Citation: Vani H Y, Anusuya M A. Improving speech recognition using bionic wavelet features[J]. AIMS Electronics and Electrical Engineering, 2020, 4(2): 200-215. doi: 10.3934/ElectrEng.2020.2.200

| [1] |
Donoho DL (1995) De-noising by soft-thresholding. IEEE T Inform Theory 41: 613-627. doi: 10.1109/18.382009

|
| [2] |
Yao J, Zhang YT (2001) Bionic wavelet transform: A new time-frequency method based on an auditory model. IEEE T Biomed Eng 48: 856-863. doi: 10.1109/10.936362
|
| [3] |
Yao J, Zhang YT (2002) The application of bionic wavelet transforms to speech signal processing in cochlear implants using neural network simulations. IEEE T Biomed Eng 49: 1299-1309. doi: 10.1109/TBME.2002.804590
|
| [4] | Yuan XL (2003) Auditory Model-based Bionic Wavelet Transform for Speech Enhancement. A thesis submitted to the graduate school in partial fulfillment. |
| [5] |
Gold T (1948) Hearing II: The physical basis of the action of the cochlea. Proc Roy Soc B-Biol Sci 135: 492-498. doi: 10.1098/rspb.1948.0025
|
| [6] | Xi Y, Bing-wu L, Fang Y (2010) Speech enhancement using bionic wavelet transform and adaptive threshold function. Second International Conference on Computational Intelligence and Natural Computing 1: 265-268. |
| [7] |
Cohen MX (2019) A better way to define and describe Morlet wavelets for time-frequency analysis. Neuroimage 199: 81-86. doi: 10.1016/j.neuroimage.2019.05.048
|
| [8] | Valencia D, Orejuela D, Salazar J, et al. (2016) Comparison analysis between rigrsure, sqtwolog, heursure and minimaxi techniques using hard and soft thresholding methods. XXI Symposium on Signal Processing, Images and Artificial Vision (STSIVA), 1-5. |
| [9] | Garg A, Sahu OP (2019) A hybrid approach for speech enhancement using Bionic wavelet transform and Butterworth filter. International Journal of Computers and Applications, 1-11. |
| [10] |
Chen F, Zhang YT (2006) A new implementation of discrete bionic wavelet transform: Adaptive tiling. Digit Signal Process 16: 233-246. doi: 10.1016/j.dsp.2005.05.002
|
| [11] | Mourad T, Lotfi S, Sabeur A, et al. (2009) Speech Enhancement with Bionic Wavelet Transform and Recurrent Neural Network. 5th International Conference: Sciences of Electronic, Technologies of Information and Telecommunications SETIT, 22-26. |
| [12] |
Bin-Fang C, Jian-Qi L, Peixin Q, et al. (2014) An Optimization Adaptive BWT Speech Enhancement Method. Information Technology Journal 13: 1730-1736. doi: 10.3923/itj.2014.1730.1736
|
| [13] | Mourad T (2016) Speech enhancement based on stationary bionic wavelet transform and maximum a posterior estimator of magnitude-squared spectrum. International Journal of Speech Technology 20: 75-88. |
| [14] | Wu LM, Li YF, Li FJ, et al. (2014) Speech Enhancement Based on Bionic Wavelet Transform and Correlation Denoising. Advanced Materials Research, 1386-1390. |
| [15] | Ben-Nasr M, Talbi M, Cherif A (2012) Arabic Speech Recognition by MFCC and Bionic Wavelet Transform using a Multi-Layer Perceptron for Voice Control. International Journal of Software Engineering and Technology. |
| [16] | Zehtabian A, Hassanpour H, Zehtabian S, et al. (2010) A novel speech enhancement approach based on Singular Value Decomposition and Genetic Algorithm. 2010 International Conference of Soft Computing and Pattern Recognition. |
| [17] | LIU Y, NI W (2015) Speech enhancement based on bionic wavelet transform of subband spectrum entropy. Journal of Computer Applications 3: 58. |
| [18] | Singh RA, Pritamdas K (2015) Enhancement of Speech Signal by Transform Method and Various threshold Techniques: A Literature Review. Advanced Research in Electrical and Electronic Engineering 2: 5-10. |
| [19] |
Tan BT, Fu M, Spray A, et al. (1996) The use of wavelet Transforms in Phoneme Recognition. Proceeding of Fourth International Conference on Spoken Language Processing. ICSLP'96 4: 2431-2434. doi: 10.1109/ICSLP.1996.607300
|
| [20] | Rioul O, Vetterli M (1991) Wavelets and Signal Processing. IEEE SP Magazine. |
| [21] | Kobayashi M and Sakamoto M (1993) Wavelets analysis of acoustic signals. Japan SIAM Wavelet Seminars II. |
| [22] |
Jones DL, Baraniuk RG (1991) Efficient approximation of continuous wavelet transform. Electron Lett 27: 748-750. doi: 10.1049/el:19910465
|
| [23] |
Swami PD, Sharma R, Jain A, et al. (2015) Speech enhancement by noise driven adaptation of perceptual scales and thresholds of continuous wavelet transform coefficients. Speech Communication 70: 1-12. doi: 10.1016/j.specom.2015.02.007
|
| [24] |
Johnson MT, Yuan X, Ren Y (2007) Speech signal enhancement through adaptive wavelet thresholding. Speech Communication 49: 123-133. doi: 10.1016/j.specom.2006.12.002
|
| [25] | Wavelet center frequency, MATLAB centfrq, MathWorks. Available from: https://in.mathworks.com/help/wavelet/ref/centfrq.html. |
| [26] | Anusuya MA and Katti SK (2011) Front end Analysis of Speech signal processing: A Review. International Journal of speech technology, Springer. |
| [27] | GitHub. Available from: https://github.com/Jakobovski/decoupled-multimodal-learning. |
| [28] |
Hu Y and Loizou P (2007) Subjective evaluation and comparison of speech enhancement algorithms. Speech Communication 49: 588-601. doi: 10.1016/j.specom.2006.12.006
|
| [29] | Aida-zade K, Xocayev A, Rustamov S (2016) Speech recognition using Support Vector Machines. 2016 IEEE 10th International Conference on Application of Information and Communication Technologies (AICT), 1-4. |
| [30] | Mini PP, Thomas T, Gopikakumari R (2018) Feature Vector Selection of Fusion of MFCC and SMRT Coefficients for SVM Classifier Based Speech Recognition System. 2018 8th International Symposium on Embedded Computing and System Design, 153-157. |
| [31] | Thiruvengatanadhan R (2018) Speech Recognition using SVM. International Research Journal of Engineering and Technology (IRJET) 5: 918-921. |
| [32] | Zou YX, Zheng WQ, Shi W, et al. (2014) Improved Voice Activity Detection based on support vector machine with high separable speech feature vectors. 2014 19th International Conference on Digital Signal Processing. |
| [33] | Gupta A, Joshi A (2018) Speech Recognition using Artificial Neural Network. International Conference on Communication and Signal Processing, India. |
| [34] | Al-Rababah MAA, Al-Marghilani A, Hamarshi AA (2018) Automatic Detection Technique for Speech Recognition based on Neural Networks Inter-Disciplinary. (IJACSA) International Journal of Advanced Computer Science and Applications 9: 179-184. |
| [35] | Swedia ER, Mutiara AB, Subali M (2018 ) Deep Learning Long-Short Term Memory (LSTM) for Indonesian Speech Digit Recognition using LPC and MFCC Feature. Third International Conference on Informatics and Computing (ICIC). |
| [36] | Vani HY, Anusuya MA (2015) Isolated Speech recognition using K-means and FCM Technique. International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT). |
| [37] | Vani HY, Anusuya MA (2017) Noisy speech recognition using KFCM. International Conference on Cognitive Computing Information Processing. |
| [38] | ICSI Speech FAQ. Available from: https://www1.icsi.berkeley.edu/Speech/faq/speechSNR.html. |
| [39] | Yangyang S, Mei-Yuh H, Lei X (2019) END-TO-END SPEECH RECOGNITION USING A HIGH RANK LSTM-CTC BASED MODEL. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). |
| [40] | Graves A, Jaitly N (2014) Towards End-to-End Speech Recognition with Recurrent Neural Networks. Proceedings of the 31 st International Conference on Machine Learning, Beijing, China. |
| [41] |
Goehring T, Keshavarzi M, Carlyon RP, et al. (2019) Recurrent neural networks to improve the perception of speech in non-stationary noise by people with cochlear implants. J Acoust Soc Am 146: 705-718. doi: 10.1121/1.5119226
|
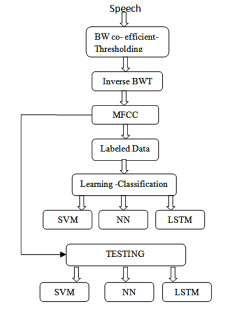
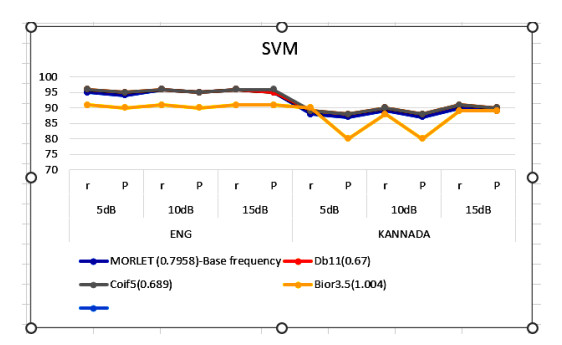
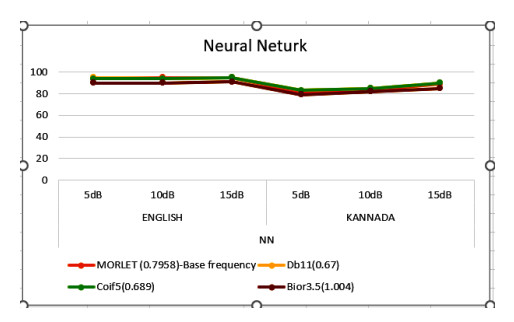
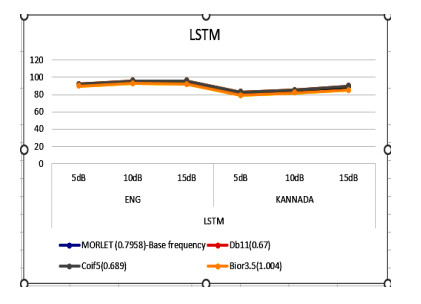
Figures(4) / Tables(8)

Vani H Y, Anusuya M A. Improving speech recognition using bionic wavelet features[J]. AIMS Electronics and Electrical Engineering, 2020, 4(2): 200-215. doi: 10.3934/ElectrEng.2020.2.200







 DownLoad:
DownLoad: