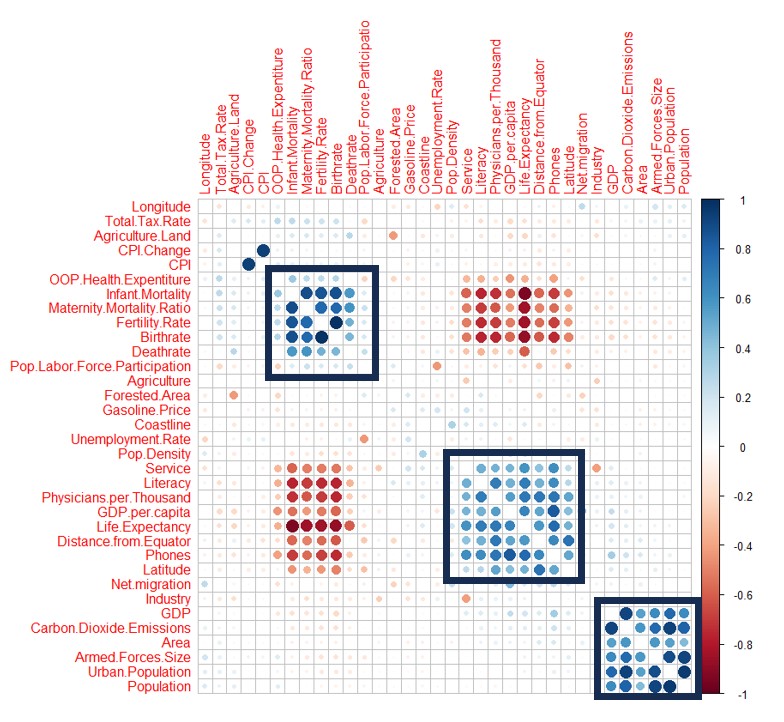
Minimum wages reflect and relate to many economic indexes and factors, and therefore is of importance to mark the developmental stage of a country. Among the 195 countries in the world, a handful of them do not have a regulated minimum wage mandated by their governments. People debate as to the advantages and disadvantages of imposing a mandatory minimum wage. It is of interest to predict what these minimum wages should be for the selected nations with none. To predict the minimum wages, motivations vary with the specific country. For example, many of these nations are members of the European Union, and there has been pressure from this organization to impose a mandatory minimum wage. Open and publicly available data from Excel Geography are employed to predict the minimum wages. We utilize many different models to predict minimum wages, and the random forest and neural network methods perform the best in terms of their validation mean squared errors. Both of these methods are nonlinear, which indicates that the relationship between the features and minimum wage exhibits some nonlinearity trends that are captured in these methods. For the method of random forests, we also compute 95% confidence intervals on each prediction to show the confidence range for the estimation.
Citation: Matthew Ki, Junfeng Shang. Prediction of minimum wages for countries with random forests and neural networks[J]. Data Science in Finance and Economics, 2024, 4(2): 309-332. doi: 10.3934/DSFE.2024013
Minimum wages reflect and relate to many economic indexes and factors, and therefore is of importance to mark the developmental stage of a country. Among the 195 countries in the world, a handful of them do not have a regulated minimum wage mandated by their governments. People debate as to the advantages and disadvantages of imposing a mandatory minimum wage. It is of interest to predict what these minimum wages should be for the selected nations with none. To predict the minimum wages, motivations vary with the specific country. For example, many of these nations are members of the European Union, and there has been pressure from this organization to impose a mandatory minimum wage. Open and publicly available data from Excel Geography are employed to predict the minimum wages. We utilize many different models to predict minimum wages, and the random forest and neural network methods perform the best in terms of their validation mean squared errors. Both of these methods are nonlinear, which indicates that the relationship between the features and minimum wage exhibits some nonlinearity trends that are captured in these methods. For the method of random forests, we also compute 95% confidence intervals on each prediction to show the confidence range for the estimation.

| [1] |
Beck MW (2018) NeuralNetTools: Visualization and Analysis Tools for Neural Networks. J Stat Softw 85: 1–20. https://doi.org/10.18637/jss.v085.i11 doi: 10.18637/jss.v085.i11

|
| [2] |
Bhorat H, Kanbur R, Stanwix B (2017) Minimum Wages in Sub-Saharan Africa: A Primer. World Bank Res Obser 32: 21–74. https://doi.org/10.1093/wbro/lkw007 doi: 10.1093/wbro/lkw007
|
| [3] | Eurofound (2018) Statutory minimum wages 2018. Available from: https://web.archive.org/web/20200831133204/https://www.eurofound.europa.eu/sites/default/files/ef_publication/field_ef_document/ef18005en.pdf. |
| [4] | Fritsch S, Guenther F, Wright MN (2019) neuralnet: Training of Neural Networks. R package version Available from: https://CRAN.R-project.org/package = neuralnet. |
| [5] | Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT Press. Available from: http://www.deeplearningbook.org. |
| [6] | Hastie T, Tibshirani R, Friedman J (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2nd ed), Springer-New York. Available from: https://doi.org/10.1007/978-0-387-84858-7. |
| [7] | International Labor Organization (1996–2024) How to define a minimum wage? Available from: https://www.ilo.org/global/topics/wages/minimum-wages/definition/WCMS_439072/lang–%en/index.htm. |
| [8] | International Trade Association (2024) Nigeria-Country Commercial Guide. Available from: https://www.trade.gov/country-commercial-guides/nigeria-healthcare. |
| [9] | James G, Witten D, Hastie T, et al. (2021) An Introduction to Statistical Learning. Springer, New York. |
| [10] | Kassambara A, Mundt F (2020) factoextra: Extract and Visualize the Results of Multivariate Data Analyses. R package version 1.0.7. Available from: https://CRAN.R-project.org/package = factoextra. |
| [11] | Ki M (2024) Country Data Set. Available from: https://www.kaggle.com/datasets/matthewki/country-data-set. |
| [12] |
MaCurdy T(2015) How Effective Is the Minimum Wage at Supporting the Poor? J Polit Econ 123: 497–545. https://doi.org/10.1086/679626 doi: 10.1086/679626
|
| [13] |
Romich J (2017) Is Raising the Minimum Wage a Good Idea? Evidence and Implication for Social Work. J Storage 62:367-370. https://doi.org/10.1093/sw/swx033 doi: 10.1093/sw/swx033
|
| [14] | Taarifa (2017) For 40 Years, Rwandan Labourers Earn Rwf100. Who Is Blocking Minimum Wage Increase? Available from: https://taarifa.rw/for-40-years/. |
| [15] | Gini Index (World Bank Estimate) (2024). Available from: https://genderdata.worldbank.org/indicators/si-pov-gini/. |
| [16] | United States Census Bureau (2024) Gini Index. Available from: https://www.census.gov/topics/income-poverty/income-inequality/about/metrics/gini-index.html. |
| [17] | USNews (2024) Quality of Life. Available from: https://www.usnews.com/news/best-countries/rankings/quality-of-life. |
| [18] | Vodafone Group PLC (2024) M-PESA. Available from: https://www.vodafone.com/about-vodafone/what-we-do/consumer-products-and-services/m-pesa. |
| [19] | Wager S, Hastie T, Efron B (2014) Confidence Intervals for Random Forests: The Jackknife and the Infinitesimal Jacknife. J Mach Learn Res 15: 1625–1651. |
| [20] | Wei T, Simko V (2021) R package 'corrplot': Visualization of a Correlation Matrix. Version 0.92. Available from: https://github.com/taiyun/corrplot. |
| [21] | Wickham H (2016) ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag, New York. Available from: https://ggplot2.tidyverse.org. |
| [22] |
Wright MN, Ziegler A (2017) Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J Stat Softw 77: 1–17. https://doi.org/10.48550/arXiv.1508.04409 doi: 10.48550/arXiv.1508.04409
|







Figures(8) / Tables(5)
Matthew Ki, Junfeng Shang. Prediction of minimum wages for countries with random forests and neural networks[J]. Data Science in Finance and Economics, 2024, 4(2): 309-332. doi: 10.3934/DSFE.2024013







 DownLoad:
DownLoad: