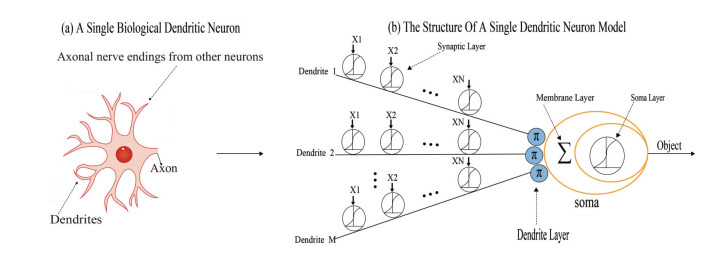
McCulloch-Pitts neuron-based neural networks have been the mainstream deep learning methods, achieving breakthrough in various real-world applications. However, McCulloch-Pitts neuron is also under longtime criticism of being overly simplistic. To alleviate this issue, the dendritic neuron model (DNM), which employs non-linear information processing capabilities of dendrites, has been widely used for prediction and classification tasks. In this study, we innovatively propose a hybrid approach to co-evolve DNM in contrast to back propagation (BP) techniques, which are sensitive to initial circumstances and readily fall into local minima. The whale optimization algorithm is improved by spherical search learning to perform co-evolution through dynamic hybridizing. Eleven classification datasets were selected from the well-known UCI Machine Learning Repository. Its efficiency in our model was verified by statistical analysis of convergence speed and Wilcoxon sign-rank tests, with receiver operating characteristic curves and the calculation of area under the curve. In terms of classification accuracy, the proposed co-evolution method beats 10 existing cutting-edge non-BP methods and BP, suggesting that well-learned DNMs are computationally significantly more potent than conventional McCulloch-Pitts types and can be employed as the building blocks for the next-generation deep learning methods.
Citation: Hang Yu, Jiarui Shi, Jin Qian, Shi Wang, Sheng Li. Single dendritic neural classification with an effective spherical search-based whale learning algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7594-7632. doi: 10.3934/mbe.2023328
McCulloch-Pitts neuron-based neural networks have been the mainstream deep learning methods, achieving breakthrough in various real-world applications. However, McCulloch-Pitts neuron is also under longtime criticism of being overly simplistic. To alleviate this issue, the dendritic neuron model (DNM), which employs non-linear information processing capabilities of dendrites, has been widely used for prediction and classification tasks. In this study, we innovatively propose a hybrid approach to co-evolve DNM in contrast to back propagation (BP) techniques, which are sensitive to initial circumstances and readily fall into local minima. The whale optimization algorithm is improved by spherical search learning to perform co-evolution through dynamic hybridizing. Eleven classification datasets were selected from the well-known UCI Machine Learning Repository. Its efficiency in our model was verified by statistical analysis of convergence speed and Wilcoxon sign-rank tests, with receiver operating characteristic curves and the calculation of area under the curve. In terms of classification accuracy, the proposed co-evolution method beats 10 existing cutting-edge non-BP methods and BP, suggesting that well-learned DNMs are computationally significantly more potent than conventional McCulloch-Pitts types and can be employed as the building blocks for the next-generation deep learning methods.

| [1] |
C. Lee, H. Hasegawa, S. Gao, Complex-valued neural networks: a comprehensive survey, IEEE/CAA J. Autom. Sin., 9 (2022), 1406–1426. https://doi.org/10.1109/JAS.2022.105743 doi: 10.1109/JAS.2022.105743

|
| [2] | Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015), 436–444. https://doi.org/10.1038/nature14539 |
| [3] |
Z. Zhang, J. Geiger, J. Pohjalainen, A. E. D. Mousa, W. Jin, B. Schuller, Deep learning for environmentally robust speech recognition: an overview of recent developments, ACM Trans. Intell. Syst. Technol., 9 (2018), 1–28. https://doi.org/10.1145/3178115 doi: 10.1145/3178115
|
| [4] |
Y. Guo, Y. Liu, A. Oerlemans, S. Lao, S. Wu, M. S. Lew, Deep learning for visual understanding: a review, Neurocomputing, 187 (2016), 27–48. https://doi.org/10.1016/j.neucom.2015.09.116 doi: 10.1016/j.neucom.2015.09.116
|
| [5] |
D. Guo, M. Zhong, H. Ji, Y. Liu, R. Yang, A hybrid feature model and deep learning based fault diagnosis for unmanned aerial vehicle sensors, Neurocomputing, 319 (2018), 155–163. https://doi.org/10.1016/j.neucom.2018.08.046 doi: 10.1016/j.neucom.2018.08.046
|
| [6] |
J. Cheng, M. Ju, M. Zhou, C. Liu, S. Gao, A. Abusorrah, et al., A dynamic evolution method for autonomous vehicle groups in a highway scene, IEEE Internet Things J., 9 (2021), 1445–1457. https://doi.org/10.1109/JIOT.2021.3086832 doi: 10.1109/JIOT.2021.3086832
|
| [7] |
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, et al., Highly accurate protein structure prediction with AlphaFold, Nature, 596 (2021), 583–589. https://doi.org/10.1038/s41586-021-03819-2 doi: 10.1038/s41586-021-03819-2
|
| [8] | I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, arXiv preprint, (2014), arXiv: 1406.2661. https://doi.org/10.48550/arXiv.1406.2661 |
| [9] | B. Zoph, Q. V. Le, Neural architecture search with reinforcement learning, arXiv preprint, (2016), arXiv: 1611.01578. https://doi.org/10.48550/arXiv.1611.01578 |
| [10] |
S. J. Pan, Q. Yang, A survey on transfer learning, IEEE Trans. Knowl. Data Eng., 22 (2009), 1345–1359, https://doi.org/10.1109/TKDE.2009.191 doi: 10.1109/TKDE.2009.191
|
| [11] |
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, et al., Advances and open problems in federated learning, Found. Trends Mach. Learn., 14 (2021), 1–210. https://doi.org/10.1561/2200000083 doi: 10.1561/2200000083
|
| [12] |
Y. Zhang, Q. Yang, A survey on multi-task learning, IEEE Trans. Knowl. Data Eng., 34 (2022), 5586–5609. http://doi.org/10.1109/TKDE.2021.3070203 doi: 10.1109/TKDE.2021.3070203
|
| [13] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, Adv. Neural Inf. Process. Syst. (NIPS), 30 (2017), 5998–6008. |
| [14] |
F. Han, J. Jiang, Q. H. Ling, B. Y. Su, A survey on metaheuristic optimization for random single-hidden layer feedforward neural network, Neurocomputing, 335 (2019), 261–273. https://doi.org/10.1016/j.neucom.2018.07.080 doi: 10.1016/j.neucom.2018.07.080
|
| [15] |
D. Yarotsky, Error bounds for approximations with deep ReLU networks, Neural Networks, 94 (2017), 103–114. http://doi.org/10.1016/j.neunet.2017.07.002 doi: 10.1016/j.neunet.2017.07.002
|
| [16] | S. Ruder, An overview of gradient descent optimization algorithms, arXiv preprint, (2016), arXiv: 1609.04747. https://doi.org/10.48550/arXiv.1609.04747 |
| [17] |
G. E. Hinton, S. Osindero, Y. W. Teh, A fast learning algorithm for deep belief nets, Neural Comput., 18 (2006), 1527–1554. http://doi.org/10.1162/neco.2006.18.7.1527 doi: 10.1162/neco.2006.18.7.1527
|
| [18] |
S. Sun, Z. Cao, H. Zhu, J. Zhao, A survey of optimization methods from a machine learning perspective, IEEE Trans. Cybern., 50 (2019), 3668–3681. https://doi.org/10.1109/TCYB.2019.2950779 doi: 10.1109/TCYB.2019.2950779
|
| [19] |
M. A. Ferrag, L. Shu, O. Friha, X. Yang, Cyber security intrusion detection for agriculture 4.0: machine learning-based solutions, datasets, and future directions, IEEE/CAA J. Autom. Sin., 9 (2021), 407–436. https://doi.org/10.1109/JAS.2021.1004344 doi: 10.1109/JAS.2021.1004344
|
| [20] | Z. Lu, H. Pu, F. Wang, Z. Hu, L. Wang, The expressive power of neural networks: a view from the width, Adv. Neural Inf. Process. Syst. (NIPS), 30, (2017). |
| [21] |
H. P. Beise, S. D. Da Cruz, U. Schröder, On decision regions of narrow deep neural networks, Neural Networks, 140 (2021), 121–129. https://doi.org/10.1016/j.neunet.2021.02.024 doi: 10.1016/j.neunet.2021.02.024
|
| [22] |
J. He, H. Yang, L. He, L. Zhao, Neural networks based on vectorized neurons, Neurocomputing, 465 (2021), 63–70. https://doi.org/10.1016/j.neucom.2021.09.006 doi: 10.1016/j.neucom.2021.09.006
|
| [23] |
S. Q. Zhang, W. Gao, Z. H. Zhou, Towards understanding theoretical advantages of complex-reaction networks, Neural Networks, 151 (2022), 80–93. https://doi.org/10.1016/j.neunet.2022.03.024 doi: 10.1016/j.neunet.2022.03.024
|
| [24] |
S. Ostojic, N. Brunel, From spiking neuron models to linear-nonlinear models, PLoS Comput. Biol., 7 (2011), e1001056. https://doi.org/10.1371/journal.pcbi.1001056 doi: 10.1371/journal.pcbi.1001056
|
| [25] |
T. Zhou, S. Gao, J. Wang, C. Chu, Y. Todo, Z. Tang, Financial time series prediction using a dendritic neuron model, Knowl. Based Syst., 105 (2016), 214–224. https://doi.org/10.1016/j.knosys.2016.05.031 doi: 10.1016/j.knosys.2016.05.031
|
| [26] |
T. Zhang, C. Lv, F. Ma, K. Zhao, H. Wang, G. M. O'Hare, A photovoltaic power forecasting model based on dendritic neuron networks with the aid of wavelet transform, Neurocomputing, 397 (2020), 438–446. https://doi.org/10.1016/j.neucom.2019.08.105 doi: 10.1016/j.neucom.2019.08.105
|
| [27] | S. Ghosh-Dastidar, H. Adeli, Spiking neural networks, Int. J. Neural Syst., 19 (2009), 295–308. https://doi.org/10.1142/S0129065709002002 |
| [28] |
S. R. Kheradpisheh, T. Masquelier, Temporal backpropagation for spiking neural networks with one spike per neuron, Int. J. Neural Syst., 30 (2020), 2050027. https://doi.org/10.1142/S0129065720500276 doi: 10.1142/S0129065720500276
|
| [29] |
X. Wang, X. Lin, X. Dang, Supervised learning in spiking neural networks: a review of algorithms and evaluations, Neural Networks, 125 (2020), 258–280. https://doi.org/10.1016/j.neunet.2020.02.011 doi: 10.1016/j.neunet.2020.02.011
|
| [30] |
L. Deng, Y. Wu, X. Hu, L. Liang, Y. Ding, G. Li, et al., Rethinking the performance comparison between SNNs and ANNs, Neural Networks, 121 (2020), 294–307. https://doi.org/10.1016/j.neunet.2019.09.005 doi: 10.1016/j.neunet.2019.09.005
|
| [31] |
S. WoĖniak, A. Pantazi, T. Bohnstingl, E. Eleftheriou, Deep learning incorporating biologically inspired neural dynamics and in-memory computing, Nat. Mach. Intell., 2 (2020), 325–336. https://doi.org/10.1038/s42256-020-0187-0 doi: 10.1038/s42256-020-0187-0
|
| [32] |
P. Poirazi, A. Papoutsi, Illuminating dendritic function with computational models, Nat. Rev. Neurosci., 21 (2020), 303–321. https://doi.org/10.1038/s42256-020-0187-0 doi: 10.1038/s42256-020-0187-0
|
| [33] |
A. Gidon, T. A. Zolnik, P. Fidzinski, F. Bolduan, A. Papoutsi, P. Poirazi, et al., Dendritic action potentials and computation in human layer 2/3 cortical neurons, Science, 367 (2020), 83–87. https://doi.org/10.1126/science.aax6239 doi: 10.1126/science.aax6239
|
| [34] |
R. L. Wang, Z. Lei, Z. Zhang, S. Gao, Dendritic convolutional neural network, IEEJ Trans. Electron. Inf. Syst., 17 (2022), 302–304. https://doi.org/10.1002/tee.23513 doi: 10.1002/tee.23513
|
| [35] | J. Li, Z. Liu, R. L. Wang, S. Gao, Dendritic deep residual learning for COVID-19 prediction, IEEJ Trans. Electron. Inf. Syst., 18 (2022) 297–299. https://doi.org/10.1002/tee.23723 |
| [36] |
Z. H. Zhan, L. Shi, K. C. Tan, J. Zhang, A survey on evolutionary computation for complex continuous optimization, Artif. Intell. Rev., 55 (2022), 59–110. https://doi.org/10.1007/s10462-021-10042-y doi: 10.1007/s10462-021-10042-y
|
| [37] | J. Greensmith, U. Aickelin, S. Cayzer, Introducing dendritic cells as a novel immune-inspired algorithm for anomaly detection, in International Conference on Artificial Immune Systems (ICARIS 2005), Springer, (2005), 153–167. https://doi.org/10.1007/11536444_12 |
| [38] | M. London, M. Häusser, Dendritic computation, Annu. Rev. Neurosci., 28 (2005), 503–532. https://doi.org/10.1146/annurev.neuro.28.061604.135703 |
| [39] |
H. Agmon-Snir, C. E. Carr, J. Rinzel, The role of dendrites in auditory coincidence detection, Nature, 393 (1998), 268–272. https://doi.org/10.1038/30505 doi: 10.1038/30505
|
| [40] |
T. Euler, P. B. Detwiler, W. Denk, Directionally selective calcium signals in dendrites of starburst amacrine cells, Nature, 418 (2002), 845–852. https://doi.org/10.1038/nature00931 doi: 10.1038/nature00931
|
| [41] | C. Koch, T. Poggio, V. Torre, Nonlinear interactions in a dendritic tree: localization, timing, and role in information processing, Proc. Natl. Acad. Sci., 80 (1983), 2799–2802. https://doi.org/10.1073/pnas.80.9.2799 |
| [42] |
S. Chavlis, P. Poirazi, Drawing inspiration from biological dendrites to empower artificial neural networks, Curr. Opin. Neurobiol., 70 (2021), 1–10. https://doi.org/10.1016/j.conb.2021.04.007 doi: 10.1016/j.conb.2021.04.007
|
| [43] |
J. Guerguiev, T. P. Lillicrap, B. A. Richards, Towards deep learning with segregated dendrites, Elife, 6 (2017), e22901. https://doi.org/10.7554/eLife.22901 doi: 10.7554/eLife.22901
|
| [44] |
T. Moldwin, M. Kalmenson, I. Segev, The gradient clusteron: a model neuron that learns to solve classification tasks via dendritic nonlinearities, structural plasticity, and gradient descent, PLoS Comput. Biol., 17 (2021), e1009015. https://doi.org/10.1371/journal.pcbi.1009015 doi: 10.1371/journal.pcbi.1009015
|
| [45] |
C. Koch, I. Segev, The role of single neurons in information processing, Nat. Neurosci., 3 (2000), 1171–1177. https://doi.org/10.1038/81444 doi: 10.1038/81444
|
| [46] |
P. Poirazi, T. Brannon, B. W. Mel, Pyramidal neuron as two-layer neural network, Neuron, 37 (2003), 989–999. https://doi.org/10.1016/S0896-6273(03)00149-1 doi: 10.1016/S0896-6273(03)00149-1
|
| [47] |
R. Legenstein, W. Maass, Branch-specific plasticity enables self-organization of nonlinear computation in single neurons, J. Neurosci., 31 (2011), 10787–10802. https://doi.org/10.1523/JNEUROSCI.5684-10.2011 doi: 10.1523/JNEUROSCI.5684-10.2011
|
| [48] | I. S. Jones, K. P. Kording, Might a single neuron solve interesting machine learning problems through successive computations on its dendritic tree, Neural Comput., 33 (2021), 1554–1571. https://doi.org/10.1162/neco_a_01390 |
| [49] | Y. Todo, H. Tamura, K. Yamashita, Z. Tang, Unsupervised learnable neuron model with nonlinear interaction on dendrites, Neural Networks, 60 (2014), 96–103. https://doi.org/10.1016/j.neunet.2014.07.011 |
| [50] |
S. Gao, M. Zhou, Y. Wang, J. Cheng, H. Yachi, J. Wang, Dendritic neuron model with effective learning algorithms for classification, approximation, and prediction, IEEE Trans. Neural Networks Learn. Syst., 30 (2019), 601–614. https://doi.org/10.1109/TNNLS.2018.2846646 doi: 10.1109/TNNLS.2018.2846646
|
| [51] |
Y. Todo, Z. Tang, H. Todo, J. Ji, K. Yamashita, Neurons with multiplicative interactions of nonlinear synapses, Int. J. Neural Syst., 29 (2019), 1950012. https://doi.org/10.1142/S0129065719500126 doi: 10.1142/S0129065719500126
|
| [52] |
X. Luo, X. Wen, M. Zhou, A. Abusorrah, L. Huang, Decision-tree-initialized dendritic neuron model for fast and accurate data classification, IEEE Trans. Neural Networks Learn. Syst., 33 (2022), 4173 – 4183. https://doi.org/10.1109/TNNLS.2021.3055991 doi: 10.1109/TNNLS.2021.3055991
|
| [53] |
J. Ji, Y. Tang, L. Ma, J. Li, Q. Lin, Z. Tang, et al., Accuracy versus simplification in an approximate logic neural model, IEEE Trans. Neural Networks Learn. Syst., 32 (2020), 5194–5207. https://doi.org/10.1109/TNNLS.2020.3027298 doi: 10.1109/TNNLS.2020.3027298
|
| [54] | S. Gao, M. Zhou, Z. Wang, D. Sugiyama, J. Cheng, J. Wang, et al., Fully complex-valued dendritic neuron model, IEEE Trans. Neural Networks Learn. Syst., 1–14. https://doi.org/10.1109/TNNLS.2021.3105901 |
| [55] | Y. Tang, J. Ji, S. Gao, H. Dai, Y. Yu, Y. Todo, A pruning neural network model in credit classification analysis, Comput. Intell. Neurosci., 2018 (2018), 9390410. https://doi.org/10.1155/2018/9390410 |
| [56] |
Z. Lei, S. Gao, Z. Zhang, M. Zhou, J. Cheng, MO4: a many-objective evolutionary algorithm for protein structure prediction, IEEE Trans. Evol. Comput., 26 (2022), 417–430. https://doi.org/10.1109/TEVC.2021.3095481 doi: 10.1109/TEVC.2021.3095481
|
| [57] |
J. X. Mi, J. Feng, K. Y. Huang, Designing efficient convolutional neural network structure: a survey, Neurocomputing, 489 (2022), 139–156. https://doi.org/10.1016/j.neucom.2021.08.158 doi: 10.1016/j.neucom.2021.08.158
|
| [58] |
Z. H. Zhan, J. Y. Li, J. Zhang, Evolutionary deep learning: a survey, Neurocomputing, 483 (2022), 42–58. https://doi.org/10.1016/j.neucom.2022.01.099 doi: 10.1016/j.neucom.2022.01.099
|
| [59] | Z. Wang, S. Gao, M. Zhou, S. Sato, J. Cheng, J. Wang, Information-theory-based nondominated sorting ant colony optimization for multiobjective feature selection in classification, IEEE Trans. Cybern., 1–14. https://doi.org/10.1109/TCYB.2022.3185554 |
| [60] |
Y. Yu, Z. Lei, Y. Wang, T. Zhang, C. Peng, S. Gao, Improving dendritic neuron model with dynamic scale-free network-based differential evolution, IEEE/CAA J. Autom. Sin., 9 (2022), 99–110. https://doi.org/10.1109/JAS.2021.1004284 doi: 10.1109/JAS.2021.1004284
|
| [61] |
Y. Yu, S. Gao, Y. Wang, Y. Todo, Global optimum-based search differential evolution, IEEE/CAA J. Autom. Sin., 6 (2018), 379–394. https://doi.org/10.1109/JAS.2019.1911378 doi: 10.1109/JAS.2019.1911378
|
| [62] | S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Software, 95 (2016), 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 |
| [63] | A. Kumar, R. K. Misra, D. Singh, S. Mishra, S. Das, The spherical search algorithm for bound-constrained global optimization problems, Appl. Soft Comput., 85 (2019), 105734. https://doi.org/10.1016/j.asoc.2019.105734 |
| [64] | K. Wang, Y. Wang, S. Tao, Z. Cai, Z. Lei, S. Gao, Spherical search algorithm with adaptive population control for global continuous optimization problems, Appl. Soft Comput., 132 (2023), 109845. https://doi.org/10.1016/j.asoc.2022.109845 |
| [65] |
N. Takahashi, K. Kitamura, N. Matsuo, M. Mayford, M. Kano, N. Matsuki, et al., Locally synchronized synaptic inputs, Science, 335 (2012), 353–356. https://doi.org/10.1126/science.1210362 doi: 10.1126/science.1210362
|
| [66] |
W. Chen, J. Sun, S. Gao, J. J. Cheng, J. Wang, Y. Todo, Using a single dendritic neuron to forecast tourist arrivals to Japan, IEICE Trans. Inf. Syst., 100 (2017), 190–202. https://doi.org/10.1587/transinf.2016EDP7152 doi: 10.1587/transinf.2016EDP7152
|
| [67] | J. Ji, S. Song, Y. Tang, S. Gao, Z. Tang, Y. Todo, Approximate logic neuron model trained by states of matter search algorithm, Knowl. Based Syst., 163 (2019), 120–130. https://doi.org/10.1016/j.knosys.2018.08.020 |
| [68] | Z. Wang, S. Gao, J. Wang, H. Yang, Y. Todo, A dendritic neuron model with adaptive synapses trained by differential evolution algorithm, Comput. Intell. Neurosci., 2020 (2020), 2710561. https://doi.org/10.1155/2020/2710561 |
| [69] | Z. Song, Y. Tang, J. Ji, Y. Todo, Evaluating a dendritic neuron model for wind speed forecasting, Knowl. Based Syst., 201 (2020), 106052. https://doi.org/10.1016/j.knosys.2020.106052 |
| [70] | R. Tanabe, A. S. Fukunaga, Improving the search performance of SHADE using linear population size reduction, in 2014 IEEE Congress on Evolutionary Computation (CEC), IEEE, (2014), 1658–1665. https://doi.org/10.1109/CEC.2014.6900380 |
| [71] | Z. Xu, Z. Wang, J. Li, T. Jin, X. Meng, S. Gao, Dendritic neuron model trained by information feedback-enhanced differential evolution algorithm for classification, Knowl. Based Syst., 233 (2021), 107536. https://doi.org/10.1016/j.knosys.2021.107536 |
| [72] | R. Jiang, M. Yang, S. Wang, T. Chao, An improved whale optimization algorithm with armed force program and strategic adjustment, Appl. Math. Modell., 81 (2020), 603–623. https://doi.org/10.1016/j.apm.2020.01.002 |
| [73] |
S. Gao, Y. Yu, Y. Wang, J. Wang, J. Cheng, M. Zhou, Chaotic local search-based differential evolution algorithms for optimization, IEEE Trans. Syst. Man Cybern. Syst., 51 (2021), 3954–3967. https://doi.org/10.1109/TSMC.2019.2956121 doi: 10.1109/TSMC.2019.2956121
|
| [74] | W. Dong, L. Kang, W. Zhang, Opposition-based particle swarm optimization with adaptive mutation strategy, Soft Comput., 21 (2017), 5081–5090. https://doi.org/0.1007/s00500-016-2102-5 |
| [75] | J. Too, M. Mafarja, S. Mirjalili, Spatial bound whale optimization algorithm: an efficient high-dimensional feature selection approach, Neural Comput. Appl., 33 (2021), 16229–16250. https://doi.org/10.1007/s00521-021-06224-y |
| [76] | Y. Gao, C. Qian, Z. Tao, H. Zhou, J. Wu, Y. Yang, Improved whale optimization algorithm via cellular automata, in 2020 IEEE International Conference on Progress in Informatics and Computing (PIC), IEEE, (2020), 34–39. https://doi.org/10.1109/PIC50277.2020.9350796 |
| [77] |
J. Zhang, J. S. Wang, Improved whale optimization algorithm based on nonlinear adaptive weight and golden sine operator, IEEE Access, 8 (2020), 77013–77048. https://doi.org/10.1109/ACCESS.2020.2989445 doi: 10.1109/ACCESS.2020.2989445
|
| [78] | C. Tang, W. Sun, W. Wu, M. Xue, A hybrid improved whale optimization algorithm, in 2019 IEEE 15th International Conference on Control and Automation (ICCA), IEEE, (2019), 362–367. https://doi.org/10.1109/ICCA.2019.8900003 |
| [79] | U. Škvorc, T. Eftimov, P. Korošec, CEC real-parameter optimization competitions: progress from 2013 to 2018, in 2019 IEEE Congress on Evolutionary Computation (CEC), IEEE, (2019), 3126–3133. https://doi.org/10.1109/CEC.2019.8790158 |
| [80] |
T. Jiang, S. Gao, D. Wang, J. Ji, Y. Todo, Z. Tang, A neuron model with synaptic nonlinearities in a dendritic tree for liver disorders, IEEJ Trans. Electr. Electron. Eng., 12 (2017), 105–115. https://doi.org/10.1002/tee.22350 doi: 10.1002/tee.22350
|
| [81] |
J. F. Khaw, B. Lim, L. E. Lim, Optimal design of neural networks using the taguchi method, Neurocomputing, 7 (1995), 225–245. https://doi.org/10.1016/0925-2312(94)00013-I doi: 10.1016/0925-2312(94)00013-I
|
| [82] | J. Carrasco, S. García, M. Rueda, S. Das, F. Herrera, Recent trends in the use of statistical tests for comparing swarm and evolutionary computing algorithms: practical guidelines and a critical review, Swarm Evol. Comput., 54 (2020), 100665. https://doi.org/10.1016/j.swevo.2020.100665 |
| [83] |
J. Misra, I. Saha, Artificial neural networks in hardware: a survey of two decades of progress, Neurocomputing, 74 (2010), 239–255. https://doi.org/10.1016/j.neucom.2010.03.021 doi: 10.1016/j.neucom.2010.03.021
|
| [84] | S. Mittal, A survey of FPGA-based accelerators for convolutional neural networks, Neural Comput. Appl., 32 (2020), 1109–1139. https://doi.org/10.1007/s00521-018-3761-1 |
| [85] | H. Zhang, M. Gu, X. Jiang, J. Thompson, H. Cai, S. Paesani, et al., An optical neural chip for implementing complex-valued neural network, Nat. Commun., 12 (2021), 1–11. https://doi.org/10.1038/s41467-020-20719-7 |
| [86] | H. Shayanfar, F. S. Gharehchopogh, Farmland fertility: a new metaheuristic algorithm for solving continuous optimization problems, Appl. Soft Comput., 71 (2018), 728–746. https://doi.org/10.1016/j.asoc.2018.07.033 |
| [87] |
F. S. Gharehchopogh, B. Farnad, A. Alizadeh, A modified farmland fertility algorithm for solving constrained engineering problems, Concurrency Comput. Pract. Exper., 33 (2021), e6310. https://doi.org/10.1002/cpe.6310 doi: 10.1002/cpe.6310
|
| [88] | A. Hosseinalipour, F. S. Gharehchopogh, M. Masdari, A. Khademi, A novel binary farmland fertility algorithm for feature selection in analysis of the text psychology, Appl. Intell., 51 (2021), 4824–4859. https://doi.org/10.1007/s10489-020-02038-y |
| [89] | B. Abdollahzadeh, F. S. Gharehchopogh, S. Mirjalili, African vultures optimization algorithm: a new nature-inspired metaheuristic algorithm for global optimization problems, Comput. Ind. Eng., 158 (2021), 107408. https://doi.org/10.1016/j.cie.2021.107408 |
| [90] | B. Abdollahzadeh, F. S. Gharehchopogh, N. Khodadadi, S. Mirjalili, Mountain gazelle optimizer: a new nature-inspired metaheuristic algorithm for global optimization problems, Adv. Eng. Software, 174 (2022), 103282. https://doi.org/10.1016/j.advengsoft.2022.103282 |
| [91] |
B. Abdollahzadeh, F. Soleimanian Gharehchopogh, S. Mirjalili, Artificial gorilla troops optimizer: a new nature-inspired metaheuristic algorithm for global optimization problems, Int. J. Intell. Syst., 36 (2021), 5887–5958. https://doi.org/10.1002/int.22535 doi: 10.1002/int.22535
|
| [92] |
W. R. Taylor, S. He, W. R. Levick, D. I. Vaney, Dendritic computation of direction selectivity by retinal ganglion cells, Science, 289 (2000), 2347–2350. https://doi.org/10.1126/science.289.5488.2347 doi: 10.1126/science.289.5488.2347
|














Figures(15) / Tables(9)

Hang Yu, Jiarui Shi, Jin Qian, Shi Wang, Sheng Li. Single dendritic neural classification with an effective spherical search-based whale learning algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7594-7632. doi: 10.3934/mbe.2023328







 DownLoad:
DownLoad: