Citation: Kai Zhang, Xinwei Wang, Hua Liu, Yunpeng Ji, Qiuwei Pan, Yumei Wei, Ming Ma. Mathematical analysis of a human papillomavirus transmission model with vaccination and screening[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5449-5476. doi: 10.3934/mbe.2020294

| [1] | M. Arbyn, X. Castellsagué, S. de Sanjosé, L. Bruni, M. Saraiya, F. Bray, et al, Worldwide burden of cervical cancer in 2008, Ann. Oncol. Circuits, 22 (2011), 2675-2686. |
| [2] | G. Bogani, U. L. R. Maggiore, M. Signorelli, F. Martinelli, A. Ditto, I. Sabatucci, et al, The role of human papillomavirus vaccines in cervical cancer: Prevention and treatment, Crit. Rev. Oncol. Hemat., 122 (2018), 92-97. |
| [3] | J. K. Oh, E. Weiderpass, Infection and cancer: Global distribution and burden of diseases, Ann. Glob. Health, 80 (2014), 384-392. |
| [4] | D. M. Parkin, F. Bray, J. Ferlay, P. Pisani, Estimating the world cancer burden: Globocan 2000, Int. J. Cancer, 94 (2001), 153-156. |
| [5] | D. M. Parkin, F. Bray, J. Ferlay, P. Pisani, Global cancer statistics, 2002, Ca-Cancer J. Clin., 55 (2005), 74-108. |
| [6] | D. M. Parkin, F. Bray, The burden of HPV-related cancers, Vaccine, 24 (2005), S11-S25. |
| [7] | G. Hancock, K. Hellner, L. Dorrell, Therapeutic HPV vaccines, Best Prcat. Res. Cl. Ob., 47 (2018), 59-72. |
| [8] | K. Miura, H. Mishima, A. Kinoshita, C. Hayashida, S. Abe, K. Tokunaga, et al, Genome-wide association study of HPV-associated cervical cancer in Japanese women, J. Med. Virol., 86 (2014), 1153-1158. |
| [9] | E. L. Franco, E. Duarte-Franco, A. Ferenczy, Cervical cancer: epidemiology, prevention and the role of human papillomavirus infection, Cmaj, 164 (2001), 1017-1025. |
| [10] | International Agency for Research on Cancer Working Group, Human papillomaviruses, IARC Monographs on the Evaluation of the Carcinogenic Risks to Humans, Lyon, 1995. |
| [11] | T. Malik, J. Reimer, A. Gumel, E. Elbasha, S. Mahmud, The impact of an imperfect vaccine and pap cytology screening on the transmission of human papillomavirus and occurrence of associated cervical dysplasia and cancer, Math. Biosci. Eng., 10 (2013), 1173-1205. |
| [12] | L. A. Denny, Jr. T. C. Wright, Human papillomavirus testing and screening, Best Prcat. Res. Cl. Ob., 19 (2005), 501-515. |
| [13] | T. G. Harris, R. D. Burk, J. M. Palefsky, L. S. Massad, J. Bang, K. Anastos, et al, Incidence of cervical squamous intraepithelial lesions associated with HIV serostatus, CD4 cell counts, and human papillomavirus test results, Jama, 293 (2005), 1471-1476. |
| [14] | M. Schiffman, P. Castle, J. Jeronimo, A. C. Rodriguez, S. Wacholder, Human papillomavirus and cervical cancer, Lancet, 370 (2000), 890-907. |
| [15] | R. L. Winer, J. P. Hughes, Q. Feng, S. O'Reilly, N. B. Kiviat, K. K. Holmes, et al, Condom use and the risk of genital human papillomavirus infection in young women, New Engl. J. Med., 354 (2006), 2645-2654. |
| [16] | International Collaboration of Epidemiological Studies of Cervical Cancer, Carcinoma of the cervix and tobacco smoking: Collaborative reanalysis of individual data on 13,541 women with carcinoma of the cervix and 23,017 women without carcinoma of the cervix from 23 epidemiological studies, Int. J. Cancer, 118 (2006), 1481-1495. |
| [17] | International Collaboration of Epidemiological Studies of Cervical Cancer, Cervical carcinoma and reproductive factors: Collaborative reanalysis of individual data on 16,563 women with cervical carcinoma and 33,542 women without cervical carcinoma from 25 epidemiological studies, Int. J. Cancer, 119 (2006), 1108-1124. |
| [18] | J. S. Smith, J. Green, A. B. de. Gonzalez, P. Appleby, P. J. Peto, M. Plummer, et al, Cervical cancer and use of hormonal contraceptives: a systematic review, Lancet, 361 (2003), 1159-1167. |
| [19] | D. Saslow, D. Solomon, H. W. Lawson, M. Killackey, S. L. Kulasingam, J. Cain, et al, American Cancer Society, American Society for Colposcopy and Cervical Pathology, and American Society for Clinical Pathology screening guidelines for the prevention and early detection of cervical cancer, Ca-Cancer J. Clin., 62 (2012), 147-172. |
| [20] | M. Al-arydah, R. Smith, An age-structured model of human papillomavirus vaccination, Math. Comput. Simulat., 82 (2011), 629-652. |
| [21] | O. Sharomi, T. Malik, A model to assess the effect of vaccine compliance on Human Papillomavirus infection and cervical cancer, Appl. Math. Model, 47 (2017), 528-550. |
| [22] | A. Omame, R. A. Umana, D. Okuonghae, S. C. Inyama, Mathematical analysis of a two-sex Human Papillomavirus (HPV) model, Int. J. Biomath., 11 (2018), 1850092. |
| [23] | E. H. Elbasha, Global stability of equilibria in a two-sex HPV vaccination model, B Math. Biol., 70 (2008), 894. |
| [24] | E. H. Elbasha, Impact of prophylactic vaccination against human papillomavirus infection, Contemp. Math., 410 (2006), 113-128. |
| [25] | Z. Qu, L. Xue, J. M. Hyman, Modeling the transmission of Wolbachia in mosquitoes for controlling mosquito-borne diseases, SIAM J. Appl. Math., 78 (2018), 826-852. |
| [26] | O. Sharomi, C. N. Podder, A. B. Gumel, S. M. Mahmud, E. Rubinstein, Modelling the transmission dynamics and control of the novel 2009 swine influenza (H1N1) pandemic, B Math. Biol., 73 (2011), 515-548. |
| [27] | H. W. Hethcote, The mathematics of infectious diseases, SIAM Review, 42 (2000), 599-653. |
| [28] | P. Van den Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29-48. |
| [29] | L. Perko, Differential Equations and Dynamical Systems, Springer, New York, 1996. |
| [30] | S. M. Blower, H. Dowlatabadi, Sensitivity and uncertainty analysis of complex models of disease transmission: an HIV model, as an example, Int. Stat. Rev., 62 (1994), 229-243. |
| [31] | M. H. A. Biswas, L. T. Paiva, M. D. R. De Pinho, A SEIR model for control of infectious diseases with constraints, Math. Biosci. Eng., 11 (2014), 761-784. |
| [32] | X. Wang, H. Peng, B. Shi, D. Jiang, S. Zhang, B. Chen, Optimal vaccination strategy of a constrained time-varying SEIR epidemic model, Commun. Nonlinear SCI, 67 (2019), 37-48. |
| [33] | W. H. Fleming, R. W. Rishel, Deterministic and stochastic optimal control, Springer Verlag, New York, 1975. |
| [34] | R. Bellman, L. S. Pontryagin, V. G. Boltyanskii, R. V. Gamkrelidze, E. F. Mischenko, The mathematical theory of optimal processes, Math. Comput., 19 (1965), 159. |
| [35] | H. Peng, Q. Gao, Z. Wu, W. Zhong, Symplectic approaches for solving two-point boundary-value problems, J. Guid. Control. Dynam., 35 (2012), 653-658. |
| [36] | M. Li, H. Peng, W. Zhong, A symplectic sequence iteration approach for nonlinear optimal control problems with state-control constraints, J. Franklin I, 352 (2015), 2381-2406. |
| [37] | H. Peng, Q. Gao, Z. Wu, W. Zhong, Efficient sparse approach for solving receding-horizon control problems, J. Guid. Control. Dynam., 36 (2013), 1864-1872. |
| [38] | H. Peng, Q. Gao, Z. Wu, W. Zhong, Symplectic adaptive algorithm for solving nonlinear two-point boundary value problems in astrodynamics, Celest Mech. Dyn. Astr., 110 (2011), 319-342. |
| [39] | X. Wang, H. Peng, S. Zhang, B. Chen, W. Zhong, A symplectic pseudospectral method for nonlinear optimal control problems with inequality constraints, ISA T, 68 (2017), 335-352. |
| [40] | H. Peng, X. Wang, M. Li, B. Chen, An hp symplectic pseudospectral method for nonlinear optimal control, Commun. Nonlinear. Sci., 42 (2017), 623-644. |
| [41] | X. Wang, H. Peng, S. Zhang, B. Chen, W. Zhong, A symplectic local pseudospectral method for solving nonlinear state-delayed optimal control problems with inequality constraints, Int. J. Robust Nonlinear Control, 28 (2018), 2097-2120. |
| [42] | X. Wang, J. Liu, X. Dong, C. Li, Y. Zhang, A symplectic pseudospectral method for constrained time-delayed optimal control problems and its application to biological control problems, Optimization, 2020. |
| [43] | J. Liu, W. Han, X. Wang, J. Li, Research on cooperative trajectory planning and tracking problem for multiple carrier aircraft on the deck, IEEE Syst., 14 (2020), 3027-3038. |
| [44] | X. Wang, J. Liu, Y. Zhang, B. Shi, D. Jiang, H. Peng, A unified symplectic pseudospectral method for motion planning and tracking control of 3D underactuated overhead cranes, Int. J. Robust Nonlinear Control, 29 (2019), 2236-2253. |
| [45] | H. Peng, X. Wang, B. Shi, S. Zhang, B. Chen, Stabilizing constrained chaotic system using a symplectic psuedospectral method, Commun. Nonlinear SCI, 56 (2018), 77-92. |
| [46] | J. Carr, Applications of Centre Manifold Theory, Springer Science & Business Media, 2012. |
| [47] | C. Castillo-Chavez, B. Song, Dynamical models of tuberculosis and their applications, Math. Biosci. Eng., 1 (2004), 361-404. |
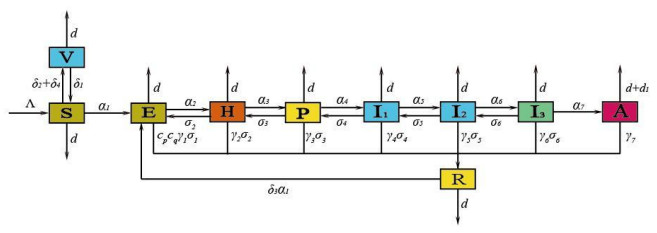
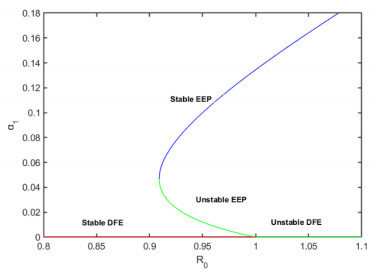
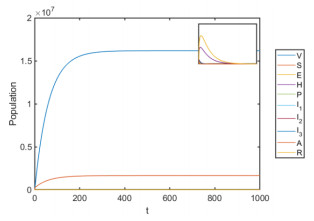
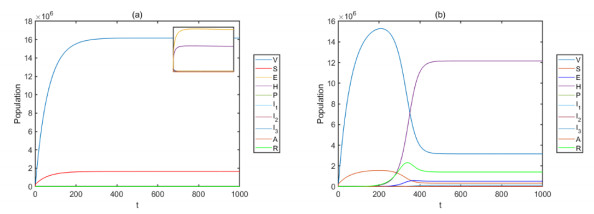
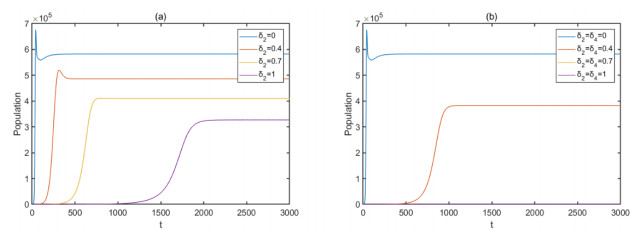
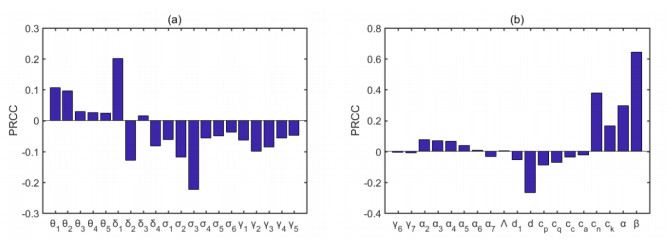
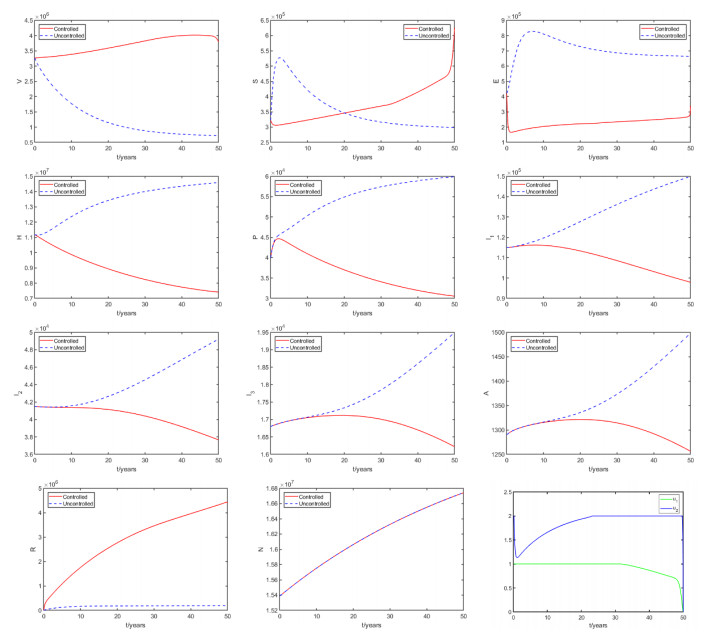
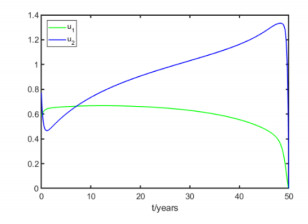
Figures(8) / Tables(6)

Kai Zhang, Xinwei Wang, Hua Liu, Yunpeng Ji, Qiuwei Pan, Yumei Wei, Ming Ma. Mathematical analysis of a human papillomavirus transmission model with vaccination and screening[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5449-5476. doi: 10.3934/mbe.2020294







 DownLoad:
DownLoad: