10.1016/j.procs.2022.01.135 doi: 10.1016/j.procs.2022.01.135
|
| [19] |
K. Zhao, Y. Wang, Y. Zuo, C. Zhang, Palletizing robot positioning bolt detection based on improved YOLO-V3, J. Intell. Robotic Syst., 104 (2022), 41. https://doi.org/10.1007/s10846-022-01580-w doi: 10.1007/s10846-022-01580-w
|
| [20] | H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, S. Savarese, Generalized intersection over union: A metric and a loss for bounding box regression, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 658–666. https://doi.org/10.1109/CVPR.2019.00075 |
| [21] |
Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, T. Tan, Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing, 506 (2022), 146–157. https://doi.org/10.1016/j.neucom.2022.07.042 doi: 10.1016/j.neucom.2022.07.042
|
| [22] | J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, D. Lin, Carafe: Content-aware reassembly of features, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 3007–3016. https://doi.org/10.1109/ICCV.2019.00310 |
| [23] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. |
| [24] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 7132–7141. https://doi.org/10.1109/CVPR.2018.00745 |
| [25] |
M. Ahmed, R. Seraj, S. M. S. Islam, The k-means algorithm: A comprehensive survey and performance evaluation, Electronics, 9 (2020), 1295. https://doi.org/10.3390/electronics9081295 doi: 10.3390/electronics9081295
|
| [26] |
Z. Niu, G. Zhong, H. Yu, A review on the attention mechanism of deep learning, Neurocomputing, 452 (2021), 48–62. https://doi.org/10.1016/j.neucom.2021.03.091 doi: 10.1016/j.neucom.2021.03.091
|
| [27] |
K. Song, Y. Yan, A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects, Appl. Surface Sci., 285 (2013), 858–864. https://doi.org/10.1016/j.apsusc.2013.09.002 doi: 10.1016/j.apsusc.2013.09.002
|
| [28] | A. Van Etten, You only look twice: Rapid multi-scale object detection in satellite imagery, preprint, arXiv: 1805.09512. https://doi.org/10.48550/arXiv.1805.09512 |
| [29] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, et al., Ssd: Single shot multibox detector, in Computer Vision--ECCV 2016: 14th European Conference, (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [30] |
Z. Guo, C. Wang, G. Yang, Z. Huang, G. Li, MSFT-YOLO: Improved YOLOv5 based on transformer for detecting defects of steel surface, Sensors, 22 (2022), 3467. https://doi.org/10.3390/s22093467 doi: 10.3390/s22093467
|




Figures(5) / Tables(3)

Yiwen Jiang. Surface defect detection of steel based on improved YOLOv5 algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19858-19870. doi: 10.3934/mbe.2023879







 DownLoad:
DownLoad: