Citation: Gheorghe Craciun, Matthew D. Johnston, Gábor Szederkényi, Elisa Tonello, János Tóth, Polly Y. Yu. Realizations of kinetic differential equations[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 862-892. doi: 10.3934/mbe.2020046

| [1] | V. Hárs and J. Tóth, On the inverse problem of reaction kinetics, In M. Farkas, editor, Colloquia Mathematica Societatis János Bolyai, volume 30, pages 363-379. Qualitative Theory of Differential Equations, 1979. |
| [2] | C. P. P. Arceo, E. C. Jose, A. Marin-Sanguino, et al., Chemical reaction network approaches to biochemical systems theory, Math. Biosci., 269 (2015), 135-152. |
| [3] | F. Horn and R. Jackson, General mass action kinetics, Arch. Ratl. Mech. Anal., 47 (1972), 81-116. |
| [4] | M. Feinberg, Complex balancing in general kinetic systems, Arch. Ratl. Mech. Anal., 49 (1972), 187-194. |
| [5] | F. Horn, Necessary and sufficient conditions for complex balancing in chemical kinetics, Arch. Ratl. Mech. Anal., 49 (1972), 172-186. |
| [6] | A. I. Volpert and S. I. Hudyaev, Analyses in Classes of Discontinuous Functions and Equations of Mathematical Physics, Martinus Nijhoff Publishers, Dordrecht, 1985. Russian original: 1975. |
| [7] | D. F. Anderson, A proof of the global attractor conjecture in the single linkage class case, SIAM J. Appl. Math., 71 (2011), 1487-1508. |
| [8] | C. Pantea, On the persistence and global stability of mass-action systems, SIAM J. Math. Anal., 44 (2012), 1636-1673. |
| [9] | M. Gopalkrshnan, E. Miller and A. Shiu, A geometric approach to the global attractor conjecture, SIAM J. Appl. Dyn. Syst., 13 (2014), 758-797. |
| [10] | G. Craciun, F. Nazarov and C. Pantea, Persistence and permanence of mass-action and power-law dynamical systems, SIAM J. Appl. Math., 73 (2013), 305-329. |
| [11] | G. Craciun, Toric differential inclusions and a proof of the global attractor conjecture, arXiv:1501.02860, 2016. |
| [12] | R. Aris, Prolegomena to the rational analysis of systems of chemical reactions, Archive Ration. Mech. An., 19 (1965), 81-99. |
| [13] | R. Aris, Mathematical aspects of chemical reaction, IEEC Fundamentals, 61 (1969), 17-29. |
| [14] | M. Dukarić, H. Errami, R. Jerala, et al., On three genetic repressilator topologies, React. Kinet. Mech. Cat., 126 (2019), 3-30. |
| [15] | D. Lichtblau, Symbolic analysis of multiple steady states in a MAPK chemical reaction network, J. Symb. Comp., 2018. submitted. |
| [16] | B. Boros, On the existence of positive steady states for weakly reversible mass-action systems, SIAM J. Math. Anal., 51 (2019), 435-449. |
| [17] | M. Feinberg, Foundations of Chemical Reaction Network Theory, Springer International Publishing, New York, 2019. |
| [18] | G. Craciun and P. Y. Yu, Mathematical analysis of chemical reaction systems, Isr. J. Chem., 50, 2018. |
| [19] | J. Tóth, A. L. Nagy and D. Papp, Reaction Kinetics: Exercises, Programs and Theorems, Mathematica for Deterministic and Stochastic Kinetics, Springer-Verlag, New York, 2018. |
| [20] | G. Lente, Deterministic kinetics in chemistry and systems biology: the dynamics of complex reaction networks, Springer, 2015. |
| [21] | M. Feinberg and F. J. M. Horn, Chemical mechanism structure and the coincidence of the stoichiometric and kinetic subspaces, Arch. Ratl. Mech. Anal., 66 (1977), 83-97. |
| [22] | G. Craciun and C. Pantea, Identifiability of chemical reaction networks, J. Math. Chem., 44 (2008), 244-259. |
| [23] | G. Craciun, J. Jin and P. Y. Yu, An efficient characterization of complex-balanced, detailedbalanced, and weakly reversible systems, SIAM J. Appl. Math., 2019. To appear. |
| [24] | P. Érdi and J. Tóth, Mathematical Models of Chemical Reactions. Theory and Applications of Deterministic and Stochastic models, Princeton University Press, Princeton, New Jersey, 1989. |
| [25] | G. Szederkényi, Comment on "identifiability of chemical reaction networks" by G. Craciun and C. Pantea, J. Math. Chem., 45 (2009), 1172-1174. |
| [26] | G. Szederkényi, Computing sparse and dense realizations of reaction kinetic systems, J. Math. Chem., 47 (2010), 551-568. |
| [27] | G. Szederkényi, K. M. Hangos and T. Péni, Maximal and minimal realizations of reaction kinetic systems: computation and properties, MATCH Commun. Math. Comput. Chem., 65 (2011), 309-332. |
| [28] | B. Ács, G. Szederkényi, Z. A. Tuza, et al., Computing linearly conjugate weakly reversible kinetic structures using optimization and graph theory, MATCH Commun. Math. Comput. Chem., 74 (2015), 489-512. |
| [29] | G. Ács, G. Szlobodnyik and G. Szederkényi, A computational approach to the structural analysis of uncertain kinetic systems, Comput. Physics Commun., 228 (2018), 83-95. |
| [30] | G. Szederkényi, A. Magyar and K. M. Hangos, Analysis and control of polynomial dynamic models with biological applications, Academic Press, London, San Diego, Cambridge, MA, Oxford, 2018. |
| [31] | J. Tóth, A formális reakciókinetika globális determinisztikus és sztochasztikus modelljéröl (On the global deterministic and stochastic models of formal reaction kinetics with applications), MTA SZTAKI Tanulmányok, 129 (1981), 1-166. In Hungarian. |
| [32] | G. Lipták, G. Szederkényi and K. M. Hangos, Computing zero deficiency realizations of kinetic systems, Syst. Control Lett., 81 (2015), 24-30. |
| [33] | G. Szederkényi and K. M. Hangos, Finding complex balanced and detailed balanced realizations of chemical reaction networks, J. Math. Chem., 49 (2011), 1163-1179. |
| [34] | M. Feinberg, Necessary and sufficient conditions for detailed balancing in mass action systems of arbitrary complexity, Chem. Eng. Sci., 44 (1989), 1819-1827. |
| [35] | V. N. Orlov and L. I. Rozonoer, The macrodynamics of open systems and the variational principle of the local potential II. Applications, J. Franklin Ins., 318 (1984), 315-347. |
| [36] | B. Joshi and A. Shiu, A survey of methods for deciding whether a reaction network is multistationary, Math. Model. Nat. Pheno., 10 (2015), 47-67. |
| [37] | G. Szederkényi, K. M. Hangos and Z. Tuza, Finding weakly reversible realizations of chemical reaction networks using optimization, MATCH Commun. Math. Comput. Chem., 67 (2012), 193-212. |
| [38] | M. D. Johnston, D. Siegel and G. Szederkényi, Computing weakly reversible linearly conjugate chemical reaction networks with minimal deficiency, Math. Biosci., 241 (2013), 88-98. |
| [39] | S. Schuster and R. Schuster, Detecting strictly detailed balanced subnetworks in open chemical reaction networks, J. Math. Chem., 6 (1991), 17-40. |
| [40] | M. D. Johnston, D. Siegel and G. Szederkényi, Dynamical equivalence and linear conjugacy of chemical reaction networks: new results and methods, MATCH Commun. Math. Comput. Chem., 68 (2012), 443-468. |
| [41] | M. D. Johnston, D. Siegel and G. Szederkényi, A linear programming approach to weak reversibility and linear conjugacy of chemical reaction networks, J. Math. Chem., 50 (2012), 274-288. |
| [42] | J. Rudan, G. Szederkényi, K. Hangos, et al., Polynomial time algorithms to determine weakly reversible realizations of chemical reaction networks, J. Math. Chem., 52 (2014), 1386-1404. |
| [43] | D. Csercsik, G. Szederkényi and K. M. Hangos, Parametric uniqueness of deficiency zero reaction networks, J. Math. Chem., 50 (2012), 1-8. |
| [44] | G. Craciun, J. Jin and P. Y. Yu, Uniqueness of kinetic realizations for weakly reversible deficiency zero networks, In preparation. |
| [45] | B. Boros and J. Hofbauer, Permanence of weakly reversible mass-action systems with a single linkage class, arXiv:1903.03071, 2019. |
| [46] | L. Cardelli, M. Tribastone and M. Tschaikowski, From electric circuits to chemical networks, arXiv:1812.03308, 2018. |
| [47] | D. Csercsik, G. Szederkényi and K. M. Hangos, Parametric uniqueness of deficiency zero reaction networks. J. Math. Chem., 50 (2012), 1-8. |
| [48] | J. Rudan, G. Szederkényi and K. M. Hangos, Efficient computation of alternative structures for large kinetic systems using linear programming, MATCH Commun. Math. Comput. Chem., 71 (2014), 71-92. |
| [49] | J. Rudan, G. Szederkényi, K. M. Hangos, et al., Polynomial time algorithms to determine weakly reversible realizations of chemical reaction networks, J. Math. Chem., (2014), 1-19. |
| [50] | G. Szederkényi, K. M. Hangos and D. Csercsik, Computing realizations of reaction kinetic networks with given properties, In A. N. Gorban and D. Roose, editors, Coping with Complexity: Model Reduction and Data Analysis, volume 75, pages 253-267. Springer, 2010. |
| [51] | J. Rudan, G. Szederkényi and K. M. Hangos, Computing dynamically equivalent realizations of biochemical reaction networks with mass conservation, In ICNAAM 2013: 11th International Conference of Numerical Analysis and Applied Mathematics, 21-27 September, Rhodes, Greece, AIP Conference Proceedings, volume 1558, pages 2356-2359, 2013. ISBN: 978-0-7354-1184-5. |
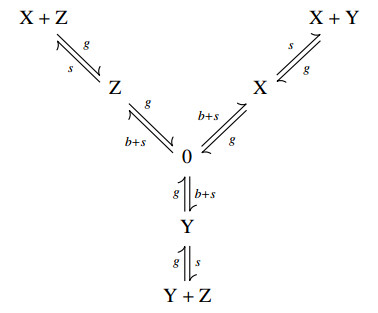
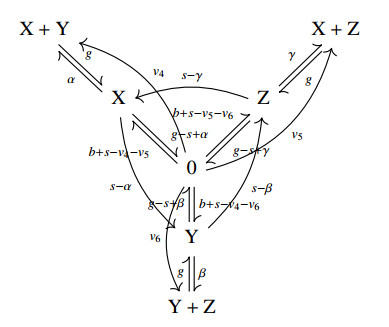
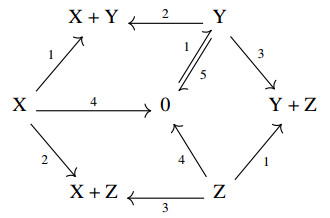
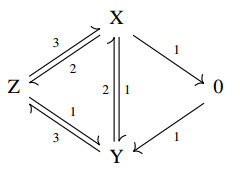
Figures(5)

Gheorghe Craciun, Matthew D. Johnston, Gábor Szederkényi, Elisa Tonello, János Tóth, Polly Y. Yu. Realizations of kinetic differential equations[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 862-892. doi: 10.3934/mbe.2020046







 DownLoad:
DownLoad: