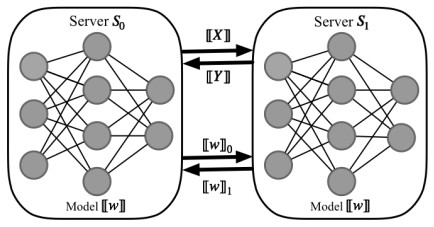
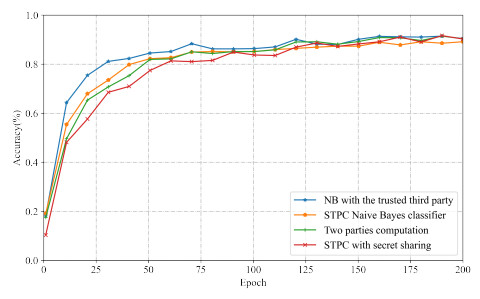
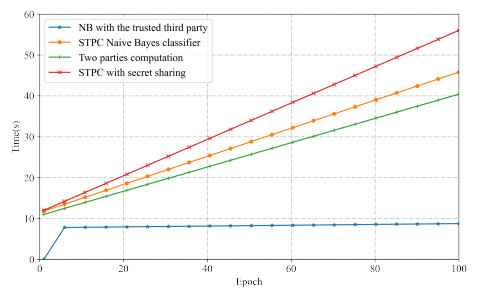
With the proliferation of data and machine learning techniques, there is a growing need to develop methods that enable collaborative training and prediction of sensitive data while preserving privacy. This paper proposes a new protocol for privacy-preserving Naive Bayes classification using secure two-party computation (STPC). The key idea is to split the training data between two non-colluding servers using STPC to train the model without leaking information. The servers secretly share their data and the intermediate computations using cryptographic techniques like Beaver's multiplication triples and Yao's garbled circuits. We implement and evaluate our protocols on the MNIST dataset, demonstrating that they achieve the same accuracy as plaintext computation with reasonable overhead. A formal security analysis in the semi-honest model shows that the scheme protects the privacy of the training data. Our work advances privacy-preserving machine learning by enabling secure outsourced Naive Bayes classification with applications such as fraud detection, medical diagnosis, and predictive analytics on confidential data from multiple entities. The modular design allows embedding different secure matrix multiplication techniques, making the framework adaptable. This line of research paves the way for practical and secure data mining in a distributed manner, upholding stringent privacy regulations.
Citation: Kun Liu, Chunming Tang. Privacy-preserving Naive Bayes classification based on secure two-party computation[J]. AIMS Mathematics, 2023, 8(12): 28517-28539. doi: 10.3934/math.20231459
With the proliferation of data and machine learning techniques, there is a growing need to develop methods that enable collaborative training and prediction of sensitive data while preserving privacy. This paper proposes a new protocol for privacy-preserving Naive Bayes classification using secure two-party computation (STPC). The key idea is to split the training data between two non-colluding servers using STPC to train the model without leaking information. The servers secretly share their data and the intermediate computations using cryptographic techniques like Beaver's multiplication triples and Yao's garbled circuits. We implement and evaluate our protocols on the MNIST dataset, demonstrating that they achieve the same accuracy as plaintext computation with reasonable overhead. A formal security analysis in the semi-honest model shows that the scheme protects the privacy of the training data. Our work advances privacy-preserving machine learning by enabling secure outsourced Naive Bayes classification with applications such as fraud detection, medical diagnosis, and predictive analytics on confidential data from multiple entities. The modular design allows embedding different secure matrix multiplication techniques, making the framework adaptable. This line of research paves the way for practical and secure data mining in a distributed manner, upholding stringent privacy regulations.

| [1] | M. Kantarcıoglu, J. Vaidya, C. Clifton, Privacy preserving Naive Bayes classifier for horizontally partitioned data, IEEE ICDM Workshop on Privacy Preserving Data Mining, 2003, 3–9. |
| [2] | J. Vaidya, C. W. Clifton, Y. M. Zhu, Privacy-preserving data mining, Vol. 19, New York: Springer, 2006. https://doi.org/10.1007/978-0-387-29489-6 |
| [3] | P. Mohassel, Y. Zhang, SecureML: a system for scalable privacy-preserving machine learning, 2017 IEEE symposium on security and privacy (SP), San Jose, CA, USA, 2017, 19–38. https://doi.org/10.1109/SP.2017.12 |
| [4] | M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, F. Koushanfar, Chameleon: a hybrid secure computation framework for machine learning applications, ASIACCS '18: Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018,707–721. https://doi.org/10.1145/3196494.3196522 |
| [5] | C. Juvekar, V. Vaikuntanathan, A. Chandrakasan, GAZELLE: a low latency framework for secure neural network inference, SEC'18: Proceedings of the 27th USENIX Conference on Security Symposium, 2018, 1651–1669. |
| [6] | M. S. Riazi, M. Samragh, H. Chen, K. Laine, K. Lauter, F. Koushanfar, XONN: XNOR-based oblivious deep neural network inference, SEC'19: Proceedings of the 28th USENIX Conference on Security Symposium, 2019, 1501–1518. |
| [7] |
R. Agrawal, R. Srikant, Privacy-preserving data mining, ACM SIGMOD Record, 2000,439–450. https://doi.org/10.1145/335191.335438 doi: 10.1145/335191.335438

|
| [8] | S. De Hoogh, B. Schoenmakers, P. Chen, H. op den Akker, Practical secure decision tree learning in a teletreatment application, In: N. Christin, R. Safavi-Naini, Financial cryptography and data security, FC 2014, Berlin, Heidelberg: Springer, 8437 (2014), 179–194. https://doi.org/10.1007/978-3-662-45472-5_12 |
| [9] | C. Choudhary, M. De Cock, R. Dowsley, A. Nascimento, D. Railsback, Secure training of extra trees classifiers over continuous data, AAAI-20 Workshop on Privacy-Preserving Artificial Intelligence, 2020. |
| [10] |
M. Abspoel, D. Escudero, N. Volgushev, Secure training of decision trees with continuous attributes, Proc. Priv. Enhancing Technol., 2021 (2021), 167–187. https://doi.org/10.2478/popets-2021-0010 doi: 10.2478/popets-2021-0010
|
| [11] | V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, N. Taft, Privacy-preserving ridge regression on hundreds of millions of records, 2013 IEEE Symposium on Security and Privacy, 2013,334–348. https://doi.org/10.1109/SP.2013.30 |
| [12] | M. de Cock, R. Dowsley, A. C. A. Nascimento, S. C. Newman, Fast, privacy preserving linear regression over distributed datasets based on pre-distributed data, AISec '15: Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security, 2015, 3–14. https://doi.org/10.1145/2808769.2808774 |
| [13] |
A. Agarwal, R. Dowsley, N. D. McKinney, D. Wu, C. T. Lin, M. De Cock, et al., Protecting privacy of users in brain-computer interface applications, IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27 (2019), 1546–1555. https://doi.org/10.1109/TNSRE.2019.2926965 doi: 10.1109/TNSRE.2019.2926965
|
| [14] |
H. Chen, R. Gilad-Bachrach, K. Han, Z. Huang, A. Jalali, K. Laine, et al., Logistic regression over encrypted data from fully homomorphic encryption, BMC Med. Genomics, 11 (2018), 81. https://doi.org/10.1186/s12920-018-0397-z doi: 10.1186/s12920-018-0397-z
|
| [15] | S. Truex, L. Liu, M. E. Gursoy, L. Yu, Privacy-preserving inductive learning with decision trees, 2017 IEEE International Congress on Big Data (BigData Congress), 2017, 57–64. https://doi.org/10.1109/BigDataCongress.2017.17 |
| [16] |
M. E. Skarkala, M. Maragoudakis, S. Gritzalis, L. Mitrou, PPDM-TAN: a privacy-preserving multi-party classifier, Computation, 9 (2021), 6. https://doi.org/10.3390/computation9010006 doi: 10.3390/computation9010006
|
| [17] | N. Agrawal, A. S. Shamsabadi, M. J. Kusner, A. Gascón, QUOTIENT: two-party secure neural network training and prediction, CCS '19: Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, 1231–1247. https://doi.org/10.1145/3319535.3339819 |
| [18] |
S. Wagh, D. Gupta, N. Chandran, SecureNN: 3-party secure computation for neural network training, Proc. Priv. Enhancing Technol., 2019 (2019), 26–49. https://doi.org/10.2478/popets-2019-0035 doi: 10.2478/popets-2019-0035
|
| [19] | C. Guo, A. Hannun, B. Knott, L. van der Maaten, M. Tygert, R. Zhu, Secure multiparty computations in floating-point arithmetic, arXiv, 2020. https://doi.org/10.48550/arXiv.2001.03192 |
| [20] |
M. De Cock, R. Dowsley, A. C. A. Nascimento, D. Railsback, J. Shen, A. Todoki, High performance logistic regression for privacy-preserving genome analysis, BMC Med. Genomics, 14 (2021), 23. https://doi.org/10.1186/s12920-020-00869-9 doi: 10.1186/s12920-020-00869-9
|
| [21] |
Y. Fan, J. Bai, X. Lei, W. Lin, Q. Hu, G. Wu, et al., PPMCK: privacy-preserving multi-party computing for k-means clustering, J. Parallel Distr. Com., 154 (2021), 54–63. https://doi.org/10.1016/j.jpdc.2021.03.009 doi: 10.1016/j.jpdc.2021.03.009
|
| [22] | Y. Lindell, B. Pinkas, Privacy preserving data mining, In: M. Bellare, Advances in cryptology–CRYPTO 2000, Lecture Notes in Computer Science, Berlin, Heidelberg: Springer, 1880 (2000), 36–54. https://doi.org/10.1007/3-540-44598-6_3 |
| [23] | E. Yilmaz, M. Al-Rubaie, J. M. Chang, Naive Bayes classification under local differential privacy, 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), 2020,709–718. https://doi.org/10.1109/DSAA49011.2020.00081 |
| [24] | H. Kargupta, S. Datta, Q. Wang, K. Sivakumar, On the privacy preserving properties of random data perturbation techniques, Third IEEE International Conference on Data Mining, 2003, 99–106. https://doi.org/10.1109/ICDM.2003.1250908 |
| [25] |
R. Bost, R. A. Popa, S. Tu, S. Goldwasser, Machine learning classification over encrypted data, NDSS, 2015. https://doi.org/10.14722/ndss.2015.23241 doi: 10.14722/ndss.2015.23241
|
| [26] | A. Wood, V. Shpilrain, K. Najarian, A. Mostashari, D. Kahrobaei, Private-key fully homomorphic encryption for private classification, In: J. Davenport, M. Kauers, G. Labahn, J. Urban, Mathematical Software–ICMS 2018, Cham: Springer, 10931 (2018), 475–481. https://doi.org/10.1007/978-3-319-96418-8_56 |
| [27] |
S. C. Rambaud, J. Hernandez-Perez, A naive justification of hyperbolic discounting from mental algebraic operations and functional analysis, Quant. Financ. Econ., 7 (2023), 463–474. https://doi.org/10.3934/QFE.2023023 doi: 10.3934/QFE.2023023
|
| [28] |
G. A. Tsiatsios, J. Leventides, E. Melas, C. Poulios, A bounded rational agent-based model of consumer choice, Data Sci. Financ. Econ., 3 (2023), 305–323. https://doi.org/10.3934/DSFE.2023018 doi: 10.3934/DSFE.2023018
|
| [29] |
Z. Li, Z. Huang, Y. Su, New media environment, environmental regulation and corporate green technology innovation: evidence from china, Energy Econ., 119 (2023), 106545. https://doi.org/10.1016/j.eneco.2023.106545 doi: 10.1016/j.eneco.2023.106545
|
| [30] |
X. Sun, P. Zhang, J. K. Liu, J. Yu, W. Xie, Private machine learning classification based on fully homomorphic encryption, IEEE Transactions on Emerging Topics in Computing, 8 (2018), 352–364. https://doi.org/10.1109/TETC.2018.2794611 doi: 10.1109/TETC.2018.2794611
|
| [31] |
A. Kjamilji, E. Savaş, A. Levi, Efficient secure building blocks with application to privacy preserving machine learning algorithms, IEEE Access, 9 (2021), 8324–8353. https://doi.org/10.1109/ACCESS.2021.3049216 doi: 10.1109/ACCESS.2021.3049216
|
| [32] |
A. Khedr, G. Gulak, V. Vaikuntanathan, Shield: scalable homomorphic implementation of encrypted data-classifiers, IEEE Transactions on Computers, 65 (2015), 2848–2858. https://doi.org/10.1109/TC.2015.2500576 doi: 10.1109/TC.2015.2500576
|
| [33] | N. Dowlin, R. Gilad-Bachrach, K. Laine, K. Lauter, M. Naehrig, John Wernsing, Cryptonets: applying neural networks to encrypted data with high throughput and accuracy, ICML'16: Proceedings of the 33rd International Conference on International Conference on Machine Learning, 48 (2016), 201–210. |
| [34] | S. Kim, M. Omori, T. Hayashi, T. Omori, L. Wang, S. Ozawa, Privacy-preserving naive Bayes classification using fully homomorphic encryption, In: L. Cheng, A. Leung, S. Ozawa, Neural Information Processing, ICONIP 2018, Cham: Springer, 11304 (2018), 349–358. https://doi.org/10.1007/978-3-030-04212-7_30 |
| [35] |
D. H. Vu, Privacy-preserving Naive Bayes classification in semi-fully distributed data model, Comput. Secur., 115 (2022), 102630. https://doi.org/10.1016/j.cose.2022.102630 doi: 10.1016/j.cose.2022.102630
|
| [36] |
D. H. Vu, T. S. Vu, T. D. Luong, An efficient and practical approach for privacy-preserving Naive Bayes classification, J. Inf. Secur. Appl., 68 (2022), 103215. https://doi.org/10.1016/j.jisa.2022.103215 doi: 10.1016/j.jisa.2022.103215
|
| [37] |
P. Li, J. Li, Z. Huang, C. Z. Gao, W. B. Chen, K. Chen, Privacy-preserving outsourced classification in cloud computing, Cluster Comput., 21 (2018), 277–286. https://doi.org/10.1007/s10586-017-0849-9 doi: 10.1007/s10586-017-0849-9
|
| [38] | C. Gentry, Fully homomorphic encryption using ideal lattices, STOC '09: Proceedings of the forty-first annual ACM symposium on Theory of computing, 2009,169–178. https://doi.org/10.1145/1536414.1536440 |
| [39] |
X. Yi, Y. Zhang, Privacy-preserving Naive Bayes classification on distributed data via semi-trusted mixers, Inf. Syst., 34 (2009), 371–380. https://doi.org/10.1016/j.is.2008.11.001 doi: 10.1016/j.is.2008.11.001
|
| [40] | A. C. Yao, Protocols for secure computations, 23rd Annual Symposium on Foundations of Computer Science (sfcs 1982), 1982,160–164. https://doi.org/10.1109/SFCS.1982.38 |
| [41] |
T. Elgamal, A public key cryptosystem and a signature scheme based on discrete logarithms, IEEE Transactions on Information Theory, 31 (1985), 469–472. https://doi.org/10.1109/TIT.1985.1057074 doi: 10.1109/TIT.1985.1057074
|
| [42] | P. Paillier, Public-key cryptosystems based on composite degree residuosity classes, In: J. Stern, Advances in cryptology–EUROCRYPT '99, Lecture Notes in Computer Science, Berlin, Heidelberg: Springer, 1592 (1999), 223–238. https://doi.org/10.1007/3-540-48910-X_16 |
| [43] |
S. Goldwasser, S. Micali, Probabilistic encryption, J. Comput. Syst. Sci., 28 (1984), 270–299. https://doi.org/10.1016/0022-0000(84)90070-9 doi: 10.1016/0022-0000(84)90070-9
|
| [44] | W. Henecka, S. Kögl, A. R. Sadeghi, T. Schneider, I. Wehrenberg, TASTY: tool for automating secure two-party computations, CCS '10: Proceedings of the 17th ACM conference on Computer and communications security, 2010,451–462. https://doi.org/10.1145/1866307.1866358 |
| [45] | A. Ben-David, N. Nisan, B. Pinkas, FairplayMP: a system for secure multi-party computation, CCS '08: Proceedings of the 15th ACM conference on Computer and communications security, 2008,257–266. https://doi.org/10.1145/1455770.1455804 |
| [46] |
X. Liu, R. H. Deng, K. K. R. Choo, Y. Yang, Privacy-preserving outsourced support vector machine design for secure drug discovery, IEEE Transactions on Cloud Computing, 8 (2020), 610–622. https://doi.org/10.1109/TCC.2018.2799219 doi: 10.1109/TCC.2018.2799219
|
| [47] |
X. Yi, Y. Zhang, Privacy-preserving Naive Bayes classification on distributed data via semi-trusted mixers, Inf. Syst., 34 (2009), 371–380. https://doi.org/10.1016/j.is.2008.11.001 doi: 10.1016/j.is.2008.11.001
|
| [48] |
H. Park, P. Kim, H. Kim, K. W. Park, Y. Lee, Efficient machine learning over encrypted data with non-interactive communication, Comput. Stand. Inter., 58 (2018), 87–108. https://doi.org/10.1016/j.csi.2017.12.004 doi: 10.1016/j.csi.2017.12.004
|
| [49] |
X. Liu, R. H. Deng, K. K. R. Choo, Y. Yang, Privacy-preserving outsourced clinical decision support system in the cloud, IEEE Transactions on Services Computing, 14 (2017), 222–234. https://doi.org/10.1109/TSC.2017.2773604 doi: 10.1109/TSC.2017.2773604
|
| [50] |
R. Podschwadt, D. Takabi, P. Hu, M. H. Rafiei, Z. Cai, A survey of deep learning architectures for privacy-preserving machine learning with fully homomorphic encryption, IEEE Access, 10 (2022), 117477–117500. https://doi.org/10.1109/ACCESS.2022.3219049 doi: 10.1109/ACCESS.2022.3219049
|
| [51] | D. Beaver, One-time tables for two-party computation, In: W. L. Hsu, M. Y. Kao, Computing and combinatorics, COCOON 1998, Berlin, Heidelberg: Springer, 1449 (1998), 361–370. https://doi.org/10.1007/3-540-68535-9_40 |
| [52] |
M. De Cock, R. Dowsley, C. Horst, R. Katti, A. C. A. Nascimento, W. S. Poon, et al., Efficient and private scoring of decision trees, support vector machines and logistic regression models based on pre-computation, IEEE Transactions on Dependable and Secure Computing, 16 (2017), 217–230. https://doi.org/10.1109/TDSC.2017.2679189 doi: 10.1109/TDSC.2017.2679189
|
| [53] | D. Reich, A. Todoki, R. Dowsley, M. De Cock, A. Nascimento, Privacy-preserving classification of personal text messages with secure multi-party computation, In: H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, R. Garnett, Advances in neural information processing systems 32, 2019, 3752–3764. |
| [54] |
A. Resende, D. Railsback, R. Dowsley, A. C. A. Nascimento, D. F. Aranha, Fast privacy-preserving text classification based on secure multiparty computation, IEEE Transactions on Information Forensics and Security, 17 (2022), 428–442. https://doi.org/10.1109/TIFS.2022.3144007 doi: 10.1109/TIFS.2022.3144007
|
| [55] | Y. Yasumura, Y. Ishimaki, H. Yamana, Secure Naïve Bayes classification protocol over encrypted data using fully homomorphic encryption, iiWAS2019: Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services, 2019, 45–54. https://doi.org/10.1145/3366030.3366056 |
| [56] | R. Canetti, Universally composable security: a new paradigm for cryptographic protocols, Proceedings 42nd IEEE Symposium on Foundations of Computer Science, 2001,136–145. https://doi.org/10.1109/SFCS.2001.959888 |
| [57] |
Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE, 86 (1998), 2278–2324. https://doi.org/10.1109/5.726791 doi: 10.1109/5.726791
|
Figures(3)

Kun Liu, Chunming Tang. Privacy-preserving Naive Bayes classification based on secure two-party computation[J]. AIMS Mathematics, 2023, 8(12): 28517-28539. doi: 10.3934/math.20231459







 DownLoad:
DownLoad: