Citation: Fumiaki Uchiumi, Akira Sato, Masashi Asai, Sei-ichi Tanuma. An NAD+ dependent/sensitive transcription system: Toward a novel anti-cancer therapy[J]. AIMS Molecular Science, 2020, 7(1): 12-28. doi: 10.3934/molsci.2020002

| [1] |
Kandoth C, McLellan MD, Vandin F, et al. (2013) Mutational landscape and significance across 12 major cancer types. Nature 502: 333-339. doi: 10.1038/nature12634

|
| [2] |
Rahman N (2014) Realizing the promise of cancer predisposition genes. Nature 505: 302-308. doi: 10.1038/nature12981
|
| [3] |
Aronson S, Rehm H (2015) Building the foundation for genomics in precision medicine. Nature 526: 336-342. doi: 10.1038/nature15816
|
| [4] | Wishart DS, Mandal R, Stanislaus A, et al. (2016) Cancer metabolomics and the human metabolome database. Metabolomics 6: E10. |
| [5] |
Warburg O (1956) On the origin of cancer cells. Science 123: 309-314. doi: 10.1126/science.123.3191.309
|
| [6] |
Vander Heiden MG, Cantley LC, Thompson CB (2009) Understanding the Warburg effect: The metabolic requirements of cell proliferation. Science 324: 1029-1033. doi: 10.1126/science.1160809
|
| [7] |
Seyfried TN, Flores RE, Poff AM, et al. (2014) Cancer as a metabolic disease: implications for novel therapeutics. Carcinogenesis 35: 515-527. doi: 10.1093/carcin/bgt480
|
| [8] |
Seyfried TN (2015) Cancer as a mitochondrial metabolic disease. Front Cell Develop Biol 3: 43. doi: 10.3389/fcell.2015.00043
|
| [9] |
Vafai SB, Mootha VK (2012) Mitochondrial disorders as windows into an ancient organelle. Nature 491: 374-383. doi: 10.1038/nature11707
|
| [10] |
Zhang J, Pavlova NN, Thompson CB (2017) Cancer cell metabolism: the essential role of the nonessential amino acid, glutamine. EMBO J 36: 1302-1315. doi: 10.15252/embj.201696151
|
| [11] |
Clunton AA, Lukey MJ, Cerione RA, et al. (2017) Glutamine metabolism in cancer: understanding the heterogeneity. Trends Cancer 3: 169-180. doi: 10.1016/j.trecan.2017.01.005
|
| [12] |
Martinez-Outschoorn UE, Peiris-Pagés M, Pestell RG, et al. (2017) Cancer metabolism: a therapeutic perspective. Nat Rev Clin Oncol 14: 11-31. doi: 10.1038/nrclinonc.2016.60
|
| [13] |
Spinelli JB, Yoon H, Ringel AE, et al. (2017) Metabolic recycling of ammonia via glutamate dehydrogenase supports breast cancer biomass. Science 358: 941-946. doi: 10.1126/science.aam9305
|
| [14] |
Mattaini KR, Sullivan MR, Vander Heiden MG (2016) The importance of serine metabolism in cancer. J Cell Biol 214: 249-257. doi: 10.1083/jcb.201604085
|
| [15] | Danenberg PV (1977) Thymidylate synthetase—A target enzyme in cancer chemotherapy. Biochim Biophys Acta 473: 73-92. |
| [16] |
Mathews CK (2015) Deoxyribonucleotide metabolism, mutagenesis and cancer. Nat Rev Cancer 15: 528-539. doi: 10.1038/nrc3981
|
| [17] |
Irwin CR, Hitt MM, Evans DH (2017) Targeting nucleotide biosynthesis: a strategy for improving the oncolytic potential of DNA viruses. Front Oncol 7: 229. doi: 10.3389/fonc.2017.00229
|
| [18] |
Shay JW (2016) Role of telomeres and telomerase in aging and cancer. Cancer Discovery 6: 584-593. doi: 10.1158/2159-8290.CD-16-0062
|
| [19] |
Sahin E, Colla S, Liesa M, et al. (2011) Telomere dysfunction induces metabolic and mitochondrial compromise. Nature 470: 359-365. doi: 10.1038/nature09787
|
| [20] |
Houtkooper RH, Mouchiroud L, Ryu D, et al. (2013) Mitochondrial protein imbalance as a conserved longevity mechanism. Nature 497: 451-457. doi: 10.1038/nature12188
|
| [21] |
Vogelstein B, Papadopoulos N, Velculescu VE, et al. (2013) Cancer genome landscapes. Science 339: 1546-1558. doi: 10.1126/science.1235122
|
| [22] | Gasparre G, Porcelli AM, Lenaz G, et al. (2014) Relevance of mitochondrial genetics and metabolism in cancer development. Mitochondria Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press, 235-251. |
| [23] |
Troulinaki K, Bano D (2012) Mitochondrial deficiency: a double-edged sword for aging and neurodegeneration. Front Genet 3: 244. doi: 10.3389/fgene.2012.00244
|
| [24] | Bender DA (2014) Micronutrients. Introduction to nutrition and metabolism Boca Raton, NW: CRC Press, Taylor & Francis Group, 343-349. |
| [25] |
Gholson RK (1966) The pyridine nucleotide cycle. Nature 212: 933-935. doi: 10.1038/212933a0
|
| [26] |
Rechsteiner M, Catanzarite V (1974) The biosynthesis and turnover of nicotinamide adenine dinucleotide in enucleated culture cells. J Cell Physiol 84: 409-422. doi: 10.1002/jcp.1040840309
|
| [27] |
Tanuma S, Sato A, Oyama T, et al. (2016) New insights into the roles of NAD+-poly (ADP-ribose) metabolism and poly (ADP-ribose) glycohydrolase. Curr Protein Pep Sci 17: 668-682. doi: 10.2174/1389203717666160419150014
|
| [28] |
Chen YR (2013) Mitochondrial dysfunction. Basis of oxidative stress: chemistry, mechanisms, and disease pathogenesis Hoboken, NJ: John Wiley & Sons, Inc, 123-135. doi: 10.1002/9781118355886.ch6
|
| [29] | Wünschiers R (2012) Carbohydrate Metabolism and Citrate Cycle. Biochemical Pathways: An Atlas of Biochemistry and Molecular Biology, 2nd ed Hoboken, NJ: John Wiley & Sons, Inc, 37-58. |
| [30] | Wünschiers R (2012) Nucleotides and Nucleosides. Biochemical Pathways: An Atlas of Biochemistry and Molecular Biology Hoboken, NJ: John Wiley & Sons, Inc, 124-133. |
| [31] |
Chaudhuri AR, Nussenzweig A (2017) The multifaceted roles of PARP1 in DNA repair and chromatin remodeling. Nat Rev Mol Cell Biol 18: 610-621. doi: 10.1038/nrm.2017.53
|
| [32] |
Maruta H, Okita N, Takasawa R, et al. (2007) The Involvement of ATP produced via (ADP-ribose) (n) in the maintenance of DNA replication apparatus during DNA Repair. Biol Pharm Bull 30: 447-450. doi: 10.1248/bpb.30.447
|
| [33] |
Wright RH, Lioutas A, Le Dily F, et al. (2016) ADP-ribose-derived nuclear ATP synthesis by NUDIX5 is required for chromatin remodeling. Science 352: 1221-1225. doi: 10.1126/science.aad9335
|
| [34] |
German NJ, Haigis MC (2015) Sirtuins and the metabolic hurdles in cancer. Current Biol 25: R569-R583. doi: 10.1016/j.cub.2015.05.012
|
| [35] |
O'Callaghan C, Vassilopoulos A (2017) Sirtuins at the crossroads of stemness, aging, and cancer. Aging Cell 16: 1208-1218. doi: 10.1111/acel.12685
|
| [36] | Hsu WW, Wu B, Liu WR (2016) Sirtuins 1 and 2 are universal histone deacetylases. ASC Chem Biol 11: 792-799. |
| [37] |
Tan B, Young DA, Lu ZH, et al. (2012) Pharmacological inhibition of nicotinamide phosphoribosyltransferase (NAMPT), an enzyme essential for NAD+ biosynthesis, in human cancer cells. J Biol Chem 288: 3500-3511. doi: 10.1074/jbc.M112.394510
|
| [38] |
Cambronne XA, Stewart ML, Kim D, et al. (2016) Biosensor reveals multiple sources for mitochondrial NAD+. Science 352: 1474-1477. doi: 10.1126/science.aad5168
|
| [39] |
Berridge G, Cramer R, Galione A, et al. (2002) Metabolism of the novel Ca2+-mobilizing messenger nicotinic acid-adenine dinucleotide phosphate via a 2′-specific Ca2+-dependent phosphatase. Biochem J 365: 295-301. doi: 10.1042/bj20020180
|
| [40] |
Tran MT, Zsengeller ZK, Berg AH, et al. (2016) PGC1α drives NAD biosynthesis linking oxidative metabolism to renal protection. Nature 531: 528-532. doi: 10.1038/nature17184
|
| [41] |
Gujar AD, Le S, Mao DD, et al. (2016) An NAD+-dependent transcriptional program governs self-renewal and radiation resistance in glioblastoma. Proc Natl Acad Sci USA 113: E8247-E8256. doi: 10.1073/pnas.1610921114
|
| [42] |
Zhao H, Tang W, Chen X, et al. (2017) The NAMPT/E2F2/SIRT1 axis promotes proliferation and inhibits p53-dependent apoptosis in human melanoma cells. Biochem Biophys Res Commun 493: 77-84. doi: 10.1016/j.bbrc.2017.09.071
|
| [43] |
Mutz CN, Schwentner R, Aryee DNT, et al. (2017) EWS-FLI1 confers exquisite sensitivity to NAMPT inhibition in Ewing sarcoma cells. Oncotarget 8: 24679-24693. doi: 10.18632/oncotarget.14976
|
| [44] |
Tan B, Dong S, Shepard RL, et al. (2015) Inhibition of nicotinamide phosphoribosyltransferase (NAMPT), an enzyme essential for NAD+ biosynthesis, leads to altered carbohydrate metabolism in cancer cells. J Biol Chem 290: 15812-15824. doi: 10.1074/jbc.M114.632141
|
| [45] |
Hufton SE, Moerkerk PT, Brandwijk R, et al. (1999) A profile of differentially expressed genes in primary colorectal cancer using suppression subtractive hybridization. FEBS Lett 463: 77-82. doi: 10.1016/S0014-5793(99)01578-1
|
| [46] |
Van Beijnum JR, Moerkerk PT, Gerbers AJ, et al. (2002) Target validation for genomics using peptide-specific phage antibodies: a study of five gene products overexpressed in colorectal cancer. Int J Cancer 101: 118-127. doi: 10.1002/ijc.10584
|
| [47] | Bi TQ, Che XM, Liao XH, et al. (2011) Over expression of Nampt in gastric cancer and chemopotentiating effects of the Nampt inhibitor FK866 in combination with fluorouracil. Oncol Rep 26: 1251-1257. |
| [48] |
Ogino Y, Sato A, Uchiumi F, et al. (2018) Cross resistance to diverse anticancer nicotinamide phosphoribosyltransferase inhibitors induced by FK866 treatment. Oncotarget 9: 16451-16461. doi: 10.18632/oncotarget.24731
|
| [49] |
Chowdhry S, Zanca C, Rajkumar U, et al. (2019) NAD metabolic dependency in cancer is shaped by gene amplification and enhancer remodelling. Nature 569: 570-575. doi: 10.1038/s41586-019-1150-2
|
| [50] |
Ulanovskaya OA, Zhul AM, Cravatt BF (2013) NNMT promotes epigenetic remodelling in cancer by creating a metabolic methylation sink. Nat Chem Biol 9: 300-306. doi: 10.1038/nchembio.1204
|
| [51] |
Eckert MA, Coscia F, Chryplewicz A, et al. (2019) Proteomics reveals NNMT as a master metabolic regulator of cancer-associated fibroblasts. Nature 569: 723-728. doi: 10.1038/s41586-019-1173-8
|
| [52] |
Cantó C, Houtkooper RH, Pirinen E, et al. (2012) The NAD+ precursor nicotinamide riboside enhances oxidative metabolism and protects against high-fat diet-induced obesity. Cell Metab 15: 838-847. doi: 10.1016/j.cmet.2012.04.022
|
| [53] |
Han X, Tai H, Wang X, et al. (2016) AMPK activation protects cells from oxidative stress-induced senescence via autophagic flux restoration and intracellular NAD elevation. Aging Cell 15: 416-427. doi: 10.1111/acel.12446
|
| [54] |
Yang Y, Sauve AA (2016) NAD+ metabolism: bioenergetics, signaling and manipulation for therapy. Biochim Biophys Acta 1864: 1787-1800. doi: 10.1016/j.bbapap.2016.06.014
|
| [55] |
Zhang H, Ryu D, Wu Y, et al. (2016) NAD+ repletion improves mitochondrial and stem cell function and enhances life span in mice. Science 352: 1436-1443. doi: 10.1126/science.aaf2693
|
| [56] |
Rehmani I, Liu F, Liu A (2013) Cell signaling and transcription. Molecular basis of oxidative stress: chemistry, mechanisms, and disease pathogenesis Hoboken, NJ: John Wiley & Sons, 179-201. doi: 10.1002/9781118355886.ch8
|
| [57] |
Yun J, Finkel T (2014) Mitohormesis. Cell Metab 19: 757-766. doi: 10.1016/j.cmet.2014.01.011
|
| [58] |
López-Otín C, Serrano M, Partridge L, et al. (2013) The hallmarks of aging. Cell 153: 1194-1217. doi: 10.1016/j.cell.2013.05.039
|
| [59] |
Santidrian AF, Matsuno-Yagi A, Ritland M, et al. (2013) Mitochondrial complex I activity and NAD+/NADH balance regulate breast cancer progression. J Clin Invest 123: 1068-1081. doi: 10.1172/JCI64264
|
| [60] |
Luo C, Lim JH, Lee Y, et al. (2016) PGC1α-mediated transcriptional axis suppresses melanoma metastasis. Nature 537: 422-426. doi: 10.1038/nature19347
|
| [61] |
Kamenisch Y, Fousteri M, Knoch J, et al. (2010) Proteins of nucleotide and base excision repair pathways interact in mitochondria to protect from loss of subcutaneous fat, a hallmark of aging. J Exp Med 207: 379-390. doi: 10.1084/jem.20091834
|
| [62] |
Guarente L (2014) Linking DNA damage, NAD+/SIRT1, and aging. Cell Metab 20: 706-707. doi: 10.1016/j.cmet.2014.10.015
|
| [63] |
Dang L, White DW, Gross S, et al. (2009) Cancer-associated IDH1 mutations produce 2-hydroxyglutarate. Nature 462: 739-744. doi: 10.1038/nature08617
|
| [64] |
Yan H, Parsons DW, Jin G, et al. (2009) IDH1 and IDH2 mutations in gliomas. N Engl J Med 360: 765-773. doi: 10.1056/NEJMoa0808710
|
| [65] |
Lu C, Ward PS, Kapoor GS, et al. (2012) IDH mutation impairs histonedemethylation and results in a block to cell differentiation. Nature 483: 474-478. doi: 10.1038/nature10860
|
| [66] | Uchiumi F, Larsen S, Tanuma S (2013) Transcriptional regulation of the human genes that encode DNA repair- and mitochondrial function-associated proteins. Advances in DNA Repair Rijeka, Croatia: InTech Open Access Publisher, 129-167. |
| [67] |
Gray LR, Tompkins SC, Taylor EB (2014) Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 71: 2577-2604. doi: 10.1007/s00018-013-1539-2
|
| [68] |
Behl C, Ziegler C (2014) Selected age-related disorders. Cell Aging: Molecular Mechanisms and Implications for Disease Heidelberg, Germany: Springer Briefs in Molecular Medicine, Springer Science+Business Media, 99-108. doi: 10.1007/978-3-642-45179-9_4
|
| [69] |
Bender A, Krishnan KJ, Morris CM, et al. (2006) High levels of mitochondrial DNA deletions in substantia nigra neurons in aging and Parkinson disease. Nat Genet 38: 515-517. doi: 10.1038/ng1769
|
| [70] |
Ansari A, Rahman MS, Saha SK, et al. (2017) Function of the SIRT3 mitochondrial deacetylase in cellular physiology, cancer, and neurodegenerative disease. Aging Cell 16: 4-16. doi: 10.1111/acel.12538
|
| [71] |
Salvatori I, Valle C, Ferri A, et al. (2018) SIRT3 and mitochondrial metabolism in neurodegenerative diseases. Neurochem Int 109: 184-192. doi: 10.1016/j.neuint.2017.04.012
|
| [72] |
Patel NV, Gordon MN, Connor KE, et al. (2005) Caloric restriction attenuates Abeta-deposition in Alzheimer transgenic models. Neurobiol Aging 26: 995-1000. doi: 10.1016/j.neurobiolaging.2004.09.014
|
| [73] |
Imai S, Guarente L (2010) Ten years of NAD-dependent SIR2 family deacetylases: implications for metabolic diseases. Trends Pharmacol Sci 31: 212-220. doi: 10.1016/j.tips.2010.02.003
|
| [74] |
Silva DF, Esteves AR, Oliveira CR, et al. (2017) Mitochondrial metabolism power SIRT2-dependent traffic causing Alzheimer's-disease related pathology. Mol Neurobiol 54: 4021-4040. doi: 10.1007/s12035-016-9951-x
|
| [75] |
Jung ES, Choi H, Song H, et al. (2016) p53-dependent SIRT6 expression protects Ab42-induced DNA damage. Sci Rep 6: 25628. doi: 10.1038/srep25628
|
| [76] | Blakey CA, Litt MD (2016) Epigenetic gene expression-an introduction. Epigenetic gene expression and regulation London, UK: Academic Press, Elsevier Inc, 1-19. |
| [77] |
Suvà ML, Riggi N, Bernstein BE (2013) Epigenetic reprogramming in cancer. Science 339: 1567-1570. doi: 10.1126/science.1230184
|
| [78] |
McDevitt MA (2016) Clinical applications of epigenetics. Epigenomics in health and disease San Diego, CA: Academic Press, 271-295. doi: 10.1016/B978-0-12-800140-0.00013-3
|
| [79] |
Hentze MW, Preiss T (2010) The REM phase of gene regulation. Trends Biochem Sci 35: 423-426. doi: 10.1016/j.tibs.2010.05.009
|
| [80] |
Gut P, Verdin E (2013) The nexus of chromatin regulation and intermediary metabolism. Nature 502: 489-498. doi: 10.1038/nature12752
|
| [81] |
Liu C, Vyas A, Kassab MA, et al. (2017) The role of poly ADP-ribosylation in the first wave of DNA damage response. Nucleic Acids Res 45: 8129-8141. doi: 10.1093/nar/gkx565
|
| [82] |
Bai P, Cantó C, Oudart H, et al. (2011) PARP-1 inhibition increases mitochondrial metabolism through SIRT1 activation. Cell Metab 13: 461-468. doi: 10.1016/j.cmet.2011.03.004
|
| [83] |
Baxter P, Chen Y, Xu Y, et al. (2014) Mitochondrial dysfunction induced by nuclear poly (ADP-ribose) polymerase-1: a treatable cause of cell death in stroke. Transl Stroke Res 5: 136-144. doi: 10.1007/s12975-013-0283-0
|
| [84] |
Uchiumi F, Watanabe T, Ohta R, et al. (2013) PARP1 gene expression is downregulated by knockdown of PARG gene. Oncol Rep 29: 1683-1688. doi: 10.3892/or.2013.2321
|
| [85] |
Gibson BA, Zhang Y, Jiang H, et al. (2016) Chemical genetic discovery of PARP targets reveals a role for PARP-1 in transcription elongation. Science 353: 45-50. doi: 10.1126/science.aaf7865
|
| [86] |
Uchiumi F, Fujikawa M, Miyazaki S, et al. (2013) Implication of bidirectional promoters containing duplicated GGAA motifs of mitochondrial function-associated genes. AIMS Mol Sci 1: 1-26. doi: 10.3934/molsci.2013.1.1
|
| [87] |
Desquiret-Dumas V, Gueguen N, Leman G, et al. (2013) Resveratrol induces a mitochondrial complex I dependent increase in NADH oxidation responsible for sirtuin activation in liver cells. J Biol Chem 288: 36662-36675. doi: 10.1074/jbc.M113.466490
|
| [88] | Liu J, Oberdoerffer P (2013) Metabolic modulation of chromatin: implications for DNA repair and genomic integrity. Front Genet 4: 182. |
| [89] |
Pearce EL, Poffenberger MC, Chang CH, et al. (2013) Fueling Immunity: Insights into metabolism and lymphocyte function. Science 342: 1242454. doi: 10.1126/science.1242454
|
| [90] |
Uchiumi F, Shoji K, Sasaki Y, et al. (2015) Characterization of the 5′-flanking region of the human TP53 gene and its response to the natural compound, Resveratrol. J Biochem 159: 437-447. doi: 10.1093/jb/mvv126
|
| [91] |
Di LJ, Fernandez AG, de Siervi A, et al. (2010) Transcriptional regulation of BRCA1 expression by a metabolic switch. Nat Struct Mol Biol 17: 1406-1413. doi: 10.1038/nsmb.1941
|
| [92] |
Chinnadurai G (2002) CtBP, an unconventional transcription corepressor in development and oncogenesis. Mol Cell 9: 213-224. doi: 10.1016/S1097-2765(02)00443-4
|
| [93] |
Chinnadurai G (2009) The transcription corepressor CtBP: a foe of multiple tumor suppressors. Cancer Res 69: 731-734. doi: 10.1158/0008-5472.CAN-08-3349
|
| [94] |
Shen Y, Kapfhamer D, Minnella AM, et al. (2017) Bioenergetic state regulates innate inflammatory responses through the transcriptional co-repressor CtBP. Nat Commun 8: 624. doi: 10.1038/s41467-017-00707-0
|
| [95] |
Chen YQ, Sengchanthalangsy LL, Hackett A, et al. (2000) NF-kappaB p65 (RelA) homodimer uses distinct mechanisms to recognize DNA targets. Structure 8: 419-428. doi: 10.1016/S0969-2126(00)00123-4
|
| [96] |
Yang ZF, Drumea K, Mott S, et al. (2014) GABP transcription factor (nuclear respiratory factor 2) is required for mitochondrial biogenesis. Mol Cell Biol 34: 3194-3201. doi: 10.1128/MCB.00492-12
|
| [97] |
Keckesova Z, Donaher JL, De Cock J, et al. (2017) LACTB is a tumor suppressor that modulates lipid metabolism and cell state. Nature 543: 681-686. doi: 10.1038/nature21408
|
| [98] |
Venigopal R, Jaiswal AK (1996) Nrf1 and Nrf2 positively and c-Fos and Fra1 negatively regulate the human antioxidant response element-mediated expression of NAD(P): quinone oxidoreductase1 gene. Proc Natl Acad Sci USA 93: 14960-14965. doi: 10.1073/pnas.93.25.14960
|
| [99] |
Wilson LA, Germin A, Espiritu R, et al. (2005) Ets-1 is transcriptionally up-regulated by H2O2 via an antioxidant response element. FASEB J 19: 2085-2087. doi: 10.1096/fj.05-4401fje
|
| [100] |
Wei GH, Badis G, Berger MF, et al. (2010) Genome-wide analysis of ETS-family DNA-binding in vitro and in vivo. EMBO J 29: 2147-2160. doi: 10.1038/emboj.2010.106
|
| [101] |
Houtkooper RH, Pirinen E, Auwerx J (2012) Sirtuins as regulators of metabolism and healthspan. Nat Rev Mol Cell Biol 13: 225-238. doi: 10.1038/nrm3293
|
| [102] |
Sabari BR, Zhang D, Allis CD, et al. (2017) Metabolic regulation of gene expression through histone acylations. Nat Rev Mol Cell Biol 18: 90-101. doi: 10.1038/nrm.2016.140
|
| [103] |
Limagne E, Thibaudin M, Euvrard R, et al. (2017) Sirtuin-1 activation controls tumor growth by impeding Th17 differentiation via STAT3 deacetylation. Cell Rep 19: 746-759. doi: 10.1016/j.celrep.2017.04.004
|
| [104] |
Bonkowski MS, Sinclair DA (2016) Slowing aging by design: the rise of NAD+ and sirtuin-activating compounds. Nat Rev Mol Cell Biol 17: 679-690. doi: 10.1038/nrm.2016.93
|
| [105] |
Menzies KJ, Singh K, Saleem A, et al. (2013) Sirtuin 1-mediated effects of exercise and resveratrol on mitochondrial biogenesis. J Biol Chem 288: 6968-6979. doi: 10.1074/jbc.M112.431155
|
| [106] | Sack MN, Finkel T (2014) Mitochondrial metabolism, sirtuins, and aging. Mitochondria Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press, 253-262. |
| [107] |
Gibson BA, Kraus WL (2012) New insights into the molecular and cellular functions of poly (ADP-ribose) and PARPs. Nat Rev Mol Cell Biol 13: 411-424. doi: 10.1038/nrm3376
|
| [108] |
Curtin NJ, Mukhopadhyay A, Drew Y, et al. (2012) The role of PARP in DNA repair and its therapeutic exploitation. DNA repair in cancer therapy-Molecular targets and clinical applications London, UK: Academic Press, Elsevier Inc, 55-73. doi: 10.1016/B978-0-12-384999-1.10004-6
|
| [109] |
Lord CJ, Ashworth A (2017) PARP inhibitors: Synthetic lethality in the clinic. Science 355: 1152-1158. doi: 10.1126/science.aam7344
|
| [110] |
Venkitaraman AR (2014) Cancer suppression by the chromosome custodians, BRCA1 and BRCA2. Science 343: 1470-1475. doi: 10.1126/science.1252230
|
| [111] |
Feng X, Koh DW (2013) Inhibition of poly (ADP-ribose) polymerase-1 or poly (ADP-ribose) glycohydrolase individually, but not in combination, leads to improved chemotherapeutic efficacy in HeLa cells. Int J Oncol 42: 749-756. doi: 10.3892/ijo.2012.1740
|
| [112] |
Gomes AP, Price NL, Ling AJY, et al. (2013) Declining NAD+ induces a pseudohypoxic state disrupting nuclear-mitochondrial communication during aging. Cell 155: 1624-1638. doi: 10.1016/j.cell.2013.11.037
|
| [113] |
Mouchiroud L, Houtkooper RH, Auwerx J (2013) NAD+ metabolism, a therapeutic target for age-related metabolic disease. Crit Rev Biochem Mol Biol 48: 397-408. doi: 10.3109/10409238.2013.789479
|
| [114] |
Williams PA, Harder JM, Foxworth NE, et al. (2017) Vitamin B3 modulates mitochondrial vulnerability and prevents glaucoma in aged mice. Science 355: 756-760. doi: 10.1126/science.aal0092
|
| [115] |
Sueishi Y, Nii R, Kakizaki N (2017) Resveratrol analogues like piceatannol are antioxidants as quantitatively demonstrated through the high scavenging ability against reactive oxygen species and methyl radical. Bioorg Med Chem Lett 27: 5203-5206. doi: 10.1016/j.bmcl.2017.10.045
|
| [116] |
Johnson SC, Yanos ME, Kayser EB, et al. (2013) mTOR inhibition alleviates mitochondrial disease in a mouse model of Leigh syndrome. Science 342: 1524-1528. doi: 10.1126/science.1244360
|
| [117] |
Fendt SM, Bell EL, Keibler MA, et al. (2013) Metformin decreases glucose oxidation and increases the dependency of prostate cancer cells on reductive glutamine metabolism. Cancer Res 73: 4429-4438. doi: 10.1158/0008-5472.CAN-13-0080
|
| [118] |
Yamato M, Kawano K, Yamanaka Y, et al. (2016) TEMPOL increases NAD+ and improves redox imbalance in obese mice. Redox Biol 8: 316-322. doi: 10.1016/j.redox.2016.02.007
|
| [119] |
Jackson SJT, Singletary KW, Murphy LL, et al. (2016) Phytonutrients differentially stimulate NAD(P)H: quinone oxidoreductase, inhibit proliferation, and trigger mitotic catastrophe in Hepa1c1c7 cells. J Med Food 19: 47-53. doi: 10.1089/jmf.2015.0079
|
| [120] |
Roubalová L, Dinkova-Kostova AT, Biedermann D, et al. (2017) Flavonolignan 2,3-dehydrosilydianin activates Nrf2 and upregulates NAD(P)H: quinone oxidoreductase 1 in Hepa1c1c7 cells. Fitoterapia 119: 115-120. doi: 10.1016/j.fitote.2017.04.012
|
| [121] |
Son MJ, Ryu JS, Kim JY, et al. (2017) Upregulation of mitochondrial NAD+ levels impairs the clonogenicity of SSEA1+ glioblastoma tumor-initiating cells. Exp Mol Med 49: e344. doi: 10.1038/emm.2017.74
|
| [122] |
Fang EF, Kassahun H, Croteau DL, et al. (2016) NAD+ replenishment improves lifespan and healthspan in ataxia telangiectasia model via mitophagy and DNA repair. Cell Metab 24: 566-581. doi: 10.1016/j.cmet.2016.09.004
|
| [123] | Takihara Y, Sudo D, Arakawa J, et al. (2018) Nicotinamide adenine dinucleotide (NAD+) and cell aging. New Research on Cell Aging and Death Hauppauge, NY: Nova Science Publishers, Inc, 131-158. |
| [124] |
Wartewig T, Kurgyis Z, Keppler S, et al. (2017) PD-1 is a haploinsufficient suppressor of T cell lymphomagenesis. Nature 552: 121-125. doi: 10.1038/nature24649
|
| [125] | Uchiumi F, Larsen S, Tanuma S (2016) Possible roles of a duplicated GGAA motif as a driver cis-element for cancer-associated genes. Understand Cancer – Research and Treatment Hong Kong: iConcept Press Ltd, 1-25. |
| [126] | Uchiumi F, Larsen S, Masumi A, et al. (2013) The putative implications of duplicated GGAA-motifs located in the human interferon regulated genes (ISGs). Genomics I-Humans, Animals and Plants Hong Kong: iConcept Press Ltd, 87-105. |
| [127] |
Uchiumi F, Arakawa J, Iwakoshi K, et al. (2016) Characterization of the 5′-flanking region of the human DNA helicase B (HELB) gene and its response to trans-resveratrol. Sci Rep 6: 24510. doi: 10.1038/srep24510
|
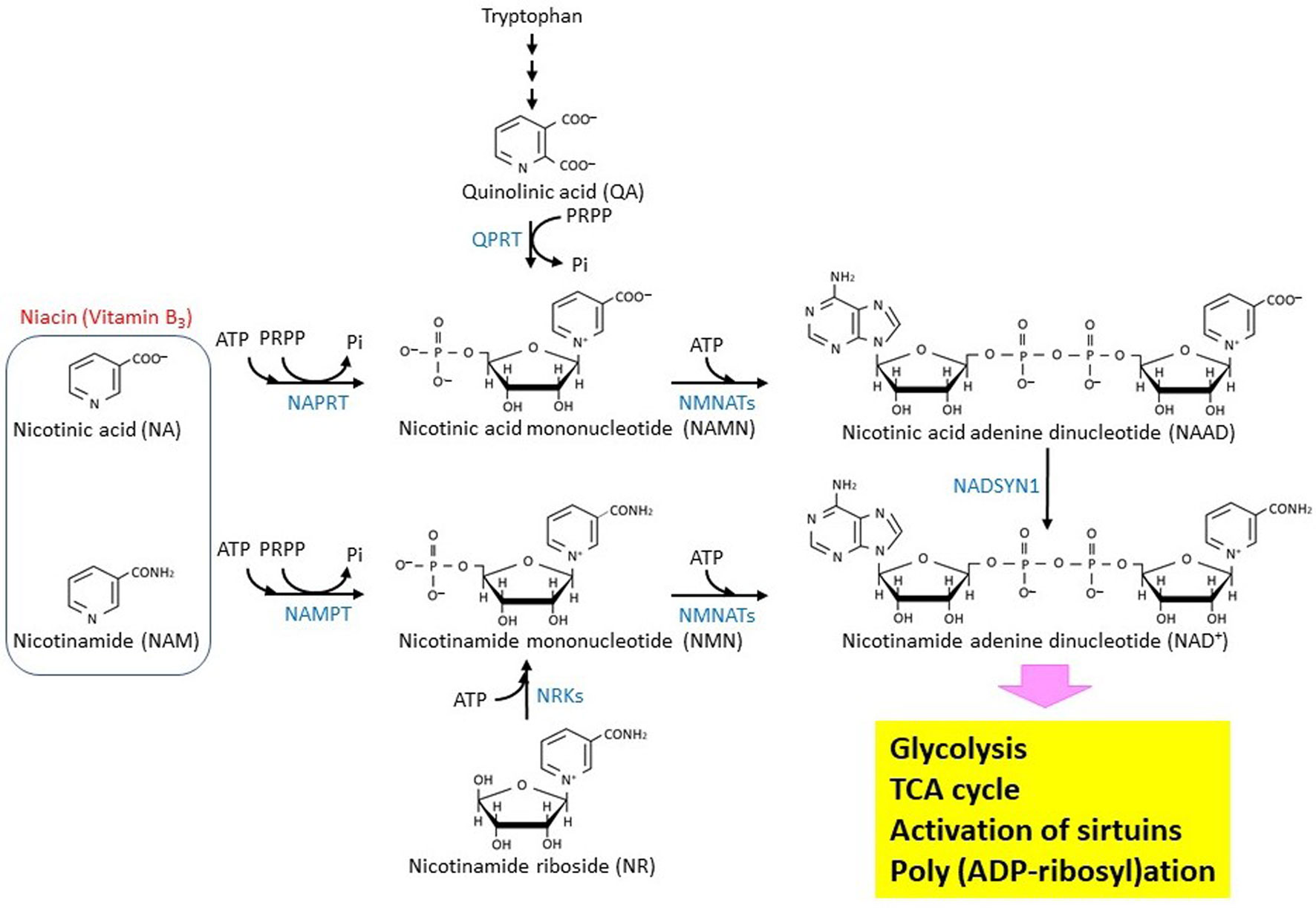
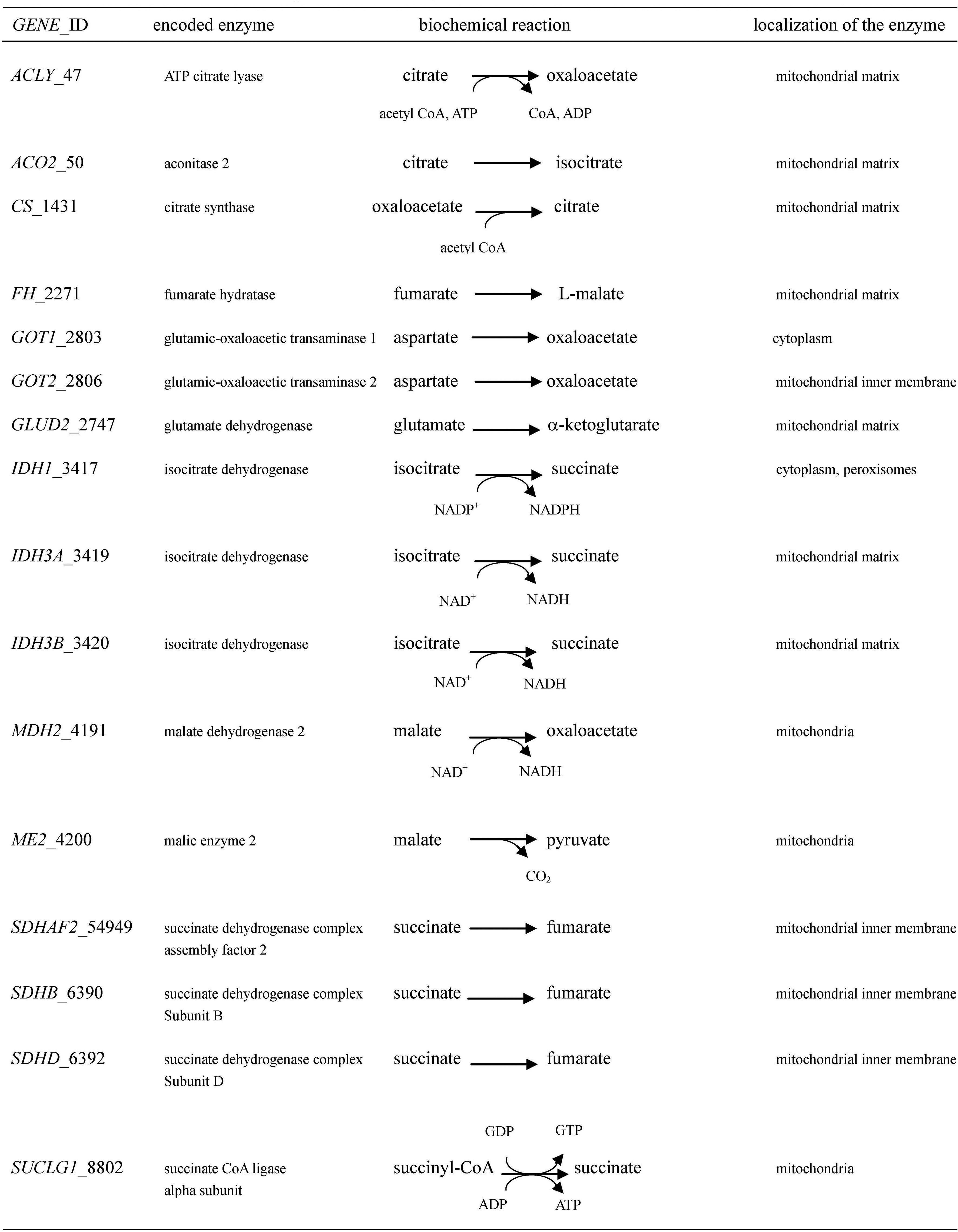
Figures(2)

Fumiaki Uchiumi, Akira Sato, Masashi Asai, Sei-ichi Tanuma. An NAD+ dependent/sensitive transcription system: Toward a novel anti-cancer therapy[J]. AIMS Molecular Science, 2020, 7(1): 12-28. doi: 10.3934/molsci.2020002







 DownLoad:
DownLoad: