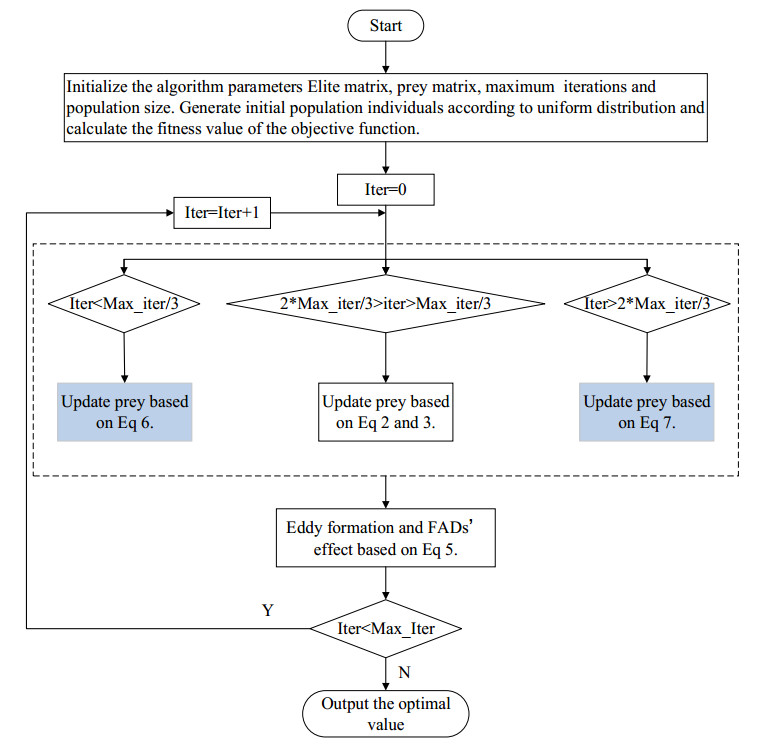
Marine Predators Algorithm (MPA) is a newly nature-inspired meta-heuristic algorithm, which is proposed based on the Lévy flight and Brownian motion of ocean predators. Since the MPA was proposed, it has been successfully applied in many fields. However, it includes several shortcomings, such as falling into local optimum easily and precocious convergence. To balance the exploitation and exploration ability of MPA, a modified marine predators algorithm hybridized with teaching-learning mechanism is proposed in this paper, namely MTLMPA. Compared with MPA, the proposed MTLMPA has two highlights. Firstly, a kind of teaching mechanism is introduced in the first phase of MPA to improve the global searching ability. Secondly, a novel learning mechanism is introduced in the third phase of MPA to enhance the chance encounter rate between predator and prey and to avoid premature convergence. MTLMPA is verified by 23 benchmark numerical testing functions and 29 CEC-2017 testing functions. Experimental results reveal that the MTLMPA is more competitive compared with several state-of-the-art heuristic optimization algorithms.
Citation: Yunpeng Ma, Chang Chang, Zehua Lin, Xinxin Zhang, Jiancai Song, Lei Chen. Modified Marine Predators Algorithm hybridized with teaching-learning mechanism for solving optimization problems[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 93-127. doi: 10.3934/mbe.2023006
Marine Predators Algorithm (MPA) is a newly nature-inspired meta-heuristic algorithm, which is proposed based on the Lévy flight and Brownian motion of ocean predators. Since the MPA was proposed, it has been successfully applied in many fields. However, it includes several shortcomings, such as falling into local optimum easily and precocious convergence. To balance the exploitation and exploration ability of MPA, a modified marine predators algorithm hybridized with teaching-learning mechanism is proposed in this paper, namely MTLMPA. Compared with MPA, the proposed MTLMPA has two highlights. Firstly, a kind of teaching mechanism is introduced in the first phase of MPA to improve the global searching ability. Secondly, a novel learning mechanism is introduced in the third phase of MPA to enhance the chance encounter rate between predator and prey and to avoid premature convergence. MTLMPA is verified by 23 benchmark numerical testing functions and 29 CEC-2017 testing functions. Experimental results reveal that the MTLMPA is more competitive compared with several state-of-the-art heuristic optimization algorithms.

| [1] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95 - International Conference on Neural Networks, 4 (1995), 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 |
| [2] |
A. H. Gandomi, A. H. Alavi, Krill herd: a new bio-inspired optimization algorithm, Commun. Nonlinear Sci. Numer. Simul., 17 (2012), 4831–4845. https://doi.org/10.1016/j.cnsns.2012.05.010 doi: 10.1016/j.cnsns.2012.05.010

|
| [3] |
A. H. Gandomi, X. Yang, A. H. Alavi, Cuckoo search algorithm: a metaheuristic approach to solve structural optimization problems, Eng. Comput., 29 (2013), 17–35. https://doi.org/10.1007/s00366-011-0241-y doi: 10.1007/s00366-011-0241-y
|
| [4] |
S. Mirjalili, S. M. Mirjalili, A. Lewis, Grey wolf optimizer, Adv. Eng. Software, 69 (2014), 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 doi: 10.1016/j.advengsoft.2013.12.007
|
| [5] |
R. V. Rao, V. J. Savsani, D. P. Vakharia, Teaching–learning-based optimization: a novel method for constrained mechanical design optimization problems, Comput.-Aided Des., 43 (2011), 303–315. https://doi.org/10.1016/j.cad.2010.12.015 doi: 10.1016/j.cad.2010.12.015
|
| [6] |
S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Software, 95 (2016), 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 doi: 10.1016/j.advengsoft.2016.01.008
|
| [7] |
A. Faramarzi, M. Heidarinejad, S. Mirjalili, A. Gandomi, Marine predators algorithm: a nature-inspired metaheuristic, Expert Syst. Appl., 152 (2020), 113377. https://doi.org/10.1016/j.eswa.2020.113377 doi: 10.1016/j.eswa.2020.113377
|
| [8] |
J. Sarvaiya, D. Singh, Selection of the optimal process parameters in friction stir welding/processing using particle swarm optimization algorithm, Mater. Today: Proc., 62 (2022), 896–901. https://doi.org/10.1016/j.matpr.2022.04.062 doi: 10.1016/j.matpr.2022.04.062
|
| [9] |
Z. Hu, H. Norouzi, M. Jiang, S. Dadfar, T. Kashiwagi, Novel hybrid modified krill herd algorithm and fuzzy controller based MPPT to optimally tune the member functions for PV system in the three-phase grid-connected mode, ISA trans., 2022 (2022). https://doi.org/10.1016/j.isatra.2022.02.009 doi: 10.1016/j.isatra.2022.02.009
|
| [10] |
Q. Bai, H. Li, The application of hybrid cuckoo search-grey wolf optimization algorithm in optimal parameters identification of solid oxide fuel cell, Int. J. Hydrogen Energy, 47 (2022), 6200–6216. https://doi.org/10.1016/j.ijhydene.2021.11.216 doi: 10.1016/j.ijhydene.2021.11.216
|
| [11] |
C. Song, X. Wang, Z. Liu, H. Chen, Evaluation of axis straightness error of shaft and hole parts based on improved grey wolf optimization algorithm, Measurement, 188 (2022), 110396. https://doi.org/10.1016/j.measurement.2021.110396 doi: 10.1016/j.measurement.2021.110396
|
| [12] |
H. Abaeifar, H. Barati, A. R. Tavakoli, Inertia-weight local-search-based TLBO algorithm for energy management in isolated micro-grids with renewable resources, Int. J. Electr. Power Energy Syst., 137 (2022), 107877. https://doi.org/10.1016/j.ijepes.2021.107877 doi: 10.1016/j.ijepes.2021.107877
|
| [13] |
V. K. Jadoun, G. R. Prashanth, S. S. Joshi, K. Narayanan, H. Malik, F. García Márquez, Optimal fuzzy based economic emission dispatch of combined heat and power units using dynamically controlled Whale Optimization Algorithm, Appl. Energy, 315 (2022), 119033. https://doi.org/10.1016/j.apenergy.2022.119033 doi: 10.1016/j.apenergy.2022.119033
|
| [14] |
M. Al-qaness, A. Ewees, H. Fan, L. Abualigah, M. Elaziz, Boosted ANFIS model using augmented marine predator algorithm with mutation operators for wind power forecasting, Appl. Energy, 314 (2022), 118851. https://doi.org/10.1016/j.apenergy.2022.118851 doi: 10.1016/j.apenergy.2022.118851
|
| [15] |
M. Al-qaness, A. Ewees, H. Fan, A. Airassas, M. Elaziz, Modified aquila optimizer for forecasting oil production, Geo-spatial Inf. Sci., 2022 (2022), 1–17. https://doi.org/10.1080/10095020.2022.2068385 doi: 10.1080/10095020.2022.2068385
|
| [16] |
A. Dahou, M. Al-qaness, M. Elaziz, A. Helmi, Human activity recognition in IoHT applications using Arithmetic Optimization Algorithm and deep learning, Measurement, 199 (2022), 111445. https://doi.org/10.1016/j.measurement.2022.111445 doi: 10.1016/j.measurement.2022.111445
|
| [17] |
M. Elaziz, A. Ewees, M. Al-qaness, L. Abualigah, R. Ibrahim, Sine–Cosine-Barnacles Algorithm Optimizer with disruption operator for global optimization and automatic data clustering, Expert Syst. Appl., 207 (2022), 117993. https://doi.org/10.1016/j.eswa.2022.117993 doi: 10.1016/j.eswa.2022.117993
|
| [18] |
X. Chen, X. Qi, Z. Wang, C. Cui, B. Wu, Y. Yang, Fault diagnosis of rolling bearing using marine predators algorithm-based support vector machine and topology learning and out-of-sample embedding, Measurement, 176 (2021), 109116. https://doi.org/10.1016/j.measurement.2021.109116 doi: 10.1016/j.measurement.2021.109116
|
| [19] |
P. H. Dinh, A novel approach based on three-scale image decomposition and marine predators algorithm for multi-modal medical image fusion, Biomed. Signal Process. Control, 67 (2021), 102536. https://doi.org/10.1016/j.bspc.2021.102536 doi: 10.1016/j.bspc.2021.102536
|
| [20] |
M. A. Sobhy, A. Y. Abdelaziz, H. M. Hasanien, M. Ezzat, Marine predators algorithm for load frequency control of modern interconnected power systems including renewable energy sources and energy storage units, Ain Shams Eng. J., 12 (2021), 3843–3857. https://doi.org/10.1016/j.asej.2021.04.031 doi: 10.1016/j.asej.2021.04.031
|
| [21] |
A. Faramarzi, M. Heidarinejad, S. Mirjalili, A. Gandomi, Marine predators algorithm: a nature-inspired metaheuristic, Expert Syst. Appl., 152 (2020), 113377. https://doi.org/10.1016/j.eswa.2020.113377 doi: 10.1016/j.eswa.2020.113377
|
| [22] |
M. A. Elaziz, D. Mohammadi, D. Oliva, K. Salimifard, Quantum marine predators algorithm for addressing multilevel image segmentation, Appl. Soft Comput., 110 (2021), 107598. https://doi.org/10.1016/j.asoc.2021.107598 doi: 10.1016/j.asoc.2021.107598
|
| [23] |
M. Ramezani, D. Bahmanyar, N. Razmjooy, A new improved model of marine predator algorithm for optimization problems, Arabian J. Sci. Eng., 46 (2021), 8803–8826. https://doi.org/10.1007/s13369-021-05688-3 doi: 10.1007/s13369-021-05688-3
|
| [24] |
M. Abdel-Basset, D. El-Shahat, R. K. Chakrabortty, M. Ryan, Parameter estimation of photovoltaic models using an improved marine predators algorithm, Energy Convers. Manage., 227 (2021), 113491. https://doi.org/10.1016/j.enconman.2020.113491 doi: 10.1016/j.enconman.2020.113491
|
| [25] |
K. Zhong, G. Zhou, W. Deng, Y. Zhou, Q. Luo, MOMPA: multi-objective marine predator algorithm, Comput. Methods Appl. Mech. Eng., 385 (2021), 114029. https://doi.org/10.1016/j.cma.2021.114029 doi: 10.1016/j.cma.2021.114029
|
| [26] |
R. Sowmya, V. Sankaranarayanan, Optimal vehicle-to-grid and grid-to-vehicle scheduling strategy with uncertainty management using improved marine predator algorithm, Comput. Electr. Eng., 100 (2022), 107949. https://doi.org/10.1016/j.compeleceng.2022.107949 doi: 10.1016/j.compeleceng.2022.107949
|
| [27] |
E. H. Houssein, I. E. Ibrahim, M. Kharrich, S. Kamel, An improved marine predators algorithm for the optimal design of hybrid renewable energy systems, Eng. Appl. Artif. Intell., 110 (2022), 104722. https://doi.org/10.1016/j.engappai.2022.104722 doi: 10.1016/j.engappai.2022.104722
|
| [28] |
D. Yousri, A. Ousama, Y. Shaker, A. Fathy, T. Babu, H. Rezk, et al., Managing the exchange of energy between microgrid elements based on multi-objective enhanced marine predators algorithm, Alexandria Eng. J., 61 (2022), 8487–8505. https://doi.org/10.1016/j.aej.2022.02.008 doi: 10.1016/j.aej.2022.02.008
|
| [29] |
Y. Ma, X. Zhang, J. Song, L. Chen, A modified teaching–learning-based optimization algorithm for solving optimization problem, Knowledge-Based Syst., 212 (2020), 106599. https://doi.org/10.1016/j.knosys.2020.106599 doi: 10.1016/j.knosys.2020.106599
|
| [30] |
N. E. Humphries, N. Queiroz, J. Dyer, N. Pade, M. Musyl, K. Schaefer, et al., Environmental context explains Lévy and Brownian movement patterns of marine predators, Nature, 465 (2010), 1066–1069. https://doi.org/10.1038/nature09116 doi: 10.1038/nature09116
|
| [31] |
D. W. Sims, E. J. Southall, N. E. Humphries, G. Hays, C. Bradshaw, J. Pitchford, et al., Scaling laws of marine predator search behaviour, Nature, 451 (2008), 1098–1102. https://doi.org/10.1038/nature06518 doi: 10.1038/nature06518
|
| [32] |
G. M. Viswanathan, E. P. Raposo, M. Luz, Lévy flights and superdiffusion in the context of biological encounters and random searches, Phys. Life Rev., 5 (2008), 133–150. https://doi.org/10.1016/j.plrev.2008.03.002 doi: 10.1016/j.plrev.2008.03.002
|
| [33] |
F. Bartumeus, J. Catalan, U. L. Fulco, M. Lyra, G. Viswanathan, Optimizing the encounter rate in biological interactions: Lévy versus Brownian strategies, Phys. Rev. Lett., 88 (2002), 097901. https://doi.org/10.1103/PhysRevLett.88.097901 doi: 10.1103/PhysRevLett.88.097901
|
| [34] |
A. Einstein, Investigations on the theory of the brownian movement, DOVER, 35 (1956), 318–320. https://doi.org/10.2307/2298685 doi: 10.2307/2298685
|
| [35] |
J. D. Filmalter, L. Dagorn, P. D. Cowley, M. Taquet, First descriptions of the behavior of silky sharks, Carcharhinus falciformis, around drifting fish aggregating devices in the Indian Ocean, Bull. Mar. Sci., 87 (2011), 325–337. https://doi.org/10.5343/bms.2010.1057 doi: 10.5343/bms.2010.1057
|
| [36] |
D. Yousri, H. M. Hasanien, A. Fathy, Parameters identification of solid oxide fuel cell for static and dynamic simulation using comprehensive learning dynamic multi-swarm marine predators algorithm, Energy Convers. Manage., 228 (2021), 113692. https://doi.org/10.1016/j.enconman.2020.113692 doi: 10.1016/j.enconman.2020.113692
|
| [37] |
M. Abdel-Basset, R. Mohamed, S. Mirjalili, R. Chakrabortty, M. Ryan, An efficient marine predators algorithm for solving multi-objective optimization problems: analysis and validations, IEEE Access, 9 (2021), 42817–42844. https://doi.org/10.1109/ACCESS.2021.3066323 doi: 10.1109/ACCESS.2021.3066323
|
| [38] |
T. Niknam, R. Azizipanah-Abarghooee, M. R. Narimani, A new multi objective optimization approach based on TLBO for location of automatic voltage regulators in distribution systems, Eng. Appl. Artif. Intell., 25 (2012), 1577–1588. https://doi.org/10.1016/j.engappai.2012.07.004 doi: 10.1016/j.engappai.2012.07.004
|
| [39] |
T. Niknam, F. Golestaneh, M. S. Sadeghi, θ-Multiobjective teaching–learning-based optimization for dynamic economic emission dispatch, IEEE Syst. J., 6 (2012), 341–352. https://doi.org/10.1109/JSYST.2012.2183276 doi: 10.1109/JSYST.2012.2183276
|
| [40] |
R. V. Rao, V. Patel, An improved teaching-learning-based optimization algorithm for solving unconstrained optimization problems, Sci. Iran., 20 (2013), 710–720. https://doi.org/10.1016/j.scient.2012.12.005 doi: 10.1016/j.scient.2012.12.005
|
| [41] |
P. K. Roy, S. Bhui, Multi-objective quasi-oppositional teaching learning based optimization for economic emission load dispatch problem, Int. J. Electr.Power Energy Syst., 53 (2013), 937–948. https://doi.org/10.1016/j.ijepes.2013.06.015 doi: 10.1016/j.ijepes.2013.06.015
|
| [42] |
H. Bouchekara, M. A. Abido, M. Boucherma, Optimal power flow using teaching-learning-based optimization technique, Electr. Power Syst. Res., 114 (2014), 49–59. https://doi.org/10.1016/j.epsr.2014.03.032 doi: 10.1016/j.epsr.2014.03.032
|
| [43] |
M. Liu, X. Yao, Y. Li, Hybrid whale optimization algorithm enhanced with Lévy flight and differential evolution for job shop scheduling problems, Appl. Soft Comput., 87 (2020), 105954. https://doi.org/10.1016/j.asoc.2019.105954 doi: 10.1016/j.asoc.2019.105954
|
| [44] |
D. Tansui, A. Thammano, Hybrid nature-inspired optimization algorithm: hydrozoan and sea turtle foraging algorithms for solving continuous optimization problems, IEEE Access, 8 (2020), 65780–65800. https://doi.org/10.1109/ACCESS.2020.2984023 doi: 10.1109/ACCESS.2020.2984023
|
| [45] |
K. Zhong, Q. Luo, Y. Zhou, M. Jiang, TLMPA: teaching-learning-based marine predators algorithm, AIMS Math., 6 (2021), 1395–1442. https://doi.org/10.3934/math.2021087 doi: 10.3934/math.2021087
|





































Figures(38) / Tables(11)

Yunpeng Ma, Chang Chang, Zehua Lin, Xinxin Zhang, Jiancai Song, Lei Chen. Modified Marine Predators Algorithm hybridized with teaching-learning mechanism for solving optimization problems[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 93-127. doi: 10.3934/mbe.2023006







 DownLoad:
DownLoad: