Citation: Renji Han, Binxiang Dai, Lin Wang. Delay induced spatiotemporal patterns in a diffusive intraguild predation model with Beddington-DeAngelis functional response[J]. Mathematical Biosciences and Engineering, 2018, 15(3): 595-627. doi: 10.3934/mbe.2018027

| [1] | [ J. D. Murray, Mathematical Biology II: Spatial Models and Biomedical Applications, Spring-Verlag, New York, 2003. |
| [2] | [ G. A. Polis,C. A. Myers,R. D. Holt, The ecology and evolution of intraguild predation: Potential competitors that each other, Ann. Rev. Ecol. Sys., 20 (1989): 297-330. |
| [3] | [ M. H. Posey,A. H. Hines, Complex predator-prey interactions within an estuarine benthic community, Ecol., 72 (1991): 2155-2169. |
| [4] | [ G. A. Polis,R. D. Holt, Intraguild predation: The dynamics of complex trophic interactions, Trends Ecol. Evol., 7 (1992): 151-154. |
| [5] | [ R. D. Holt,G. A. Polis, A theoretical framework for intraguild predation, Am. Nat., 149 (1997): 745-764. |
| [6] | [ M. Arim,P. A. Marquet, Intraguild predation: A widespread interaction related to species biology, Ecol. Let., 7 (2004): 557-564. |
| [7] | [ P. Amarasekare, Trade-offs, temporal, variation, and species coexistence in communities with intraguild predation, Ecol., 88 (2007): 2720-2728. |
| [8] | [ R. Hall, Intraguild predation in the presence of a shared natural enemy, Ecol., 92 (2011): 352-361. |
| [9] | [ Y. S. Wang,D. L. DeAngelis, Stability of an intraguild predation system with mutual predation, Commun. Nonlinear Sci. Numer. Simulat., 33 (2016): 141-159. |
| [10] | [ I. Velazquez,D. Kaplan,J. X. Velasco-Hernandez,S. A. Navarrete, Multistability in an open recruitment food web model, Appl. Math. Comp., 163 (2005): 275-294. |
| [11] | [ S. B. Hsu,S. Ruan,T. H. Yang, Analysis of three species Lotka-Volterra food web models with omnivory, J. Math. Anal. Appl., 426 (2015): 659-687. |
| [12] | [ P. A. Abrams,S. R. Fung, Prey persistence and abundance in systems with intraguild predation and type-2 functional response, J. Theor. Biol., 264 (2010): 1033-1042. |
| [13] | [ A. Verdy,P. Amarasekare, Alternative stable states in communities with intraguild predatiion, J. Theor. Biol., 262 (2010): 116-128. |
| [14] | [ M. Freeze,Y. Chang,W. Feng, Analysis of dynamics in a complex food chain with ratio-dependent functional response, J. Appl. Anal. Comput., 4 (2014): 69-87. |
| [15] | [ Y. Kang,L. Wedekin, Dynamics of a intraguild predation model with generalist or specialist predator, J. Math. Biol., 67 (2013): 1227-1259. |
| [16] | [ H. I. Freedman,V. S. H. Rao, Stability criteria for a system involving two time delays, SIAM J. Appl. Math., 46 (1986): 552-560. |
| [17] | [ G. S. K. Wolkowicz,H. X. Xia, Global asymptotic behavior of chemostat model with discrete delays, SIAM J. Appl. Math., 57 (1997): 1019-1043. |
| [18] | [ Y. L. Song,M. A. Han,J. J. Wei, Stability and Hopf bifurcation analysis on a simplified BAM neural network with delays, Physica D, 200 (2005): 185-204. |
| [19] | [ S. Ruan, On nonlinear dynamics of predator-prey models with discrete delay, Math. Mod. Nat. Phen., 4 (2009): 140-188. |
| [20] | [ X. Y. Meng,H. F. Huo,X. B. Zhao,H. Xiang, Stability and Hopf bifurcation in a three-species system with feedback delays, Nonlinear Dyn., 64 (2011): 349-364. |
| [21] | [ M. Y. Li,H. Shu, Multiple stable periodic oscillations in a mathematical model of CTL-response to HTLV-I infection, Bull. Math. Biol., 73 (2011): 1774-1793. |
| [22] | [ H. Shu,L. Wang,J. Watmough, Sustained and transient oscillations and chaos induced by delayed antiviral inmune response in an immunosuppressive infective model, J. Math. Biol., 68 (2014): 477-503. |
| [23] | [ M. Yamaguchi,Y. Takeuchi,W. Ma, Dynamical properties of a stage structured three-species model with intra-guild predation, J. Comput. Appl. Math., 201 (2007): 327-338. |
| [24] | [ H. Shu,X. Hu,L. Wang,J. Watmough, Delayed induced stability switch, multitype bistability and chaos in an intraguild predation model, J. Math. Biol., 71 (2015): 1269-1298. |
| [25] | [ A. Okubo and S. A. Levin, Diffusion and Ecological Problems: Modern perspectives, Springer-Verlag, New York, 2001. |
| [26] | [ T. Faria, Stability and bifurcation for a delayed predator-prey model and the effect of diffusion, J. Math. Anal. Appl., 254 (2001): 433-463. |
| [27] | [ C. V. Pao, Systems of parabolic equations with continuous and discrete delays, J. Math. Anal. Appl., 205 (1997): 157-185. |
| [28] | [ C. V. Pao, Convergence of solutions of reaction-diffusion systems with time delays, Nonlinear Anal., 48 (2002): 349-362. |
| [29] | [ J. Wang,J. P. Shi,J. J. Wei, Dyanmics and pattern formation in a diffusive predator-prey system with strong Allee effect in prey, J. Diff. Equat., 251 (2011): 1276-1304. |
| [30] | [ C. Tian, Delay-driven spatial patterns in a plankton allelopathic system, Chaos, 22(2012), 013129, 7 pp. |
| [31] | [ C. Tian,L. Zhang, Hopf bifurcation analysis in a diffusive food-chain model with time delay, Comput. Math. Appl., 66 (2013): 2139-2153. |
| [32] | [ W. Zuo,J. Wei, Global stability and Hopf bifurcations of a Beddington-DeAngelis type predator-prey system with diffusion and delay, Appl. Math. Comput., 223 (2013): 423-435. |
| [33] | [ J. Zhao,J. Wei, Dynamics in a diffusive plankton system with delay and toxic substances effect, Nonlinear Anal., 22 (2015): 66-83. |
| [34] | [ L. Zhu,H. Zhao,X. M. Wang, Bifurcation analysis of a delay reaction-diffusion malware propagation model with feedback control, Commun. Nonlinear Sci. Numer. Simulat., 22 (2015): 747-768. |
| [35] | [ Y. Li,M. X. Wang, Hopf bifurcation and global stability of a delayed predator-prey model with prey harvesting, Comput. Math. Appl., 69 (2015): 398-410. |
| [36] | [ H. Y. Zhao,X. Zhang,X. Huang, Hopf bifurcation and spatial patterns of a delayed biological economic system with diffusion, Appl. Math. Comput., 266 (2015): 462-480. |
| [37] | [ Q. X. Ye, Z. Y. Li, M. X. Wang and Y. P. Wu, Introduction to Reaction-diffusion Equations (Second Edition), Science Press, Bei Jing, 2011. |
| [38] | [ D. Henry, Geometric Theory of Semilinear Parabolic Equations, Springer-Verlag, Berlin/New York, 1981. |
| [39] | [ S. Ruan,J. Wei, On the zeros of a third degree exponential polynomial with applications to a delayed model for the control of testoterone secretion, Math. Med. Biol., 18 (2001): 41-52. |
| [40] | [ J. Wu, Theory and Applications of Partial Functional Differential Equations, Springer-Verlag, New York, 1996. |
| [41] | [ B. Hassard, N. Kazarinoff and Y. Wan, Theory and Applications of Hopf bifurcation, Cambridge University Press, Cambridge, 1981. |
| [42] | [ J. Y. Wakano,C. Hauert, Pattern formation and chaos in spatial ecological public goods games, J. Theor. Biol., 268 (2011): 30-38. |
| [43] | [ M. Banerjee, S. Ghoral and N. Mukherjee, Approximated spiral and target patterns in Bazykin's prey-predator model: Multiscale perturbation analysis, Int. J. Bifurcat. Chaos, 27 (2017), 1750038, 14 pp. |
| [44] | [ H. Malchow, S. V. Petrovskii and E. Venturino, Spatiotemporal Patterns in Ecology and Epidemiology: Theory, Models, Simulations, Chapman & Hall / CRC Press, 2008. |
| [45] | [ Q. Ouyang, Pattern Formation in Reaction-Diffusion Systems Shanghai Scientific and Technological Education Publishing House, SHANGHAI, 2000. |
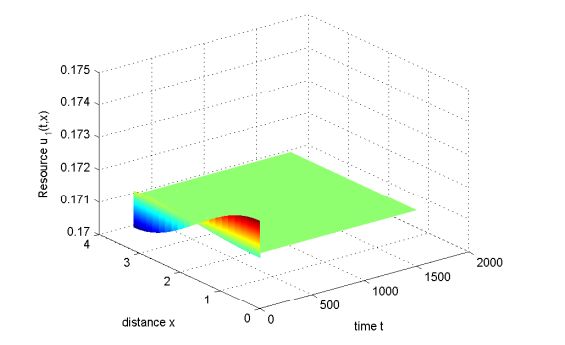
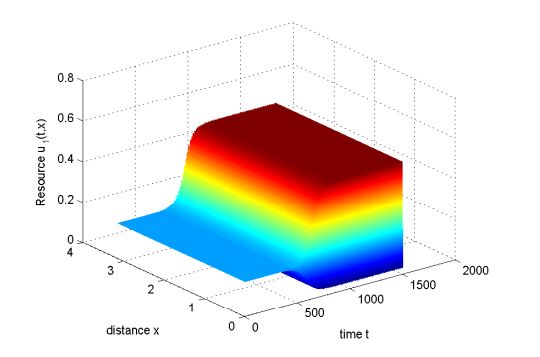
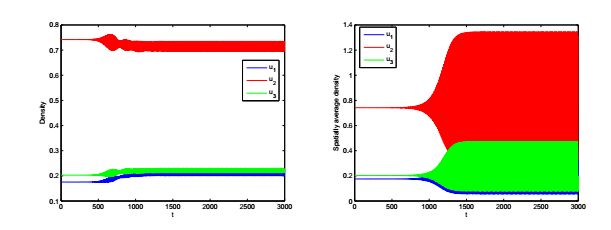
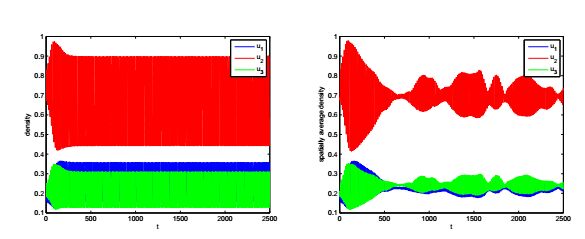
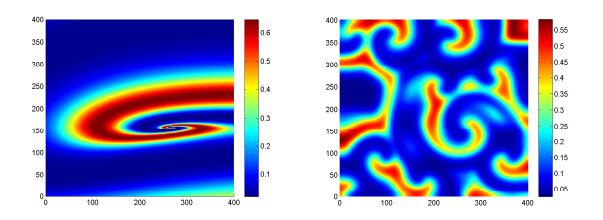
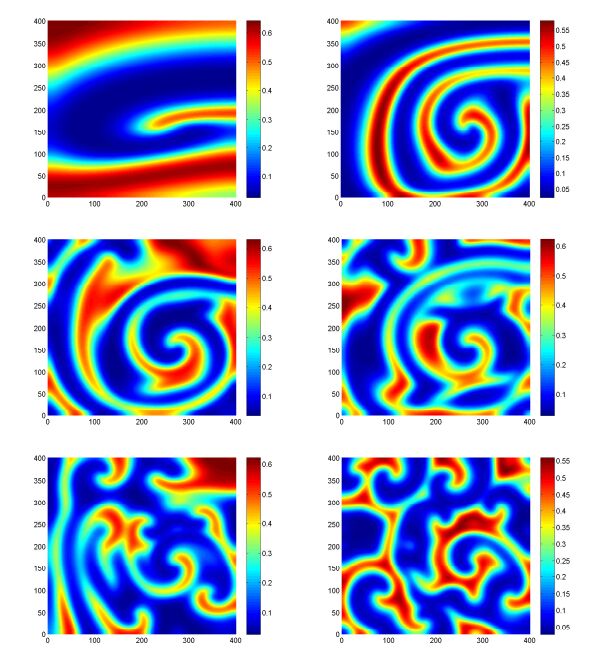
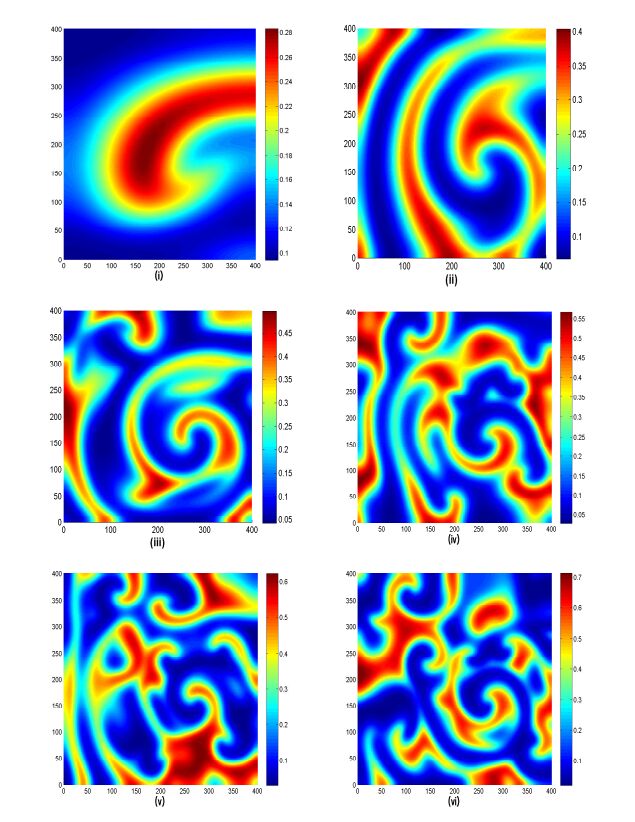
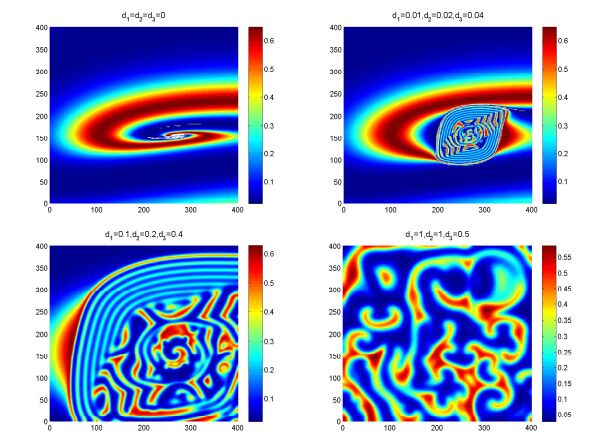
Figures(10) / Tables(1)

Renji Han, Binxiang Dai, Lin Wang. Delay induced spatiotemporal patterns in a diffusive intraguild predation model with Beddington-DeAngelis functional response[J]. Mathematical Biosciences and Engineering, 2018, 15(3): 595-627. doi: 10.3934/mbe.2018027







 DownLoad:
DownLoad: