Citation: Jianming Zhang , Chaoquan Lu , Xudong Li , Hye-Jin Kim, Jin Wang. A full convolutional network based on DenseNet for remote sensing scene classification[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3345-3367. doi: 10.3934/mbe.2019167

| [1] | X. W. Yao, J. W. Han, G. Cheng, et al., Semantic annotation ofhigh-resolution satellite images via weakly supervised learning, IEEE Trans. Geosci. Remote Sens., 54 (2016), 3660–3671. |
| [2] | S. Y.Cui and M. H. Datcu, Comparison of approximation methods to Kullback–Leiblerdivergence between Gaussian mixture models for satellite image retrieval, Remote Sens. Lett., 7 (2016), 651–660. |
| [3] | Y. B.Wang, L. Q. Zhang, X.H. Tong, et al., A three-layered graph-basedlearning approach for remote sensing image retrieval, IEEE Trans. Geosci. Remote Sens., 54 (2016), 6020–6034. |
| [4] | J.Muñoz-Marí, F. Bovolo, L.Gómez-Chova, et al., Semisupervised one-class support vector machines forclassification of remote sensing data, IEEETrans. Geosci. Remote Sens., 48 (2010), 3188–3197. |
| [5] | L. Y.Xiang, Y. Li, W.Hao, et al., Reversible natural language watermarking using synonymsubstitution and arithmetic coding, Comput. Mater. Continua, 55 (2018), 541–559. |
| [6] | Y. Tu,Y. Lin, J. Wang, et al., Semisupervised learningwith generative adversarial networks on digital signal modulationclassification. Comput. Mater. Continua, 55 (2018), 243–254. |
| [7] | D. J.Zeng, Y. Dai, F.Li, et al., Adversarial learning for distant supervised relation extraction, Comput. Mater. Continua, 55 (2018), 121–136. |
| [8] | J. M.Zhang, X. K. Jin, J.Sun, et al., Spatial and semantic convolutionalfeatures for robust visual object tracking, MultimediaTools Appl., Forthcoming 2018. Available at https://doi.org/ 10.1007/s11042-018-6562-8. |
| [9] | S. R.Zhou, W. L. Liang, J.G. Li, et al., Improved VGG model for road traffic sign recognition, Comput. Mater. Continua, 57 (2018), 11–24. |
| [10] | S. Karimpouli and P. Tahmasebi, Image-basedvelocity estimation of rock using convolutionalneural networks, Neural Netw., 111 (2019), 89–97. |
| [11] | S. Karimpouli and P. Tahmesbi, Segmentationof digital rock images using deep convolutional autoencoder networks, Comput. Geosci-UK, 126 (2019), 142–150. |
| [12] | P. Tahmasebi and A. Hezarkhani, Applicationof a modular feedforward neural network for grade estimation, Nat. Resour. Res., 20 (2011), 25–32. |
| [13] | O. Russakovsky, J. Deng, H. Su, et al., ImageNet large scale visualrecognition challenge, Int. J. Comput.Vision, 115 (2015), 211–252. |
| [14] | G. S.Xia, J. W. Hu, F.Hu, et al., AID: a benchmark data set for performance evaluation of aerial sceneclassification, IEEE Trans. Geosci.Remote Sens., 55 (2017), 3965–3981. |
| [15] | J. M.Zhang, Y. Wu, X.K. Jin, et al., A fast object tracker based on integrated multiple features anddynamic learning rate, Math. Probl. Eng.,2018 (2018), Article ID 5986062, 14 pages. |
| [16] | Y.Yang and N. Shawn, Comparing sift descriptors and gabor texture features forclassification of remote sensed imagery, 15thIEEE International Conference on Image Processing,(2008), 1852–1855. |
| [17] | B.Luo, S. J. Jiang and L. P. Zhang, Indexing of remote sensing images withdifferent resolutions by multiple features, IEEEJ. Sel. Top. Appl. Earth Obs. Remote Sens., 6 (2013), 1899–1912. |
| [18] | A.Avramović and V. Risojević, Block-based semantic classification ofhigh-resolution multispectral aerial images, Signal Image Video Process., 10 (2016), 75–84. |
| [19] | X.Chen, T. Fang, H.Huo, et al., Measuring the effectiveness of various features for thematicinformation extraction from very high resolution remote sensing imagery, IEEE Trans. Geosci. Remote Sens., 53 (2015), 4837–4851. |
| [20] | J. A. dos Santos, O. A. B. Penatti and R.da Silva Torres, Evaluating the potential of texture and color descriptors forremote sensing image retrieval and classification, 5th International Conference on Computer Vision Theory and Applications,(2010), 203–208. |
| [21] | Y.Yang and N. Shawn, Geographic image retrieval using local invariant features, IEEE Trans. Geosci. Remote Sens., 5 (2013), 818–832. |
| [22] | Y.Yang and N. Shawn, Bag-of-visual-words and spatial extensions for land-useclassification, 18th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems,(2010), 270–279. |
| [23] | Y.Yang and N. Shawn, Spatial pyramid co-occurrence for image classification, IEEE International Conference on ComputerVision, (2011), 1465–1472. |
| [24] | W. Shao, W. Yang, G.S. Xia, et al., A hierarchical scheme of multiple feature fusion forhigh-resolution satellite scene categorization, IEEE InternationalConference on Computer Vision Systems, (2013), 324–333. |
| [25] | W. Shao, W. Yang and G. S. Xia, Extremevalue theory-based calibration for the fusion of multiple features inhigh-resolution satellite scene classification, Int. J. Remote Sens., 34 (2013), 8588–8602. |
| [26] | N. Romain, P. David and G. Philippe-Henri,Evaluation of second-order visual features for land-use classification, 12th International Workshop on Content-BasedMultimedia Indexing, (2014), 1–5. |
| [27] | L. J.Chen, W. Yang, K.Xu, et al., Evaluation of local features for scene classification using VHRsatellite images, 2011 Joint Urban RemoteSensing Event, (2011), 385–388. |
| [28] | F. Hu,G. S. Xia, J. W. Hu, et al., Transferring deepconvolutional neural networks for the scene classification of high-resolutionremote sensing imagery, Remote Sens., 7 (2015), 14680–14707. |
| [29] | M. Castelluccio, G. Poggi, C. Sansone, et al., Land useclassification in remotesensing imagesby convolutional neuralnetworks, preprint, arXiv:1508.00092. |
| [30] | O. A. B. Penatti, K. Nogueira and J. A. dos Santos, Do deep features generalize from everydayobjects to remote sensing and aerial scenes domains?, IEEE Conference on Computer Vision and Pattern Recognition Workshops, (2015), 44–51. |
| [31] | F. P.S. Luus, B. P. Salmon, F.Van den Bergh, et al.,Multiview deep learning for land-use classification, IEEE Geosci. Remote Sens. Lett., 12 (2015), 2448–2452. |
| [32] | F. Zhang, B. Du and L. P. Zhang, Sceneclassification via a gradient boosting random convolutional network framework, IEEE Trans. Geosci. Remote Sens., 54 (2016), 1793–1802. |
| [33] | K.Nogueira, O. A. B. Penatti and J. A. dos Santos, Towards better exploitingconvolutional neural networks for remote sensing scene classification, Pattern Recogn., 61 (2017), 539–556. |
| [34] | G. Cheng, P. C. Zhou and J. W. Han,Learning rotation-invariant convolutional neural networks for objectdetection in VHR optical remote sensing images, IEEE Trans. Geosci. Remote Sens., 54 (2016), 7405–7415. |
| [35] | X. W.Yao, J. W. Han, G. Cheng, et al., Semantic annotation of high-resolutionsatellite images via weakly supervised learning, IEEE Trans. Geosci. Remote Sens., 54 (2016), 3660–3671. |
| [36] | G.Cheng, C. Y. Yang, X.W. Yao, et al., When deep learning meets metric learning: remote sensing imagescene classification via learning discriminative CNNs, IEEE Trans. Geosci. Remote Sens., 56 (2018), 2811–2821. |
| [37] | S.Chaib, H. Liu,Y. F. Gu, et al., Deep feature fusion for VHR remote sensing sceneclassification, IEEE Trans. Geosci.Remote Sens., 55 (2017), 4775–4784. |
| [38] | Q.Wang, S. T. Liu,J. Chanussot, et al., Scene classification with recurrent attention of VHR remotesensing images, IEEE Trans. Geosci.Remote Sens., 99 (2018), 1–13. |
| [39] | Y. L.Yu and F. X. Liu, Dense connectivity based two-stream deep feature fusion frameworkfor aerial scene classification, RemoteSens., 10 (2018), 1158. |
| [40] | Y. T. Chen, W. H. Xu, J. W. Zuo, et al., The fire recognition algorithmusing dynamic feature fusion and IV-SVM classifier, Cluster Comput., Forthcoming 2018. Available at https://doi.org/10.1007/s10586-018-2368-8. |
| [41] | G.Huang, Z. Liu, L.van derMaaten, et al., Densely connected convolutional networks, IEEE Conferenceon Computer Vision and Pattern Recognition,(2017), 4700–4708. |
| [42] | G.Huang, Y. Sun,Z. Liu, et al., Deep networks with stochastic depth, European Conferenceon Computer Vision,(2016), 646–661. |
| [43] | S.loffe and C. Szegedy, Batch normalization: acceleratingdeep network training by reducing internal covariate shift, 32nd International Conference on Machine Learning,(2015), 448–456. |
| [44] | P. Tahmasebi, F. Javadpour and M. Sahimi,Data mining and machine learning for identifying sweet spots in shalereservoirs, Expert Sys. Appl., 88 (2017), 435–447. |
| [45] | G.Cheng, J. W. Han and X. Q. Lu, Remote sensing image scene classification: benchmark and state of the art, Proc. IEEE, 105 (2017), 1865–1883. |
| [46] | L. H.Huang, C. Chen,W. Li, et al., Remote sensing image scene classification using multi-scalecompleted local binary patterns and fisher vectors, Remote Sens., 8 (2016),483. |
| [47] | X. Y.Bian, C. Chen,L. Tian, et al., Fusing local and global features for high-resolution sceneclassification, IEEE J. Sel. Top. Appl.Earth Obs. Remote Sens., 10 (2017), 2889–2901. |

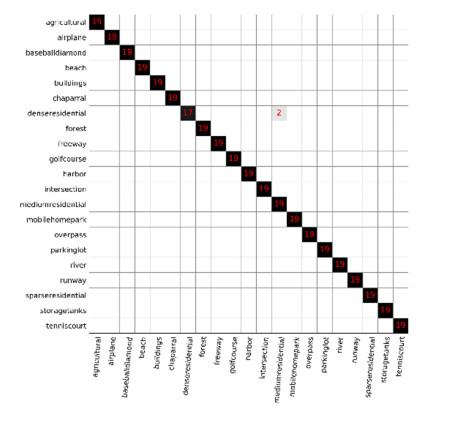
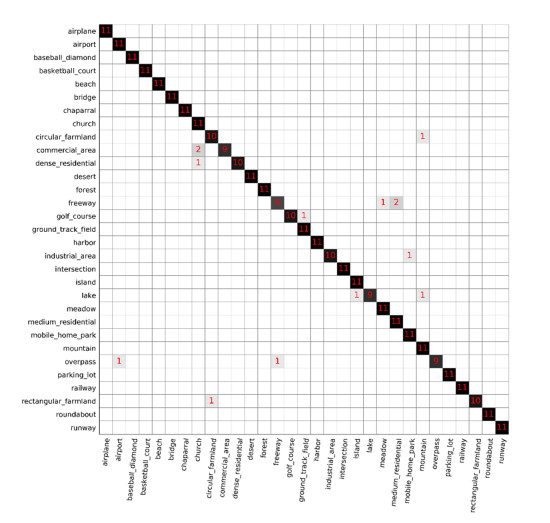
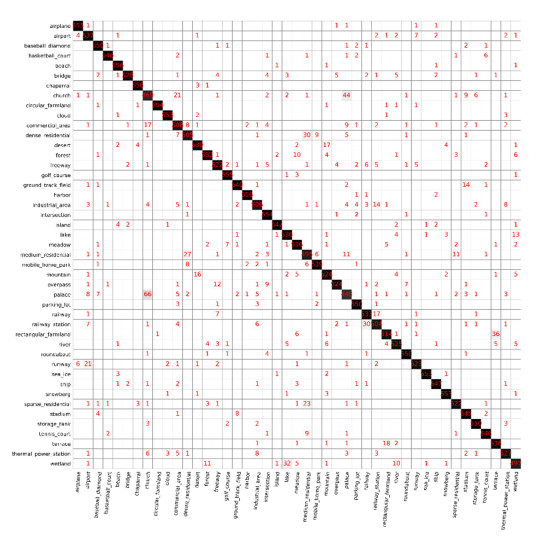
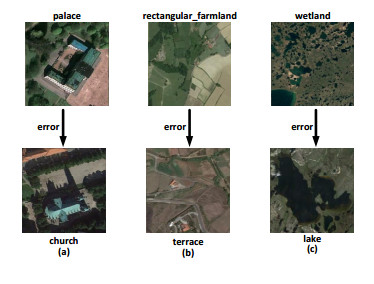
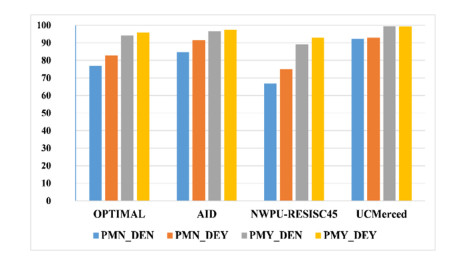

Figures(11) / Tables(7)

Jianming Zhang , Chaoquan Lu , Xudong Li , Hye-Jin Kim, Jin Wang. A full convolutional network based on DenseNet for remote sensing scene classification[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3345-3367. doi: 10.3934/mbe.2019167







 DownLoad:
DownLoad: