Citation: Merily Horwat, Meggie Tice, Birthe V. Kjellerup. Biofilms at work: Bio-, phyto- and rhizoremediation approaches for soils contaminated with polychlorinated biphenyls[J]. AIMS Bioengineering, 2015, 2(4): 324-334. doi: 10.3934/bioeng.2015.4.324

| [1] |
Sowers KR, May HD (2013) In Situ Treatment of PCBs by Anaerobic Microbial Dechlorination in Aquatic Sediment: Are We There Yet? Curr Opin Biotechnol 24: 482-488. doi: 10.1016/j.copbio.2012.10.004

|
| [2] | U.S. Environmental Protection Agency (2014) Polychlorinated Biphenyls (PCBs). Available at: http://www.epa.gov/epawaste/hazard/tsd/pcbs/. |
| [3] | World Health Organization Regional Office for Europe (1996) Air Quality Guidelines for Europe. 2nd Ed. WHO Regional Publications. |
| [4] | U.S. Department of Health and Human Services Agency for Toxic Substances and Disease Registry (2014) ATSDR Case Studies in Environmental Medicine Polychlorinated Biphenyls (PCBs) Toxicity. |
| [5] |
Khairy MA, Weinstein MP, Lohmann R (2014) Trophodynamic Behavior of Hydrophobic Organic Contaminants in the Aquatic Food Web of a Tidal River. Environ Sci Technol 48: 12533-12542. doi: 10.1021/es502886n
|
| [6] |
Wakeman TH, Themelis NJ (2001) A Basin-Wide Approach to Dredged Material Management in New York/New Jersey Harbor. J Hazard Mater 85: 1-13. doi: 10.1016/S0304-3894(01)00218-7
|
| [7] |
Kinney CA, Furlong ET, Zaugg SD, et al. (2006) Survey of Organic Wastewater Contaminants in Biosolids Destined for Land Application. Environ Sci Technol 40: 7207-7215. doi: 10.1021/es0603406
|
| [8] | Colborn T, Vom Saal FS, Soto AM (1993) Developmental Effects of Endocrine-Disrupting Chemicals in Wildlife and Humans. Environ Health Perspect 101(5): 378-384. |
| [9] | U.S. Environmental Protection Agency (2012) Superfund Site Information. Available at: http://www.epa.gov/superfund/sites/cursites/. |
| [10] | Payne RB, Fagervold SK, May HD, et al. (2013) Remediation of polychlorinated biphenyl impacted sediment by concurrent bioaugmentation with anaerobic halorespiring and aerobic degrading bactera. Environ Sci Technol 47(8): 3807-3815. |
| [11] |
Johansen HR, Alexander J, Rossland OJ, et al. (1996) PCDDs, PCDFs, and PCBs in human blood in relation to consumption of crabs from a contaminated fjord area in Norway. Environ Health Perspect 104: 756-764. doi: 10.1289/ehp.96104756
|
| [12] | Yao M, Li Z, Zhang X, et al. (2014) Polychlorinated biphenyls in the centralized wastewater Tteatment plant in a chemical industry zone: source, distribution, and removal. J Chem 2014. |
| [13] |
Fuoco R, Giannarelli S, Onor M, et al. (2012) A snow/firn four-century record of polycyclic aromatic hydrocarbons (PAHs) and polychlorobiphenyls (PCBs) at Talos Dome (Antarctica). Microchem J 105: 133-141. doi: 10.1016/j.microc.2012.05.018
|
| [14] | Fuoco R, Colombini M, Ceccarini A, et al. (1996) Polychlorobiphenyls in Antarctica. Microchem J 54(4): 384-390. |
| [15] | Kjellerup BV, Paul P, Ghosh U, et al. (2012) Spatial Distribution of PCB Dechlorinating Bacteria and Activities in Contaminated Soil. Appl Environ Soil Sci 2012. |
| [16] |
Stoodley P, Sauer K, Davies DG, et al. (2002) Biofilms as Complex Differentiated Communities. Annu Rev Microbiol 56: 187-209. doi: 10.1146/annurev.micro.56.012302.160705
|
| [17] | Leys D, Adrian L, Smidt H (2013) Organohalide respiration: microbes breathing chlorinated molecules. Philos Trans R Soc London Ser B, Biol Sci 368: 2012316. |
| [18] | Mercier A, Joulian C, Michel C, et al. (2014) Evaluation of Three Activated Carbons for Combined Adsorption and Biodegradation of PCBs in Aquatic Sediment. Water Res 59(0): 304-315. |
| [19] |
Meagher RB (2000) Phytoremediation of toxic elemental and organic pollutants. Curr Opin Plant Biol 3: 153-162. doi: 10.1016/S1369-5266(99)00054-0
|
| [20] | Mackova M, Macek T, Ocenaskova J, et al. (1997) Biodegradation of polychlorinated biphenyls by plant cells. Int Biodeterior Biodegradation 39(4): 317-325. |
| [21] |
Passatore L, Rossetti S, Juwarkar AA, et al. (2014) Phytoremediation and bioremediation of polychlorinated biphenyls (PCBs): State of knowledge and research perspectives. J Hazard Mater 278: 189-202. doi: 10.1016/j.jhazmat.2014.05.051
|
| [22] |
Zanaroli G, Negroni A, Häggblom MM, et al. (2015) Microbial dehalogenation of organohalides in marine and estuarine environments. Curr Opin Biotechnol 33: 287-295. doi: 10.1016/j.copbio.2015.03.013
|
| [23] | Cardon ZG, Gage DJ (2006) Resource Exchange in the Rhizosphere: Molecular Tools and the Microbial Perspective. Annu Rev Ecol Evol Syst 37(1): 459-488. |
| [24] | Van Aken B, Correa PA, Schnoor JL (2010) Phytoremediation of Polychlorinated Biphenyls: New Trends and Promises. Environ Sci Technol 44(8): 2767-2776. |
| [25] | Leigh MB, et al. (2006) Polychlorinated Biphenyl (PCB)-Degrading Bacteria Associated with Trees in a PCB-Contaminated Site. Appl Environ Microbiol 72(4): 2331-2342. |
| [26] | Erickson MD (1997) Analytical Chemistry of PCBs, 2 Ed. CRC Press; 90 p. |
| [27] |
Pieper DH, Seeger M (2008) Bacterial metabolism of polychlorinated biphenyls. J Mol Microbiol Biotechnol 15: 121-138. doi: 10.1159/000121325
|
| [28] |
Cooper M, et al. (2015) Anaerobic Microbial Transformation of Halogenated Aromatics and Fate Prediction Using Electron Density Modelling. Environ Sci Technol Technol 49: 6018-6028. doi: 10.1021/acs.est.5b00303
|
| [29] |
Bedard DL (2008) A Case Study for Microbial Biodegradation: Anaerobic Bacterial Reductive Dechlorination of Polychlorinated Biphenyls-From Sediment to Defined Medium. Annu Rev Microbiol 62: 253-270. doi: 10.1146/annurev.micro.62.081307.162733
|
| [30] | Vasilyeva GK, Strijakova ER (2007) Bioremediation of soils and sediments contaminated by polychlorinated biphenyls. Microbiology 76(6): 639-653. |
| [31] | Donlan RM (2002) Biofilms: microbial life on surfaces. Emerg Infect Dis 8(9): 881-890. |
| [32] | Borja J, Taleon DM, Auresenia J, et al. (2005) Polychlorinated biphenyls and their biodegradation. Process Biochem 40(6): 1999-2013. |
| [33] | Liu J, Schnoor JL (2008) Uptake and Translocation of Lesser-Chlorinated Polychlorinated Biphenyls (PCBs) in Whole Hybrid Poplar Plants after Hydroponic Exposure. Chemosphere 73(10): 1608-1616. |
| [34] |
Pilon-Smits E (2005) Phytoremediation. Annu Rev Plant Biol 56: 15-39. doi: 10.1146/annurev.arplant.56.032604.144214
|
| [35] | Rezek J, Macek T, Mackova M, et al. (2008) Hydroxy-PCBs, Methoxy-PCBs and Hydroxy-Methoxy-PCBs: Metabolites of Polychlorinated Biphenyls Formed In Vitro by Tobacco Cells. Environ Sci Technol 42(15): 5746-5751. |
| [36] |
Moeckel C, Thomas GO, Barber JL, et al. (2008) Uptake and storage of PCBs by plant cuticles. Environ Sci Technol 42: 100-105. doi: 10.1021/es070764f
|
| [37] | Wang W, Gorsuch JW, Hughes J (1997) Plants for Environmental Studies (CRC Press), p 484. |
| [38] | O'Connor GA, Kiehl D, Eiceman GA, et al. (1990) Plant uptake of sludge-borne PCBs. J Environ Qual 19: 113-118. |
| [39] |
Mackova M, et al. (2009) Phyto/rhizoremediation studies using long-term PCB-contaminated soil. Environ Sci Pollut Res 16: 817-829. doi: 10.1007/s11356-009-0240-3
|
| [40] | Campanella BF, Bock C, Schröder P (2002) Phytoremediation to increase the degradation of PCBs and PCDD/Fs. Environ Sci Pollut Res 9(1): 73-85. |
| [41] | Pivetz BE (2001) Phytoremediation of Contaminated Soil and Ground Water at Hazardous Waste Sites. U.S. Environmental Protection Agency, Office of Research and Development, Office of Solid Waste and Emergency Response. |
| [42] | Kuiper I, Lagendijk EL, Bloemberg GV, et al. (2004) Rhizoremediation: A Beneficial Plant-Microbe Interaction. Mol Plant-Microbe Interact 17(1): 6-15. |
| [43] | Hall-Stoodley L, Costerton JW, Stoodley P (2004) Bacterial biofilms: from the natural environment to infectious diseases. Nat Rev Microbiol 2(2): 95-108. |
| [44] |
Macek T, Mackova M, Kas J (2000) Exploitation of plants for the removal of organics in environmental remediation. Biotechnol Adv 18: 23-34. doi: 10.1016/S0734-9750(99)00034-8
|
| [45] |
Liang Y, Meggo R, Hu D, et al. (2015) Microbial community analysis of switchgrass planted and unplanted soil microcosms displaying PCB dechlorination. Appl Microbiol Biotechnol 99: 6515-6526. doi: 10.1007/s00253-015-6545-x
|
| [46] |
Field J, Sierra-Alvarez R (2008) Microbial transformation and degradation of polychlorinated biphenyls. Environ Pollut 155: 1-12. doi: 10.1016/j.envpol.2007.10.016
|
| [47] | Fagervold SK, Watts JEM, May HD, et al. (2005) Sequential Reductive Dechlorination of Meta-Chlorinated Polychlorinated Biphenyl Congeners in Sediment Microcosms by Two Different Chloroflexi Phylotypes. Appl Environ Microbiol 71(12): 8085-8090. |
| [48] | Vasilyeva GK, Strijakova ER, Shea PJ (2006) Proceedings of the NATO Advanced Research Workshop on Viable Methods of Soil and Water Pollution Monitoring, Protection and Remediation. Springer; p 309-322. |
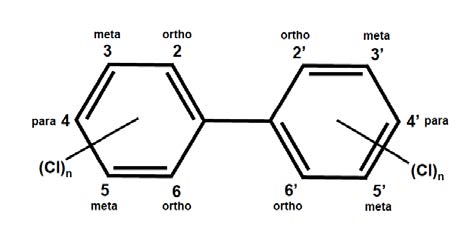
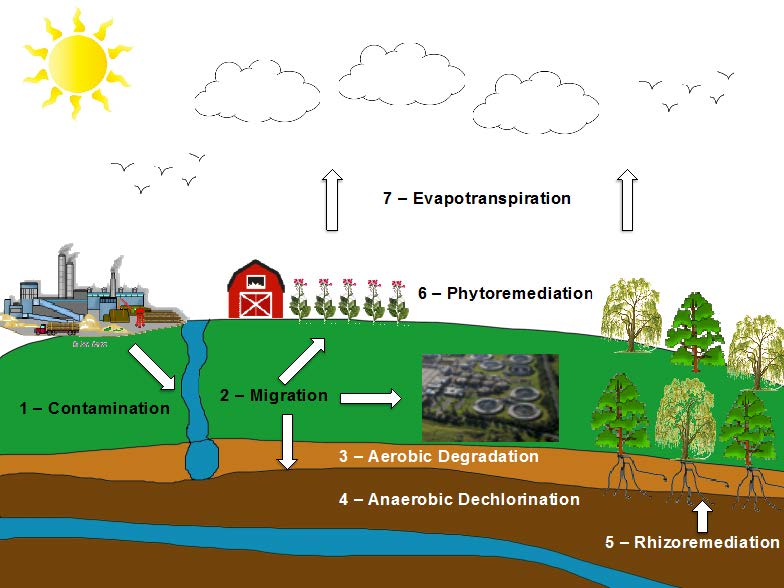
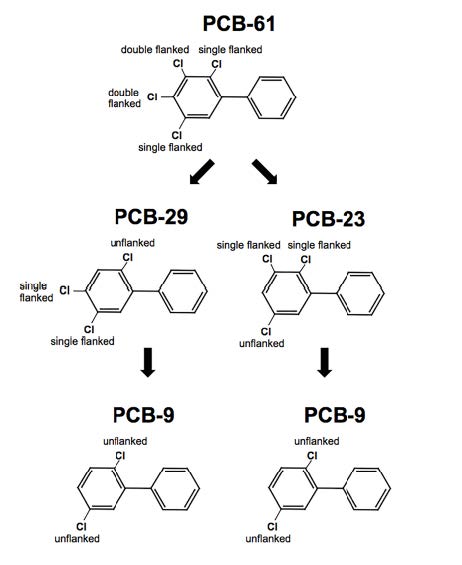
Figures(3)

Merily Horwat, Meggie Tice, Birthe V. Kjellerup. Biofilms at work: Bio-, phyto- and rhizoremediation approaches for soils contaminated with polychlorinated biphenyls[J]. AIMS Bioengineering, 2015, 2(4): 324-334. doi: 10.3934/bioeng.2015.4.324







 DownLoad:
DownLoad: