Citation: Xi-Chao Duan, Xue-Zhi Li, Maia Martcheva. Dynamics of an age-structured heroin transmission model with vaccination and treatment[J]. Mathematical Biosciences and Engineering, 2019, 16(1): 397-420. doi: 10.3934/mbe.2019019

| [1] | NIDA InfoFacts: Heroin. Available from: http://www.nida.nih.gov/infofacts/heroin.html. |
| [2] | J. Arino, C. C. McCluskey and P. van den Sriessche, Global results for an epidemic model with vaccination that exhibits backward bifurcation, SIAM J. Appl. Math., 64 (2003), 260–276. |
| [3] | P. T. Bremer, J. E. Schlosburg, M. L. Banks, F. F. Steele, B. Zhou, J. L. Poklis and K. D. Janda, Development of a clinically viable heroin vaccine, J. Am. Chem. Soc., 139 (2017), 8601–8611. |
| [4] | C. Comiskey, National prevalence of problematic opiate use in Ireland, EMCDDA Tech. Report, 1999. |
| [5] | O. Diekmann, J. A. P. Heesterbeek and J. A. J. Metz, On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogeneous populations, J. Math. Biol., 28 (1990), 365–382. |
| [6] | P. van den Driessche and J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29–48. |
| [7] | X. Duan, S. Yuan and X. Li, Global stability of an SVIR model with age of vaccination, Appl. Math. Comput., 226 (2014), 528–540. |
| [8] | X. Duan, S. Yuan, Z. Qiu and J. Ma, Global stability of an SVEIR epidemic model with ages of vaccination and latency, Comp. Math. Appl., 68 (2014), 288–308. |
| [9] | European Monitoring Centre for Drugs and Drug Addiction (EMCDDA): Annual Report, 2005. Available from: http:// annualreport.emcdda.eu.int/en/homeen.html. |
| [10] | B. Fang, X. Z. Li, M. Martcheva and L. M. Cai, Global asymptotic properties of a heroin epidemic model with treat-age, Appl. Math. Comput., 263 (2015), 315–331. |
| [11] | J. K. Hale, Asymptotic Behavior of Dissipative Systems, Mathematical Surveys and Monographs Vol 25, American Mathematical Society, Providence, RI, 1988. |
| [12] | W. Hao, Z. Su, S. Xiao, C. Fan, H. Chen and T. Liu, Longitudinal surveys of prevalence rates and use patterns of illicit drugs at selected high-prevalence areas in china from 1993 to 2000, Addiction., 99 (2004), 1176–1180. |
| [13] | W. M. Hirsch, H. Hanisch and J. P. Gabriel, Differential equation models of some parasitic infections: methods for the study of asymptotic behavior, Comm. Pure Appl. Math., 38 (1985), 733–753. |
| [14] | M. Iannelli, M. Martcheva and X. Z. Li, Strain replacement in an epidemic model with superinfection and perfect vaccination, Math. Biosci., 195 (2005), 23–46. |
| [15] | M. Iannelli, Mathematical theory of age-structured population dynamics, CNR Applied Mathematics Monographs, Giardini, Pisa, Vol. 7, 1995. |
| [16] | A. Kelly, M. Carvalho and C. Teljeur, Prevalence of Opiate Use in Ireland 2000-2001. A 3-Source Capture Recapture Study. A Report to the National Advisory Committee on Drugs, Subcommittee on Prevalence. Small Area Health Research Unit, Department of Public. |
| [17] | C. M. Kribs-Zaleta and J. X. Velasco-Hernndez, A simple vaccination model with multiple endemic states, Math. Biosci., 164 (2000), 183–201. |
| [18] | C. M. Kribs-Zaleta and M. Martcheva, Vaccination strategies and backward bifurcation in an agesince- infection structured model, Math. Biosci., 177&178 (2002), 317–332. |
| [19] | X. Z. Li, J. Wang and M. Ghosh, Stability and bifurcation of an SIVS epidemic model with treatment and age of vaccination, Appl. Math. Model., 34 (2010), 437–450. |
| [20] | X. Liu, Y. Takeuchi and S. Iwami, SVIR epidemic models with vaccination strategies, J. Theor. Bio., 253 (2008), 1–11. |
| [21] | D. R. Mackintosh and G. T. Stewart, A mathematical model of a heroin epidemic: implications for control policies, J. Epidemiol. Commun. H., 33 (1979), 299–304. |
| [22] | P. Magal, Compact attractors for time-periodic age-structured population models, Electron. J. Differ. Eq., 65 (2001), 1–35. |
| [23] | P. Magal and H. R. Thieme, Eventual compactness for semiflows generated by nonlinear agestructured models, Commun. Pure Appl. Anal., 3 (2004), 695–727. |
| [24] | R. K. Miller, Nonlinear Volterra integral equations Mathematics Lecture Note Series, W.A. Benjamin Inc., Menlo Park, CA, 1971. |
| [25] | K. A. Sporer, Acute heroin overdose, Ann. Intern. Med., 130 (1999), 584–590. |
| [26] | H. R. Thieme, Semiflows generated by Lipschitz perturbations of non-densely defined operators, Diff. Int. Eqns., 3 (1990), 1035–1066. |
| [27] | J.Wang, R. Zhang and T. Kuniya, The dynamics of an SVIR epidemiological model with infection age, IMA J. Appl. Math., 81 (2016), 321–343. |
| [28] | W. D. Wang and X. Q. Zhao, Basic reproduction numbers for reactio-diffusion epidemic models, SIAM J. Appl. Dyn. Syst., 11 (2012), 1652–1673. |
| [29] | Y. Xiao and S. Tang, Dynamics of infection with nonlinear incidence in a simple vaccination model, Nonlinear Anal. Real World Appl., 11 (2010), 4154–4163. |
| [30] | J. Yang, M. Martcheva and L. Wang, Global threshold dynamics of an SIVS model with waning vaccine-induced immunity and nonlinear incidence, Math. Biosci., 268 (2015), 1–8. |
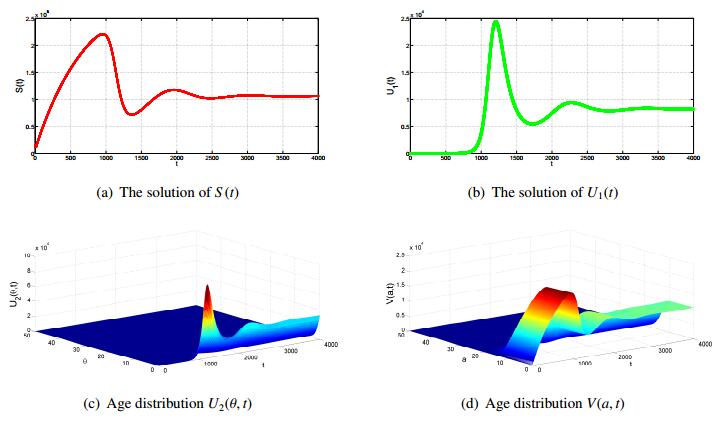
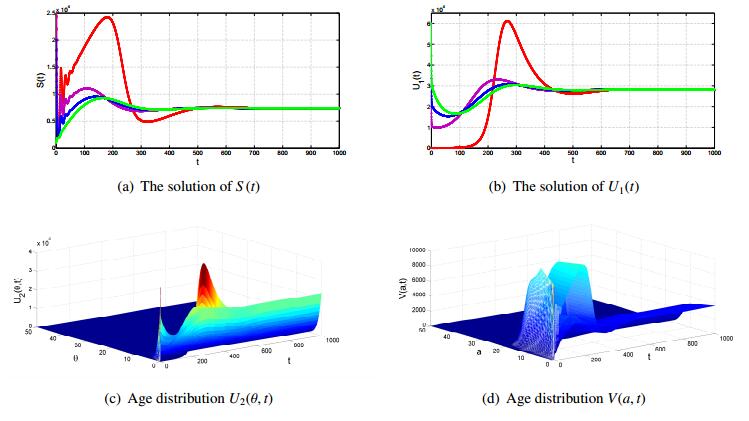
Figures(2)

Xi-Chao Duan, Xue-Zhi Li, Maia Martcheva. Dynamics of an age-structured heroin transmission model with vaccination and treatment[J]. Mathematical Biosciences and Engineering, 2019, 16(1): 397-420. doi: 10.3934/mbe.2019019







 DownLoad:
DownLoad: