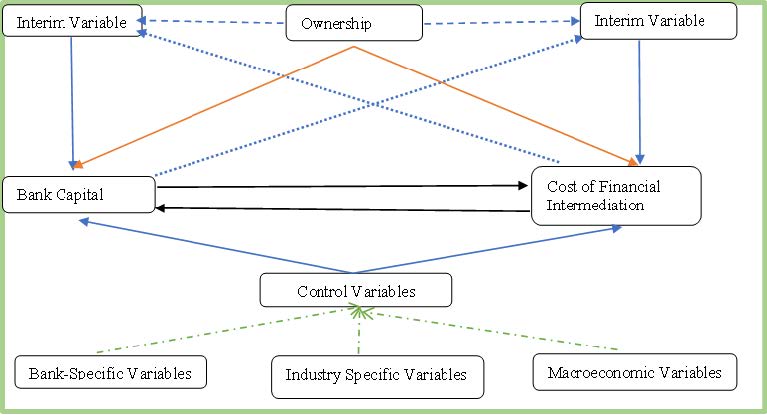
This study investigated the simultaneous association between capital and the cost of financial intermediation (COFI) by bridging the gap of ownership effects on the nexus between capital and COFI. This study revealed several significant insights by using data from 44 commercial banks in Bangladesh between 2010 and 2021 and applying two-step system generalized methods of moments (2SGMM). First, a significant nonlinear bidirectional relationship exists between bank capital and COFI. The tendency to generate average and low COFI enables banks to acquire more capital than those with high COFI. In contrast, banks with high and average capital bases can maximize their COFI compared to low ones. Second, state-owned and conventional commercial banks are better positioned to source more capital. However, state-owned and Islamic commercial banks can strengthen the inverted U-shaped relationship between COFI and bank capital than private-owned and Islamic commercial banks. Finally, state-owned commercial banks do not experience the same benefits in COFI from capital increases as privately owned banks. Unlike Islamic commercial banks, conventional banks generate more COFI in the long run as capital rises. The findings provide helpful insights into shaping policy and regulations regarding emerging country's banking systems, especially capital, COFI, and ownership policies.
Citation: Changjun Zheng, Md Mohiuddin Chowdhury, Anupam Das Gupta. Investigating the influence of ownership on the relationship between bank capital and the cost of financial intermediation[J]. Data Science in Finance and Economics, 2024, 4(3): 388-421. doi: 10.3934/DSFE.2024017
This study investigated the simultaneous association between capital and the cost of financial intermediation (COFI) by bridging the gap of ownership effects on the nexus between capital and COFI. This study revealed several significant insights by using data from 44 commercial banks in Bangladesh between 2010 and 2021 and applying two-step system generalized methods of moments (2SGMM). First, a significant nonlinear bidirectional relationship exists between bank capital and COFI. The tendency to generate average and low COFI enables banks to acquire more capital than those with high COFI. In contrast, banks with high and average capital bases can maximize their COFI compared to low ones. Second, state-owned and conventional commercial banks are better positioned to source more capital. However, state-owned and Islamic commercial banks can strengthen the inverted U-shaped relationship between COFI and bank capital than private-owned and Islamic commercial banks. Finally, state-owned commercial banks do not experience the same benefits in COFI from capital increases as privately owned banks. Unlike Islamic commercial banks, conventional banks generate more COFI in the long run as capital rises. The findings provide helpful insights into shaping policy and regulations regarding emerging country's banking systems, especially capital, COFI, and ownership policies.

| [1] |
Abbas F, Ali S, Ahmad M (2023) Does economic growth affect the relationship between banks' capital, liquidity and profitability: empirical evidence from emerging economies. J Econ Admin Sci 39: 366–381. https://doi.org/10.1108/JEAS-03-2021-0056 doi: 10.1108/JEAS-03-2021-0056

|
| [2] |
Agoraki MEK, Kouretas GP (2019) The determinants of net interest margin during transition. Rev Quant Financ Account 53: 1005–1029. https://doi.org/10.1007/s11156-018-0773-y doi: 10.1007/s11156-018-0773-y
|
| [3] |
Ahmad R, Albaity M (2019) The determinants of bank capital for East Asian countries. Glob Bus Rev 20: 1311–1323. https://doi.org/10.1177/0972150919848915 doi: 10.1177/0972150919848915
|
| [4] |
Ahmad R, Ariff M, Skully MJ (2009) The Determinants of Bank Capital Ratios in a Developing Economy. Asia Pac Financ Mark 15: 255–272. https://doi.org/10.1007/s10690-009-9081-9 doi: 10.1007/s10690-009-9081-9
|
| [5] |
Aktas R, Acikalin S, Bakin B, et al. (2015) The determinants of banks' capital adequacy ratio: Some evidence from South Eastern European countries. J Econ Behav Stud 7: 79–88. https://doi.org/10.22610/jebs.v7i1(J).565 doi: 10.22610/jebs.v7i1(J).565
|
| [6] |
Al-Harbi A (2019) The determinants of conventional banks profitability in developing and underdeveloped OIC countries. J Econ Financ Adm Sci 24: 4–28. https://doi.org/10.1108/JEFAS-05-2018-0043 doi: 10.1108/JEFAS-05-2018-0043
|
| [7] | Al-Hares OM, AbuGhazaleh NM, El-Galfy AM (2013) Financial performance and compliance with Basel Ⅲ capital standards: Conventional vs. Islamic banks. J Appl Bus Res 29: 1031–1048. |
| [8] |
Al-Nasser Mohammed SAS, Muhammed J (2017) The relationship between agency theory, stakeholder theory and Shariah supervisory board in Islamic banking: An attempt towards discussion. Humanomics 33: 75–83. https://doi.org/10.1108/H-08-2016-0062 doi: 10.1108/H-08-2016-0062
|
| [9] |
Allen L (1988) The Determinants of Bank Interest Margins: A Note. J Financ Quant Anal 23: 231–235. https://doi.org/10.2307/2330883 doi: 10.2307/2330883
|
| [10] |
Alqahtani F, Mayes DG, Brown K (2016) Economic turmoil and Islamic banking: Evidence from the Gulf Cooperation Council. Pac-Basin Financ J 39: 44–56. https://doi.org/10.1016/j.pacfin.2016.05.017 doi: 10.1016/j.pacfin.2016.05.017
|
| [11] |
Alshammari T (2022) State ownership and bank performance: conventional vs Islamic banks. J Islamic Account Bus Res 13: 141–156. https://doi.org/10.1108/JIABR-06-2021-0161 doi: 10.1108/JIABR-06-2021-0161
|
| [12] |
Alves CF, Citterio A, Marques BP (2023) Bank-specific capital requirements: Short and long-run determinants. Financ Res Lette 52: 103558. https://doi.org/10.1016/j.frl.2022.103558 doi: 10.1016/j.frl.2022.103558
|
| [13] |
Alvi MA, Akhtar K, Rafique A (2021) Does efficiency play a transmission role in the relationship between competition and stability in the banking industry? New evidence from South Asian economies. J Public Aff 21. https://doi.org/10.1002/pa.2678 doi: 10.1002/pa.2678
|
| [14] |
Angbazo L (1997) Commercial bank net interest margins, default risk, interest-rate risk, and off-balance sheet banking. J Bank Financ 21: 55–87. https://doi.org/10.1016/S0378-4266(96)00025-8 doi: 10.1016/S0378-4266(96)00025-8
|
| [15] |
Archarya VV, Mehran H, Schuermann T, et al. (2012) Robust capital regulation. Curr Issues Econ Financ 18: 1–11. https://doi.org/10.2139/ssrn.2070102 doi: 10.2139/ssrn.2070102
|
| [16] |
Arellano M, Bover O (1995) Another look at the instrumental variable estimation of error-components models. J Econometrics 68: 29–51. https://doi.org/10.1016/0304-4076(94)01642-D doi: 10.1016/0304-4076(94)01642-D
|
| [17] |
Balla E, Rose MJ (2019) Earnings, risk-taking, and capital accumulation in small and large community banks. J Bank Financ 103: 36–50. https://doi.org/10.1016/j.jbankfin.2019.03.005 doi: 10.1016/j.jbankfin.2019.03.005
|
| [18] | Bangladesh Bank (2022) Annual Report. Available from: https://www.bb.org.bd/pub/annual/anreport/ar2122.pdf. |
| [19] |
Barajas A, Steiner R, Salazar N (2000) The impact of liberalization and foreign investment in Colombia's financial sector. J Dev Econ 63: 157–196. https://doi.org/10.1016/S0304-3878(00)00104-8 doi: 10.1016/S0304-3878(00)00104-8
|
| [20] |
Barra C, Ruggiero N (2021) Do microeconomic and macroeconomic factors influence Italian bank credit risk in different local markets? Evidence from cooperative and non-cooperative banks. J Econ Bus 114: 105976. https://doi.org/10.1016/j.jeconbus.2020.105976 doi: 10.1016/j.jeconbus.2020.105976
|
| [21] | Basel Committee on Banking Supervision (2009) Strengthening the resilience of the banking sector. B. f. I. Settlements. Available from: https://www.bis.org/publ/bcbs164.pdf. |
| [22] | Basel Committee on Banking Supervision (2010) An assessment of the long-term economic impact of stronger capital and liquidity requirements. B. f. I. Settlements. Available from: https://www.bis.org/publ/bcbs173.pdf. |
| [23] |
Ben Naceur S, Kandil M (2009) The impact of capital requirements on banks' cost of intermediation and performance: The case of Egypt. J Econ Bus 61: 70–89. https://doi.org/10.1016/j.jeconbus.2007.12.001 doi: 10.1016/j.jeconbus.2007.12.001
|
| [24] |
Berger AN, Bonaccorsi di Patti E (2006) Capital structure and firm performance: A new approach to testing agency theory and an application to the banking industry. J Bank Financ 30: 1065–1102. https://doi.org/10.1016/j.jbankfin.2005.05.015 doi: 10.1016/j.jbankfin.2005.05.015
|
| [25] |
Berger AN, Demirgüç-Kunt A, Moshirian F, et al. (2021) The way forward for banks during the COVID-19 crisis and beyond: Government and central bank responses, threats to the global banking industry. J Bank Financ 133: 106303. https://doi.org/10.1016/j.jbankfin.2021.106303 doi: 10.1016/j.jbankfin.2021.106303
|
| [26] |
Berger AN, Herring RJ, Szegö GP (1995) The role of capital in financial institutions. J Bank Financ 19: 393–430. https://doi.org/10.1016/0378-4266(95)00002-X doi: 10.1016/0378-4266(95)00002-X
|
| [27] |
Berger AN, Klapper LF, Turk-Ariss R (2009) Bank Competition and Financial Stability. J Financ Serv Res 35: 99–118. https://doi.org/10.1007/s10693-008-0050-7 doi: 10.1007/s10693-008-0050-7
|
| [28] |
Berger AN, Öztekin Ö, Roman RA (2023) Geographic deregulation and bank capital structure. J Bank Financ 149: 106761. https://doi.org/10.1016/j.jbankfin.2023.106761 doi: 10.1016/j.jbankfin.2023.106761
|
| [29] | Berle A, Means G (1932) The modern corporation and private property. Harcourt, Brace & World, Inc, New York, NY. |
| [30] |
Blundell R, Bond S (1998) Initial conditions and moment restrictions in dynamic panel data models. J Econometrics 87: 115–143. https://doi.org/10.1016/S0304-4076(98)00009-8 doi: 10.1016/S0304-4076(98)00009-8
|
| [31] | Bock RD, Demyanets A (2012) Bank Asset Quality in Emerging Markets: Determinants and Spillovers. I. M. Fund. Available from: https://www.elibrary.imf.org. |
| [32] |
Bougatef K, Mgadmi N (2016) The impact of prudential regulation on bank capital and risk-taking: The case of MENA countries. Span Rev Financ Econ 14: 51–56. https://doi.org/10.1016/j.srfe.2015.11.001 doi: 10.1016/j.srfe.2015.11.001
|
| [33] |
Carsamer E, Abbam A, Queku YN (2022) Bank capital, liquidity and risk in Ghana. J Financ Regul Compl 30: 149–166. https://doi.org/10.1108/JFRC-12-2020-0117 doi: 10.1108/JFRC-12-2020-0117
|
| [34] |
Chen YS, Chen Y, Lin CY, et al. (2016) Is there a bright side to government banks? Evidence from the global financial crisis. J Financ Stabil 26: 128–143. https://doi.org/10.1016/j.jfs.2016.08.006 doi: 10.1016/j.jfs.2016.08.006
|
| [35] |
Claeys S, Vander Vennet R (2008) Determinants of bank interest margins in Central and Eastern Europe: A comparison with the West. Econ Syst 32: 197–216. https://doi.org/10.1016/j.ecosys.2007.04.001 doi: 10.1016/j.ecosys.2007.04.001
|
| [36] |
Clarke GRG, Cull R, Shirley MM (2005) Bank privatization in developing countries: A summary of lessons and findings. J Bank Financ 29: 1905–1930. https://doi.org/10.1016/j.jbankfin.2005.03.006 doi: 10.1016/j.jbankfin.2005.03.006
|
| [37] |
Cornett MM, Guo L, Khaksari S, et al. (2010) The impact of state ownership on performance differences in privately-owned versus state-owned banks: An international comparison. J Financ Intermed 19: 74–94. https://doi.org/10.1016/j.jfi.2008.09.005 doi: 10.1016/j.jfi.2008.09.005
|
| [38] |
Cruz-García P, Fernández de Guevara J (2019) Determinants of net interest margin: the effect of capital requirements and deposit insurance scheme. Eu J Financ 26: 1102–1123. https://doi.org/10.1080/1351847X.2019.1700149 doi: 10.1080/1351847X.2019.1700149
|
| [39] |
Demirgüç-Kunt A, Huizinga H (1999) Determinants of Commercial Bank Interest Margins and Profitability: Some International Evidence. World Bank Econ Rev 13: 379–408. https://doi.org/10.1093/wber/13.2.379 doi: 10.1093/wber/13.2.379
|
| [40] |
Deng W, Wang J, Zhang R (2022) Measures of concordance and testing of independence in multivariate structure. J Multivariate Anal 191: 105035. https://doi.org/10.1016/j.jmva.2022.105035 doi: 10.1016/j.jmva.2022.105035
|
| [41] |
Dwumfour RA (2017) Explaining banking stability in Sub-Saharan Africa. Res Int Bus Financ 41: 260–279. https://doi.org/10.1016/j.ribaf.2017.04.027 doi: 10.1016/j.ribaf.2017.04.027
|
| [42] |
Entrop O, Memmel C, Ruprecht B, et al. (2015) Determinants of bank interest margins: Impact of maturity transformation. J Bank Financ 54: 1–19. https://doi.org/10.1016/j.jbankfin.2014.12.001 doi: 10.1016/j.jbankfin.2014.12.001
|
| [43] |
Fernández-Méndez C, González VM (2019) Bank ownership, lending relationships and capital structure: Evidence from Spain. BRQ Bus Res Quart 22: 137–154. https://doi.org/10.1016/j.brq.2018.05.002 doi: 10.1016/j.brq.2018.05.002
|
| [44] |
Fiordelisi F, Marques-Ibanez D, Molyneux P (2011) Efficiency and risk in European banking. J Bank Financ 35: 1315–1326. https://doi.org/10.1016/j.jbankfin.2010.10.005 doi: 10.1016/j.jbankfin.2010.10.005
|
| [45] |
Fleming G, Heaney R, McCosker R (2005) Agency costs and ownership structure in Australia. Pac-Basin Financ J 13: 29–52. https://doi.org/10.1016/j.pacfin.2004.04.001 doi: 10.1016/j.pacfin.2004.04.001
|
| [46] |
Fu XM, Lin YR, Molyneux P (2014) Bank competition and financial stability in Asia Pacific. J Bank Financ 38: 64–77. https://doi.org/10.1016/j.jbankfin.2013.09.012 doi: 10.1016/j.jbankfin.2013.09.012
|
| [47] |
Fungáčová Z, Poghosyan T (2011) Determinants of bank interest margins in Russia: Does bank ownership matter? Econ Syst 35: 481–495. https://doi.org/10.1016/j.ecosys.2010.11.007 doi: 10.1016/j.ecosys.2010.11.007
|
| [48] |
Garel A, Petit-Romec A, Vennet RV (2022) Institutional Shareholders and Bank Capital. J Financ Intermed 50: 100960. https://doi.org/10.1016/j.jfi.2022.100960 doi: 10.1016/j.jfi.2022.100960
|
| [49] |
Gertler M, Kiyotaki N, Queralto A (2012) Financial crises, bank risk exposure and government financial policy. J Monetary Econ 59: S17–S34. https://doi.org/10.1016/j.jmoneco.2012.11.007 doi: 10.1016/j.jmoneco.2012.11.007
|
| [50] |
Gharaibeh AMO (2023) The Determinants of Capital Adequacy in the Jordanian Banking Sector: An Autoregressive Distributed Lag-Bound Testing Approach. Int J Financ Stud 11: 75. https://doi.org/https://doi.org/10.3390/ijfs11020075 doi: 10.3390/ijfs11020075
|
| [51] | Gitman LJ, Zutter CJ (2015) Principles of Managerial Finance (6th ed.). Pearson Higher Education AU. |
| [52] |
Gorton G, Winton A (1998) Banking in Transition Economies: Does Efficiency Require Instability? J Money Credit Bank 30: 621–650. https://doi.org/10.2307/2601261 doi: 10.2307/2601261
|
| [53] |
Granger CW (1969) Investigating causal relations by econometric models and cross-spectral methods. Econometrica J Econometric Soc 37: 424–438. https://doi.org/10.2307/1912791 doi: 10.2307/1912791
|
| [54] |
Gupta AD, Sarker N, Rahman MR (2021) Relationship among cost of financial intermediation, risk, and efficiency: Empirical evidence from Bangladeshi commercial banks. Cogent Econ Financ 9: 1967575. https://doi.org/10.1080/23322039.2021.1967575 doi: 10.1080/23322039.2021.1967575
|
| [55] |
Gupta AD, Yesmin A (2022) Effect of Risk and Market Competition on Efficiency of Commercial Banks: Does Ownership Matter. J Bus Econ Financ 11: 22–42. https://doi.org/10.17261/Pressacademia.2022.1550 doi: 10.17261/Pressacademia.2022.1550
|
| [56] |
Gupta J, Kashiramka S, Ly KC, et al. (2023) The interrelationship between bank capital and liquidity creation: A non-linear perspective from the Asia-Pacific region. Int Rev Econ Financ 85: 793–820. https://doi.org/10.1016/j.iref.2023.02.017 doi: 10.1016/j.iref.2023.02.017
|
| [57] |
Gupta N, Mahakud J, McMillan D (2020) Ownership, bank size, capitalization and bank performance: Evidence from India. Cogent Econ Financ 8. https://doi.org/10.1080/23322039.2020.1808282 doi: 10.1080/23322039.2020.1808282
|
| [58] |
Gupta PK, Sharma S (2023) Role of corporate governance in asset quality of banks: comparison between government-owned and private banks. Manag Financ 49: 724–740. https://doi.org/10.1108/MF-04-2022-0165 doi: 10.1108/MF-04-2022-0165
|
| [59] |
Hanzlík P, Teplý P (2020) Key factors of the net interest margin of European and US banks in a low interest rate environment. Int J Financ Econ 27: 2795–2818. https://doi.org/10.1002/ijfe.2299 doi: 10.1002/ijfe.2299
|
| [60] |
Haris M, Tan Y, Malik A, et al. (2020) A study on the impact of capitalization on the profitability of banks in emerging markets: A case of Pakistan. J Risk Financ Manage 13: 217. https://doi.org/10.3390/jrfm13090217 doi: 10.3390/jrfm13090217
|
| [61] |
Ho TSY, Saunder A (1981) The determinants of bank interest margins: theory and empirical evidence. J Financ Quant Anal 16: 581–600. https://doi.org/10.2307/2330377 doi: 10.2307/2330377
|
| [62] |
Huang FW, Chen S, Tsai JY (2019) Optimal bank interest margin under capital regulation: bank as a liquidity provider. J Financ Econ Policy 11: 158–173. https://doi.org/10.1108/JFEP-12-2017-0124 doi: 10.1108/JFEP-12-2017-0124
|
| [63] |
Hussain M, Bashir U (2020) Risk-competition nexus: Evidence from Chinese banking industry. Asia Pac Manag Rev 25: 23–37. https://doi.org/10.1016/j.apmrv.2019.06.001 doi: 10.1016/j.apmrv.2019.06.001
|
| [64] |
Iannotta G, Nocera G, Sironi A (2013) The impact of government ownership on bank risk. J Financ Int 22: 152–176. https://doi.org/10.1016/j.jfi.2012.11.002 doi: 10.1016/j.jfi.2012.11.002
|
| [65] |
Islam MS, Nishiyama SI (2016) The determinants of bank net interest margins: A panel evidence from South Asian countries. Res Int Bus Financ 37: 501–514. https://doi.org/10.1016/j.ribaf.2016.01.024 doi: 10.1016/j.ribaf.2016.01.024
|
| [66] |
Jensen MC, Meckling WH (1976) Theory of the firm: Managerial behaviour, agency costs and ownership structure. J Financ Econ 3: 305–360. https://doi.org/10.1016/0304-405X(76)90026-X doi: 10.1016/0304-405X(76)90026-X
|
| [67] |
Jiang C, Liu H, Molyneux P (2019) Do different forms of government ownership matter for bank capital behavior? Evidence from China. J Financ Stabil 40: 38–49. https://doi.org/10.1016/j.jfs.2018.11.005 doi: 10.1016/j.jfs.2018.11.005
|
| [68] |
Jones JD (1989) A comparison of lag–length selection techniques in tests of Granger causality between money growth and inflation: evidence for the US, 1959–86. Appl Econ 21: 809–822. https://doi.org/https://doi.org/10.1080/758520275 doi: 10.1080/758520275
|
| [69] |
Kanapiyanova K, Faizulayev A, Ruzanov R, et al. (2023) Does social and governmental responsibility matter for financial stability and bank profitability? Evidence from commercial and Islamic banks. J Islamic Account Bus Res 14: 451–472. https://doi.org/10.1108/JIABR-01-2022-0004 doi: 10.1108/JIABR-01-2022-0004
|
| [70] |
Kasman S, Kasman A (2015) Bank competition, concentration and financial stability in the Turkish banking industry. Econ Syst 39: 502–517. https://doi.org/10.1016/j.ecosys.2014.12.003 doi: 10.1016/j.ecosys.2014.12.003
|
| [71] |
Khan MS, Senhadji AS (2001) Threshold effects in the relationship between inflation and growth. IMF Staff Papers 48: 1–21. https://doi.org/10.2307/4621658 doi: 10.2307/4621658
|
| [72] | Kimeldorf G, May JH, Sampson AR (1982) Concordant and discordant monotone correlations and their evaluation by nonlinear optimization. Stud Manag Sci 19: 117–130. https://apps.dtic.mil/sti/pdfs/ADA093816.pdf |
| [73] |
La Porta R, Lopez‐de‐Silanes F, Shleifer A (2002) Government ownership of banks. J Financ 57: 265–301. https://doi.org/10.1111/1540-6261.00422 doi: 10.1111/1540-6261.00422
|
| [74] |
Lazopoulos I (2013) Liquidity uncertainty and intermediation. J Bank Financ 37: 403–414. https://doi.org/10.1016/j.jbankfin.2012.09.026 doi: 10.1016/j.jbankfin.2012.09.026
|
| [75] |
Lepetit L, Saghi-Zedek N, Tarazi A (2015) Excess control rights, bank capital structure adjustments, and lending. J Financ Econ 115: 574–591. https://doi.org/10.1016/j.jfineco.2014.10.004 doi: 10.1016/j.jfineco.2014.10.004
|
| [76] | Levine R (1997) Financial Development and Economic Growth: Views and Agenda. J Econ lit 35: 688–726. https://www.jstor.org/stable/2729790 |
| [77] |
Liu Y, Brahma S, Boateng A (2020) Impact of ownership structure and ownership concentration on credit risk of Chinese commercial banks. Int J Manag Financ 16: 253–272. https://doi.org/10.1108/IJMF-03-2019-0094 doi: 10.1108/IJMF-03-2019-0094
|
| [78] |
Marinkovic S, Radovic O (2010) On the determinants of interest margin in transition banking: the case of Serbia. Manag Financ 36: 1028–1042. https://doi.org/10.1108/03074351011088432 doi: 10.1108/03074351011088432
|
| [79] |
Mateev M, Nasr T (2023) Banking system stability in the MENA region: the impact of market power and capital requirements on banks' risk-taking behavior. Int J Islamic Middle Eastern Financ Manag 16: 1107–1140. https://doi.org/10.1108/IMEFM-05-2022-0198 doi: 10.1108/IMEFM-05-2022-0198
|
| [80] |
Mateev M, Tariq MU, Sahyouni A (2021) Competition, capital growth and risk-taking in emerging markets: Policy implications for banking sector stability during COVID-19 pandemic. PLoS One 16: e0253803. https://doi.org/10.1371/journal.pone.0253803 doi: 10.1371/journal.pone.0253803
|
| [81] |
Maudos Jn, Fernández de Guevara J (2004) Factors explaining the interest margin in the banking sectors of the European Union. J Bank Financ 28: 2259–2281. https://doi.org/10.1016/j.jbankfin.2003.09.004 doi: 10.1016/j.jbankfin.2003.09.004
|
| [82] |
McShane RW, Sharpe IG (1985) A time series/cross section analysis of the determinants of Australian trading bank loan/deposit interest margins: 1962–1981. J Bank Financ 9: 115–136. https://doi.org/10.1016/0378-4266(85)90065-2 doi: 10.1016/0378-4266(85)90065-2
|
| [83] |
Mehrotra P, Vyas V, Naik PK (2023) Behaviour of Capital and Risk Under Basel Regulations: A Simultaneous Equations Model Study of Indian Commercial Banks. Glob Bus Rev 1–19. https://doi.org/10.1177/09721509221146059 doi: 10.1177/09721509221146059
|
| [84] |
Mehzabin S, Shahriar A, Hoque MN, et al. (2023) The effect of capital structure, operating efficiency and non-interest income on bank profitability: new evidence from Asia. Asian J Econ Bank 7: 25–44. https://doi.org/10.1108/AJEB-03-2022-0036 doi: 10.1108/AJEB-03-2022-0036
|
| [85] | Mekonnen Y (2015) Determinants of capital adequacy of Ethiopia commercial banks. Eu Sci J 11: 315–331. https://eujournal.org/index.php/esj/article/view/6222 |
| [86] |
Mia MDR (2023) Market competition, capital regulation and cost of financial intermediation: an empirical study on the banking sector of Bangladesh. Asian J Econ Bank 7: 251–276. https://doi.org/10.1108/AJEB-03-2022-0028 doi: 10.1108/AJEB-03-2022-0028
|
| [87] | Modigliani F, Miller MH (1958) The Cost of Capital, Corporation Finance and the Theory of Investment. Am Econ Rev 48: 261–297. https://www.jstor.org/stable/1809766 |
| [88] |
Moudud-Ul-Huq S (2021) Does bank competition matter for performance and risk-taking? Empirical evidence from BRICS countries. Int J Emerg Mark 16: 409–447. https://doi.org/10.1108/IJOEM-03-2019-0197 doi: 10.1108/IJOEM-03-2019-0197
|
| [89] |
Moudud-Ul-Huq S, Ahmed K, Chowdhury MAF, et al. (2022) How do banks' capital regulation and risk-taking respond to COVID-19? Empirical insights of ownership structure. Int J Islamic Middle Eastern Financ Manag 15: 406–424. https://doi.org/10.1108/IMEFM-07-2020-0372 doi: 10.1108/IMEFM-07-2020-0372
|
| [90] | Moussa MAB (2018) Determinants of bank capital: Case of Tunisia. J Appl Financ Bank 8: 1–15. Available from: http://www.scienpress.com/Upload/JAFB/Vol%208_2_1.pdf. |
| [91] |
Mujtaba G, Akhtar Y, Ashfaq S, et al. (2021) The nexus between Basel capital requirements, risk-taking and profitability: what about emerging economies? Econ Res-Ekon Istraž 1–22. https://doi.org/10.1080/1331677X.2021.1890177 doi: 10.1080/1331677X.2021.1890177
|
| [92] |
Nguyen TPT, Nghiem SH (2015) The interrelationships among default risk, capital ratio and efficiency. Manag Financ 41: 507–525. https://doi.org/10.1108/MF-12-2013-0354 doi: 10.1108/MF-12-2013-0354
|
| [93] |
Nickell S (1981) Biases in dynamic models with fixed effects. Econometrica: J Econometric Soc 49: 1417–1426. https://doi.org/10.2307/1911408 doi: 10.2307/1911408
|
| [94] |
Otero L, Razia A, Cunill OM, et al. (2020) What determines efficiency in MENA banks? J Bus Res 112: 331–341. https://doi.org/10.1016/j.jbusres.2019.11.002 doi: 10.1016/j.jbusres.2019.11.002
|
| [95] |
Ozili PK, Uadiale O (2017) Ownership concentration and bank profitability. Futur Bus J 3: 159–171. https://doi.org/10.1016/j.fbj.2017.07.001 doi: 10.1016/j.fbj.2017.07.001
|
| [96] |
Peia O, Vranceanu R (2018) The cost of capital in a model of financial intermediation with coordination frictions. Oxford Econ Pap 70: 266–285. https://doi.org/10.1093/oep/gpx037 doi: 10.1093/oep/gpx037
|
| [97] |
Poghosyan T (2010) Re-examining the impact of foreign bank participation on interest margins in emerging markets. Emerg Mark Rev 11: 390–403. https://doi.org/10.1016/j.ememar.2010.08.003 doi: 10.1016/j.ememar.2010.08.003
|
| [98] |
Pushner GM (1995) Equity ownership structure, leverage, and productivity: Empirical evidence from Japan. Pac-Basin Financ J 3: 241–255. https://doi.org/10.1016/0927-538X(95)00003-4 doi: 10.1016/0927-538X(95)00003-4
|
| [99] |
Puspitasari E, Sudiyatno B, Hartoto WE, et al. (2021) Net interest margin and return on assets: A Case Study in Indonesia. J Asian Financ Econ Bus 8: 727–734. https://doi.org/10.13106/jafeb.2021.vol8.no4.0727 doi: 10.13106/jafeb.2021.vol8.no4.0727
|
| [100] |
Raharjo PG, Hakim DB, Manurung AH, et al. (2014) Determinant of capital ratio: A panel data analysis on state-owned banks in Indonesia. Bull Monetary Econ Bank 16: 395–414. https://doi.org/10.21098/bemp.v16i4.19 doi: 10.21098/bemp.v16i4.19
|
| [101] |
Rahman M, Ashraf B, Zheng C, et al. (2017) Impact of Cost Efficiency on Bank Capital and the Cost of Financial Intermediation: Evidence from BRICS Countries. Int J Financ Stud 5: 32. https://doi.org/10.3390/ijfs5040032 doi: 10.3390/ijfs5040032
|
| [102] |
Rahman MM, Rahman M, Masud MAK (2023) Determinants of the Cost of Financial Intermediation: Evidence from Emerging Economies. Int J Financ Stud 11. https://doi.org/10.3390/ijfs11010011 doi: 10.3390/ijfs11010011
|
| [103] |
Rahman MM, Zheng C, Ashraf BN, et al. (2018) Capital requirements, the cost of financial intermediation and bank risk-taking: Empirical evidence from Bangladesh. Res Int Bus Financ 44: 488–503. https://doi.org/10.1016/j.ribaf.2017.07.119 doi: 10.1016/j.ribaf.2017.07.119
|
| [104] |
Rakshit B, Bardhan S (2019) Bank Competition and its Determinants: Evidence from Indian Banking. Int J Econ Bus 26: 283–313. https://doi.org/10.1080/13571516.2019.1592995 doi: 10.1080/13571516.2019.1592995
|
| [105] |
Rastogi S, Gupte R, Meenakshi R (2021) A holistic perspective on bank performance using regulation, profitability, and risk-taking with a view on ownership concentration. J Risk Financ Manag 14: 111. https://doi.org/10.3390/jrfm14030111 doi: 10.3390/jrfm14030111
|
| [106] |
Roodman D (2009) How to do xtabond2: An introduction to difference and system GMM in Stata. Stata J 9: 86–136. https://doi.org//10.1177/1536867X0900900106 doi: 10.1177/1536867X0900900106
|
| [107] |
Saeed M, Izzeldin M, Hassan MK, et al. (2020) The inter-temporal relationship between risk, capital and efficiency: The case of Islamic and conventional banks. Pac-Basin Financ J 62: 101328. https://doi.org/10.1016/j.pacfin.2020.101328 doi: 10.1016/j.pacfin.2020.101328
|
| [108] |
Saif-Alyousfi AY, Saha A (2021) Determinants of banks' risk-taking behavior, stability and profitability: Evidence from GCC countries. Int J Islamic Middle Eastern Financ Manag 14: 874–907. https://doi.org/10.1108/IMEFM-03-2019-0129 doi: 10.1108/IMEFM-03-2019-0129
|
| [109] |
Sapienza P (2004) The effects of government ownership on bank lending. J Financ Econ 72: 357–384. https://doi.org/10.1016/j.jfineco.2002.10.002 doi: 10.1016/j.jfineco.2002.10.002
|
| [110] |
Saunders A, Wilson B (2001) An analysis of bank charter value and its risk-constraining incentives. J Financ Serv Res 19: 185–195. https://doi.org/10.1023/A:1011163522271 doi: 10.1023/A:1011163522271
|
| [111] |
Sensarma R, Ghosh S (2004) Net interest margin: does ownership matter? Vikalpa 29: 41–48. https://doi.org/10.1177/0256090920040104 doi: 10.1177/0256090920040104
|
| [112] |
Shabir M, Jiang P, Wang W, et al. (2023) COVID-19 pandemic impact on banking sector: A cross-country analysis. J Multinatl Financ Manag 67: 100784. https://doi.org/10.1016/j.mulfin.2023.100784 doi: 10.1016/j.mulfin.2023.100784
|
| [113] |
Shawtari FA, Ariff M, Razak SHA (2019) Efficiency and bank margins: a comparative analysis of Islamic and conventional banks in Yemen. J Islamic Account Bus Res 10: 50–72. https://doi.org/10.1108/JIABR-07-2015-0033 doi: 10.1108/JIABR-07-2015-0033
|
| [114] |
Shleifer A, Vishny RW (1997) A survey of corporate governance. J Financ 52: 737–783. https://doi.org/10.1111/j.1540-6261.1997.tb04820.x doi: 10.1111/j.1540-6261.1997.tb04820.x
|
| [115] |
Soedarmono W, Tarazi A (2013) Bank opacity, intermediation cost and globalization: Evidence from a sample of publicly traded banks in Asia. J Asian Econ 29: 91–100. https://doi.org/10.1016/j.asieco.2013.09.003 doi: 10.1016/j.asieco.2013.09.003
|
| [116] |
Tabak BM, Fazio DM, Cajueiro DO (2012) The relationship between banking market competition and risk-taking: Do size and capitalization matter? J Bank Financ 36: 3366–3381. https://doi.org/10.1016/j.jbankfin.2012.07.022 doi: 10.1016/j.jbankfin.2012.07.022
|
| [117] |
Thompson CG, Kim RS, Aloe AM, et al. (2017) Extracting the Variance Inflation Factor and Other Multicollinearity Diagnostics from Typical Regression Results. Basic Appl Soc Psych 39: 81–90. https://doi.org/10.1080/01973533.2016.1277529 doi: 10.1080/01973533.2016.1277529
|
| [118] |
Toumi K (2019) Islamic ethics, capital structure and profitability of banks; what makes Islamic banks different? Int J Islamic Middle Eastern Financ Manag 13: 116–134. https://doi.org/10.1108/imefm-05-2016-0061 doi: 10.1108/imefm-05-2016-0061
|
| [119] |
Trinugroho I, Agusman A, Tarazi A (2014) Why have bank interest margins been so high in Indonesia since the 1997/1998 financial crisis? Res Int Bus Financ 32: 139–158. https://doi.org/10.1016/j.ribaf.2014.04.001 doi: 10.1016/j.ribaf.2014.04.001
|
| [120] |
Vo XV (2018) Bank lending behavior in emerging markets. Financ Res Lett 27: 129–134. https://doi.org/10.1016/j.frl.2018.02.011 doi: 10.1016/j.frl.2018.02.011
|
| [121] |
Yu HC (2000) Banks' capital structure and the liquid asset–policy implication of Taiwan. Pac Econ Rev 5: 109–114. https://doi.org/10.1111/1468-0106.00093 doi: 10.1111/1468-0106.00093
|
| [122] |
Zheng C, Chowdhury MM, Khan MAM, et al. (2023) Effects of ownership on the relationship between bank capital and financial performance: evidence from Bangladesh. Int J Res Bus Soc Sci 12: 260–274. https://doi.org/10.20525/ijrbs.v12i9.2787 doi: 10.20525/ijrbs.v12i9.2787
|
| [123] |
Zheng C, Gupta AD, Moudud-Ul-Huq S (2018) Do human capital and cost efficiency affect risk and capital of commercial banks? An empirical study of a developing country. Asian Econ Financ Rev 8: 22–37. https://doi.org/10.18488/journal.aefr.2018.81.22.37 doi: 10.18488/journal.aefr.2018.81.22.37
|
Figures(1) / Tables(13)
Changjun Zheng, Md Mohiuddin Chowdhury, Anupam Das Gupta. Investigating the influence of ownership on the relationship between bank capital and the cost of financial intermediation[J]. Data Science in Finance and Economics, 2024, 4(3): 388-421. doi: 10.3934/DSFE.2024017







 DownLoad:
DownLoad: