Citation: Kory J. Allred, Wei Luo. Data-mining Based Detection of Glaciers: Quantifying the Extent of Alpine Valley Glaciation[J]. AIMS Geosciences, 2015, 1(1): 1-18. doi: 10.3934/geosci.2015.1.1

| [1] |
Brandon MT, Rodent-Tice MK, Garver JL (1998) Late Cenozoic exhumation of the Cascadia accretionary wedge in the Olympic Mountains, northwest Washington State. GSA Bulletin 110: 985-1009. doi: 10.1130/0016-7606(1998)110<0985:LCEOTC>2.3.CO;2

|
| [2] | Poulos MJ, Pierce JL, Flores AN, et al. (2012) Hillslope asymmetry maps reveal widespread, multi-scale organization. Geophys Res Lett 39: 6. |
| [3] | Gillespie AR (1982) Quaternary Glaciation and Tectonism in the Southeastern Sierra Nevada. Pasadena. 720 p. |
| [4] |
Delmas M, Gunnell Y, Calvet M (2014) Environmental controls on alpine cirque size. Geomorphology 206: 318-329. doi: 10.1016/j.geomorph.2013.09.037
|
| [5] |
Montgomery DR, Balco G, Willett SD (2001) Climate, tectonics and the morphology of the Andes. Geology 29: 579-582. doi: 10.1130/0091-7613(2001)029<0579:CTATMO>2.0.CO;2
|
| [6] |
Yanites BJ, Ehlers TA (2012) Global climate and tectonic controls on the denudation of glaciated mountains. Earth Planet Sc Lett 325-326: 63-75. doi: 10.1016/j.epsl.2012.01.030
|
| [7] |
Hooyer TS, Cohen D, Iverson NR (2012) Control of glacial quarrying by bedrock joints. Geomorphology 153-154: 91-101. doi: 10.1016/j.geomorph.2012.02.012
|
| [8] |
Brocklehurst SH, Whipple KX (2002) Glacial erosion and relief production in the Eastern Sierra Nevada, California. Geomorphology 42: 1-24. doi: 10.1016/S0169-555X(01)00069-1
|
| [9] |
Hallet B, Hunter L, Bogen J (1996) Rates of erosion and sediment evacuation by glaciers: a review of field data and their implications. Global Planet Change 12: 213-235. doi: 10.1016/0921-8181(95)00021-6
|
| [10] | Headley R, Hallet B, Roe G, et al. (2012) Spatial distribution of glacial erosion rates in the St. Elias range, Alaska, inferred from a realistic model of glacier dynamics. J Geophys Res 117: 16. |
| [11] |
Koppes MN, Montgomery DR (2009) The relative efficacy of fluvial and glacial erosion over modern to orogenic timescales. Nature Geoscience 2: 644-647. doi: 10.1038/ngeo616
|
| [12] | Oerlemans J (1984) Numerical Experiments on Large-Scale Glacial Erosion. Zeitschrift für Gletscherkunde und Glazialgeologie 20: 107-126. |
| [13] | Sternai P, Herman F, Fox MR, et al. (2011) Hypsometric analysis to identify spatially variable glacial erosion. J Geophys Res 116: 17. |
| [14] |
Hanson PR, Mason JA, Goble RJ (2006) Fluvial terrace formation along Wyomings Laramie Range as a response to inceased late Pleistocene flood magnitudes. Geomorphology 76: 12-25. doi: 10.1016/j.geomorph.2005.08.010
|
| [15] | Anderson RS, Molnar P, Kessler MA (2006) Features of glacial valley profiles simply explained. J Geophys Res 111: 14. |
| [16] |
Harbor J (1992) Numerical modeling of the development of U-shaped valleys by glacial erosion. Geol Soc Am Bull 104: 1364-1375. doi: 10.1130/0016-7606(1992)104<1364:NMOTDO>2.3.CO;2
|
| [17] |
Brocklehurst SH, Whipple KX (2004) Hypsometry of glaciated landscapes. Earth Surf Proc land 29: 907-926. doi: 10.1002/esp.1083
|
| [18] | Swanson CD II (2012) Applying GIS metrics to determine degree of glacial modification in mountainous landscapes. Central Washington University. 104 p. |
| [19] |
Amerson BE, Montgomery DR, Meyer G (2008) Relative size of fluvial and glaciated valleys in central Idaho. Geomorphology 93: 537-547. doi: 10.1016/j.geomorph.2007.04.001
|
| [20] | Bonk R. Scale-dependent (2002) Geomorphometric Analysis of Glacier Mapping of Nanga Parbat: GRASS GIS Approach; 2002; Trento. pp. 21. |
| [21] |
Anders AM, Mitchell SG, Tomkin JH (2010) Cirques, peaks, and precipitation patterns in the Swiss Alps: Connections among climate, glacial erosion, and topography. Geology 38: 239-242. doi: 10.1130/G30691.1
|
| [22] | Brown DG, Lusch DP, Duda KA (1998) Supervised classification of types of glaciated landscapes using digital elevation data. Geomorphology 21: 18. |
| [23] | Wahbeh AH, Al-Radaideh QA, Al-Kabi MN, et al. (2011) A Comparison Study between Data Mining Tools over some Classification Methods. IJACSA, Special Issue: 18-26. |
| [24] | Han J, Kamber M (2006) Data Mining: Concepts and Techniques. Burlington, MA: Elsevier Sci Technol. |
| [25] | Giudici P (2005) Applied Data Mining: Statistical Methods for Business and Industry. Hoboken: Wiley. |
| [26] | Haghanikhameneh F, Panahy PHS, Khanahmadliravi N, et al. (2012) A Comparison Study between Data Mining Algorithms over Classification Techniques in Squid Dataset. IJAI 9: 59-66. |
| [27] |
Foster D, Brocklehurst SH, Gawthorpe RL (2008) Small valley glaciers and the effectiveness of the glacial buzzsaw in the northern Basin and Range, USA. Geomorphology 102: 624-639. doi: 10.1016/j.geomorph.2008.06.009
|
| [28] |
Resources WSDoN. Montgomery DR (2002) Valley formation by fluvial and glacial erosion. Geology 30: 1047-1050. doi: 10.1130/0091-7613(2002)030<1047:VFBFAG>2.0.CO;2
|
| [29] |
Strahler AN (1952) Hypsometric (Area-Altitude) Analysis of Erosional Topography. Bull Geol Soc Am 63: 1117-1142. doi: 10.1130/0016-7606(1952)63[1117:HAAOET]2.0.CO;2
|
| [30] | Ramu M, Mahalingam B (2012) Hypsometric Properties of Drainage Basins In Karnataka Using Geographical Information System. NY Sci J 5: 156-158. |
| [31] | Luo W (2002) Hypsometric analysis of Margaritifer Sinus and origin of valley networks. J Geophys Res 107: 10. |
| [32] | Perez-Pena JV, Azanon JM, Azor A (2009) CalHypso: An ArcGIS extension to calculate hypsometric curves and their statistical moments. Applications to drainage basin analysis in SE Spain. Compu Geosciences 35: 1214-1223. |
| [33] |
Harlin JM (1978) Statistical Moments of the Hypsometric Curve and Its Density Function. Math Geol 10: 59-72. doi: 10.1007/BF01033300
|
| [34] | Luo W (2000) Quantifying groundwater-sapping landforms with a hypsometric technique. J Geophys Res 105: 10. |
| [35] |
Luo W (1998) Hypsometric analysis with a Geographic Information System. Compu Geosciences 24: 815-821. doi: 10.1016/S0098-3004(98)00076-4
|
| [36] |
Thomson SN, Brandon MT, Tomkin JH, et al. (2010) Glaciation as a destructive and constructive control on mountain building. Nature 467: 4. doi: 10.1038/467S4a
|
| [37] | Meier MF, Post AS. Recent variations in mass net budgets of glaciers in Westen North America. In: Ward WH, editor; 1962; Obergurgl. IUGG. pp. 63-77. |
| [38] | Bahr DB, Dyurgerov M, Meier MF (2009) Sea-level rise from glaciers and ice caps: A lower bound. Geophys Res Lett 36: 4. |
| [39] | Demsar J, Curk T, Erjavec A (2013) Orange: Data Mining Toolbox in Python. JMLR 14: 2349-2353. |
| [40] |
Bellazi R, Zupan B (2008) Predictive data mining in clinical medicin: current issures and guidelnes. Int Journal Med Inform 77: 81-97. doi: 10.1016/j.ijmedinf.2006.11.006
|
| [41] |
Breiman L (2001) Random Forests. Mach Learn 45: 5-32. doi: 10.1023/A:1010933404324
|
| [42] | Ho TK. Random Decision Forests; 1995; Montreal. IEEE. pp. 278-282. |
| [43] |
Catal C, Sevim U, Diri B (2011) Practical development of an Eclipse-based software fault prediction tool using Naive Bayes algorithm. Expert Syst Appl 38: 2347-2353. doi: 10.1016/j.eswa.2010.08.022
|
| [44] | Garcia V, Debreuve E, Nielsen F, et al. K-nearest neighbor search: Fast GPU-based implementations and application to high-dimensional feature matching; 2010 26-29 Sept. 2010. pp. 3757-3760. |
| [45] |
Shao J (1993) Linear model selection by cross-validation. J Am Stat Ass 88: 486--494 . doi: 10.1080/01621459.1993.10476299
|
| [46] | Strobl C, Malley J, Tutz G(2009) An Introduction to Recursive Partitioning: Rationale, Application, and Characteristics of Classification and Regression Trees, Bagging, and Random Forests. Pschol Methods 14(4): 323-348. |
| [47] | Segal MR (2004) Machine Learning Benchmarks and Random Forest Regression. |
| [48] | Možina M, Demšar J, Kattan M, et al. (2004) Nomograms for Visualization of Naive Bayesian Classifier. In: Boulicaut J-F, Esposito F, Giannotti F et al., editors. Knowledge Discovery in Databases: PKDD 2004: Springer Berlin Heidelberg. pp. 337-348. |
| [49] |
Horton RE (1945) Erosional development of streams and their drainage basins: hydro-physical approach to quantitative morphology. Geol Soc Am Bull 56: 275-370. doi: 10.1130/0016-7606(1945)56[275:EDOSAT]2.0.CO;2
|
| [50] | Souness C, Hubbard B, Milliken RE, et al. (2012) An inventory and population-scale analysis of martian glacier-like forms. Icarus 217: 13. |
| [51] | Meier MF, Post AS (1962) Recent variations in mass net budgets of glaciers in western North America. IASHP 58: 63-77. |
| [52] | Kern Z, László P (2010) Size specific steady-state accumulation-area rato: an improvement for equilibrium-line estimation of small paleoglaciers. QSP 29: 2781-2787 |
| [53] |
Naylor S, Gabet EJ (2007) Valley asymmetry and glacial versus nonglacial erosion in the Bitterroot Range, Montana, USA. Geology 35: 375-378. doi: 10.1130/G23283A.1
|
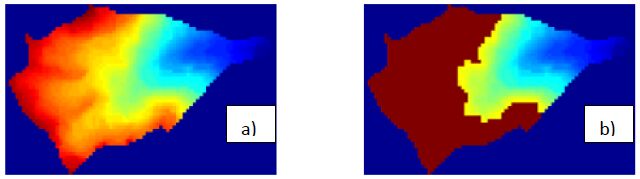
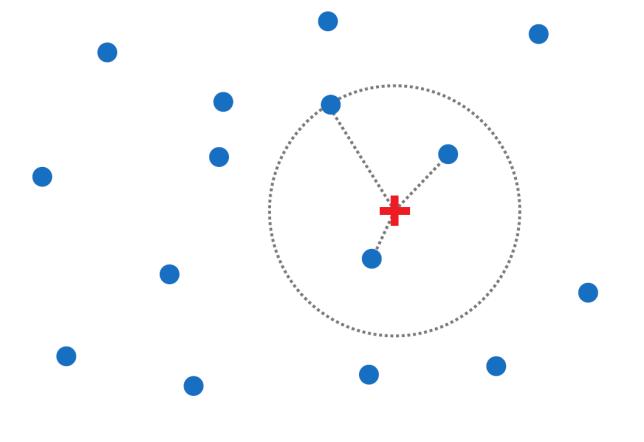
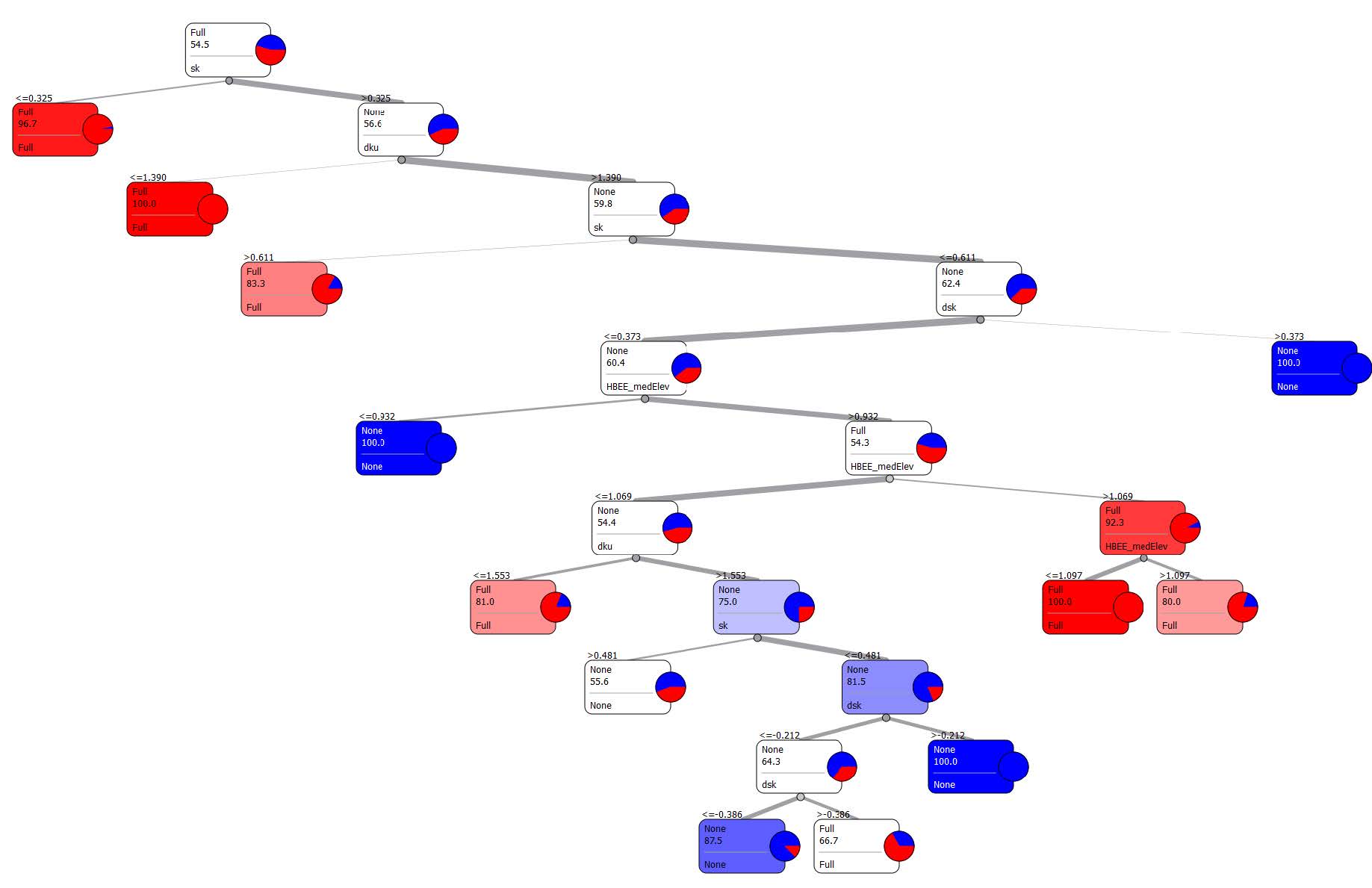
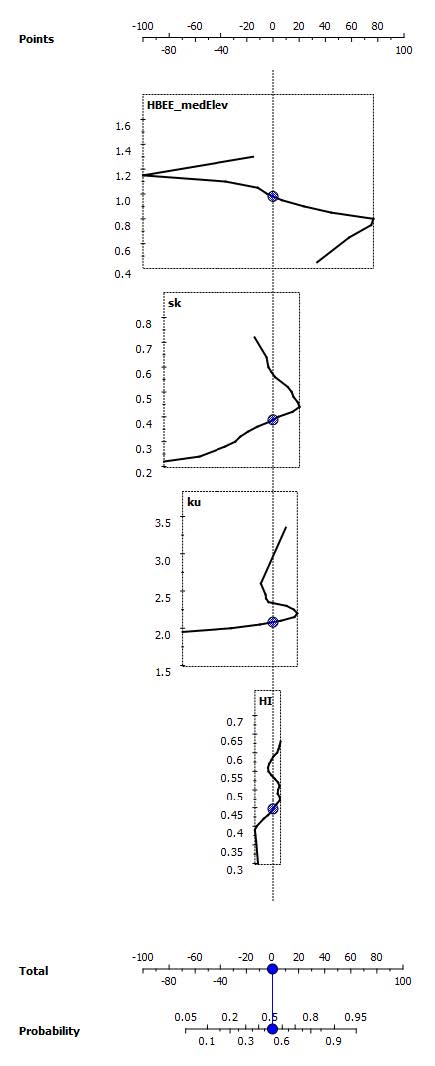
Figures(5) / Tables(2)

Kory J. Allred, Wei Luo. Data-mining Based Detection of Glaciers: Quantifying the Extent of Alpine Valley Glaciation[J]. AIMS Geosciences, 2015, 1(1): 1-18. doi: 10.3934/geosci.2015.1.1







 DownLoad:
DownLoad: