Citation: Wanda C Reygaert. An overview of the antimicrobial resistance mechanisms of bacteria[J]. AIMS Microbiology, 2018, 4(3): 482-501. doi: 10.3934/microbiol.2018.3.482

| [1] | World Health Organization (2014) World Health Statistics 2014. |
| [2] | World Health Organization (2015) Global action plan on antimicrobial resistance. |
| [3] |
Griffith M, Postelnick M, Scheetz M (2012) Antimicrobial stewardship programs: methods of operation and suggested outcomes. Expert Rev Anti-Infe 10: 63–73. doi: 10.1586/eri.11.153

|
| [4] |
Yu VL (2011) Guidelines for hospital-acquired pneumonia and health-care-associated pneumonia: a vulnerability, a pitfall, and a fatal flaw. Lancet Infect Dis 11: 248–252. doi: 10.1016/S1473-3099(11)70005-6
|
| [5] | Goossens H (2009) Antibiotic consumption and link to resistance. Clin Microbiol Infec 15 3:12–15. |
| [6] |
Pakyz AL, MacDougall C, Oinonen M, et al. (2008) Trends in antibacterial use in US academic health centers: 2002 to 2006. Arch Intern Med 168: 2254–2260. doi: 10.1001/archinte.168.20.2254
|
| [7] |
Tacconelli E (2009) Antimicrobial use: risk driver of multidrug resistant microorganisms in healthcare settings. Curr Opin Infect Dis 22: 352–358. doi: 10.1097/QCO.0b013e32832d52e0
|
| [8] |
Landers TF, Cohen B, Wittum TE, et al. (2012) A review of antibiotic use in food animals: perspective, policy, and potential. Public Health Rep 127: 4–22. doi: 10.1177/003335491212700103
|
| [9] | Wegener HC (2012) Antibiotic resistance-Linking human and animal health, In: Improving food safety through a One Health approach, Washington: National Academy of Sciences, 331–349. |
| [10] | Centers for Disease Control and Prevention (CDC) (2013) Antibiotic resistance threats in the United States, 2013, U.S, Department of Health and Human Services, CS239559-B. |
| [11] |
Maragakis LL, Perencevich EN, Cosgrove SE (2008) Clinical and economic burden of antimicrobial resistance. Expert Rev Anti-Infe 6: 751–763. doi: 10.1586/14787210.6.5.751
|
| [12] |
Filice GA, Nyman JA, Lexau C, et al. (2010) Excess costs and utilization associated with methicillin resistance for patients with Staphylococcus aureus infection. Infect Cont Hosp Ep 31: 365–373. doi: 10.1086/651094
|
| [13] |
Hübner C, Hübner NO, Hopert K, et al. (2014) Analysis of MRSA-attributed costs of hospitalized patients in Germany. Eur J Clin Microbiol 33: 1817–1822. doi: 10.1007/s10096-014-2131-x
|
| [14] |
Macedo-Viñas M, De Angelis G, Rohner P, et al. (2013) Burden of methicillin-resistant Staphylococcus aureus infections at a Swiss University hospital: excess length of stay and costs. J Hosp Infect 84: 132–137. doi: 10.1016/j.jhin.2013.02.015
|
| [15] |
Pakyz A, Powell JP, Harpe SE, et al. (2008) Diversity of antimicrobial use and resistance in 42 hospitals in the United States. Pharmacotherapy 28: 906–912. doi: 10.1592/phco.28.7.906
|
| [16] |
Sandiumenge A, Diaz E, Rodriguez A, et al. (2006) Impact of diversity of antibiotic use on the development of antimicrobial resistance. J Antimicrob Chemoth 57: 1197–1204. doi: 10.1093/jac/dkl097
|
| [17] |
Wood TK, Knabel SJ, Kwan BW (2013) Bacterial persister cell formation and dormancy. Appl Environ Microbiol 79: 7116–7121. doi: 10.1128/AEM.02636-13
|
| [18] |
Keren I, Kaldalu N, Spoering A, et al. (2004) Persister cells and tolerance to antimicrobials. FEMS Microbiol Lett 230: 13–18. doi: 10.1016/S0378-1097(03)00856-5
|
| [19] | Coculescu BI (2009) Antimicrobial resistance induced by genetic changes. J Med Life 2: 114–123. |
| [20] |
Martinez JL (2014) General principles of antibiotic resistance in bacteria. Drug Discov Today 11: 33–39. doi: 10.1016/j.ddtec.2014.02.001
|
| [21] |
Cox G, Wright GD (2013) Intrinsic antibiotic resistance: mechanisms, origins, challenges and solutions. Int J Med Microbiol 303: 287–292. doi: 10.1016/j.ijmm.2013.02.009
|
| [22] |
Fajardo A, Martinez-Martin N, Mercadillo M, et al. (2008) The neglected intrinsic resistome of bacterial pathogens. PLoS One 3: e1619. doi: 10.1371/journal.pone.0001619
|
| [23] |
Davies J, Davies D (2010) Origins and evolution of antibiotic resistance. Microbiol Mol Biol Rev 74: 417–433. doi: 10.1128/MMBR.00016-10
|
| [24] | Reygaert WC (2009) Methicillin-resistant Staphylococcus aureus (MRSA): molecular aspects of antimicrobial resistance and virulence. Clin Lab Sci 22: 115–119. |
| [25] |
Blázquez J, Couce A, Rodríguez-Beltrán J, et al. (2012) Antimicrobials as promoters of genetic variation. Curr Opin Microbiol 15: 561–569. doi: 10.1016/j.mib.2012.07.007
|
| [26] |
Chancey ST, Zähner D, Stephens DS (2012) Acquired inducible antimicrobial resistance in Gram-positive bacteria. Future Microbiol 7: 959–978. doi: 10.2217/fmb.12.63
|
| [27] | Mahon CR, Lehman DC, Manuselis G (2014) Antimicrobial agent mechanisms of action and resistance, In: Textbook of Diagnostic Microbiology, St. Louis: Saunders, 254–273. |
| [28] |
Blair JM, Richmond GE, Piddock LJ (2014) Multidrug efflux pumps in Gram-negative bacteria and their role in antibiotic resistance. Future Microbiol 9: 1165–1177. doi: 10.2217/fmb.14.66
|
| [29] |
Kumar A, Schweizer HP (2005) Bacterial resistance to antibiotics: active efflux and reduced uptake. Adv Drug Deliver Rev 57: 1486–1513. doi: 10.1016/j.addr.2005.04.004
|
| [30] |
Lambert PA (2002) Cellular impermeability and uptake of biocides and antibiotics in gram-positive bacteria and mycobacteria. J Appl Microbiol 92: 46S–54S. doi: 10.1046/j.1365-2672.92.5s1.7.x
|
| [31] |
Bébéar CM, Pereyre S (2005) Mechanisms of drug resistance in Mycoplasma pneumoniae. Curr Drug Targets 5: 263–271. doi: 10.2174/1568005054880109
|
| [32] |
Miller WR, Munita JM, Arias CA (2014) Mechanisms of antibiotic resistance in enterococci. Expert Rev Anti-Infe 12: 1221–1236. doi: 10.1586/14787210.2014.956092
|
| [33] | Gill MJ, Simjee S, Al-Hattawi K, et al. (1998) Gonococcal resistance to β-lactams and tetracycline involves mutation in loop 3 of the porin encoded at the penB locus. Antimicrob Agents Ch 42: 2799–2803. |
| [34] |
Cornaglia G, Mazzariol A, Fontana R, et al. (1996) Diffusion of carbapenems through the outer membrane of enterobacteriaceae and correlation of their activities with their periplasmic concentrations. Microb Drug Resist 2: 273–276. doi: 10.1089/mdr.1996.2.273
|
| [35] |
Chow JW, Shlaes DM (1991) Imipenem resistance associated with the loss of a 40 kDa outer membrane protein in Enterobacter aerogenes. J Antimicrob Chemoth 28: 499–504. doi: 10.1093/jac/28.4.499
|
| [36] |
Thiolas A, Bornet C, Davin-Régli A, et al. (2004) Resistance to imipenem, cefepime, and cefpirome associated with mutation in Omp36 osmoporin of Enterobacter aerogenes. Biochem Bioph Res Co 317: 851–856. doi: 10.1016/j.bbrc.2004.03.130
|
| [37] |
Mah TF (2012) Biofilm-specific antibiotic resistance. Future Microbiol 7: 1061–1072. doi: 10.2217/fmb.12.76
|
| [38] |
Soto SM (2013) Role of efflux pumps in the antibiotic resistance of bacteria embedded in a biofilm. Virulence 4: 223–229. doi: 10.4161/viru.23724
|
| [39] |
Van Acker H, Van Dijck P, Coenye T (2014) Molecular mechanisms of antimicrobial tolerance and resistance in bacterial and fungal biofilms. Trends Microbiol 22: 326–333. doi: 10.1016/j.tim.2014.02.001
|
| [40] |
Beceiro A, Tomás M, Bou G (2013) Antimicrobial resistance and virulence: a successful or deleterious association in the bacterial world? Clin Microbiol Rev 26: 185–230. doi: 10.1128/CMR.00059-12
|
| [41] |
Randall CP, Mariner KR, Chopra I, et al. (2013) The target of daptomycin is absent form Escherichia coli and other gram-negative pathogens. Antimicrob Agents Ch 57: 637–639. doi: 10.1128/AAC.02005-12
|
| [42] |
Yang SJ, Kreiswirth BN, Sakoulas G, et al. (2009) Enhanced expression of dltABCD is associated with development of daptomycin nonsusceptibility in a clinical endocarditis isolate of Staphylococcus aureus. J Infect Dis 200: 1916–1920. doi: 10.1086/648473
|
| [43] |
Mishra NN, Bayer AS, Weidenmaier C, et al. (2014) Phenotypic and genotypic characterization of daptomycin-resistant methicillin-resistant Staphylococcus aureus strains: relative roles of mprF and dlt operons. PLoS One 9: e107426. doi: 10.1371/journal.pone.0107426
|
| [44] |
Stefani S, Campanile F, Santagati M, et al. (2015) Insights and clinical perspectives of daptomycin resistance in Staphylococcus aureus: a review of the available evidence. Int J Antimicrob Agents 46: 278–289. doi: 10.1016/j.ijantimicag.2015.05.008
|
| [45] | Kumar S, Mukherjee MM, Varela MF (2013) Modulation of bacterial multidrug resistance efflux pumps of the major facilitator superfamily. Int J Bacteriol. |
| [46] |
Roberts MC (2003) Tetracycline therapy: update. Clin Infect Dis 36: 462–467. doi: 10.1086/367622
|
| [47] |
Roberts MC (2004) Resistance to macrolide, lincosamide, streptogramin, ketolide, and oxazolidinone antibiotics. Mol Biotechnol 28: 47–62. doi: 10.1385/MB:28:1:47
|
| [48] | Hawkey PM (2003) Mechanisms of quinolone action and microbial response. J Antimicrob Chemoth 1: 28–35. |
| [49] |
Redgrave LS, Sutton SB, Webber MA, et al. (2014) Fluoroquinolone resistance: mechanisms, impact on bacteria, and role in evolutionary success. Trends Microbiol 22: 438–445. doi: 10.1016/j.tim.2014.04.007
|
| [50] |
Huovinen P, Sundström L, Swedberg G, et al. (1995) Trimethoprim and sulfonamide resistance. Antimicrob Agents Ch 39: 279–289. doi: 10.1128/AAC.39.2.279
|
| [51] | Vedantam G, Guay GG, Austria NE, et al. (1998) Characterization of mutations contributing to sulfathiazole resistance in Escherichia coli. Antimicrob Agents Ch 42: 88–93. |
| [52] |
Blair JM, Webber MA, Baylay AJ, et al. (2015) Molecular mechanisms of antibiotic resistance. Nat Rev Microbiol 13: 42–51. doi: 10.1038/nrmicro3380
|
| [53] |
Ramirez MS, Tolmasky ME (2010) Aminoglycoside modifying enzymes. Drug Resist Update 13: 151–171. doi: 10.1016/j.drup.2010.08.003
|
| [54] |
Robicsek A, Strahilevitz J, Jacoby GA, et al. (2006) Fluoroquinolone-modifying enzyme: a new adaptation of a common aminoglycoside acetyltransferase. Nat Med 12: 83–88. doi: 10.1038/nm1347
|
| [55] |
Schwarz S, Kehrenberg C, Doublet B, et al. (2004) Molecular basis of bacterial resistance to chloramphenicol and florfenicol. FEMS Microbiol Rev 28: 519–542. doi: 10.1016/j.femsre.2004.04.001
|
| [56] |
Pfeifer Y, Cullik A, Witte W (2010) Resistance to cephalosporins and carbapenems in Gram-negative bacterial pathogens. Int J Med Microbiol 300: 371–379. doi: 10.1016/j.ijmm.2010.04.005
|
| [57] | Bush K, Bradford PA (2016) β-Lactams and β-lactamase inhibitors: an overview. CSH Perspect Med 6: a02527. |
| [58] |
Bush K, Jacoby GA (2010) Updated functional classification of β-lactamases. Antimicrob Agents Ch 54: 969–976. doi: 10.1128/AAC.01009-09
|
| [59] | Schultsz C, Geerlings S (2012) Plasmid-mediated resistance in Enterobacteriaceae. Drugs 72: 1–16. |
| [60] |
Bush K (2013) Proliferation and significance of clinically relevant β-lactamases. Ann NY Acad Sci 1277: 84–90. doi: 10.1111/nyas.12023
|
| [61] | Reygaert WC (2013) Antimicrobial resistance mechanisms of Staphylococcus aureus, In: Microbial pathogens and strategies for combating them: science, technology and education, Spain: Formatex, 297–310. |
| [62] |
Toth M, Antunes NT, Stewart NK, et al. (2016) Class D β-lactamases do exist in Gram-positive bacteria. Nat Chem Biol 12: 9–14. doi: 10.1038/nchembio.1950
|
| [63] |
Jacoby GA (2009) AmpC β-lactamases. Clin Microbiol Rev 22: 161–182. doi: 10.1128/CMR.00036-08
|
| [64] |
Thomson KS (2010) Extended-spectrum-β-lactamase, AmpC, and carbapenemase issues. J Clin Microbiol 48: 1019–1025. doi: 10.1128/JCM.00219-10
|
| [65] |
Lahlaoui H, Khalifa ABH, Mousa MB (2014) Epidemiology of Enterobacteriaceae producing CTX-M type extended spectrum β-lactamase (ESBL). Med Maladies Infect 44: 400–404. doi: 10.1016/j.medmal.2014.03.010
|
| [66] |
Bevan ER, Jones AM, Hawkey PM (2017) Global epidemiology of CTX-M β-lactamases: temporal and geographical shifts in genotype. J Antimicrob Chemoth 72: 2145–2155. doi: 10.1093/jac/dkx146
|
| [67] | Bajaj P, Singh NS, Virdi JS (2016) Escherichia coli β-lactamases: what really matters. Front Microbiol 7: 417. |
| [68] |
Friedman ND, Tomkin E, Carmeli Y (2016) The negative impact of antibiotic resistance. Clin Microbiol Infect 22: 416–422. doi: 10.1016/j.cmi.2015.12.002
|
| [69] |
Zhanel GG, Lawson CD, Adam H, et al. (2013) Ceftazidime-Avibactam: a novel cephalosporin/β-lactamase inhibitor combination. Drugs 73: 159–177. doi: 10.1007/s40265-013-0013-7
|
| [70] |
Bush K (2018) Game changers: new β-lactamase inhibitor combinations targeting antibiotic resistance in gram-negative bacteria. ACS Infect Dis 4: 84–87. doi: 10.1021/acsinfecdis.7b00243
|
| [71] |
Docquier JD, Mangani S (2018) An update on β-lactamase inhibitor discovery and development. Drug Resist Update 36: 13–29. doi: 10.1016/j.drup.2017.11.002
|
| [72] |
Villagra NA, Fuentes JA, Jofré MR, et al. (2012) The carbon source influences the efflux pump-mediated antimicrobial resistance in clinically important Gram-negative bacteria. J Antimicrob Chemoth 67: 921–927. doi: 10.1093/jac/dkr573
|
| [73] |
Piddock LJ (2006) Clinically relevant chromosomally encoded multidrug resistance efflux pumps in bacteria. Clin Microbiol Rev 19: 382–402. doi: 10.1128/CMR.19.2.382-402.2006
|
| [74] |
Poole K (2007) Efflux pumps as antimicrobial resistance mechanisms. Ann Med 39: 162–176. doi: 10.1080/07853890701195262
|
| [75] |
Tanabe M, Szakonyi G, Brown KA, et al. (2009) The multidrug resistance efflux complex, EmrAB from Escherichia coli forms a dimer in vitro. Biochem Bioph Res Co 380: 338–342. doi: 10.1016/j.bbrc.2009.01.081
|
| [76] |
Jo I, Hong S, Lee M, et al. (2017) Stoichiometry and mechanistic implications of the MacAB-TolC tripartite efflux pump. Biochem Bioph Res Co 494: 668–673. doi: 10.1016/j.bbrc.2017.10.102
|
| [77] |
Jonas BM, Murray BE, Weinstock GM (2001) Characterization of emeA, a norA homolog and multidrug resistance efflux pump, in Enterococcus faecalis. Antimicrob Agents Ch 45: 3574–3579. doi: 10.1128/AAC.45.12.3574-3579.2001
|
| [78] |
Truong-Bolduc QC, Dunman PM, Strahilevitz J, et al. (2005) MgrA is a multiple regulator of two new efflux pumps in Staphylococcus aureus. J Bacteriol 187: 2395–2405. doi: 10.1128/JB.187.7.2395-2405.2005
|
| [79] |
Kourtesi C, Ball AR, Huang YY, et al. (2013) Microbial efflux systems and inhibitors: approaches to drug discovery and the challenge of clinical implementation. Open Microbiol J 7: 34–52. doi: 10.2174/1874285801307010034
|
| [80] |
Costa SS, Viveiros M, Amaral L, et al. (2013) Multidrug efflux pumps in Staphylococcus aureus: an update. Open Microbiol J 7: 59–71. doi: 10.2174/1874285801307010059
|
| [81] |
Lubelski J, Konings WN, Driessen AJ (2007) Distribution and physiology of ABC-type transporters contributing to multidrug resistance in bacteria. Microbiol Mol Biol Rev 71: 463–476. doi: 10.1128/MMBR.00001-07
|
| [82] |
Putman M, van Veen HW, Konings WN (2000) Molecular properties of bacterial multidrug transporters. Microbiol Mol Biol Rev 64: 672–693. doi: 10.1128/MMBR.64.4.672-693.2000
|
| [83] |
Kuroda T, Tsuchiya T (2009) Multidrug efflux transporters in the MATE family. BBA-Proteins Proteom 1794: 763–768. doi: 10.1016/j.bbapap.2008.11.012
|
| [84] |
Rouquette-Loughlin, C, Dunham SA, Kuhn M, et al. (2003) The NorM efflux pump of Neisseria gonorrhoeae and Neisseria meningitidis recognizes antimicrobial cationic compounds. J Bacteriol 185: 1101–1106. doi: 10.1128/JB.185.3.1101-1106.2003
|
| [85] |
Bay DC, Rommens KL, Turner RJ (2008) Small multidrug resistance proteins: a multidrug transporter family that continues to grow. BBA-Biomembranes 1778: 1814–1838. doi: 10.1016/j.bbamem.2007.08.015
|
| [86] |
Yerushalmi H, Lebendiker M, Schuldiner S (1995) EmrE, an Escherichia coli 12-kDa multidrug transporter, exchanges toxic cations and H+ and is soluble in organic solvents. J Biol Chem 270: 6856–6863. doi: 10.1074/jbc.270.12.6856
|
| [87] |
Collu F, Cascella M (2013) Multidrug resistance and efflux pumps: insights from molecular dynamics simulations. Curr Top Med Chem 13: 3165–3183. doi: 10.2174/15680266113136660224
|
| [88] |
Martinez JL, Sánchez MB, Martinez-Solano L, et al. (2009) Functional role of bacterial multidrug efflux pumps in microbial natural ecosystems. FEMS Microbiol Rev 33: 430–449. doi: 10.1111/j.1574-6976.2008.00157.x
|
| [89] | Deak D, Outterson K, Powers JH, et al. (2016) Progress in the fight against multidrug-resistant bacteria? A review of U.S. Food and Drug Administration-approved antibiotics, 2010-2015. Ann Intern Med 165: 363–372. |

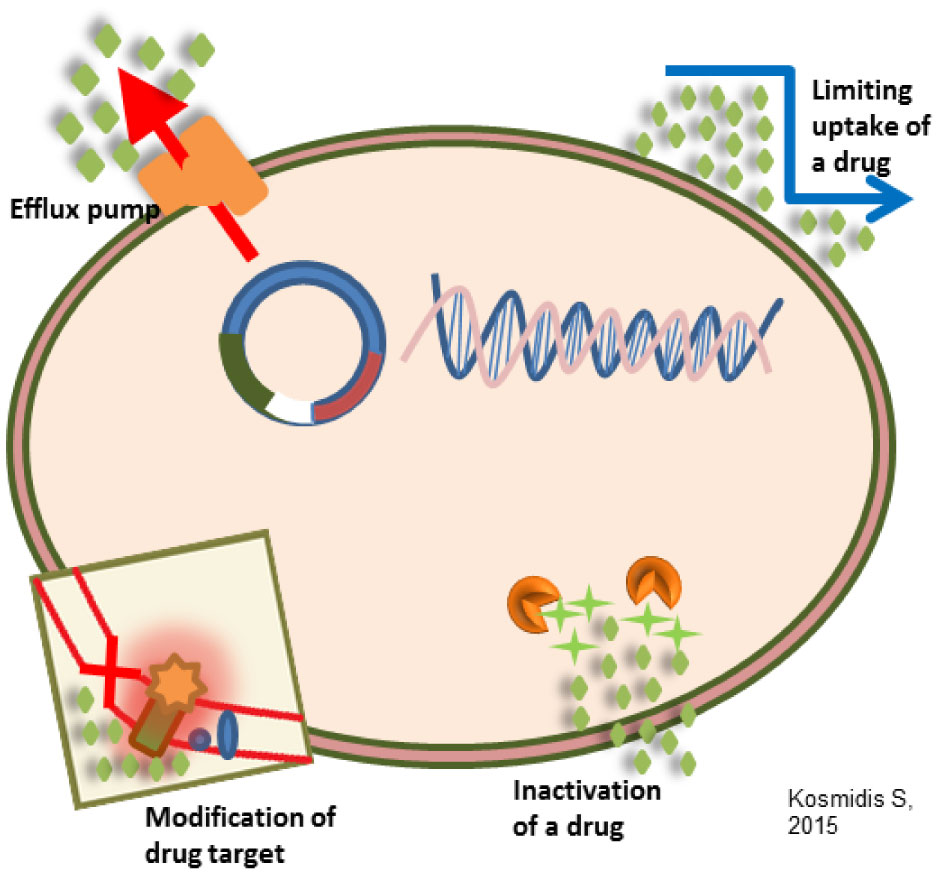
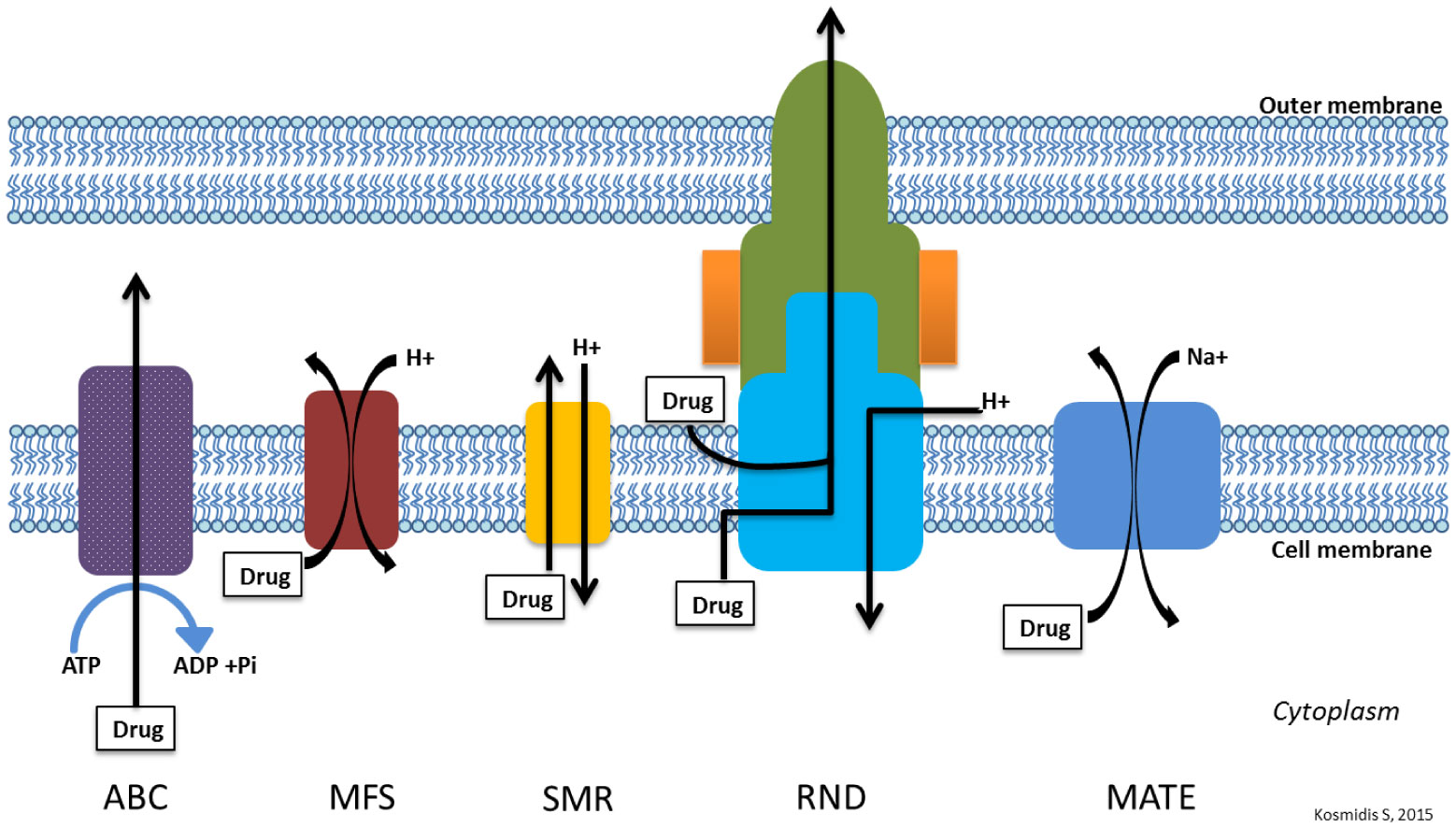
Figures(3) / Tables(4)

Wanda C Reygaert. An overview of the antimicrobial resistance mechanisms of bacteria[J]. AIMS Microbiology, 2018, 4(3): 482-501. doi: 10.3934/microbiol.2018.3.482







 DownLoad:
DownLoad: