Citation: Simge Çelebi, Mert Burkay Çöteli. Red and white blood cell classification using Artificial Neural Networks[J]. AIMS Bioengineering, 2018, 5(3): 179-191. doi: 10.3934/bioeng.2018.3.179

| [1] | Shapiro MF, Sheldon G (1987) The Complete Blood Count and Leukocyte Differential Count: An Approach to Their Rational Application. J Emerg Med 106: 65–74. |
| [2] | Lynch E C. (1990) Peripheral blood smear. Butterworths, Boston: Pubmed, 90: 1373–1377. |
| [3] |
Hastings WK (1970) Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57: 97–109. doi: 10.1093/biomet/57.1.97

|
| [4] | Ng HP, Ong SH, Foong KWC, et al. (2006) Medical image segmentation using k-means clustering and improved watershed algorithm. IEEE Southwest Symp Image Anal Interpret 106: 61–65. |
| [5] |
Kurita T, Otsu N, Abdelmalek N (1992) Maximum likelihood thresholding based on population mixture models. Pattern Recogn 25: 1231–1240. doi: 10.1016/0031-3203(92)90024-D
|
| [6] |
Danielsson PE (1980) Euclidean distance mapping. Comput GraphImage Process 14: 227–248. doi: 10.1016/0146-664X(80)90054-4
|
| [7] | Sobel I (1990) An isotropic 3 × 3 image gradient operator. Mach vision three dimensional scenes, 376–379. |
| [8] | Scotti F (2005) Automatic morphological analysis for acute leukemia identification in peripheral blood microscope images. IEEE Int Conf Computl Intelli Meas Syst Appl CIMSA. 25: 96–101 |
| [9] |
Sadeghian F, Seman Z, Ramli AR, et al. (2009) A framework for white blood cell segmentation in microscopic blood images using digital image processing. Biol Proced Online 11: 196. doi: 10.1007/s12575-009-9011-2
|
| [10] |
Jesus A, Georges F (2003) Automated detection of working area of peripheral blood smears using mathematical morphology. Anal Cell pathol 25: 37–49. doi: 10.1155/2003/642562
|
| [11] |
Goswami R, Pi D, Pal J, et al. (2015) Performance evaluation of a dynamic telepathology system (Panoptiq(™)) in the morphologic assessment of peripheral blood film abnormalities. Int J Lab hematol 37: 365–371. doi: 10.1111/ijlh.12294
|
| [12] | D'Ambrosio MV, Bakalar M, Bennuru S, et al. (2015) Point-of-care quantification of blood-borne filarial parasites with a mobile phone microscope. Sci Transl Med 7: 286re4. |
| [13] | Manik S, Saini LM, Vadera N (2017) Counting and classification of White blood cell using Artificial Neural Network (ANN). IEEE Int Con Power Electron Intell Control Energy Syst 2017:1–5 |
| [14] | Jia YQ, Shelhamer E, Donahue J, et al.(2014) Caffe: Convolutional architecture for fast feature embedding. Proc 22nd ACM Int Conf Multimedia, 675–678 |
| [15] | Das DK, Maiti AK, Chakraborty C (2015) Automated system for characterization and classification of malaria infected stages using light microscopic images of thin blood smears. J Microsc-Oxford 257: 238–252. |
| [16] | Automatic Peripheral Blood Smear and Slide Scanner Device. Available from: http://www.mantiscope.com |
| [17] | Devi S, Singha J, Sharma M, et al. (2016) Erythrocyte segmentation for quantification in microscopic images of thin blood smears. J Intell Fuzzy Syst 4: 2847–2856. |
| [18] |
Lee H, Chen YPP (2014) Cell morphology based classification for red cells in blood smear images. Pattern Recogn Lett 49: 155–161. doi: 10.1016/j.patrec.2014.06.010
|
| [19] | Amin MM, Kermani S, Talebi A, et al. (2015) Recognition of acute lymphoblastic leukemia cells in microscopic images using K-means clustering and support vector machine classifier. J Med Signal Sensor 5: 49. |
| [20] | Li Y, Zhu R, Mi L, et al. (2016) Segmentation of white blood cell from acute Lymphoblastic Leukemia images using dual-threshold method. ComputMathMethod M 2016: 9514707. |
| [21] | Linder N,Tukki R, Walliander M, et al. (2014) A malaria diagnostic tool based on computer vision screening and visualization of Plasmodium falciparum candidate areas in digitized blood smears. PLos One 9: e104855. |
| [22] | Zhu C, Zheng Y, Luu K, et al. (2016) CMS-RCNN: contextual multi-scale region-based CNN for unconstrained face detection. In Bhanu B, Kumar A, Deep Learning for Biometrics, 3 Eds., Switzerland: Springer , 57–79. |
| [23] | Beucher S, Mathmatique CDM (1991) The watershed transformation applied to image segmentation. Scanning Microsc Suppl 6: 299–314 |
| [24] |
Dollar P, Wojek C, Schiele B, et al. (2012) Pedestrian detection: An evaluation of the state of the art. IEEE T Pattern Anal 34: 743. doi: 10.1109/TPAMI.2011.155
|
| [25] | Redmon J, Divvala S, Girshick R, et al. (2016) You only look once: Unified, real-time object detection. Comput Vision Pattern Recognit 2016: 779–788. |
| [26] | He K, Zhang X, Ren S, et al. (2016) Deep residual learning for image recognition. IEEE conference on Compute Vison and Pattern Recogn, 770–778. |
| [27] | Govind D, Lutnick B, Tomaszewski JE, et al. (2018). Automated erythrocyte detection and classification from whole slide images. J Med Imag 5: 027501. |


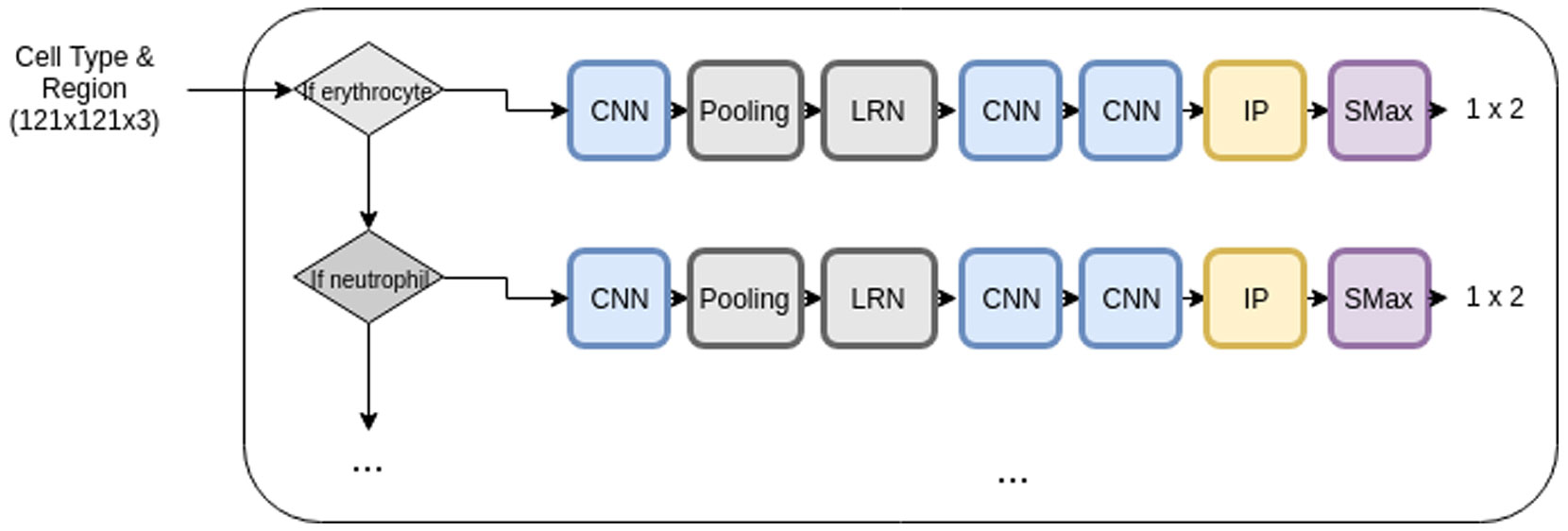
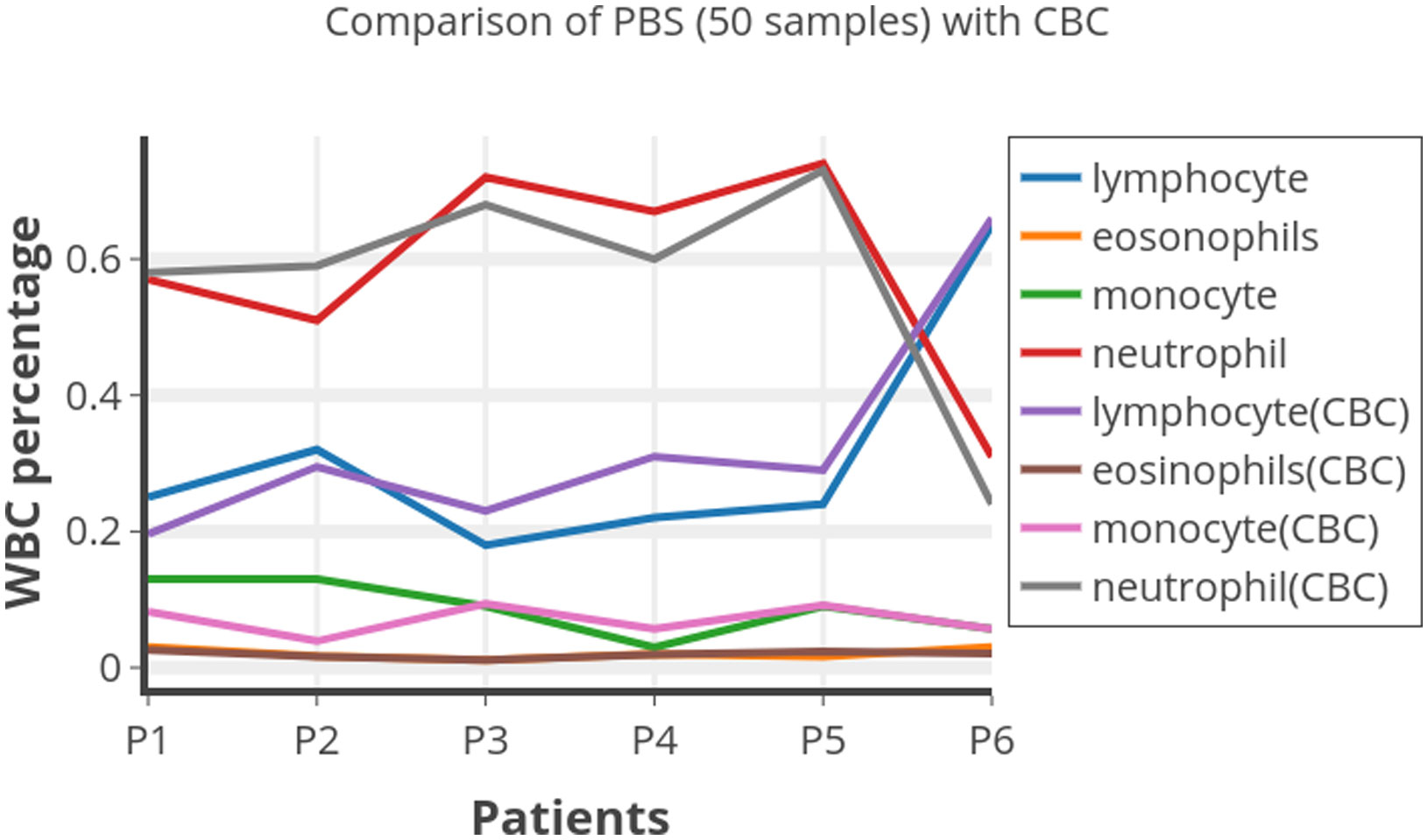
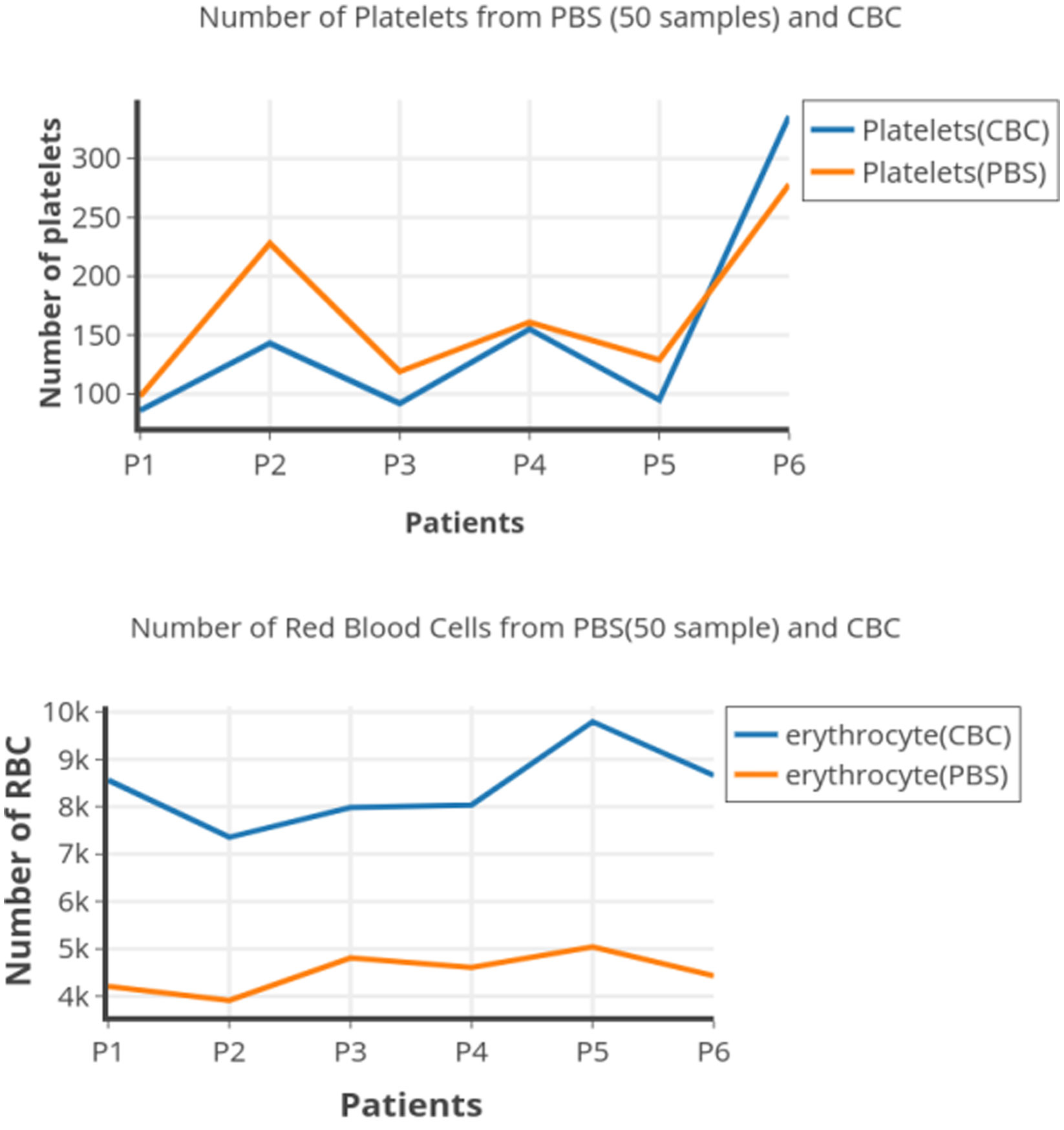

Figures(10) / Tables(1)

Simge Çelebi, Mert Burkay Çöteli. Red and white blood cell classification using Artificial Neural Networks[J]. AIMS Bioengineering, 2018, 5(3): 179-191. doi: 10.3934/bioeng.2018.3.179







 DownLoad:
DownLoad: