Citation: Alessia Civallero, Cristina Zucca. The Inverse First Passage time method for a two dimensional Ornstein Uhlenbeck process with neuronal application[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 8162-8178. doi: 10.3934/mbe.2019412

| [1] | X. Chen, L. Cheng, J. Chadam, et al., Existence and uniqueness of solutions to the inverse boundary crossing problem for diffusions, Ann. Appl. Probab., 21(2011), 1663–1693. |
| [2] | E. Ekström and S. Janson, The inverse first-passage problem and optimal stopping, Ann. Appl. Probab., 26(2016), 3154–3177. |
| [3] | M. Abundo, An inverse first-passage problem for one-dimensional diffusions with random starting point, Stat. Probab. Lett. 82(2012), 7–14. |
| [4] | P. Lansky, L. Sacerdote and C. Zucca, The Gamma renewal process as an output of the diffusion leaky integrate-and-fire neuronal model, Biol. Cybern., 110(2016),193–200. |
| [5] | L. Sacerdote, A. E. P. Villa and C. Zucca, On the classification of experimental data modeled via a stochastic leaky integrate and fire model through boundary values, Bull. Math. Biol., 68(2006),1257–1274. |
| [6] | C. Zucca and L. Sacerdote, On the inverse first-passage-time problem for a Wiener process, Ann. Appl. Prob., 19(2009), 1319–1346. |
| [7] | G. L. Gerstein and B. Mandelbrot, Random walk models for the spike activity of a single neuron, Biophys. J., 4(1964),41–68. |
| [8] | A. Klaus, S. Yu and D. Plenz, Statistical Analyses Support Power Law Distributions Found in Neuronal Avalanches, PLoS ONE, 6(2011), e19779. |
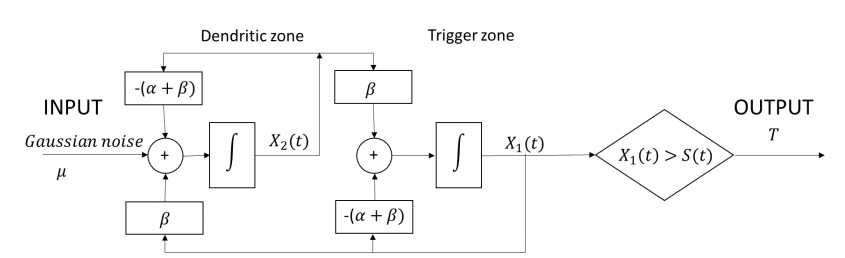
| [9] | P. Lansky and R. Rodriguez, Two-compartment stochastic model of a neuron, Physica D, 132(1999), 267–286. |
| [10] | L. M. Ricciardi and L.Sacerdote, The Ornstein-Uhlenbeck process as a model for neuronal activity. I. Mean and variance of the firing time, Biological Cybernetics, 35(1979), 1–9. |
| [11] | L. Sacerdote and M. T. Giraudo, Stochastic Integrate and Fire Models: a Review on Mathematical Methods and their Applications Stochastic Biomathematical Models with Applications to Neuronal Modeling, in Lecture Notes in Mathematics series (Biosciences subseries) (eds. Bachar, Batzel and Ditlevsen), Springer, 2058(2013), 99–142. |
| [12] | Y. Tsubo, Y. Isomura and T. Fukai, Power-Law Inter-Spike Interval Distributions Infer a Conditional Maximization of Entropy in Cortical Neurons, PLoS Comput. Biol., 8(2012), e1002461. |
| [13] | N. Yannaros, On Cox processes and Gamma-renewal processes, J. Appl. Probab., 25(1988), 423–427. |
| [14] | J. L. Folks and R. S. Chhikara, The Inverse Gaussian Distribution and Its Statistical Application–A Review, J. Royal Statist. Soc. Series B Methodol. 40(1978), 263–289. |
| [15] | S. Iyengar and G. Patwardhan, Recent developments in the inverse Gaussian distribution, Handbook Statist., 7(1988),479–490. |
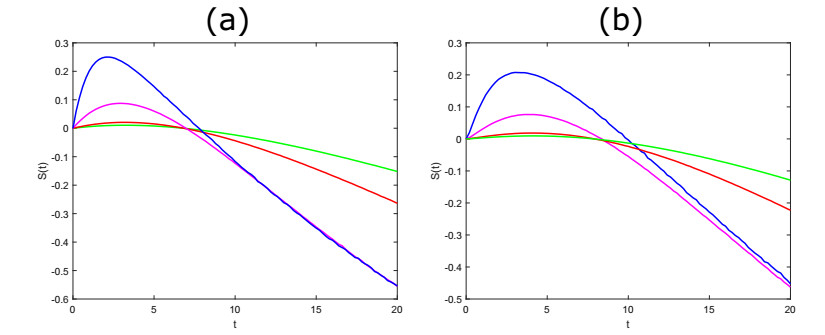
| [16] | E. Benedetto, L. Sacerdote and C. Zucca, A first passage problem for a bivariate diffusion process: numerical solution with an application to neuroscience when the process is Gauss-Markov, J. Comp. Appl. Math., 242(2013), 41–52. |
| [17] | L. Arnold, Stochastic Differential Equations: Theory and Applications, Krieger Publishing Company, Malabar, Florida, 1974. |
| [18] | M. Abramowitz and I. A. Stegun, Handbook of Mathematical Functions With Formulas, Graphs, and Mathematical Tables, Dover, New York, 1964. |
| [19] | K. E. Atkinson, An introduction to numerical analysis, Wiley, New York, 1989. |
Figures(10)

Alessia Civallero, Cristina Zucca. The Inverse First Passage time method for a two dimensional Ornstein Uhlenbeck process with neuronal application[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 8162-8178. doi: 10.3934/mbe.2019412







 DownLoad:
DownLoad: