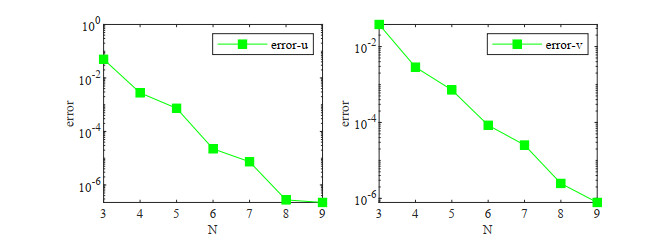
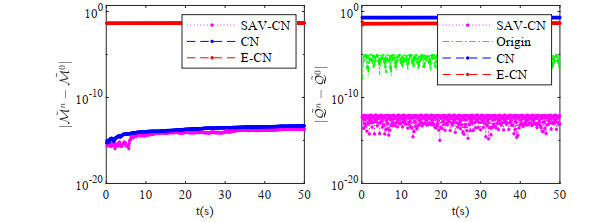
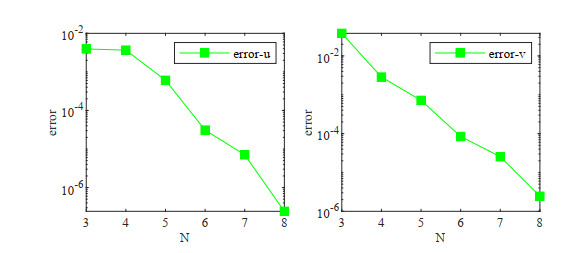
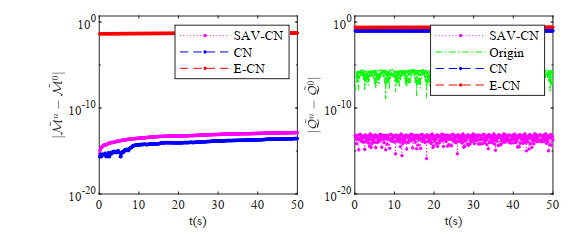
In this paper, a fully discrete scheme is proposed to solve the nonlinear Schrödinger-Possion equations. The scheme is developed by the scalar auxiliary variable (SAV) approach, the Crank-Nicolson temproal discretization and the Galerkin-Legendre spectral spatial discretization. The fully discrete scheme is proved to be mass- and energy- conserved. Moreover, unconditional energy stability and convergence of the scheme are obtained by the use of the Gagliardo-Nirenberg and some Sobolev inequalities. Numerical results are presented to confirm our theoretical findings.
Citation: Chunye Gong, Mianfu She, Wanqiu Yuan, Dan Zhao. SAV Galerkin-Legendre spectral method for the nonlinear Schrödinger-Possion equations[J]. Electronic Research Archive, 2022, 30(3): 943-960. doi: 10.3934/era.2022049
In this paper, a fully discrete scheme is proposed to solve the nonlinear Schrödinger-Possion equations. The scheme is developed by the scalar auxiliary variable (SAV) approach, the Crank-Nicolson temproal discretization and the Galerkin-Legendre spectral spatial discretization. The fully discrete scheme is proved to be mass- and energy- conserved. Moreover, unconditional energy stability and convergence of the scheme are obtained by the use of the Gagliardo-Nirenberg and some Sobolev inequalities. Numerical results are presented to confirm our theoretical findings.

| [1] |
T. Lu, W. Cai, A Fourier spectral-discontinuous Galerkin method for time-dependent 3-D Schrödinger-Possion equations with discontinuous potentials, J. Comput. Appl. Math., 220 (2008), 588–614. https://doi.org/10.1016/j.cam.2007.09.025 doi: 10.1016/j.cam.2007.09.025

|
| [2] |
M. Ehrhardt, A. Zisowsky, Fast calculation of energy and mass preserving solutions of Schrödinger-Poisson systems on unbounded domains, J. Comput. Appl. Math., 187 (2006), 1–28. https://doi.org/10.1016/j.cam.2005.03.026 doi: 10.1016/j.cam.2005.03.026
|
| [3] |
C. Ringhofer, J. Soler, Discrete Schrödinger-Poisson systems preserving energy and mass, Appl. Math. Lett., 13 (2000), 27–32. https://doi.org/10.1016/S0893-9659(00)00072-0 doi: 10.1016/S0893-9659(00)00072-0
|
| [4] |
X. Dong, A short note on simplified pseudospectral methods for computing ground state and dynamics of spherically symmetric Schrödinger-Possion Slater system, J. Comput. Phys., 230 (2011), 7917–7922. https://doi.org/10.1016/j.jcp.2011.07.026 doi: 10.1016/j.jcp.2011.07.026
|
| [5] |
Y. Zhang, X. Dong, On the computation of ground state and dynamics of Schrödinger-Poisson Slater system, J. Comput. Phys., 230 (2011), 2660–2676. https://doi.org/10.1016/j.jcp.2010.12.045 doi: 10.1016/j.jcp.2010.12.045
|
| [6] |
W. Auzinger, T. Kassebacher, O. Koch, M. Thalhammeret, Convergence of a strang splitting finite element discretization for the Schrödinger-Poisson equation, Math. Model. Numer. Anal., 51 (2017), 1245–1278. https://doi.org/10.1051/m2an/2016059 doi: 10.1051/m2an/2016059
|
| [7] |
C. Cheng, Q. Liu, J. LeeH, H. Z. Massoud, Spectral element method for the Schrödinger-Possion system, J. Comput. Electron., 3 (2004), 417–421. https://doi.org/10.1007/s10825-004-7088-z doi: 10.1007/s10825-004-7088-z
|
| [8] |
C. Lubich, On splitting methods for Schrödinger-Poisson and cubic nonlinear Schrödinger equations, Math. Comput., 264 (2008), 2141–2153. https://doi.org/10.1090/S0025-5718-08-02101-7 doi: 10.1090/S0025-5718-08-02101-7
|
| [9] |
M. Li, C. Huang, Y. Zhao, Fast conservative numerical algorithm for the coupled fractional Klein-Gordon-Schrödinger equation, Numer. Algorithms, 84 (2020), 1080–1119. https://doi.org/10.1007/s11075-019-00793-9 doi: 10.1007/s11075-019-00793-9
|
| [10] |
M. Li, D. Shi, J. Wang, J. Wang, W. Ming, Unconditional superconvergence analysis of the conservative linearized Galerkin FEMs for nonlinear Klein-Gordon-Schrödinger equation, Appl. Numer. Math., 142 (2019), 47–63. https://doi.org/10.1016/j.apnum.2019.02.004 doi: 10.1016/j.apnum.2019.02.004
|
| [11] |
M. Li, Y. Zhao, A fast energy conserving finite element method for the nonlinear fractional Schrödinger equation with wave operator, Appl. Math. Comput., 338 (2018), 758–773. https://doi.org/10.1016/j.amc.2018.06.010 doi: 10.1016/j.amc.2018.06.010
|
| [12] |
X. Antoine, W. Bao, C. Besse, Computational methods for the dynamics of the nonlinear Schrödinger/Gross-Pitaevskii equations, Comput. Phys. Commun., 184 (2013), 758–773. https://doi.org/10.1016/j.cpc.2013.07.012 doi: 10.1016/j.cpc.2013.07.012
|
| [13] |
W. Bao, Q. Tang, Z. Xu, Numerical methods and comparison for computing dark and bright solitons in the NLS equation, J. Comput. Phys., 235 (2013), 423–445. https://doi.org/10.1016/j.jcp.2012.10.054 doi: 10.1016/j.jcp.2012.10.054
|
| [14] |
J. Hong, Y. Liu, H. Munthe-Kaas, A. Zanna, Globally conservative properties and error estimation of a multi-symplectic scheme for Schrödinger equations with variable coefficients, Appl. Numer. Math., 56 (2006), 814–843. https://doi.org/10.1016/j.apnum.2005.06.006 doi: 10.1016/j.apnum.2005.06.006
|
| [15] |
T. Wang, B. Guo, Q. Xu, Fourth-order compact and energy conservative difference schemes for the nonlinear Schrödinger equation in two dimensions, J. Comput. Phys., 243 (2013), 382–399. https://doi.org/10.1016/j.jcp.2013.03.007 doi: 10.1016/j.jcp.2013.03.007
|
| [16] |
C. Besse, A relaxation scheme for the nonlinear Schrödinger equation, SIAM J. Numer. Anal., 42 (2004), 934–952. https://doi.org/10.1137/S0036142901396521 doi: 10.1137/S0036142901396521
|
| [17] |
W. Liu, B. Wang, High-order implicit Galerkin-Legendre spectral method for the two-dimensional Schrödinger equation, Appl. Math. Comput., 324 (2018), 59–68. https://doi.org/10.1016/j.amc.2017.12.009 doi: 10.1016/j.amc.2017.12.009
|
| [18] |
M. Wang, D. Li, C. Zhang, Y. Tang, Long time behavior of solutions of gKdV equations, J. Math. Anal. Appl., 390 (2012), 136–150. https://doi.org/10.1016/j.jmaa.2012.01.031 doi: 10.1016/j.jmaa.2012.01.031
|
| [19] |
M. Li, M. Fei, N. Wang, C. Huang, A dissipation-preserving finite element method for nonlinear fractional wave equations on irregular convex domains, Math. Comput. Simu., 177 (2020), 404–419. https://doi.org/10.1016/j.matcom.2020.05.005 doi: 10.1016/j.matcom.2020.05.005
|
| [20] |
J. Shen, J. Xu, J. Yang, A new class of efficient and robust energy stable schemes for gradient flows, Math. Comput. Simu., 61 (2019), 474–506. https://doi.org/10.1137/17M1150153 doi: 10.1137/17M1150153
|
| [21] |
J. Shen, J. Xu, J. Yang, The scalar auxiliary variable (SAV) approach for gradient flows, J. Comput. Phys., 353 (2018), 407–416. https://doi.org/10.1016/j.jcp.2017.10.021 doi: 10.1016/j.jcp.2017.10.021
|
| [22] |
X. Li, J. Shen, H. Rui, Energy stability and convergence of SAV block-centered finite difference method for gradient flows, Math. Comput., 319 (2019), 2047–2968. https://doi.org/10.1090/mcom/3428 doi: 10.1090/mcom/3428
|
| [23] |
J. Shen, J. Xu, Convergence and error analysis for the scalar auxiliary variable (SAV) schemes to gradient flows, SIAM J. Numer. Anal., 56 (2018), 2895–2912. https://doi.org/10.1137/17M1159968 doi: 10.1137/17M1159968
|
| [24] |
G. Akrivis, B. Li, D. Li, Energy-decaying extrapolated RK–SAV methods for the Allen–Cahn and Cahn–Hilliard equations, SIAM J. Sci. Comput., 41 (2019), A3703–A3727. https://doi.org/10.1137/19M1264412 doi: 10.1137/19M1264412
|
| [25] | D. Li, W. Sun, Linearly implicit and high-order energy-conserving schemes for nonlinear wave equations, J. Sci. Comput., 83 (2020). https://doi.org/10.1007/s10915-020-01245-6 |
| [26] | W. Cao, D. Li, Z. Zhang, Unconditionally optimal convergence of an energy-conserving and linearly implicit scheme for nonlinear wave equations, Sci. China. Math., 2021. https://doi.org/10.1007/s11425-020-1857-5 |
| [27] |
W. Cai, C. Jiang, Y. Wang, Y. Song, Structure-preserving algorithms for the two-dimensional sine-Gordon equation with Neumann boundary conditions, J. Comput. Phys., 395 (2019), 166–185. https://doi.org/10.1016/j.jcp.2019.05.048 doi: 10.1016/j.jcp.2019.05.048
|
| [28] |
X. Li, J. Wen, D. Li, Mass-and energy-conserving difference schemes for nonlinear fractional Schrödinger equations, Appl. Math. Lett., 111 (2020), 106686. https://doi.org/10.1016/j.aml.2020.106686 doi: 10.1016/j.aml.2020.106686
|
| [29] |
J. Cai, J. Shen, Two classes of linearly implicit local energy-preserving approach for general multi-symplectic Hamiltonian PDEs, J. Comput. Phys., 401 (2019), 108975. https://doi.org/10.1016/j.jcp.2019.108975 doi: 10.1016/j.jcp.2019.108975
|
| [30] |
R. Tang, D. Li, On symmetrical methods for charged particle dynamics, Symmetry, 13 (2021), 1626. https://doi.org/10.3390/sym13091626 doi: 10.3390/sym13091626
|
| [31] | C. Canuto, M. Hussaini, A. Quarteroni, T. Zang, Spectral Methods in Fluid Dynamics, Springer, Berlin, 1987. |
| [32] | Z. Sun, The numerical methods for partial differential equations, Science Press, Beijing, 2005. |
| [33] | L. Evans, Partial Differential Equations, 2$^{nd}$ edition, AMS, Providence, 2010. |
| [34] | Y. Zhou, Application of discrete functional analysis to the finite difference methods, International Academic Publishers, Beijing, 1990. |
| [35] |
Y. Maday, A. Quarteroni, Legendre and Chebyshev spectral approximations of Burgers' equation, Numer. Math., 37 (1981), 321-332. https://doi.org/10.1007/BF01400311 doi: 10.1007/BF01400311
|
| [36] |
D. Li, C. Zhang, Split Newton iterative algorithm and its application, Appl. Math. Comput., 217 (2010), 2260-2265. https://doi.org/10.1016/j.amc.2010.07.026 doi: 10.1016/j.amc.2010.07.026
|
Figures(4) / Tables(2)
Chunye Gong, Mianfu She, Wanqiu Yuan, Dan Zhao. SAV Galerkin-Legendre spectral method for the nonlinear Schrödinger-Possion equations[J]. Electronic Research Archive, 2022, 30(3): 943-960. doi: 10.3934/era.2022049







 DownLoad:
DownLoad: