Traditionally, financial risk management is examined with cartesian and interpretivist frameworks. However, the emergence of complexity science provides a different perspective. Using a structured questionnaire completed by 120 Risk Managers, this paper pioneers a comparative analysis of cartesian and complexity science theoretical frameworks adoption in sixteen Zimbabwean banks, in unique settings of a developing country. Data are analysed with descriptive statistics. The paper finds that overally banks in Zimbabwe are adopting cartesian and complexity science theories regardless of bank size, in the same direction and trajectory. However, adoption of cartesian modeling is more comprehensive and deeper than complexity science. Furthermore, due to information asymmetries, there is diverging modeling priorities between the regulator and supervisor. The regulator places strategic thrust on Knightian risks modeling whereas banks prioritise ontological, ambiguous and Knightian uncertainty measurement. Finally, it is found that complexity science and cartesianism intersect on market discipline. From these findings, it is concluded that complexity science provides an additional dimension to quantitative risk management, hence an integration of these two perspectives is beneficial. This paper makes three contributions to knowledge. First, it adds valuable insights to theoretical perspectives on Quantitative Risk Management. Second, it provides empirical evidence on adoption of two theories from developing country perspective. Third, it offers recommendations to improve Quantitative Risk Management policy formulation and practice.
Citation: Gilbert Tepetepe, Easton Simenti-Phiri, Danny Morton. A survey comparative analysis of cartesian and complexity science frameworks adoption in financial risk management of Zimbabwean banks[J]. Quantitative Finance and Economics, 2022, 6(2): 359-384. doi: 10.3934/QFE.2022016
Traditionally, financial risk management is examined with cartesian and interpretivist frameworks. However, the emergence of complexity science provides a different perspective. Using a structured questionnaire completed by 120 Risk Managers, this paper pioneers a comparative analysis of cartesian and complexity science theoretical frameworks adoption in sixteen Zimbabwean banks, in unique settings of a developing country. Data are analysed with descriptive statistics. The paper finds that overally banks in Zimbabwe are adopting cartesian and complexity science theories regardless of bank size, in the same direction and trajectory. However, adoption of cartesian modeling is more comprehensive and deeper than complexity science. Furthermore, due to information asymmetries, there is diverging modeling priorities between the regulator and supervisor. The regulator places strategic thrust on Knightian risks modeling whereas banks prioritise ontological, ambiguous and Knightian uncertainty measurement. Finally, it is found that complexity science and cartesianism intersect on market discipline. From these findings, it is concluded that complexity science provides an additional dimension to quantitative risk management, hence an integration of these two perspectives is beneficial. This paper makes three contributions to knowledge. First, it adds valuable insights to theoretical perspectives on Quantitative Risk Management. Second, it provides empirical evidence on adoption of two theories from developing country perspective. Third, it offers recommendations to improve Quantitative Risk Management policy formulation and practice.

| [1] |
Aikman D, Galesic M, Gigerenzer G, et al. (2014) Taking uncertainty seriously: simplicity versus complexity in financial regulation. Ind Corp Change 30: 317–345. https://doi.org/10.1093/icc/dtaa024 doi: 10.1093/icc/dtaa024

|
| [2] |
Allan N, Cantle N, Godfrey P (2013) A review of the use of complex systems applied to risk appetite and emerging risks in ERM practice: Recommendations for practical tools to help risk professionals tackle the problem of risk appetite and emerging risks. Brit Actuar J 18: 163–234. https://doi.org/10.1017/S135732171200030X doi: 10.1017/S135732171200030X
|
| [3] |
Allen F, Gale D (2000) Financial Contagion. J Polit Econ 108: 1–33. https://doi.org/10.1086/262109 doi: 10.1086/262109
|
| [4] |
Althaus CE (2005) A disciplinary perspective on the epistemological status of risk. Risk Anal 25: 567–588. https://doi.org/10.1111/j.1539-6924.2005.00625.x doi: 10.1111/j.1539-6924.2005.00625.x
|
| [5] |
Anagnostou I, Sourabh S, Kandhai D (2018) Incorporating Contagion in Portfolio Credit Risk Models using Network Theory. Complexity 2018. https://doi.org/10.1155/2018/6076173 doi: 10.1155/2018/6076173
|
| [6] | Anderson N, Noss J (2013) The Fractal Market Hypothesis and its implications for the stability of financial markets. Available from: https://www.bankofengland.co.uk/-/media/boe/files/financial-stability-paper/2013/the-fractal-market-hypothesis-and-its-implications-for-the-stability-of-financial-markets.pdf?la=en&hash=D096065EA97BE61902BDE5CC022D1E6EA38AAC49. |
| [7] |
Anderson PW (1972) More is different. Science 177: 393–396. https://doi.org/10.1126/science.177.4047.393 doi: 10.1126/science.177.4047.393
|
| [8] |
Arthur WB (2021) Foundations of Complexity. Nat Rev Phys 3: 136–145. https://doi.org/10.1038/s42254-020-00273-3 doi: 10.1038/s42254-020-00273-3
|
| [9] | Arthur WB (2013) Complexity Economics: A Different Framework for Economic Thought. Complexity Economics, Oxford University Press. https://doi.org/10.2469/dig.v43.n4.70 |
| [10] |
Arthur WB (1999) Complexity and the economy. Science 284: 107–09. https://doi.org/10.1126/science.284.5411.107 doi: 10.1126/science.284.5411.107
|
| [11] | Aven T (2017) A Conceptual Foundation for Assessing and Managing Risk, Surprises and Black Swans. In: Motet, G., Bieder, C., The Illusion of Risk Control, Springer Briefs in Applied Sciences and Technology. Springer, Cham. https://doi.org/10.1007/978-3-319-32939-0_3 |
| [12] |
Aven T (2013) On how to deal with deep uncertainties in risk assessment and management context. Risk Anal 33: 2082–2091. https://doi.org/10.1111/risa.12067 doi: 10.1111/risa.12067
|
| [13] |
Aven T, Flage R (2015) Emerging risk – Conceptual definition and a relation to black swan type of events. Reliab Eng Syst Safe 144: 61–67. https://doi.org/10.1016/j.ress.2015.07.008 doi: 10.1016/j.ress.2015.07.008
|
| [14] |
Aven T, Krohn BS (2014) A new perspective on how to understand, assess and manage risk and the unforeseen. Reliab Eng Syst Safe 121: 1–10. https://doi.org/10.1016/j.ress.2013.07.005 doi: 10.1016/j.ress.2013.07.005
|
| [15] | Babbie ER (2011) The Practice of Social Science Research. South African Ed. Cape Town. Oxford University Press. |
| [16] | Baranger M (2010) Chaos, Complexity, and Entropy. A Physics Talk for Non-Physicists. Report in New England Complex Systems Institute, Cambridge. |
| [17] | Barberis N (2017) Behavioural Finance: Asset Prices and Investor Behaviour. Available from: https://www.aeaweb.org/content/file?id=2978. |
| [18] | Basel Committee on Banking Supervision (2017) Basel Ⅲ: Finalising Post-Crisis Reforms. Available from: https://www.bis.org/bcbs/publ/d424.htm. |
| [19] | Basel Committee on Banking Supervision (2013) Fundamental Review of the Trading Book: A Revised Market Risk Framework. Available from: https://www.bis.org/publ/bcbs265.pdf. |
| [20] | Basel Committee on Banking Supervision (2006) Basel Ⅱ International Convergence of Capital Measurement and Capital Standards: A Revised Framework-Comprehensive Version. Available from: https://www.bis.org/publ/bcbs128.pdf. |
| [21] | Basel Committee on Banking Supervision (1996) Amendment to the Capital Accord to Incorporate Market Risks. Available from: https://www.bis.org/publ/bcbs24.pdf. |
| [22] | Basel Committee on Banking Supervision (BCBS) (1988) International Convergence of Capital Measurement and Capital Standards. Available from: https://www.bis.org/publ/bcbs107.pdf. |
| [23] |
Battiston S, Caldarelli G, May R, et al. (2016a) The Price of Complexity in Financial Networks. P Natl A Sci 113: 10031–10036. https://doi.org/10.1073/pnas.1521573113. doi: 10.1073/pnas.1521573113
|
| [24] |
Battiston S, Farmer JD, Flache A, et al. (2016b) Complexity theory and financial regulation: Economic policy needs interdisciplinary network analysis and behavioural modelling. Science 351: 818–819. https://doi.org/10.1126/science.aad0299 doi: 10.1126/science.aad0299
|
| [25] |
Bayes T, Price R (1763) An Essay towards Solving a Problem in the Doctrine of Chances. Philos T R Soc London 53: 370–418. https://doi.org/10.1098/rstl.1763.0053 doi: 10.1098/rstl.1763.0053
|
| [26] | Beck U (1992) Risk society: towards a new modernity. Sage London. |
| [27] | Beissner P, Riedel F (2016) Knight-Walras Equilibria. Centre for Mathematical Economics Working Paper 558. |
| [28] |
Bharathy GK, McShane MK (2014) Applying a Systems Model to Enterprise Risk Management. Eng Manag J 26: 38–46. https://doi.org/10.1080/10429247.2014.11432027 doi: 10.1080/10429247.2014.11432027
|
| [29] | Black F, Scholes M (1973) The Pricing of Options and Corporate Liabilities. J Polit Econ 29: 449–470. |
| [30] | Blume L, Durlauf (2006) The Economy as an Evolving Complex System Ⅲ: current perspectives and future directios. https://doi.org/10.1093/acprof:oso/9780195162592.001.0001 |
| [31] | Bolton P, Despres M, Pereira da Silva L, et al. (2020) The green swan: central banking and financial stability in the age of climate change. Available from: https://www.bis.org/publ/othp31.pdf. |
| [32] |
Bonabeau E (2002) Agent-Based Modeling: Methods and Techniques for Simulating Human Systems. Natl Acad Sci 99: 7280–7287. https://doi.org/10.1073/pnas.082080899 doi: 10.1073/pnas.082080899
|
| [33] | Brace I (2008) Questionnaire Design: How to Plan, Structure, and Write Survey Material for Effective Market Research, 2 Eds., London: Kogan Page. https://doi.org/10.5860/choice.42-3520 |
| [34] | Bronk R (2011) Uncertainty, modeling monocultures and the financial crisis. Bus Econ 42: 5–18. |
| [35] | Bruno B, Faggini M, Parziale A (2016) Complexity Modeling in Economics: the state of the Art. Econ Thought 5: 29–43. |
| [36] |
Burzoni M, Riedel F, Soner MH (2021) Viability and arbitrage under Knightian uncertainty. Econometrica 89: 1207–1234. https://doi.org/10.3982/ECTA16535 doi: 10.3982/ECTA16535
|
| [37] | Chan-Lau JA (2017) An Agent Based Model of the Banking System. IMF Working Paper. https://doi.org/10.5089/9781484300688.001 |
| [38] | Chaudhuri A, Ghosh SK (2016) Quantitative Modeling of Operational Risk in Finance and Banking Using Possibility Theory, Springer International Publishing Switzerland. https://doi.org/10.1007/978-3-319-26039-6 |
| [39] | Collis J, Hussey R (2009) Business Research: a practical guide for undergraduate and postgraduate students, 3rd ed., New York: Palgrave Macmillan. |
| [40] | Corrigan J, Luraschi P, Cantle N (2013) Operational Risk Modeling Framework. Milliman Research Report. Available from: https://web.actuaries.ie/sites/default/files/erm-resources/operational_risk_modelling_framework.pdf. |
| [41] |
De Bondt W, Thaler R (1985) Does the stock market overact? J Financ 40: 793–808. https://doi.org/10.2307/2327804 doi: 10.2307/2327804
|
| [42] | Diebold FX, Doherty NA, Herring RJ (2010) The Known, Unknown, and the Unknowable. Princeton, NJ: Princeton University Press. |
| [43] |
Dorigo M (2007) Editorial. Swarm Intell 1: 1–2. https://doi.org/10.1007/s11721-007-0003-z doi: 10.1007/s11721-007-0003-z
|
| [44] |
Dorigo M, Maniezzo V, Colorni A (1996) Ant system: optimisation by a colony cooperating agents. IEEE T Syst Man Cy B 26: 29–41. https://doi.org/10.1109/3477.484436 doi: 10.1109/3477.484436
|
| [45] |
Dowd K (1996) The case for financial Laissez-faire. Econ J 106: 679–687. https://doi.org/10.2307/2235576 doi: 10.2307/2235576
|
| [46] | Dowd K, Hutchinson M (2014) How should financial markets be regulated? Cato J 34: 353–388. |
| [47] | Dowd K, Hutchinson M, Ashby S, et al. (2011) Capital Inadequacies the Dismal Failure of the Basel Regime of Bank Capital Regulation. Banking & Insurance Journal. |
| [48] | Easterby-Smith M, Thorpe R, Jackson PR (2015) Management and Business Research, 5 Eds., London: Sage. |
| [49] |
Ellinas C, Allan N, Combe C (2018) Evaluating the role of risk networks on risk identification, classification, and emergence. J Network Theory Financ 3: 1–24. https://doi.org/10.21314/JNTF.2017.032 doi: 10.21314/JNTF.2017.032
|
| [50] |
Ellsberg D (1961) Risk, ambiguity, and the savage axioms. Q J Econ 75: 643–669. https://doi.org/10.2307/1884324 doi: 10.2307/1884324
|
| [51] |
Evans JR, Allan N, Cantle N (2017) A New Insight into the World Economic Forum Global Risks. Econ Pap 36. https://doi.org/10.1111/1759-3441.12172 doi: 10.1111/1759-3441.12172
|
| [52] |
Fadina T, Schmidt T (2019) Default Ambiguity. Risks 7: 64. https://doi.org/10.3390/risks7020064 doi: 10.3390/risks7020064
|
| [53] |
Fama EF (1970) Efficient Capital Markets: A review of Theory and Empirical Work. J Financ 25: 383–417. https://doi.org/10.2307/2325486 doi: 10.2307/2325486
|
| [54] | Farmer JD (2012) Economics needs to treat the economy as a complex system. Institute for New Economic Thinking at Oxford Martin School. Working Paper. |
| [55] |
Farmer D (2002) Market force, ecology, and evolution. Ind Corp Change 11: 895–953. https://doi.org/10.1093/icc/11.5.895 doi: 10.1093/icc/11.5.895
|
| [56] |
Farmer D, Lo A (1999) Fronties of finance: Evolution and efficient markets. Pro Nat Acad Sci 96: 9991–9992. https://doi.org/10.1073/pnas.96.18.99 doi: 10.1073/pnas.96.18.99
|
| [57] | Farmer JD, Gallegati C, Hommes C, et al. (2012) A complex systems approach to constructing better models for financial markets and the economy. Eur Phys J-Spec Top 214: 295–324. https://link.springer.com/article/10.1140/epjst/e2012-01696-9 |
| [58] | Farmer JD, Foley D (2009) The economy needs agent-based modeling. Nature 460: 685–686. https://www.nature.com/articles/460685a |
| [59] | Fellegi IP (2010) Survey Methods and Practices, Available from: https://unstats.un.org/wiki/download/attachments/101354131/12-587-x2003001-eng.pdf?api=v2. |
| [60] | Field A (2009) Discovering Statistics Using SPSS, 3 eds., London: Sage. |
| [61] | Fink A (2009) How to Conduct Surveys, 4 eds., Thousand Oaks, CA: Sage. |
| [62] | Fink A (1995) How to Measure Survey Reliability and Validity, Thousand Oaks, CA: Sage. |
| [63] | Forrester JW (1969) Urban Dynamics. Cambridge Mass M.I.T Press. |
| [64] |
Ganegoda A, Evans J (2014) A framework to manage the measurable, immeasurable and the unidentifiable financial risk. Aust J Manage 39: 5–34. https://doi.org/10.1177/0312896212461033 doi: 10.1177/0312896212461033
|
| [65] |
Gao Q, Fan H, Shen J (2018) The Stability of Banking System Based on Network Structure: An Overview. J Math Financ 8: 517–526. 10.4236/jmf.2018.83032 doi: 10.4236/jmf.2018.83032
|
| [66] |
Gebizlioglu OL, Dhaene J (2009) Risk Measures and Solvency-Special Issue. J Comput Appl Math 233: 1–2. https://doi.org/10.1016/j.cam.2009.07.030 doi: 10.1016/j.cam.2009.07.030
|
| [67] | Gigerenzer G (2007) Gut feelings: The Intelligence of the unconscious. New York: Viking Press. |
| [68] | Gigerenzer G, Hertwig R, Pachur T (Eds) (2011) Heuristics: The foundations of adaptive behaviour, New York: Oxford University Press. |
| [69] |
Glasserman P, Young HP (2015) How likely is contagion in financial networks? J Bank Financ 50: 383–399. https://doi.org/10.1016/j.jbankfin.2014.02.006 doi: 10.1016/j.jbankfin.2014.02.006
|
| [70] | Gros S (2011) Complex systems and risk management. IEEE Eng Manag Rev 39: 61–72. |
| [71] | Hair J, Black W, Babin B, et al (2014) Multivariate Data Analysis, 7 eds., Pearson Prentice Hall, Auflage. |
| [72] | Haldane AG (2017) Rethinking Financial Stability. Available from: https://www.bis.org/review/r171013f.pdf. |
| [73] | Haldane AG (2016) The dappled world. Available from: https://www.bankofengland.co.uk/-/media/boe/files/speech/2016/the-dappled-world.pdf. |
| [74] | Haldane AG (2012) The Dog and the Frisbee. Available from: https://www.bis.org/review/r120905a.pdf. |
| [75] | Haldane AG (2009) Rethinking the financial network. Available from: https://www.bis.org/review/r090505e.pdf. |
| [76] | Haldane AG, May RM (2011) Systemic risk in banking ecosystems. Available from: https://www.nature.com/articles/nature09659. |
| [77] | Hayek FA (1964) The theory of complex phenomena. The critical approach to science and philosophy, 332–349. https://doi.org/10.4324/9781351313087-22 |
| [78] |
Helbing D (2013) Globally network risks and how to respond. Nature 497: 51–59. https://doi.org/10.1038/nature12047 doi: 10.1038/nature12047
|
| [79] | Holland JH (2002) Complex adaptive systems and spontaneous emergence. In Curzio, A.Q., Fortis, M., Complexity and Industrial Clusters: Dynamics and Models in Theory and Practice, New York: Physica-Verlag, 25–34. https://doi.org/10.1007/978-3-642-50007-7_3 |
| [80] |
Hommes C (2011) The heterogeneous expectations hypothesis: Some evidence from the lab. J Econ Dyn Control 35: 1–24. https://doi.org/10.1016/j.jedc.2010.10.003 doi: 10.1016/j.jedc.2010.10.003
|
| [81] |
Hommes C (2001) Financial markets as nonlinear adaptive evolutionary systems. Quant Financ 1: 149–167. https://doi.org/10.1080/713665542 doi: 10.1080/713665542
|
| [82] | Hull J (2018) Risk Management and Financial Institutions, 5 eds., John Wiley. |
| [83] | Ingram D, Thompson M (2011) Changing seasons of risk attitudes. Actuary 8: 20–24. |
| [84] | Joshi D (2014) Fractals, liquidity, and a trading model. European Investment Strategy, BCA Research. |
| [85] |
Karp A, van Vuuren G (2019) Investment's implications of the Fractal Market Hypothesis. Ann Financ Econ 14: 1–27. https://doi.org/10.1142/S2010495219500015 doi: 10.1142/S2010495219500015
|
| [86] |
Katsikopoulos KV (2011) Psychological Heuristics for Making Inferences: Definition, Performance, and the Emerging Theory and Practice. Decis Anal 8: 10–29. https://doi.org/10.1287/deca.1100.0191 doi: 10.1287/deca.1100.0191
|
| [87] | Keynes JM (1921) A Treatise on Probability, London: Macmillan. |
| [88] |
Kimberlin CL, Winterstein AG (2008) Validity and Reliability of Measurement Instruments in Research. Am J Health Syst Pharma 65: 2276–2284. https://doi.org/10.2146/ajhp070364. doi: 10.2146/ajhp070364
|
| [89] |
Kirman A (2006) Heterogeneity in economics. J Econ Interact Co-ordination 1: 89–117. https://doi.org/10.1007/s11403-006-0005-8 doi: 10.1007/s11403-006-0005-8
|
| [90] | Kirman A (2017) The Economy as a Complex System. In: Aruka, Y., Kirman, A., Economic Foundations for Social Complexity Science. Evolutionary Economics and Social Complexity Science, Singapore. https://doi.org/10.1007/978-981-10-5705-2_1 |
| [91] |
Klioutchnikova I, Sigovaa M, Beizerova N (2017) Chaos Theory in Finance. Procedia Comput Sci 119: 368–375. https://doi.org/10.1016/j.procs.2017.11.196 doi: 10.1016/j.procs.2017.11.196
|
| [92] | Knight FH (1921) Risk, Uncertainty and Profit, Boston and New York: Houghton Mifflin Company. |
| [93] | Krejcie RV, Morgan DW (1970) Determining the sample size for research activities. Educ Psychol Meas 30: 607–610. |
| [94] | Kremer E (2012) Modeling and Simulation of Electrical Energy Systems though a Complex Systems Approach using Agent Based Models, Kit Scientific Publishing. |
| [95] |
Kurtz CF, Snowden DJ (2003) The new dynamics of strategy: Sense-making in a complex and complicated world. IBM Syst J 42: 462–483. https://doi.org/10.1147/sj.423.0462 doi: 10.1147/sj.423.0462
|
| [96] | Li Y (2017) A non-linear analysis of operational risk and operational risk management in banking industry, PhD Thesis, School of Accounting, Economics and Finance, University of Wollongong. Australia. |
| [97] |
Li Y, Allan N, Evans J (2018) An analysis of the feasibility of an extreme operational risk pool for banks. Ann Actuar Sci 13: 295–307. https://doi.org/10.1017/S1748499518000222 doi: 10.1017/S1748499518000222
|
| [98] |
Li Y, Allan N, Evans J (2017) An analysis of operational risk events in US and European banks 2008–2014. Ann Actuar Sci 11: 315–342. https://doi.org/10.1017/S1748499517000021 doi: 10.1017/S1748499517000021
|
| [99] |
Li Y, Allan N, Evans J (2017) A nonlinear analysis of operational risk events in Australian banks. J Oper Risk 12: 1–22. https://doi.org/10.21314/JOP.2017.185 doi: 10.21314/JOP.2017.185
|
| [100] |
Li Y, Evans J (2019) Analysis of financial events under an assumption of complexity. Ann Actuar Sci 13: 360–377. https://doi.org/10.1017/S1748499518000337 doi: 10.1017/S1748499518000337
|
| [101] |
Li Y, Shi L, Allan N, et al. (2019) An Analysis of power law distributions and tipping points during the global financial crisis. Ann Actuar Sci 13: 80–91. https://doi.org/10.1017/S1748499518000088 doi: 10.1017/S1748499518000088
|
| [102] | Liu G, Song G (2012) EMH and FMH: Origin, evolution, and tendency. 2012 Fifth International Workshop on Chaos-fractals Theories and Applications. https://doi.org/10.1109/IWCFTA.2012.71 |
| [103] |
Lo A (2004) The adaptive markets hypothesis: Market efficiency from an evolutionary perspective. J Portfolio Manage 30: 15–29. https://doi.org/10.3905/jpm.2004.442611 doi: 10.3905/jpm.2004.442611
|
| [104] |
Lo A (2012) Adaptive markets and the new world order. Financ Anal J 68: 18–29. https://doi.org/10.2469/faj.v68.n2.6 doi: 10.2469/faj.v68.n2.6
|
| [105] | Macal CM, North MJ, Samuelson MJ (2013) Agent-Based Simulation. In: Gass, S.I., Fu M.C., Encyclopaedia of Operations Research and Management Science, Springer, Boston MA. |
| [106] | Mandelbrot B (1963) The Variation of Certain Speculative Prices. J Bus 36: 394–419. http://www.jstor.org/stable/2350970 |
| [107] | Mandelbrot B, Hudson RL (2004) The (Mis) behaviour of Markets: A Fractal View of Risk, Ruin, and Reward, Basic Books: Cambridge. |
| [108] | Mandelbrot B, Taleb N (2007) Mild vs. wild randomness: Focusing on risks that matter. In: Diebold, F.X., Doherty, N.A., Herring, R.J., The Known, the Unknown, and the Unknowable in Financial Risk Management: Measurement and Theory Advancing Practice, Princeton, NJ: Princeton University Press, 47–58. |
| [109] |
Markowitz HM (1952) Portfolio Selection. J Financ 7: 77–91. https://doi.org/10.1111/j.1540-6261.1952.tb01525.x doi: 10.1111/j.1540-6261.1952.tb01525.x
|
| [110] | Martens D, Van Gestel T, De Backer M, et al. (2010) Credit rating prediction using Ant Colony Optimisation. J Oper Res Soc 61: 561–573. |
| [111] |
Mazri C (2017) (Re)Defining Emerging Risk. Risk Anal 37: 2053–2065. https://doi.org/10.1111/risa.12759 doi: 10.1111/risa.12759
|
| [112] | McNeil AJ, Frey R, Embrechts P (2015) Quantitative Risk Management (2nd ed): Concepts, Techniques and Tools, Princeton University Press. Princeton. |
| [113] |
Merton RC (1974) On the pricing of corporate debt: the risk structure of interest rate. J Financ 29: 637–654. https://doi.org/10.1111/j.1540-6261.1974.tb03058.x doi: 10.1111/j.1540-6261.1974.tb03058.x
|
| [114] | Mikes A (2005) Enterprise Risk Management in Action. Available from: https://etheses.lse.ac.uk/2924/. |
| [115] |
Mitchell M (2006) Complex systems: Network thinking. Artif Intell 170: 1194–1212. https://doi.org/10.1016/j.artint.2006.10.002 doi: 10.1016/j.artint.2006.10.002
|
| [116] | Mitchell M (2009) Complexity: A Guided Tour. Oxford University Press. |
| [117] | Mitleton-Kelly E (2003) Complex systems and evolutionary perspectives on organisations: the application of complexity theory to organisations. Oxford: Pergamon. |
| [118] | Mohajan H (2017) Two Criteria for Good Measurements in Research: Validity and Reliability. Annals of Spiru Haret University 17: 58–82. |
| [119] | Mohajan HK (2018) Qualitative Research Methodology in Social Sciences and Related Subjects. J Econ Dev Environ Peopl 7: 23–48. |
| [120] | Morin E (2014) Complex Thinking for a Complex World-About Reductionism, Disjunction and Systemism. Systema 2: 14–22. |
| [121] |
Morin E (1992) From the concept of system to the paradigm of complexity. J Soc Evol Sys 15: 371–385. https://doi.org/10.1016/1061-7361(92)90024-8 doi: 10.1016/1061-7361(92)90024-8
|
| [122] | Motet G, Bieder C (2017) The Illusion of Risk Control, Springer Briefs in Applied Sciences and Technology. Springer, Cham. |
| [123] |
Mousavi S, Gigerenzer G (2014) Risk, Uncertainty and Heuristics. J Bus Res 67: 1671–1678. https://doi.org/10.1016/j.jbusres.2014.02.013 doi: 10.1016/j.jbusres.2014.02.013
|
| [124] | Muth JF (1961) Rational Expectations and the Theory of Price Movements. Econometrica 29: 315–35. |
| [125] |
Newman MJ (2011) Complex systems: A survey. Am J Phy 79: 800–810. https://doi.org/10.1119/1.3590372 doi: 10.1119/1.3590372
|
| [126] | Pagel M, Atkinson Q, Meade A (2007) Frequency of word-use predicts rates of lexical evolution throughout Indo-European history. Nature 449: 717–720. |
| [127] | Pallant J (2010) SPSS Survival Manual: A Step-by-Step Guide to Data Analysis using SPSS for Windows, Maidenhead: Open University Press. |
| [128] | Peters E (1991) Fractal Market Analysis: Applying Chaos Theory to Investment and Economics. London: Wiley Finance. John Wiley Science. |
| [129] | Peters E (1994) Fractal Market Analysis: Applying Chaos Theory to Investment and Economics. New York: John Wiley & Sons. |
| [130] |
Pichler A (2017) A quantitative comparison of risk measures. Ann Oper Res 254: 1–2. https://doi.org/10.1007/s10479-017-2397-3 doi: 10.1007/s10479-017-2397-3
|
| [131] | Plosser M, Santos J (2018) The Cost of Bank Regulatory Capital. Mimeo, Federal Reserve Bank of New York. Staff Report Number 853. |
| [132] |
Ponto J 2015) Understanding and Evaluatin Survey Research. J Adv Pract Oncol 6: 66–171. https://doi.org/10.6004/jadpro.2015.6.2.9 doi: 10.6004/jadpro.2015.6.2.9
|
| [133] | Quinlan C (2011) Business Research Methods. South Westen Cengage Learning. |
| [134] | Ramsey FP (1926) Truth and Probability. In Ramsey 1931, The Foundations of Mathematics and Other Logical Essays, Chapter Ⅶ, 156–198, edited by R.B. Braithwaite, London: Kegan, Paul, Trench, Trubner and Co., New York: Harcourt, Brace and Company. |
| [135] |
Righi BM, Muller FM, da Silveira VG, et al. (2019) The effect of organisational studies on financial risk measures estimation. Rev Bus Manage 21: 103–117. https://doi.org/10.7819/rbgn.v0i0.3953 doi: 10.7819/rbgn.v0i0.3953
|
| [136] |
Ross SA (1976) The arbitrage theory of capital asset pricing. J Econ Theory 13: 341–360. https://doi.org/10.1016/0022-0531(76)90046-6 doi: 10.1016/0022-0531(76)90046-6
|
| [137] | Saunders M, Lewis P, Thornhill A (2019) Research Methods for Business Students, New York Pearson Publishers. |
| [138] | Saunders M, Lewis P, Thornhill A (2012) Research Methods, Pearson Publishers. |
| [139] | Savage LJ (1954) The Foundations of Statistics. New York: John Wiley and Sons. |
| [140] | Sekaran U (2003) Research Methods for Business (4th ed.), Hoboken, NJ: John Wiley &Sons. Shane, S. and Cable. |
| [141] | Senge P (1990) The Fifth Discipline- The Art and Practice of the Learning Organisation. New York, Currency Doubleday. |
| [142] | Shackle GLS (1949) Expectations in Economics. Cambridge: Cambridge University Press. |
| [143] |
Shackle GLS (1949) Probability and uncertainty. Metroeconomica 1: 161–173. https://doi.org/10.1111/j.1467-999X.1949.tb00040.x doi: 10.1111/j.1467-999X.1949.tb00040.x
|
| [144] |
Sharpe WF (1964) Capital Asset Prices: A Theory of Market Equilibrium under Conditions of Risk. J Financ 19: 425–442. https://doi.org/10.1111/j.1540-6261.1964.tb02865.x doi: 10.1111/j.1540-6261.1964.tb02865.x
|
| [145] |
Shefrin H (2010) Behaviouralising Finance. Found Trends Financ 4: 1–184. http://dx.doi.org/10.1561/0500000030 doi: 10.1561/0500000030
|
| [146] |
Shefrin H, Statman M (1985) The disposition to sell winners to early and ride loses too long: Theory and evidence. J Financ 40: 777–790. https://doi.org/10.2307/2327802 doi: 10.2307/2327802
|
| [147] | Snowden D, Boone M (2007) A leader's framework for decision making. Harvard Bus Rev 85: 68–76. |
| [148] | Soramaki K, Cook S (2018) Network Theory and Financial Risk, Riskbooks. |
| [149] | Sornette D (2003) Why Stock Markets Crash: Critical Events in Complex Financial Systems, Princeton University Press. |
| [150] |
Sornette D, Ouillon G (2012) Dragon-kings: mechanisms, statistical methods, and empirical evidence. Eur Phys J Spec Topics 205: 1–26. https://doi.org/10.1140/epjst/e2012-01559-5 doi: 10.1140/epjst/e2012-01559-5
|
| [151] | Sweeting P (2011) Financial Enterprise Risk Management. Cambridge University Press. |
| [152] | Tepetepe G, Simenti-Phiri E, Morton D (2021) Survey on Complexity Science Adoption in Emerging Risks Management of Zimbabwean Banks. J Global Bus Technol 17: 41–60 |
| [153] | Thaler RH (2015) Misbehaving: The Making of Behavioural Economics. New York: W. W. Norton and Company. |
| [154] | Thompson M (2018) How banks and other financial institutions. Brit Actuar J 23: 1–16. |
| [155] | Tukey JW (1977) Exploratory Data Analysis, MA: Addison-Wesley. |
| [156] |
Turner RJ, Baker MR (2019) Complexity Theory: An Overview with Potential Applications for the Social Sciences. Sys Rev 7: 1–22. https://doi.org/10.3390/systems7010004 doi: 10.3390/systems7010004
|
| [157] | Virigineni M, Rao MB (2017) Contemporary Developments in Behavioural Finance. Int J Econ Financ Issues 7: 448–459. |
| [158] | Yamane T (1967) Statistics: An Introductory Analysis (2nd ed), New York: Harper and Row. |
| [159] |
Zadeh LA (1965) Fuzzy sets. Inf Control 8: 335–338. http://dx.doi.org/10.1016/S0019-9958(65)90241-X doi: 10.1016/S0019-9958(65)90241-X
|
| [160] |
Zadeh LA (1978) Fuzzy sets as basis for a theory of possibility. Fuzzy Set Syst 1: 3–28. https://doi.org/10.1016/0165-0114(78)90029-5 doi: 10.1016/0165-0114(78)90029-5
|
| [161] | Zikmund W (2003) Business Research Methods, 7th Ed, Mason, OH. and Great Britain, Thomson/South-Western. |
| [162] | Zimbabwe (2011) Technical Guidance on the Implementation of the Revised Adequacy Framework in Zimbabwe. Reserve Bank of Zimbabwe. |
| [163] | Zimmerman B (1999) Complexity science: A route through hard times and uncertainty. Health Forum J 42: 42–46. |
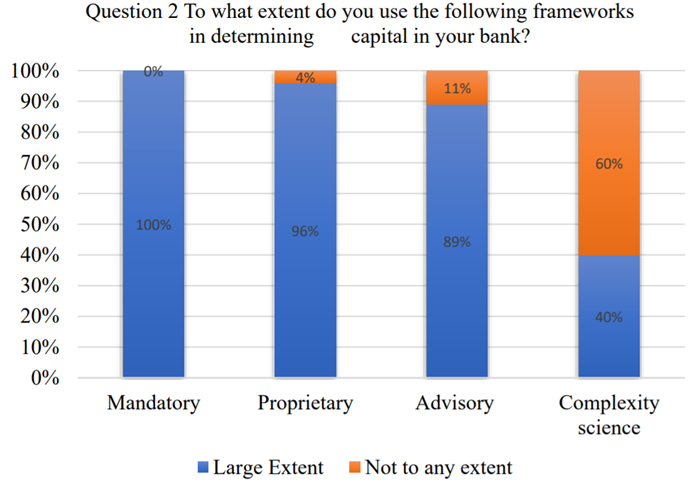
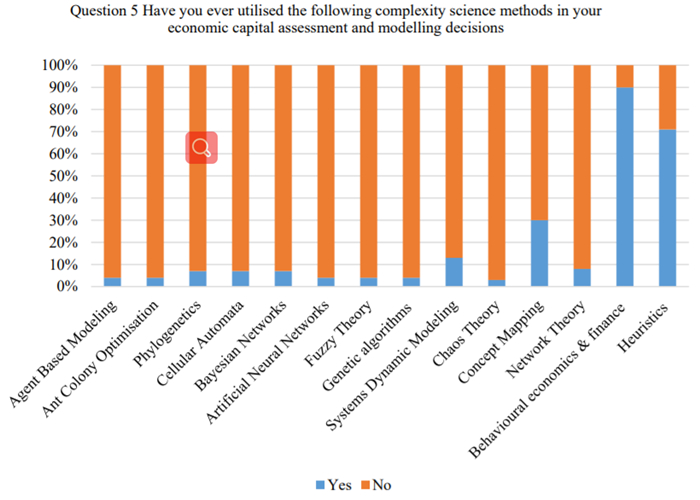
Figures(2) / Tables(4)

Gilbert Tepetepe, Easton Simenti-Phiri, Danny Morton. A survey comparative analysis of cartesian and complexity science frameworks adoption in financial risk management of Zimbabwean banks[J]. Quantitative Finance and Economics, 2022, 6(2): 359-384. doi: 10.3934/QFE.2022016







 DownLoad:
DownLoad: