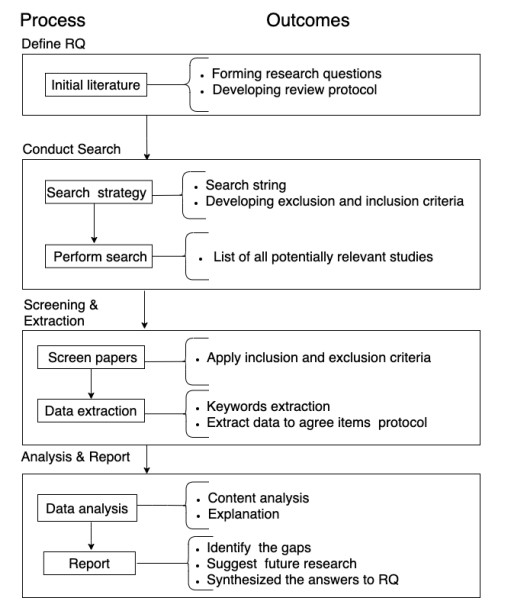
Affective music composition systems are known to trigger emotions in humans. However, the design of such systems to stimulate users' emotions continues to be a challenge because, studies that aggregate existing literature in the domain to help advance research and knowledge is limited. This study presents a systematic literature review on affective algorithmic composition systems. Eighteen primary studies were selected from IEEE Xplore, ACM Digital Library, SpringerLink, PubMed, ScienceDirect, and Google Scholar databases following a systematic review protocol. The findings revealed that there is a lack of a unique definition that encapsulates the various types of affective algorithmic composition systems. Accordingly, a unique definition is provided. The findings also show that most affective algorithmic composition systems are designed for games to provide background music. The generative composition method was the most used compositional approach. Overall, there was rather a low amount of research in the domain. Possible reasons for these trends are the lack of a common definition for affective music composition systems and also the lack of detailed documentation of the design, implementation and evaluation of the existing systems.
Citation: Abigail Wiafe, Pasi Fränti. Affective algorithmic composition of music: A systematic review[J]. Applied Computing and Intelligence, 2023, 3(1): 27-43. doi: 10.3934/aci.2023003
Affective music composition systems are known to trigger emotions in humans. However, the design of such systems to stimulate users' emotions continues to be a challenge because, studies that aggregate existing literature in the domain to help advance research and knowledge is limited. This study presents a systematic literature review on affective algorithmic composition systems. Eighteen primary studies were selected from IEEE Xplore, ACM Digital Library, SpringerLink, PubMed, ScienceDirect, and Google Scholar databases following a systematic review protocol. The findings revealed that there is a lack of a unique definition that encapsulates the various types of affective algorithmic composition systems. Accordingly, a unique definition is provided. The findings also show that most affective algorithmic composition systems are designed for games to provide background music. The generative composition method was the most used compositional approach. Overall, there was rather a low amount of research in the domain. Possible reasons for these trends are the lack of a common definition for affective music composition systems and also the lack of detailed documentation of the design, implementation and evaluation of the existing systems.

| [1] | D. M. Butler, An Historical Investigation and Bibligraphy of Ninetheeth Century Music Psychology Literature, Thesis, 1973. |
| [2] | C. Roads, The Computer Music Tutorial, MIT Press, 1996. |
| [3] |
M. Scirea, P. Eklund, J. Togelius, S. Risi, Can you feel it? Evaluation of affective expression in music generated by MetaCompose, GECCO 2017 - Proc. 2017 Genet. Evol. Comput. Conf., (2017), 211–218. https://doi.org/10.1145/3071178.3071314 doi: 10.1145/3071178.3071314

|
| [4] |
M. Scirea, J. Togelius, P. Eklund, S. Risi, Towards an experiment on perception of affective music generation using MetaCompose, GECCO 2018 Companion - Proc. 2018 Genet. Evol. Comput. Conf. Companion, (2018), 131–132. https://doi.org/10.1145/3205651.3205745 doi: 10.1145/3205651.3205745
|
| [5] | G. R. Marcos, An investigation on the automatic generation of music and its application into video games, 2019 8th Int. Conf. Affect. Comput. Intell. Interact. Work. Demos, ACⅡW 2019, (2019), 21–25. https://doi.org/10.1109/ACIIW.2019.8925275 |
| [6] |
M. Scirea, M. J. Nelson, J. Togelius, Moody Music Generator: Characterising Control Parameters Using Crowdsourcing, International Conference on Evolutionary and Biologically Inspired Music and Art, (2015), 200–211. https://doi.org/10.1007/978-3-319-16498-4 doi: 10.1007/978-3-319-16498-4
|
| [7] |
I. Daly, D. Williams, A. Malik, J. Weaver, A. Kirke, F. Hwang, et al., Personalised, Multi-Modal, Affective State Detection for Hybrid Brain-Computer Music Interfacing, IEEE T. Affect. Comput., 11 (2018), 111–124. https://doi.org/10.1109/TAFFC.2018.2801811 doi: 10.1109/TAFFC.2018.2801811
|
| [8] |
K. Trochidis, S. Lui, Modeling affective responses to music using audio signal analysis and physiology, Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), 9617 (2016), 346–357. https://doi.org/10.1007/978-3-319-46282-0_22 doi: 10.1007/978-3-319-46282-0_22
|
| [9] | E. J. S. Gonzalez, K. McMullen, The Design of an Algorithmic Modal Music Platform for Eliciting and Detecting Emotion, 8th Int. Winter Conf. Brain-Computer Interface, BCI 2020, (2020), 31–33. https://doi.org/10.1109/BCI48061.2020.9061664 |
| [10] | D. Williams, A. Kirke, E. Miranda, I. Daly, J. Hallowell, J. Weaver, J. et al., Investigating perceived emotional correlates of rhythmic density in algorithmic music composition, ACM T. Appl. Percept., 12 (2015), 1–21. https://doi.org/10.1145/2749466 |
| [11] |
J. C. Wang, Y. H. Yang, H. M. Wang, S. K. Jeng, Modeling the affective content of music with a Gaussian mixture model, IEEE T. Affect. Comput., 6 (2015), 56–68. https://doi.org/10.1109/TAFFC.2015.2397457 doi: 10.1109/TAFFC.2015.2397457
|
| [12] | A. Chamberlain, M. Bødker, M. Kallionpää, R. Ramchurn, H. P. Gasselseder, The Design of Future Music Technologies, Proceedings of the Audio Mostly 2018 on Sound in Immersion and Emotion - AM'18, (2018), 1–2. https://doi.org/10.1145/3243274.3243314 |
| [13] |
D. Williams, A. Kirke, E. R. Miranda, E. Roesch, I. Daly, S. Nasuto, Investigating affect in algorithmic composition systems, Psychol. Music, 43 (2015) 831–854. https://doi.org/10.1177/0305735614543282 doi: 10.1177/0305735614543282
|
| [14] |
T. Eerola, J. K. Vuoskoski, A review of music and emotion studies: Approaches, emotion models, and stimuli, Music Percept., 30 (2013), 307–340. https://doi.org/10.1525/mp.2012.30.3.307 doi: 10.1525/mp.2012.30.3.307
|
| [15] | D. J. Fernández, F. Vico, AI Methods in Algorithmic Composition: A Comprehensive Survey, 2013. Accessed: Feb. 14, 2020. Available from: http://www.flexatone.net/algoNet/. |
| [16] | O. Lopez-Rincon, O. Starostenko, G. A.-S. Martín, Algoritmic music composition based on artificial intelligence: A survey, 2018 International Conference on Electronics, Communications and Computers (CONIELECOMP), (2018), 187–193. https://doi.org/10.1109/CONIELECOMP.2018.8327197 |
| [17] | B. Kitchenham, S. Charters, Guidelines for performing Systematic Literature Reviews in Software Engineering, 2007, Accessed: Feb. 15, 2020. Available from: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.117.471. |
| [18] | M. Cerqueira, P. Silva, S. Fernandes, Systematic Literature Review on Machine Learning in Software Engineering, Am. Acad. Sci. Res. J. Eng. Technol. Sci., 85 (2022), 370–396. |
| [19] |
M. N. Giannakos, P. Mikalef, I. O. Pappas, Systematic Literature Review of E-Learning Capabilities to Enhance Organizational Learning, Inf. Syst. Front., 24 (2021), 619–635. https://doi.org/10.1007/s10796-020-10097-2 doi: 10.1007/s10796-020-10097-2
|
| [20] |
R. van Dinter, B. Tekinerdogan, C. Catal, Automation of systematic literature reviews: A systematic literature review, Inf. Softw. Technol., 136 (2021), 106589. https://doi.org/10.1016/j.infsof.2021.106589 doi: 10.1016/j.infsof.2021.106589
|
| [21] | L. M. Kmet, R. C. Lee, L. S. Cook, Standard quality assessment criteria for evaluating primary research papers from a variety of fields, 2004. |
| [22] | M. Schreier, Qualitative content analysis in practice, Sage Publications, 2012. |
| [23] |
H. Koechlin, R. Coakley, N. Schechter, C. Werner, J. Kossowsky, The role of emotion regulation in chronic pain: A systematic literature review, J. Psychosom. Res., 107 (2018), 38–45. https://doi.org/10.1016/j.jpsychores.2018.02.002 doi: 10.1016/j.jpsychores.2018.02.002
|
| [24] |
T. Materla, E. A. Cudney, J. Antony, The application of Kano model in the healthcare industry: a systematic literature review, Total Qual. Manag. Bus. Excell., 30 (2019), 660–681. https://doi.org/10.1080/14783363.2017.1328980 doi: 10.1080/14783363.2017.1328980
|
| [25] |
D. Ni, Z. Xiao, M. K. Lim, A systematic review of the research trends of machine learning in supply chain management, Int. J. Mach. Learn. Cybern., 11 (2020), 1463–1482. https://doi.org/10.1007/s13042-019-01050-0 doi: 10.1007/s13042-019-01050-0
|
| [26] | A. Mattek, Emotional Communication in Computer Generated Music: Experimenting with Affective Algorithms, 2011. |
| [27] | Y. Feng, Y. Zhuang, Y. Pan, Music information retrieval by detecting mood via computational media aesthetics, Proceedings - IEEE/WIC International Conference on Web Intelligence, WI 2003, (2003), 235–241. https://doi.org/10.1109/WI.2003.1241199 |
| [28] |
J. A. Russell, A circumplex model of affect, J. Pers. Soc. Psychol., 39 (1980), 1161–1178. https://doi.org/10.1037/h0077714 doi: 10.1037/h0077714
|
| [29] |
T. Eerola, J. K. Vuoskoski, A comparison of the discrete and dimensional models of emotion in music, Psychol. Music, 39 (2011), 18–49. https://doi.org/10.1177/0305735610362821 doi: 10.1177/0305735610362821
|
| [30] |
R. A. Calvo, S. Mac Kim, Emotions in text: Dimensional and categorical models, Comput. Intell., 29 (2013), 527–543. https://doi.org/10.1111/j.1467-8640.2012.00456.x doi: 10.1111/j.1467-8640.2012.00456.x
|
| [31] |
E. Brattico, M. Pearce, The neuroaesthetics of music, Psychol. Aesthetics, Creat. Arts, 7 (2013), 48–61. https://doi.org/10.1037/a0031624 doi: 10.1037/a0031624
|
| [32] | S. Cunningham, H. Ridley, J. Weinel, R. Picking, Supervised machine learning for audio emotion recognition: Enhancing film sound design using audio features, regression models and artificial neural networks, Pers. Ubiquitous Comput., 25 (2021), 637–650. https://doi.org/10.1007/s00779-020-01389-0 |
| [33] | R. L. De Mantaras, Making Music with AI: Some examples, Proceeding of the 2006 conference on Rob Milne: A Tribute to a Pioneering AI Scientist, Entrepreneur and Mountaineer, (2006), 90–100. Available from: http://portal.acm.org/citation.cfm?id=1565089 |
| [34] | R. Wooller, A. Brown, E. Miranda, J. Diederich, A framework for comparison of process in algorithmic music systems, Generative Arts Practice, (2005), 109–124. |
| [35] | R. Rowe, Interactive music systems: machine listening and composing. Cambridge, Mass.: MIT Press, 1992. https://doi.org/10.2307/3680494 |
| [36] | D. Williams, A. Kirke, E. R. Miranda, E. B. Roesch, S. J. Nasuto, Towards Affective Algorithmic Composition, The 3rd International Conference on Music & Emotion, Jyväskylä, Finland, June 11-15, 2013, 2013. |
| [37] |
M. M. Bradley, P. J. Lang, Measuring emotion: The self-assessment manikin and the semantic differential, J. Behav. Ther. Exp. Psychiatry, 25 (1994), 49–59. https://doi.org/10.1016/0005-7916(94)90063-9 doi: 10.1016/0005-7916(94)90063-9
|
| [38] | R. Cowie, E. Douglas-Cowie, S. Savvidou, E. Mcmahon, M. Sawey, M. Schröder, 'Feeltrace': An instrument for recording perceived emotion in real time, ISCA Work. Speech & Emot., (2000), 19–24. |
| [39] |
P. Evans, G. E. McPherson, J. W. Davidson, The role of psychological needs in ceasing music and music learning activities, Psychol. Music, 41 (2013), 600–619. https://doi.org/10.1177/0305735612441736 doi: 10.1177/0305735612441736
|




Figures(5) / Tables(2)
Abigail Wiafe, Pasi Fränti. Affective algorithmic composition of music: A systematic review[J]. Applied Computing and Intelligence, 2023, 3(1): 27-43. doi: 10.3934/aci.2023003







 DownLoad:
DownLoad: