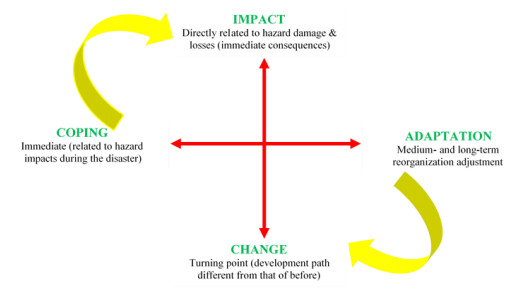
The frequency and severity of flooding in urban areas have escalated in recent years, and the worst affected urban areas are those in Africa. Despite the escalating flood risks accompanied by the growing vulnerability, cities and urban areas in Africa are struggling to build resilience. One of the actors in urban resilience building are the households in the urban settlements. Indeed, their contribution forms an important component of many flood risk response strategies. Nonetheless, the knowledge about this remains limited and is often confined to specific regions or case studies. In this study, we sought to identify the measures put in place to respond to flood risk by the households in Nyamasaria and Manyatta and explored the potential of mainstreaming resilience to flood risk in these settlements. We adopted a survey design. The settlements were purposively sampled, while the sampling procedure for the households involved transect lines established parallel to the major roads within the settlements. A transect walk was made to mark the households, and then simple random sampling was used. Data collection through personal interviews using questionnaires followed. Descriptive statistics were used to analyze the primary data. The findings showed that both settlements suffered frequent flood events, with 79 % of households having suffered inundation by floods in the past. About 46 % of the households have put in place flood risk reduction measures, including using sandbags, digging trenches around the houses, and raising floor levels. There were also cases of households temporarily relocating from the risk areas to safer places. The findings showed that the households' response measures were short-term and were aimed at addressing immediate risks. We concluded that the existence of capacities and actions to reduce flood risk among households provides a viable starting point for mainstreaming the resilience to flood risk in these settlements. We therefore recommend that households need to transition from short-term measures to risk-sensitive resilience measures, including flood-resilient designing of buildings, installation of risk-reducing infrastructure, and risk-sensitive urban planning.
Citation: Adoyo Laji, Jeremiah N. Ayonga. Mainstreaming resilience to flood risk among households in informal settlements in Kisumu City, Kenya[J]. Urban Resilience and Sustainability, 2024, 2(4): 326-347. doi: 10.3934/urs.2024017
The frequency and severity of flooding in urban areas have escalated in recent years, and the worst affected urban areas are those in Africa. Despite the escalating flood risks accompanied by the growing vulnerability, cities and urban areas in Africa are struggling to build resilience. One of the actors in urban resilience building are the households in the urban settlements. Indeed, their contribution forms an important component of many flood risk response strategies. Nonetheless, the knowledge about this remains limited and is often confined to specific regions or case studies. In this study, we sought to identify the measures put in place to respond to flood risk by the households in Nyamasaria and Manyatta and explored the potential of mainstreaming resilience to flood risk in these settlements. We adopted a survey design. The settlements were purposively sampled, while the sampling procedure for the households involved transect lines established parallel to the major roads within the settlements. A transect walk was made to mark the households, and then simple random sampling was used. Data collection through personal interviews using questionnaires followed. Descriptive statistics were used to analyze the primary data. The findings showed that both settlements suffered frequent flood events, with 79 % of households having suffered inundation by floods in the past. About 46 % of the households have put in place flood risk reduction measures, including using sandbags, digging trenches around the houses, and raising floor levels. There were also cases of households temporarily relocating from the risk areas to safer places. The findings showed that the households' response measures were short-term and were aimed at addressing immediate risks. We concluded that the existence of capacities and actions to reduce flood risk among households provides a viable starting point for mainstreaming the resilience to flood risk in these settlements. We therefore recommend that households need to transition from short-term measures to risk-sensitive resilience measures, including flood-resilient designing of buildings, installation of risk-reducing infrastructure, and risk-sensitive urban planning.

| [1] |
Prashar N, Lakra HS, Shaw R, et al. (2023) Urban flood resilience: A comprehensive review of assessment methods, tools, and techniques to manage disaster. Prog Disaster Sci 20: 100299. https://doi.org/10.1016/j.pdisas.2023.100299 doi: 10.1016/j.pdisas.2023.100299

|
| [2] |
Neves JL (2024) Urban planning for flood resilience under technical and financial constraints: The role of planners and competence development in building a flood-resilient city in Matola, Mozambique. City Environ Interact 22: 100147. https://doi.org/10.1016/j.cacint.2024.100147 doi: 10.1016/j.cacint.2024.100147
|
| [3] | Porio E (2011) Vulnerability, adaptation, and resilience to floods and climate change-related risks among marginal, riverine communities in Metro Manila. Asian J Soc Sci 39: 425–445. Available from: https://www.jstor.org/stable/43498807. |
| [4] | Laji A, Ayonga JN, Daudi F (2017) The interplay between urban development patterns and vulnerability to flood risk in Kisumu city, Kenya. J Environ Earth Sci 7: 92–99. |
| [5] |
Cobbinah PB (2021) Urban resilience in climate change hotspot. Land Use Policy 100: 104948. https://doi.org/10.1016/j.landusepol.2020.104948 doi: 10.1016/j.landusepol.2020.104948
|
| [6] | Bahadur AV, Tanner T (2022) Resilient Reset: Creating Resilient Cities in the Global South, London: Routledge. https://doi.org/10.4324/9780429355066 |
| [7] |
Brody SD, Lee Y, Highfield WE (2017) Household adjustment to flood risk: A survey of coastal residents in Texas and Florida, United States. Disasters 41: 566–586. https://doi.org/10.1111/disa.12216 doi: 10.1111/disa.12216
|
| [8] | Cao Y, Wilkinson E, Pettinotti L, et al. (2021) An Analytical Review: A Decade of Urban Resilience, New York: UNDP. Available from: https://www.undp.org/publications/analytical-review-decade-urban-resilience. |
| [9] |
Kareem B, Lwasa S, Tugume D, et al. (2020) Pathways for resilience to climate change in African cities. Environ Res Lett 15: 073002. https://doi.org/10.1088/1748-9326/ab7951 doi: 10.1088/1748-9326/ab7951
|
| [10] |
Kreibich H, Bubeck P, Van Vliet M, et al. (2015) A review of damage-reducing measures to manage fluvial flood risks in a changing climate. Mitig Adapt Strateg Glob Change 20: 967–989. http://doi.org/10.1007/s11027-014-9629-5 doi: 10.1007/s11027-014-9629-5
|
| [11] | van Valkengoed AM, Steg L (2019) Climate change adaptation by individuals and households: A psychological perspective. University of Groningen. Available from: https://gca.org. |
| [12] | Lavell A, Oppenheimer M, Diop C, et al. (2012) Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation, Cambridge: Cambridge University Press, 25–64. |
| [13] | Melissa P, Ebalu O (2012) City Resilience in Africa: A Ten Essentials Pilot, New York: UNISDR. |
| [14] | Mulligan J, Harper J, Kipkemboi P, et al. (2016) Community-responsive adaptation to flooding in Kibera, Kenya', in Proceedings of the institution of civil engineers-engineering sustainability, 170: 268–280. https://doi.org/10.1680/jensu.15.00060 |
| [15] |
Ncube S, Wilson A, Petersen L, et al. (2023) Understanding resilience capitals, agency and habitus in household experiences of water scarcity, floods and fire in marginalized settlements in the Cape Flats, South Africa. Soc Sci Humanit Open 8: 100710. https://doi.org/10.1016/j.ssaho.2023.100710 doi: 10.1016/j.ssaho.2023.100710
|
| [16] | Coaffee J, Lee P (2016) Urban Resilience: Planning for Risk, Crisis and Uncertainty, London: Palgrave. |
| [17] | Cutter SL (2021) Urban risks and resilience, In: Urban Informatics, Singapore: Springer. https://doi.org/10.1007/978-981-15-8983-6-13 |
| [18] |
Sharifi A, Yamagata Y (2014) Resilient urban planning: Major principles and criteria. Energy Procedia 61: 1491–1495. https://doi.org/10.1016/j.egypro.2014.12.154 doi: 10.1016/j.egypro.2014.12.154
|
| [19] |
Twum KO, Abubakari M (2019) Cities and floods: A pragmatic insight into the determinants of households' coping strategies to floods in informal Accra, Ghana. Jàmbá: J Disaster Risk Stud 11: 608. https://doi.org/10.4102/jamba.v11i1.608 doi: 10.4102/jamba.v11i1.608
|
| [20] |
Birkmann J (2011) First-and second-order adaptation to natural hazards and extreme events in the context of climate change. Nat Hazard 58: 811–840. https://doi.org/10.1007/s11069-011-9806-8 doi: 10.1007/s11069-011-9806-8
|
| [21] | Pelling M (2011) Adaptation to Climate Change: From Resilience to Transformation, London: Routledge. https://doi.org/10.4324/9780203889046 |
| [22] |
Forsyth T, Evans N (2013) What is autonomous adaption? Resource scarcity and smallholder agency in Thailand. World Dev 43: 56–66. https://doi.org/10.1016/j.worlddev.2012.11.010 doi: 10.1016/j.worlddev.2012.11.010
|
| [23] |
Ahsan MN (2017) Can strategies to cope with hazard shocks be explained by at-risk households' socioeconomic asset profile? Evidence from tropical cyclone-prone coastal Bangladesh. Int J Disaster Risk Sci 8: 46–63. https://doi.org/10.1007/s13753-017-0119-8 doi: 10.1007/s13753-017-0119-8
|
| [24] |
Schaer C (2015) Condemned to live with one's feet in water? A case study of community-based strategies and urban maladaptation in flood prone Pikine/Dakar, Senegal. Int J Clim Change Strategies Manage 7: 534–551. https://doi.org/10.1108/IJCCSM-03-2014-0038 doi: 10.1108/IJCCSM-03-2014-0038
|
| [25] |
Chhetri N, Stuhlmacher M, Ishtiaque A (2019) Nested pathways to adaptation. Environ Res Commun 1: 015001. https://doi.org/10.1088/2515-7620/aaf9f9 doi: 10.1088/2515-7620/aaf9f9
|
| [26] | Birkman J, Tetzlaff G, Zentel KO (2009) Addressing the Challenge: Recommendations and Quality Criteria for Linking Disaster Risk Reduction and Adaptation to Climate Change, Bonn: DKKV Publication Series. |
| [27] |
Bulkeley H, Tuts R (2013) Understanding urban vulnerability, adaptation and resilience in the context of climate change. Local Environ 18: 646–662. https://doi.org/10.1080/13549839.2013.788479 doi: 10.1080/13549839.2013.788479
|
| [28] | Glavovic BC, Smith GP (2014) Adapting to Climate Change: Lessons from Natural Hazards Planning, Dordrecht: Springer. |
| [29] |
Grothman T, Patt A (2005) Adaptive capacity and human cognition: The process of individual adaptation to climate change. Global Environ Change 15: 199–213. https://doi.org/10.1016/j.gloenvcha.2005.01.002 doi: 10.1016/j.gloenvcha.2005.01.002
|
| [30] | Ashwill M, Heltberg R (2014) Is there a Community Level Adaptation Deficit?, Washington, DC: Word Bank. |
| [31] |
Haque AN, Dodman D, Hossain MM (2014) Individual, communal and institutional responses to climate change by low-income households in Khulna, Bangladesh. Environ Urban 26: 112–129. https://doi.org/10.1177/0956247813518681 doi: 10.1177/0956247813518681
|
| [32] |
Limthongsakul S, Nitivattananon V, Arifwidodo SD (2017) Localized flooding and autonomous adaptation in peri-urban Bangkok. Environ Urban 29: 51–68. https://doi.org/10.1177/0956247816683854 doi: 10.1177/0956247816683854
|
| [33] |
Kiunsi R (2013) The constraints on climate change adaptation in a city with a large development deficit: The case of Dar es Salaam. Environ Urban 25: 321–337. https://doi.org/10.1177/0956247813489617 doi: 10.1177/0956247813489617
|
| [34] |
John R (2020) Flooding in informal Settlements: Potentials and limits for household adaptation in Dar es Salaam City, Tanzania. Am J Clim Change 9: 68–86. https://doi.org/10.4236/ajcc.2020.92006 doi: 10.4236/ajcc.2020.92006
|
| [35] | Owusu K, Obour PB (2021) Urban flooding, adaptation strategies, and resilience: Case study of Accra, Ghana, In: African Handbook of Climate Change Adaptation, Cham: Springer International Publishing, 2387–2403. https://doi.org/10.1007/978-3-030-45106-6_249 |
| [36] |
Amoako C (2017) Emerging grassroots resilience and flood responses in informal settlements in Accra, Ghana. GeoJournal 83: 949–965. https://doi.org/10.1007/s10708-017-9807-6 doi: 10.1007/s10708-017-9807-6
|
| [37] |
Hunter NB, North MA, Roberts DC, et al. (2020) A systematic map of responses to climate impacts in urban Africa. Environ Res Lett 15: 103005. https://doi.org/10.1088/1748-9326/ab9d00 doi: 10.1088/1748-9326/ab9d00
|
| [38] |
Okunola OH, Simatele MD, Olowoporoku O (2022) The influence of socioeconomic factors on individual and household adaptation strategies to climate change risks in Port Harcourt, Nigeria. J Integr Environ Sci 19: 273–288. https://doi.org/10.1080/1943815X.2022.2143821 doi: 10.1080/1943815X.2022.2143821
|
| [39] |
Twerefou DK, Adu-Danso E, Abbey E, et al. (2019) Choice of household adaptation strategies to flood risk management in Accra, Ghana. City Environ Interact 3: 100023. https://doi.org/10.1016/j.cacint.2020.100023 doi: 10.1016/j.cacint.2020.100023
|
| [40] |
Dilling L, Daly ME, Travis WR, et al. (2015) The dynamics of vulnerability: Why adapting to climate variability will not always prepare us for climate change. Wiley Interdiscip Rev Clim Change 6: 413–425. https://doi.org/10.1002/wcc.341 doi: 10.1002/wcc.341
|
| [41] |
Zevenbergen C, Gersonius B, Radhakrishan M (2020) Flood resilience. Phil Trans R Soc A 378: 1–7. https://doi.org/10.1098/rsta.2019.0212 doi: 10.1098/rsta.2019.0212
|
| [42] |
Satterthwaite D, Archer D, Colenbrander S, et al. (2020) Building resilience to climate change in informal settlements. One Earth 2: 143–156. https://doi.org/10.1016/j.oneear.2020.02.002 doi: 10.1016/j.oneear.2020.02.002
|
| [43] | Anyumba G. Kisumu town: History of the built form, planning and environment: 1890–1990, PhD Dissertation, Technische Universiteit van Delf, Netherlands, 1995. |
| [44] |
Mireri C, Atekyereza P, Kyessi A, et al. (2007) Environmental risks of urban agriculture in the Lake Victoria drainage basin: A case of Kisumu municipality, Kenya. Habitat Int 31: 375–386. https://doi.org/10.1016/j.habitatint.2007.06.006 doi: 10.1016/j.habitatint.2007.06.006
|
| [45] | Associated Programme on Flood Management (APFM) (2008) APFM Technical Document–11: Urban flood risk management. |
| [46] | Kenya National Bureau of Statistics (2019) 2019 Kenya population and housing census volume Ⅱ: Distribution of population by administrative units. Available from: https://www.knbs.or.ke/2019-kenya-population-and-housing-census-reports. |
| [47] |
Noll B, Filatova T, Need A (2022) One and done? Exploring linkages between households' intended adaptations to climate‐induced floods. Risk Anal 42: 2781–2799. https://doi.org/10.1111/risa.13897 doi: 10.1111/risa.13897
|
| [48] |
Liao KH (2012) A theory on urban resilience to floods—a basis for alternative planning practices. Ecol Soc 17: 48. http://doi.org/10.5751/ES-05231-170448 doi: 10.5751/ES-05231-170448
|
| [49] | UN Habitat (2005) Situation analysis of informal settlements in Kisumu. Available from: https://unhabitat.org/situation-analysis-of-informal-settlements-in-kisumu. |













Figures(14) / Tables(4)
Adoyo Laji, Jeremiah N. Ayonga. Mainstreaming resilience to flood risk among households in informal settlements in Kisumu City, Kenya[J]. Urban Resilience and Sustainability, 2024, 2(4): 326-347. doi: 10.3934/urs.2024017







 DownLoad:
DownLoad: