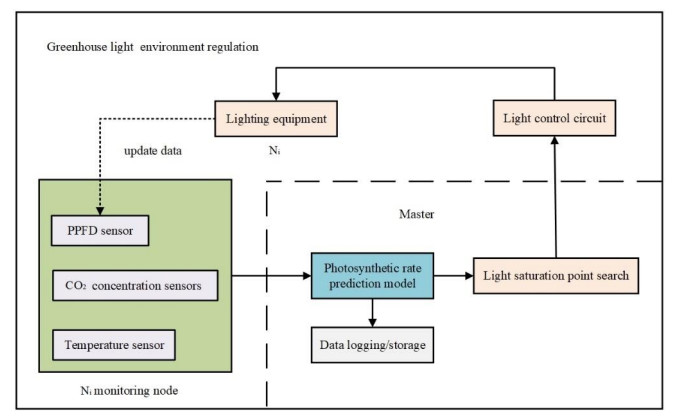
In winter and spring, for greenhouses with larger areas and stereoscopic cultivation, distributed light environment regulation based on photosynthetic rate prediction model can better ensure good crop growth. In this paper, strawberries at flowering-fruit stage were used as the test crop, and the LI-6800 portable photosynthesis system was used to control the leaf chamber environment and obtain sample data by nested photosynthetic rate combination experiments under temperature, light and CO2 concentration conditions to study the photosynthetic rate prediction model construction method. For a small-sample, nonlinear real experimental data set validated by grey relational analysis, a photosynthetic rate prediction model was developed based on Support vector regression (SVR), and the particle swarm algorithm (PSO) was used to search the influence of the empirical values of parameters, such as the penalty parameter C, accuracy ε and kernel constant g, on the model prediction performance. The modeling and prediction results show that the PSO-SVR method outperforms the commonly used algorithms such as MLR, BP, SVR and RF in terms of prediction performance and generalization on a small sample data set. The research in this paper achieves accurate prediction of photosynthetic rate of strawberry and lays the foundation for subsequent distributed regulation of greenhouse strawberry light environment.
Citation: Xinyan Chen, Zhaohui Jiang, Qile Tai, Chunshan Shen, Yuan Rao, Wu Zhang. Construction of a photosynthetic rate prediction model for greenhouse strawberries with distributed regulation of light environment[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12774-12791. doi: 10.3934/mbe.2022596
In winter and spring, for greenhouses with larger areas and stereoscopic cultivation, distributed light environment regulation based on photosynthetic rate prediction model can better ensure good crop growth. In this paper, strawberries at flowering-fruit stage were used as the test crop, and the LI-6800 portable photosynthesis system was used to control the leaf chamber environment and obtain sample data by nested photosynthetic rate combination experiments under temperature, light and CO2 concentration conditions to study the photosynthetic rate prediction model construction method. For a small-sample, nonlinear real experimental data set validated by grey relational analysis, a photosynthetic rate prediction model was developed based on Support vector regression (SVR), and the particle swarm algorithm (PSO) was used to search the influence of the empirical values of parameters, such as the penalty parameter C, accuracy ε and kernel constant g, on the model prediction performance. The modeling and prediction results show that the PSO-SVR method outperforms the commonly used algorithms such as MLR, BP, SVR and RF in terms of prediction performance and generalization on a small sample data set. The research in this paper achieves accurate prediction of photosynthetic rate of strawberry and lays the foundation for subsequent distributed regulation of greenhouse strawberry light environment.

| [1] |
Q. Li, R. H. Zhang, Y. Wang, Interannual variation of the wintertime fog-haze days across central and eastern China and its relation with East Asian winter monsoon, Int. J. Climatol., 36 (2016), 346–354. https://doi.org/10.1002/joc.4350 doi: 10.1002/joc.4350

|
| [2] |
X. Li, W. Lu, G. Y. Hu, X. C. Wang, Y. Zhang, Effects of light-emitting diode supplementary lighting on the winter growth of greenhouse plants in the Yangtze River Delta of China, Bot. Stud., 57 (2016). https://doi.org/10.1186/s40529-015-0117-3 doi: 10.1186/s40529-015-0117-3
|
| [3] |
Y. Kong, D. Llewellyn, Y. B. Zheng, Response of growth, yield, and quality of pea shoots to supplemental light-emitting diode lighting during winter greenhouse production, Can. J. Agric. Sci., 98 (2018), 732–740. https://doi.org/10.1139/cjps-2017-0276 doi: 10.1139/cjps-2017-0276
|
| [4] |
Y. C. Xu, Y. X. Chang, G. Y. Chen, H. Y Lin, The research on LED supplementary lighting system for plants, Optik, 127 (2016), 7193–7201. https://doi.org/10.1016/j.ijleo.2016.05.056 doi: 10.1016/j.ijleo.2016.05.056
|
| [5] |
T. Kmet, M. Kmetova, Adaptive critic design and Hopfield neural network based simulation of time delayed photosynthetic production and prey–predator model, Inf. Sci., 294 (2015), 586–599. https://doi.org/10.1016/j.ins.2014.08.020 doi: 10.1016/j.ins.2014.08.020
|
| [6] |
Y. J. Zheng, Y. T. Zhang, H. C. Liu, Y. M. Li, Y. L. Liu, Supplemental blue light increases growth and quality of greenhouse pak choi depending on cultivar and supplemental light intensity, J. Integr. Agric., 17 (2018), 2245–2256. https://doi.org/10.1016/S2095-3119(18)62064-7 doi: 10.1016/S2095-3119(18)62064-7
|
| [7] |
L. Xu, R. Wei, L. Xu, Optimal greenhouse lighting scheduling using canopy light distribution model: A simulation study on tomatoes, Lighting Res. Technol., 52 (2020), 233–246. https://doi.org/10.1177/1477153519825995 doi: 10.1177/1477153519825995
|
| [8] |
O. D. Palmitessa, M. A. Pantaleo, P. Santamaria, Applications and development of LEDs as supplementary lighting for tomato at different latitudes, Agronomy, 11 (2021), 835. https://doi.org/10.3390/agronomy11050835 doi: 10.3390/agronomy11050835
|
| [9] |
F. F. He, L. H. Zeng, D. M. Li, Z. H. Ren, Study of LED array fill light based on parallel particle swarm optimization in greenhouse planting, Inf. Process. Agric., 6 (2019), 73–80. https://doi.org/10.1016/j.inpa.2018.08.006 doi: 10.1016/j.inpa.2018.08.006
|
| [10] |
C. Y. Li, H. Y. Shan, C. H. Zhang, H. Q. Liu, X. C. Guo, M. Z. Xu, Optimal regulation model of Greenhouse light under limited light resources, IOP Conf. Ser. Earth Environ. Sci., 792 (2021), 12025. https://doi.org/10.1088/1755-1315/792/1/012025 doi: 10.1088/1755-1315/792/1/012025
|
| [11] |
M. Carlini, S. Castellucci, A. Mennuni, S. Morelli, Numerical modeling and simulation of pitched and curved-roof solar greenhouses provided with internal heating systems for different ambient conditions, Energy Rep., 6 (2020), 146–154. https://doi.org/10.1016/j.egyr.2019.10.033 doi: 10.1016/j.egyr.2019.10.033
|
| [12] |
N. Choab, A. Allouhi, A. E. Maakoul, T. Kousksou, S. Saadeddine, A. Jamil, Review on greenhouse microclimate and application: Design parameters, thermal modeling and simulation, climate controlling technologies, Solar Energy, 191 (2019), 109–137. https://doi.org/10.1016/j.solener.2019.08.042 doi: 10.1016/j.solener.2019.08.042
|
| [13] |
J. T. Chen, Y. W. Ma, Z. Z. Pang, A mathematical model of global solar radiation to select the optimal shape and orientation of the greenhouses in southern China, Solar Energy, 205 (2020), 380–389. https://doi.org/10.1016/j.solener.2020.05.055 doi: 10.1016/j.solener.2020.05.055
|
| [14] |
R. Liu, M. Li, J. L. Guzmán, F. Rodríguez, A fast and practical one-dimensional transient model for greenhouse temperature and humidity, Comput. Electron. Agric., 186 (2021), 106186. https://doi.org/10.1016/j.compag.2021.106186 doi: 10.1016/j.compag.2021.106186
|
| [15] |
T. Liu, Q. Y. Yuan, Y. G Wang, Hierarchical optimization control based on crop growth model for greenhouse light environment, Comput. Electron. Agric., 180 (2021), 105854. https://doi.org/10.1016/j.compag.2020.105854 doi: 10.1016/j.compag.2020.105854
|
| [16] |
P. P. Xin, B. Li, H. H. Zhang, J. Hu, Optimization and control of the light environment for greenhouse crop production, Sci. Rep., 9 (2019), 1–13. https://doi.org/10.1038/s41598-019-44980-z doi: 10.1038/s41598-019-44980-z
|
| [17] |
P. P. Xin, H. H. Zhang, J. Hu, Z. Y. Wang, Z. Zhang, An improved photosynthesis prediction model based on artificial neural networks intended for cucumber growth control, Appl. Eng. Agric., 34 (2018), 769–787. https://doi.org/10.13031/aea.12634 doi: 10.13031/aea.12634
|
| [18] |
J. Hu, P. P. Xin, S. W. Zhang, H. H. Zhang, D. J. He, Model for tomato photosynthetic rate based on neural network with genetic algorithm, Int. J. Agric. Biol. Eng., 12 (2019), 179–185. https://doi.org/10.25165/j.ijabe.20191201.3127 doi: 10.25165/j.ijabe.20191201.3127
|
| [19] |
J. T. Ding, H. Y. Tu, Z. L. Zang, M. Huang, S. J. Zhou, Precise control and prediction of the greenhouse growth environment of Dendrobium candidum, Comput. Electron. Agric., 151 (2018), 453–459. https://doi.org/10.1016/j.compag.2018.06.037 doi: 10.1016/j.compag.2018.06.037
|
| [20] |
Y. W. Liu, D. J. Li, S. H. Wan, F. Wang, W. C. Dou, X. L. Xu, et al., A long short‐term memory‐based model for greenhouse climate prediction, Int. J. Intell., 37 (2022), 135–151. https://doi.org/10.1002/int.22620 doi: 10.1002/int.22620
|
| [21] |
X. Y. Zhang, Z. Y. Huang, X. H. Su, A. Siu, Y. P. Song, D. Q. Zhang, et al., Machine learning models for net photosynthetic rate prediction using poplar leaf phenotype data, PLoS One, 15 (2020), e228645. https://doi.org/10.1371/journal.pone.0228645 doi: 10.1371/journal.pone.0228645
|
| [22] |
K. P. Zheng, Y. Bo, Y. D. Bao, X. L. Zhu, J. Wang, Y. Wang, A machine learning model for photorespiration response to multi-factors, Horticulturae, 7 (2021), 207. https://doi.org/10.3390/horticulturae7080207 doi: 10.3390/horticulturae7080207
|
| [23] |
D. H. Jung, H. S. Kim, C. Jhin, H. J. Kim, S. H. Park, Time-serial analysis of deep neural network models for prediction of climatic conditions inside a greenhouse, Comput. Electron. Agric., 173 (2020), 105402. https://doi.org/10.1016/j.compag.2020.105402 doi: 10.1016/j.compag.2020.105402
|
| [24] |
H. G. Choi, B. Y. Moon, N. J. Kang, Effects of LED light on the production of strawberry during cultivation in a plastic greenhouse and in a growth chamber, Sci. Hortic, 189 (2015), 22–31. https://doi.org/10.1016/j.scienta.2015.03.022 doi: 10.1016/j.scienta.2015.03.022
|
| [25] |
S. V. Archontoulis, F. E. Miguez, Nonlinear regression models and applications in agricultural research, Agron. J., 107 (2015), 786–798. https://doi.org/10.2134/agronj2012.0506 doi: 10.2134/agronj2012.0506
|
| [26] | M. Riches, D. Lee, D. K. Farmer, Simultaneous leaf-level measurement of trace gas emissions and photosynthesis with a portable photosynthesis system, Atmos. Meas. Tech., 13 (2020), 4123–4139, https://doi.org/10.5194/amt-13-4123-2020, 2020 |
| [27] |
X. X. Huang, M. Chen, W. J. Wang, Y. Ge, J. Xie, Shelf-life Prediction of chilled Penaeus vannamei using grey relational analysis and support vector regression, J. Aquat. Food Prod. Technol., 29 (2020), 507–519. https://doi.org/10.1080/10498850.2020.1766616 doi: 10.1080/10498850.2020.1766616
|
| [28] |
Y. Zhang, H. Sun, Y. Guo, Wind power prediction based on PSO-SVR and grey combination model, IEEE Access, 7 (2019), 136254–136267. https://doi.org/10.1109/ACCESS.2019.2942012 doi: 10.1109/ACCESS.2019.2942012
|
| [29] |
J. H. Li, D. S. Zhu, C. X. Li, Comparative analysis of BPNN, SVR, LSTM, Random Forest, and LSTM-SVR for conditional simulation of non-Gaussian measured fluctuating wind pressures, Mech. Syst. Signal. Process, 178 (2022), 109285. https://doi.org/10.1016/j.ymssp.2022.109285 doi: 10.1016/j.ymssp.2022.109285
|




Figures(5) / Tables(2)

Xinyan Chen, Zhaohui Jiang, Qile Tai, Chunshan Shen, Yuan Rao, Wu Zhang. Construction of a photosynthetic rate prediction model for greenhouse strawberries with distributed regulation of light environment[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12774-12791. doi: 10.3934/mbe.2022596







 DownLoad:
DownLoad: