Citation: Ross Sadler. Towards a more complete understanding of the occurrence and toxicities of the cylindrospermopsins[J]. AIMS Environmental Science, 2015, 2(3): 827-851. doi: 10.3934/environsci.2015.3.827

| [1] | Hawkins PR, Runnegar MTC, Jackson ARB, et al. (1985) Severe hepatotoxicity caused by the tropical cyanobacterium (bluegreen alga) Cylindrospermopsis racoborskii (Woloszynska) Seenaya and Subba Raju isolaged from a domestic water supply reservoir. Appl Environ Microb 50: 1292-1295. |
| [2] |
Ohtani I, Moore RE, Runnegar MTC (1992) Cylindrospermopsin: a potent hepatotoxin from the blue-green alga Cylindrospermopsis raciborskii. J Am Chem Soc 114: 7941-7942. doi: 10.1021/ja00046a067

|
| [3] | Seawright AA, Nolan CC, Shaw GR, et al. (1999) The oral toxicity for mice of the tropical cyanobacterium Cylindrospermopsis raciborskii (Woloszynska). Environ Toxicol 14: 135-142. |
| [4] | Humpage A (2008) Toxin types, toxicokinetics and toxicodynamics. Adv Exp Med Biol619: 383-416. |
| [5] |
Kinnear S (2010) Cylindrospermopsin: A Decade of Progress on Bioaccumulation Research. Mar Drugs 8: 542-564. doi: 10.3390/md8030542
|
| [6] | Moreira C, Azevedo J, Antunes A, et al. (2013) Cylindrospermopsin: occurrence, methods of detection and toxicology. J Appl Microb 114: 605-620. |
| [7] | de la Cruz AA, Hiskia A, Kaloudis T, et al. (2013) A review on cylindrospermopsin: the global occurrence, detection, toxicity and degradation of a potent cyanotoxin. Environmental Sci Proc Impacts 15: 1979-2003. |
| [8] | Stewart I, Seawright AA, Schluter PJ, et al. (2006) Primary irritant and delayed-contact hypersensitivity reactions to the freshwater cyanobacterium Cylindrospermopsis raciborskii and its associated toxin cylindrospermopsin. BMC Dermatol 6: PMC1544345. |
| [9] | Wimmer KM, Strangman WK, Wright JLC (2014) 7-Deoxy-desulfo-cylindrospermopsin and 7-deoxy-desulfo-12-acetylcylindrospermopsin: Two new cylindrospermopsin analogs isolated from a Thai strain of Cylindrospermopsis raciborskii. Harmful Algae 37: 203-206. |
| [10] | Orr PT, Rasmussen JP, Burford MA, et al. (2011) Evaluation of quantitative real-time PCR to characterise spatial and temporal variations in cyanobacteria, Cylindrospermopsis raciborskii (Woloszynska) Seenaya et Subba Raju and cylindrospermopsin concentrations in three subtropical Australian reservoirs. Corrigendum. Harmful Algae 10: 234. |
| [11] |
Li R, Carmichael WW, Brittain S, et al. (2001) First Report of the Cyanotoxins Cylindrospermopsin and Deoxycylindrospermopsin from Raphidiopsis curvata (Cyanobacteria). J Phycol 37: 1121-1126. doi: 10.1046/j.1529-8817.2001.01075.x
|
| [12] | Neumann C, Bain P, Shaw G (2007) Studies of the comparative in vitro toxicology of the cyanobacterial metabolite deoxycylindrospermopsin. J Toxicol Env Health, Part A 70: 1679-1686. |
| [13] |
Everson S, Fabbro L, Kinnear S, et al. (2009) Distribution of the cyanobacterial toxins cylindrospermopsin and deoxycylindrospermopsin in a stratified lake in north-eastern New South Wales, Australia. Mar Fresh Res 60: 25-33. doi: 10.1071/MF08115
|
| [14] |
McGregor G, Sendall BC, Hunt LT, et al. (2011) Report of the cyanotoxinscylindrospermopsin and deoxy-cylindrospermopsin from Raphidiopsis mediterranea Skuja (Cyanobacteria/Nostocales). Harmful Algae 10: 402-410. doi: 10.1016/j.hal.2011.02.002
|
| [15] |
Rzymski P, Poniedziałek B, Kokocin ski M, et al. (2014) Interspecific allelopathy in cyanobacteria: Cylindrospermopsin and Cylindrospermopsis raciborskii effect on the growth and metabolism of Microcystis aeruginosa. Harmful Algae 35: 1-8. doi: 10.1016/j.hal.2014.03.002
|
| [16] |
Heintzelman GR, Fang WK, Keen SP, et al. (2002) Stereoselective total synthesis and reassignment of stereochemistry of the freshwater cyanobacterial hepatotoxins cylindrospermopsin and 7-epi-cylindrospermopsin. J Am Chem Soc 124: 3939-3945. doi: 10.1021/ja020032h
|
| [17] |
Moustaka-Gouni M, Kormas KA, Vardaka E, et al. (2009) Raphidiopsis mediterranea Skuja represents non-heterocytous life-cycle stages of Cylindrospermopsis raciborskii (Woloszynska) Seenayya et Subba Raju in Lake Kastoria (Greece), its type locality: Evidence by morphological and phylogenetic analysis. Harmful Algae 8: 864-872. doi: 10.1016/j.hal.2009.04.003
|
| [18] |
Banker R, Teltsch B, Sukenik A, et al. (2000) 7-epi-cylindrospermopsin, a toxic minor metabolite of the cyanobacterium Aphanizomenon ovalisporumfrom Lake Kinneret, Israel. J Nat Prod 63: 387-389. doi: 10.1021/np990498m
|
| [19] | Mazmouz R, Chapuis-Hugon F, Pichon V, et al. (2010) Biosynthesis of Cylindrospermopsin and 7-epi-cylindrospermopsin in Oscillatoria sp. Strain PCC 6506: Identification of the cyr Gene Cluster and Toxin Analysis. Appl Environ Microb 76: 4943-4949. |
| [20] | Mazmouz R, Chapuis-Hugon F, Pichon V, et al. (2011) The Last Step of the Biosynthesis of the CyanotoxinsCylindrospermopsin and 7-epi-Cylindrospermopsin is Catalysed by CyrI, a 2-Oxoglutarate- Dependent Iron Oxygenase. Chem Bio Chem 12: 858-862. |
| [21] | Norris RLG, Eaglesham GK, Pierens G, et al. (1999) Deoxycylindropermopsin, an analog of cylindropermopsin from Cylindrospermopsis raciborskii. Environ Toxicol 14: 163-165. |
| [22] | Jiang Y, Xiao P, Yu G, et al. (2012) Molecular Basis and Phylogenetic Implications of Deoxycylindrospermopsin Biosynthesis in the Cyanobacterium Raphidiopsiscurvata, Appl Environ Microb 78: 2256-2263. |
| [23] | Seifert M, McGregor G, Eaglesham G, et al. (2007) First evidence for the production of cylindrospermopsin and deoxycylindrospermopsin by the freshwater benthic cyanobacterium, Lyngbyawollei (Farlow ex Gomont) Speziale and Dyck, JHarmful Algae 6: 73-80. |
| [24] | Evans DM, Murphy PJ (2011) Chapter 1—TheCylindrospermopsin Alkaloids,Elsevier.The Alkaloids: Chemistry and Biology 70: 1-77. |
| [25] |
Looper RE, Runnegar MTC, Williams RM (2006) Syntheses of the cylindrospermopsin alkaloids. Tetrahedron 62: 4549-4562. doi: 10.1016/j.tet.2006.02.044
|
| [26] |
Ríos V, Prieto AI, Cameán AM, et al. (2014) Detection of cylindrospermopsin toxin markers in cyanobacterial algal blooms using analytical pyrolysis (Py-GC/MS) and thermally-assisted hydrolysis and methylation (TCh-GC/MS). Chemosphere 108: 175-182. doi: 10.1016/j.chemosphere.2014.01.033
|
| [27] | Orr PT, Rasmussen JP, Burford MA, et al. (2011) Evaluation of quantitative real-time PCR to characterize spatial and temporal variations in cyanobacteria, Cylindrospermopsis raciborskii (Woloszynska) Seenaya et Subba Raju and cylindrospermopsin concentrations in three subtropical Australian reservoirs. Harmful Algae 9: 243-254. |
| [28] | Shihana F, Jayasekera JMKB, Dissananyake DM, et al. (2012) The short term effect of cyanobacterial toxin extracts on mice kidney. In: Symposium Proceedings, International Symposium on Water Quality and Human Health: Challenges Ahead, PGIS, Peradeniya, Sri Lanka. |
| [29] |
Davis TW, Orr PT, Boyer GL, et al. (2014) Investigating the production and release of cylindrospermopsin and deoxy-cylindrospermopsin by Cylindrospermopsis raciborskii over a natural growth cycle. Harmful Algae 31: 18-25. doi: 10.1016/j.hal.2013.09.007
|
| [30] | Dissananyake DM, Jayasekera JMKB, Ratnayake P, et al. (2012) Effect of Concentrated Water from Reservoirs of high prevalence Area for Chronic Kidney Disease (CKDu) of unknown Origin in Sri Lanka on Mice, In: Symposium Proceedings, International Symposium on Water Quality and Human Health: Challenges Ahead, PGIS, Peradeniya, Sri Lanka. |
| [31] | Saker ML, Griffiths DJ (2000) The Effect of Temperature on Growth and Cylindrospermopsiin Content of seven isolates of Cylindrospermopsis raciborskii (Nostocales, Cyanophyceae) from Water bodies in Northern Australia. Phycologia 39: 349-354. |
| [32] |
Bácsi I, Vasas G, Surányi, G, et al. (2006) Alteration of cylindrospermopsin production in sulfate- or phosphate-starved cyanobacterium Aphanizomenon ovalisporum. FEMS Microbiol Lett 259: 303-310. doi: 10.1111/j.1574-6968.2006.00282.x
|
| [33] | Preussel K, Wessel G, Fastner J, et al. (2009) Response of cylindrospermopsin production and release in Aphanizomenon flos-aquae (Cyanobacteria) to varying light and temperature conditions. Harmful Algae 6: 645-650. |
| [34] |
Dyble J, Tester PA, Litaker RW (2006) Effects of light intensity on cylindrospermopsin production in the cyanobacterial HAB species Cylindrospermopsis raciborskii. Afr J Mar Sci 28: 309-312. doi: 10.2989/18142320609504168
|
| [35] | Chiswell RK, Shaw GR, Eaglesham G, et al. (1999) Stability of cylindrospermopsin, the toxin from the cyanobacterium, Cylindrospermopsis raciborskii: effect of pH, temperature, and sunlight on decomposition. Environ Toxicol 14: 155-161. |
| [36] | Smith M, Shaw GR, Eaglesham, GK, et al. (2008) Elucidating the Factors Influencing the Biodegradation of Cylindrospermopsin in Drinking Water Sources. Environ Toxicol 23: 413-421. |
| [37] |
Burgoyne DL, Hemscheidt TK, Moore RE, et al. (2000) Biosynthesis of cylindrospermopsin. J Org Chem 65: 152-156. doi: 10.1021/jo991257m
|
| [38] |
Muenchhoff J, Siddiqui KS, Poljak A, et al. (2010) A novel prokaryotic L-arginine:glycineamidinotransferase s involved in cylindrospermopsin biosynthesis. FEBS J 277: 3844-3860. doi: 10.1111/j.1742-4658.2010.07788.x
|
| [39] |
Kellmann R, Mills T, Neilan BA (2006) Functional modeling and phylogenetic distribution of putative cylindrospermopsin biosynthesis enzymes. J Mol Evol 62: 267-280. doi: 10.1007/s00239-005-0030-6
|
| [40] | Mihali TK, Kellmann R, Muenchhoff J, et al. (2008) Characterization of the gene cluster responsible for cylindrospermopsin biosynthesis. Appl Environ Microb74: 716-722. |
| [41] |
Lagos N, Onodera H, Zagatto HPA, et al. (1999) The first evidence of paralytic shellfish toxins in the freshwater cyanobacterium Cylindrospermopsis raciborskii, isolated from Brazil. Toxicon 37: 1359-1373. doi: 10.1016/S0041-0101(99)00080-X
|
| [42] |
Schembri MA, Neilan BA, Saint CP (2001) Identification of genes implicated in toxin production in the cyanobacterium Cylindrospermopsis raciborskii. Environ Toxicol 16: 413-421. doi: 10.1002/tox.1051
|
| [43] | Shalev-Alon G, Sukenik A, Livnah O, et al. (2002) A novel gene encoding amidinotransferase in the cylindrospermopsin producing cyanobacterium Aphanizomenon ovalisporum. FEMS Microbiol Lett 209: 87-91. |
| [44] | Neilan BA, Saker ML, Fastner J, et al. (2003). Phylogeography of the invasive cyanobacterium Cylindrospermopsis raciborskii. Mol Ecol 12: 133-140. |
| [45] |
Piccini C, AubriotL, Fabre A, et al. (2011) Genetic and eco-physiological differences of South American Cylindrospermopsis raciborskii isolates support the hypothesis of multiple ecotypes. Harmful Algae 10: 644-653. doi: 10.1016/j.hal.2011.04.016
|
| [46] |
Hoff-Risseti C, Dörr FA, Schaker PDC, et al. (2013) Cylindrospermopsin and SaxitoxinSynthetase Genes in Cylindrospermopsis raciborskii Strains from Brazilian Freshwater. PLoS ONE 8: e74238. doi: 10.1371/journal.pone.0074238
|
| [47] |
Chonudomkul D, Yongmanitchaia W, Theeragool G, et al. (2004) Morphology, genetic diversity, temperature tolerance and toxicity of Cylindrospermopsis raciborskii (Nostocales, Cyanobacteria) strains from Thailand and Japan. FEMS Microbiol Ecol 48: 345-355. doi: 10.1016/j.femsec.2004.02.014
|
| [48] | Rasmussen JP, Giglio S, Monis PT, et al. (2008) Development and field testing of a real-time PCR assay for cylindrospermopsin-producing cyanobacteria. J Appl Microb 104: 1503-1515. |
| [49] | Stucken K, Murillo AA, Soto-Liebe K, et al. (2009) Toxicity phenotype does not correlate with phylogeny of Cylindrospermopsis raciborskii strains. Syst Appl Microbiol 32: 37-48. |
| [50] |
Froscio SM, Humpage AR, Burcham PC, et al. (2003) Cylindrospermopsin-induced protein synthesis inhibition and its dissociation from acute toxicity in mouse hepatocytes. Environ Toxicol 18: 243-251. doi: 10.1002/tox.10121
|
| [51] | Norris RLG, Seawright AA, Shaw GR, et al. (2001) Distribution of 14C Cylindrospermopsinin vivo in the Mouse. Environ Toxicol 16: 498-505. |
| [52] | Oliveira VR, CarvalhoGM, Avila MB, et al. (2012) Time-dependence of lung injury in mice acutely exposed to cylindrospermopsin. Toxicon 60: 764-772. |
| [53] |
Poniedziałek B, Rzymski P, Wiktorowicz K (2014) Toxicity of cylindrospermopsin in human lymphocytes: Proliferation, viability and cell cycle studies. Toxicol in vitro 28: 968-974. doi: 10.1016/j.tiv.2014.04.015
|
| [54] |
Poniedziałek B, Rzymski P, Wiktorowicz K (2014) Cylindrospermopsin decreases the oxidative burst capacity of human neutrophils. Toxicon 87: 113-119. doi: 10.1016/j.toxicon.2014.05.004
|
| [55] | Young FM, Micklem J, Humpage AR (2008) Effects of blue-green algal toxin cylindrospermopsin (CYN) on human granulosa cells in vitro. Reprod Toxicol 25: 374-380. |
| [56] | Gutiérrez-Praena D, Pichardo S, Jos, Á, et al. (2012) Biochemical and pathological toxic effects induced by the cyanotoxin Cylindrospermopsin on the human cell line Caco-2. Water Res 46: 1566-1575. |
| [57] | Stewart I, Wickramasinghe W, Carroll A, et al. (2012) The cylindrospermopsin analogue deoxycylindrospermopsin: Isolation, purification and acute toxicity in mice. 3rd National Cyanobacteria Workshop, Canberra, Australia, June 2012. Available from: http://www.waterra.com.au/publications/document-search/?download=697 |
| [58] | Štraser A, Filipič M, Novak M, et al. (2013) Double Strand Breaks and Cell-Cycle Arrest Induced by the Cyanobacterial Toxin Cylindrospermopsin in HepG2 Cells. Mar Drugs 11: 3077-3090. |
| [59] | Maire MA, Bazin E, Fessard V, et al. (2010) P. Morphological cell transformation of Syrian hamster embryo (SHE) cells by the cyanotoxin, Cylindrospermopsin. Toxicon 55: 1317-1322. |
| [60] | Rogers EH, Zehra RD, Gage MI, et al. (2007)The cyanobacterial toxin, cylindrospermopsin, induces fetal toxicity in the mouse after exposure late in gestation. Toxicon 49: 855-864. |
| [61] | Chernoff N, Rogers EH, Zehr RD, et al. (2011)Toxicity and recovery in the pregnant mouse after gestational exposure to the cyanobacterial toxin, cylindrospermopsin. J Appl Toxicol 31: 242-254. |
| [62] | Hayman J (1992) Beyond the Barcoo—probable human tropical cyanobacterial poisoning in outback Australia. Med J Aust 157: 794-796. |
| [63] | Carmichael WW, Azevedo SMFO, An JS, et al. (2001) Human fatalities from cyanobacteria: chemical and biological evidence for cyanotoxins. Environ Health Persp 109: 663-668. |
| [64] | Bokhari M, Carnachan RJ, Cameron NR, et al. (2007) Culture of HepG2 liver cells on three dimensional polystyrene scaffolds enhances cell structure and function during toxicological challenge. J Anat 211: 567-576. |
| [65] | Grainger SJ, Putnam AJ, 2011. Assessing the Permeability of Engineered Capillary Networks in a 3D Culture. Plos One 6: E22086. |
| [66] |
Angulo P (2002) Nonalcoholic fatty liver disease. New Engl J Med 346: 1221-1231. doi: 10.1056/NEJMra011775
|
| [67] |
Vanni E, Bugianesi E, Kotronen A, et al. (2010) From the metabolic syndrome to NAFLD or vice versa? Digest Liver Dis 42: 320-330. doi: 10.1016/j.dld.2010.01.016
|
| [68] |
Li ZZ, Berk M, McIntyre TM, et al. (2008) The Lysosomal-Mitochondrial Axis in Free Fatty Acid-Induced Hepatic Lipotoxicity. Hepatology 47: 1495-1503. doi: 10.1002/hep.22183
|
| [69] |
Ivanova S, Repnik U, Bojic L, et al. (2008) Lysosomes in apoptosis. Methods in Enzymology 442: 183-199. doi: 10.1016/S0076-6879(08)01409-2
|
| [70] | Goldman SDB, Funk RS, Rajewski RA, et al. (2009) Mechanisms of amine accumulation in, and egress from, lysosomes. Bioanalysis 1: 1445-1459. |
| [71] |
Anderson N, Borlak J (2006) Drug-induced phospholipidosis. FEBS Lett 580: 5533-5540. doi: 10.1016/j.febslet.2006.08.061
|
| [72] | Shayman JA, Abe A (2013) Drug induced phospholipidosis: An acquired lysosomal storage disorder. BiochimBiophys Acta 1831: 602-611. |
| [73] | Kornhuber J, Henkel AW, Groemer TW, et al. (2010) Lipophilic Cationic Drugs Increase the Permeability of Lysosomal Membranes in a Cell Culture System. J Cell Physiol 224: 152-164. |
| [74] | Saker ML, Thomas AD, Norton JH (1999) Cattle mortality attributed to the toxic cyanobacterium Cylindrospermopsis raciborskii in an outback region of North Queensland. Environ Toxicol 14: 179-182. |
| [75] | Shaw GR, McKenzie RA, Wickramasinghe WA, et al. (2002) Comparative Toxicity of the Cyanobacterial Toxin CylindrospermopsinBetween Mice and Cattle: Human Implications. In: Harmful Algae 2002. Xth International Conference on Harmful Algae, St. Pete Beach, Florida, U.S.A., 465-467. |
| [76] | Hamilton B, Whittle N, Shaw G, et al. (2010) Human fatality associated with Pacific ciguatoxin contaminated fish. Toxicon 56: 668-673. |
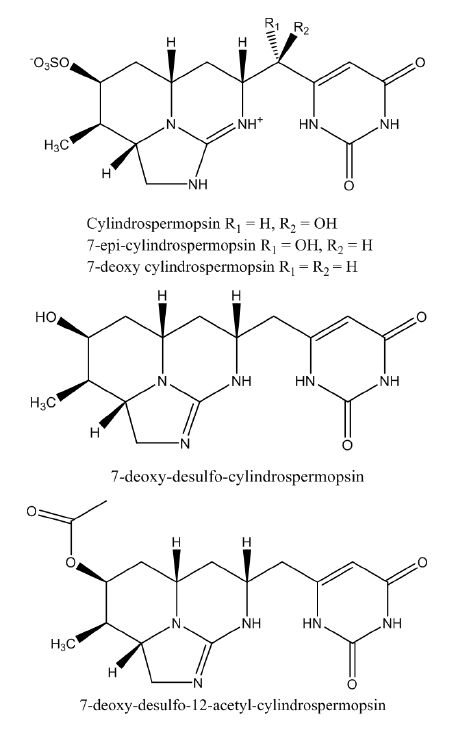
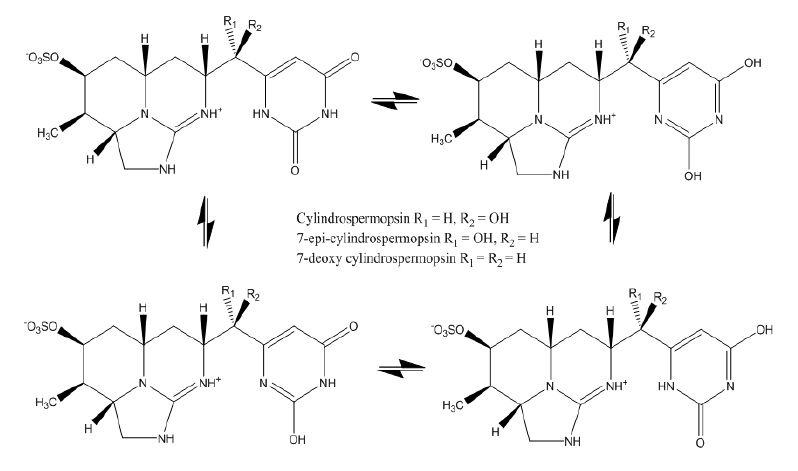

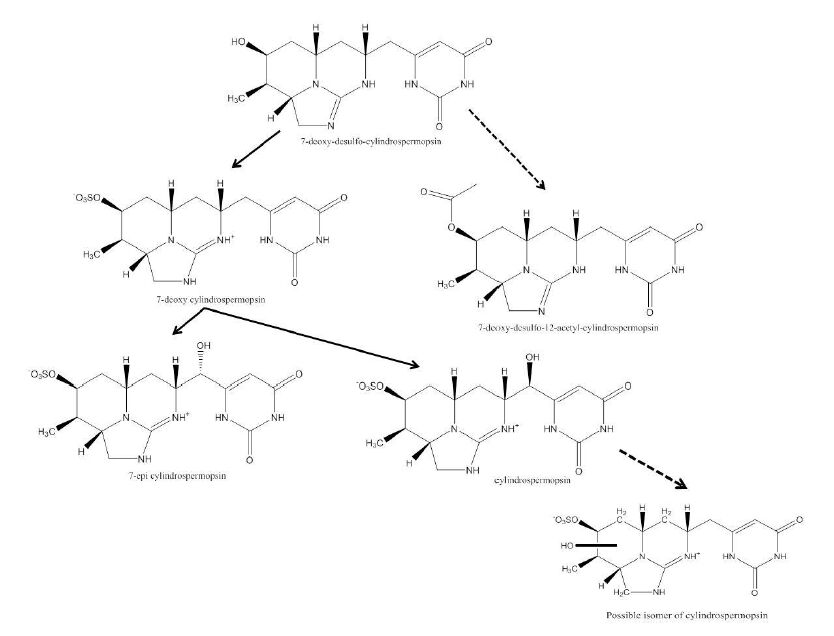
Figures(4) / Tables(3)

Ross Sadler. Towards a more complete understanding of the occurrence and toxicities of the cylindrospermopsins[J]. AIMS Environmental Science, 2015, 2(3): 827-851. doi: 10.3934/environsci.2015.3.827







 DownLoad:
DownLoad: