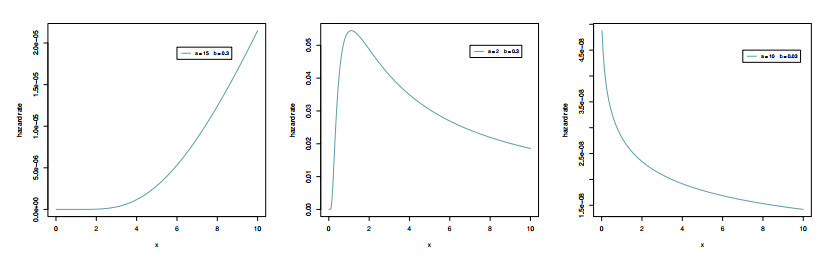
A system's reliability is defined as the likelihood that its strength surpasses its stress, referred to as the stress–strength index. In this work, we introduce a new stress–strength model based on the inverted Chen distribution. By analyzing the failure times of organic white light-emitting diodes and pump motors, we focus on the inferences of the stress–strength index $ \mathfrak{R} = P(Y < X) $, where: (1) the strength $ (X) $ and stress $ (Y) $ are independent random variables following inverted Chen distributions, and (2) the data are acquired using the adaptive progressive type-Ⅱ censoring plan. The inferences are based on two estimation approaches: maximum likelihood and Bayesian. The Bayes estimates are obtained with the Markov Chain Monte Carlo sampling process leveraging the squared error and LINEX loss functions. Furthermore, two approximate confidence intervals and two credible intervals are developed. A simulation study is done to examine the various estimations presented in this work. To assess the effectiveness of different point and interval estimates, some precision metrics are applied, especially root mean square error, interval length, and coverage probability. Finally, two practical problems are examined to demonstrate the significance and applicability of the given estimation approaches. The analysis demonstrates the suitability of the proposed model for examining engineering data and highlights the superiority of the Bayesian estimation approach in estimating the unknown parameters.
Citation: Refah Alotaibi, Mazen Nassar, Zareen A. Khan, Ahmed Elshahhat. Statistical analysis of stress–strength in a newly inverted Chen model from adaptive progressive type-Ⅱ censoring and modelling on light-emitting diodes and pump motors[J]. AIMS Mathematics, 2024, 9(12): 34311-34355. doi: 10.3934/math.20241635
A system's reliability is defined as the likelihood that its strength surpasses its stress, referred to as the stress–strength index. In this work, we introduce a new stress–strength model based on the inverted Chen distribution. By analyzing the failure times of organic white light-emitting diodes and pump motors, we focus on the inferences of the stress–strength index $ \mathfrak{R} = P(Y < X) $, where: (1) the strength $ (X) $ and stress $ (Y) $ are independent random variables following inverted Chen distributions, and (2) the data are acquired using the adaptive progressive type-Ⅱ censoring plan. The inferences are based on two estimation approaches: maximum likelihood and Bayesian. The Bayes estimates are obtained with the Markov Chain Monte Carlo sampling process leveraging the squared error and LINEX loss functions. Furthermore, two approximate confidence intervals and two credible intervals are developed. A simulation study is done to examine the various estimations presented in this work. To assess the effectiveness of different point and interval estimates, some precision metrics are applied, especially root mean square error, interval length, and coverage probability. Finally, two practical problems are examined to demonstrate the significance and applicability of the given estimation approaches. The analysis demonstrates the suitability of the proposed model for examining engineering data and highlights the superiority of the Bayesian estimation approach in estimating the unknown parameters.

| [1] |
Z. W. Birnbaum, R. C. McCarty, A distribution-free upper confidence bound for $Pr(Y < X)$, based on independent samples of $X$ and $Y$, Ann. Math. Statist., 29 (1958), 558–562. https://doi.org/10.1214/aoms/1177706631 doi: 10.1214/aoms/1177706631

|
| [2] | S. Kotz, Y. Lumelskii, Y. Pensky, The stress–strength model and its generalizations: Theory and applications, World Scientific, 2003. https://doi.org/10.1142/5015 |
| [3] |
D. K. Al-Mutairi, M. E. Ghitany, D. Kundu, Inferences on stress–strength reliability from Lindley distributions, Comm. Statist. Theory Methods, 42 (2013), 1443–1463. https://doi.org/10.1080/03610926.2011.563011 doi: 10.1080/03610926.2011.563011
|
| [4] |
V. K. Sharma, S. K. Singh, U. Singh, V. Agiwal, The inverse Lindley distribution: A stress–strength reliability model with application to head and neck cancer data, J. Ind. Prod. Eng., 32 (2015), 162–173. https://doi.org/10.1080/21681015.2015.1025901 doi: 10.1080/21681015.2015.1025901
|
| [5] |
A. S. Hassan, A. Al-Omari, H. F. Nagy, Stress–strength reliability for the generalized inverted exponential distribution using MRSS, Iran. J. Sci. Technol. Trans. A Sci., 45 (2021), 641–659. https://doi.org/10.1007/s40995-020-01033-9 doi: 10.1007/s40995-020-01033-9
|
| [6] |
A. Pak, M. Z. Raqab, M. R. Mahmoudi, S. S. Band, A. Mosavi, Estimation of stress–strength reliability R = P (X> Y) based on Weibull record data in the presence of inter-record times, Alexandria Eng. J., 61 (2022), 2130–2144. https://doi.org/10.1016/j.aej.2021.07.025 doi: 10.1016/j.aej.2021.07.025
|
| [7] |
N. Alsadat, A. S. Hassan, M. Elgarhy, C. Chesneau, R. E. Mohamed, An efficient stress–strength reliability estimate of the unit gompertz distribution using ranked set sampling, Symmetry, 15 (2023), 1121. https://doi.org/10.3390/sym15051121 doi: 10.3390/sym15051121
|
| [8] |
M. Nassar, R. Alotaibi, C. Zhang, Product of spacing estimation of stress–strength reliability for alpha power exponential progressively Type-Ⅱ censored data, Axioms, 12 (2023), 752. https://doi.org/10.3390/axioms12080752 doi: 10.3390/axioms12080752
|
| [9] |
F. S. Quintino, M. Oliveira, P. N. Rathie, L. C. S. M. Ozelim, T. A. da Fonseca, Asset selection based on estimating stress–strength probabilities: The case of returns following three-parameter generalized extreme value distributions, AIMS Mathematics, 9 (2024), 2345–2368. https://doi.org/10.3934/math.2024116 doi: 10.3934/math.2024116
|
| [10] | P. K. Srivastava, R. S. Srivastava, Two parameter inverse Chen distribution as survival model, Int. J. Stat. Math., 11 (2014), 12–16. |
| [11] |
V. Agiwal, Bayesian estimation of stress strength reliability from inverse Chen distribution with application on failure time data, Ann. Data. Sci., 10 (2023), 317–347. https://doi.org/10.1007/s40745-020-00313-w doi: 10.1007/s40745-020-00313-w
|
| [12] | S.Kumar, A. Kumari, K. Kumar, Bayesian and classical inferences in two inverse Chen populations based on joint Type-Ⅱ censoring, Amer. J. Theor. Appl. Stat., 11 (2022), 150–159. |
| [13] |
R. Aggarwala, N. Balakrishnan, Some properties of progressive censored order statistics from arbitrary and uniform distributions with applications to inference and simulation, J. Statist. Plann. Inference, 70 (1998), 35–49. https://doi.org/10.1016/S0378-3758(97)00173-0 doi: 10.1016/S0378-3758(97)00173-0
|
| [14] |
N. Balakrishnan, C. T. Lin, On the distribution of a test for exponentiality based on progressively type-Ⅱ right censored spacings, J. Stat. Comput. Simul., 73 (2003), 277–283. https://doi.org/10.1080/0094965021000033530 doi: 10.1080/0094965021000033530
|
| [15] |
S. K. Singh, U. Singh, M. Kumar, Bayesian estimation for Poisson-exponential model under progressive type-Ⅱ censoring data with binomial removal and its application to ovarian cancer data, Comm. Statist. Simulation Comput., 45 (2016), 3457–3475. https://doi.org/10.1080/03610918.2014.948189 doi: 10.1080/03610918.2014.948189
|
| [16] |
S. Dey, M. Nassar, R. K. Maurya, Y. M. Tripathi, Estimation and prediction of Marshall–Olkin extended exponential distribution under progressively type-Ⅱ censored data, J. Stat. Comput. Simul., 88 (2018), 2287–2308. https://doi.org/10.1080/00949655.2018.1458310 doi: 10.1080/00949655.2018.1458310
|
| [17] |
M. Chacko, R. Mohan, Bayesian analysis of Weibull distribution based on progressive type-Ⅱ censored competing risks data with binomial removals, Comput. Statist., 34 (2019), 233–252. https://doi.org/10.1007/s00180-018-0847-2 doi: 10.1007/s00180-018-0847-2
|
| [18] |
H. K. T. Ng, D. Kundu, P. S. Chan, Statistical analysis of exponential lifetimes under an adaptive Type-Ⅱ progressive censoring scheme, Naval Res. Logist., 56 (2009), 687–698. https://doi.org/10.1002/nav.20371 doi: 10.1002/nav.20371
|
| [19] |
M. Nassar, O. Abo-Kasem, C. Zhang, S. Dey, Analysis of Weibull distribution under adaptive type-Ⅱ progressive hybrid censoring scheme, J. Indian Soc. Probab. Stat., 19 (2018), 25–65. https://doi.org/10.1007/s41096-018-0032-5 doi: 10.1007/s41096-018-0032-5
|
| [20] |
Y. Du, W. Gui, Statistical inference of adaptive type Ⅱ progressive hybrid censored data with dependent competing risks under bivariate exponential distribution, J. Appl. Stat., 49 (2022), 3120–3140. https://doi.org/10.1080/02664763.2021.1937961 doi: 10.1080/02664763.2021.1937961
|
| [21] |
S. Dey, A. Elshahhat, M. Nassar, Analysis of progressive type-Ⅱ censored gamma distribution, Comput. Stat., 38 (2023), 481–508. https://doi.org/10.1007/s00180-022-01239-y doi: 10.1007/s00180-022-01239-y
|
| [22] |
R. Alotaibi, M. Nassar, A. Elshahhat, Estimations of modified Lindley parameters using progressive type-Ⅱ censoring with applications, Axioms, 12 (2023), 171. https://doi.org/10.3390/axioms12020171 doi: 10.3390/axioms12020171
|
| [23] |
Q. Lv, Y. Tian, W. Gui, Statistical inference for Gompertz distribution under adaptive type-Ⅱ progressive hybrid censoring, J. Appl. Stat., 51 (2024), 451–480. https://doi.org/10.1080/02664763.2022.2136147 doi: 10.1080/02664763.2022.2136147
|
| [24] |
S. Xiao, X. Hu, H. Ren, Estimation of lifetime performance index for generalized inverse lindley distribution under adaptive progressive type-Ⅱ censored lifetime test, Axioms, 13 (2024), 727. https://doi.org/10.3390/axioms13100727 doi: 10.3390/axioms13100727
|
| [25] |
R. Kumari, F. Sultana, Y. M. Tripathi, R. K. Sinha, Parametric inference for inverted exponentiated family with jointly adaptive progressive type-Ⅱ censoring, Life Cycle Reliab. Saf. Eng., 2024. https://doi.org/10.1007/s41872-024-00281-7 doi: 10.1007/s41872-024-00281-7
|
| [26] |
M. Nassar, R. Alotaibi, A. Elshahhat, Bayesian estimation of some reliability characteristics for Nakagami model using adaptive progressive censoring, Phys. Scr., 99 (2024), 27. https://doi.org/10.1088/1402-4896/ad6f4a doi: 10.1088/1402-4896/ad6f4a
|
| [27] |
Q. Li, P. Ni, X. Du, Q. Han, K. Xu, Y. Bai, Bayesian finite element model updating with a variational autoencoder and polynomial chaos expansion, Eng. Structures, 316 (2024), 118606. https://doi.org/10.1016/j.engstruct.2024.118606 doi: 10.1016/j.engstruct.2024.118606
|
| [28] |
Q.Li, X. Du, P. Ni, Q. Han, K. Xu, Z. Yuan, Efficient Bayesian inference for finite element model updating with surrogate modeling techniques, J. Civil. Struct. Health Monit., 14 (2024), 997–1015. https://doi.org/10.1007/s13349-024-00768-y doi: 10.1007/s13349-024-00768-y
|
| [29] |
Q. Li, X. Du, P. Ni, Q. Han, K. Xu, Y. Bai, Improved hierarchical Bayesian modeling framework with arbitrary polynomial chaos for probabilistic model updating, Mech. Syst. Signal Process., 215 (2024), 111409. https://doi.org/10.1016/j.ymssp.2024.111409 doi: 10.1016/j.ymssp.2024.111409
|
| [30] |
P. Ni, Q. Han, X. Du, J. Fu, K. Xu, Probabilistic model updating of civil structures with a decentralized variational inference approach, Mech. Syst. Signal Process., 209 (2024), 111106. https://doi.org/10.1016/j.ymssp.2024.111106 doi: 10.1016/j.ymssp.2024.111106
|
| [31] |
A. Henningsen, O. Toomet, maxLik: A package for maximum likelihood estimation in R, Comput. Stat., 26 (2011), 443–458. https://doi.org/10.1007/s00180-010-0217-1 doi: 10.1007/s00180-010-0217-1
|
| [32] |
L. Zhuang, A. Xu, Y. Wang, Y. Tang, Remaining useful life prediction for two-phase degradation model based on reparameterized inverse Gaussian process, European J. Oper. Res., 319 (2024), 877–890. https://doi.org/10.1016/j.ejor.2024.06.032 doi: 10.1016/j.ejor.2024.06.032
|
| [33] | L. B. Klebanov, "Universal" loss function and unbiased estimation, Dokl. Akad. Nauk SSSR, 203 (1972), 1249–1251. |
| [34] | H. R. Varian, A Bayesian approach to real estate assessment, In: Studies in Bayesian econometrics and statistics: In Honor of L. J. Savage, North-Holland Pub. Co., 1975,195–208. |
| [35] | M. Plummer, N. Best, K. Cowles, K. Vines, CODA: Convergence diagnosis and output analysis for MCMC, R News, 6 (2006), 7–11. |
| [36] |
G. M. Farinola, R. Ragni, Electroluminescent materials for white organic light emitting diodes, Chem. Soc. Rev., 40 (2011), 3467–3482. https://doi.org/10.1039/C0CS00204F doi: 10.1039/C0CS00204F
|
| [37] | J. Zhang, G. Cheng, X. Chen, Y. Han, T. Zhou, Y. Qiu, Accelerated life test of white OLED based on lognormal distribution, Indian J. Pure Appl. Phys., 52 (2014), 671–677. |
| [38] |
M. Nassar, S. Dey, L. Wang, A. Elshahhat, Estimation of Lindley constant-stress model via product of spacing with Type-Ⅱ censored accelerated life data, Comm. Statist. Simulation Comput., 53 (2024), 288–314. https://doi.org/10.1080/03610918.2021.2018460 doi: 10.1080/03610918.2021.2018460
|
| [39] |
A. A. A. Ghaly, H. M. Aly, R. N. Salah, Different estimation methods for constant stress accelerated life test under the family of the exponentiated distributions, Qual. Reliab. Eng. Int., 32 (2016), 1095–1108. https://doi.org/10.1002/qre.1818 doi: 10.1002/qre.1818
|
| [40] | A. James, N. Chandra, Dependence stress–strength reliability estimation of bivariate xgamma exponential distribu-tion under copula approach, Palest. J. Math., 11 (2022), 213–233 |
| [41] |
N. Chandra, A. James, F. Domma, H. Rehman, Bivariate iterated Farlie-Gumbel-Morgenstern stress–strength reliability model for Rayleigh margins: Properties and estimation, Stat. Theory Related Fields, 2024. https://doi.org/10.1080/24754269.2024.2398987 doi: 10.1080/24754269.2024.2398987
|
| [42] |
L. F. Shang, Z. Z. Yan, Reliability estimation stress–strength dependent model based on copula function using ranked set sampling, J. Radiat. Res. Appl. Sci., 17 (2024), 100811. https://doi.org/10.1016/j.jrras.2023.100811 doi: 10.1016/j.jrras.2023.100811
|







Figures(8) / Tables(25)

Refah Alotaibi, Mazen Nassar, Zareen A. Khan, Ahmed Elshahhat. Statistical analysis of stress–strength in a newly inverted Chen model from adaptive progressive type-Ⅱ censoring and modelling on light-emitting diodes and pump motors[J]. AIMS Mathematics, 2024, 9(12): 34311-34355. doi: 10.3934/math.20241635







 DownLoad:
DownLoad: