Citation: Muhammad Umer Farooq, Iqra Ishaaq, Rizwana Maqbool, Iqra Aslam, Syed Muhammad Taseer Abbas Naqvi, Sana e Mustafa. Heritability, genetic gain and detection of gene action in hexaploid wheat for yield and its related attributes[J]. AIMS Agriculture and Food, 2019, 4(1): 56-72. doi: 10.3934/agrfood.2019.1.56

| [1] |
Widyaratne G, Zijlstra R (2007) Nutritional value of wheat and corn distiller's dried grain with solubles: Digestibility and digestible contents of energy, amino acids and phosphorus, nutrient excretion and growth performance of grower-finisher pigs. Can J Anim Sci 87: 103–114. doi: 10.4141/A05-070

|
| [2] | Pakistan G (2018) Ministry of Food and Agriculture. Economic Wing Islamabad, Pakistan. |
| [3] |
Cleland J (2013) World population growth; past, present and future. Environ Resour Econ 55: 543–554. doi: 10.1007/s10640-013-9675-6
|
| [4] | Ahmad N, Shabbir G, Akram Z, et al. (2013) Combining ability effects of some phenological traits in bread wheat. Sarhad J Agric 29: 15–20. |
| [5] |
Liang Y, Farooq MU, Hu Y, et al. (2018) Study on Stability and Antioxidant Activity of Red Anthocyanidin Glucoside Rich Hybrid Rice, its Nutritional and Physicochemical Characteristics. Food Sci Technol Res 24: 687–696. doi: 10.3136/fstr.24.687
|
| [6] | Liang Y, Farooq MU, Zeng R, et al. (2018) Breeding of Selenium Rich Red Glutinous Rice, Protein Extraction and Analysis of the Distribution of Selenium in Grain. Int J Agric Biol 20: 1005–1011. |
| [7] | Farooq MU, Zhicheng T, Zeng R, et al. (2018) Accumulation, mobilization and transformation of selenium in rice grain provided with foliar sodium selenite. J Sci Food Agr. |
| [8] | Farooq MU, Cheema AA, Ishaaq I, et al. (2018) Correlation and genetic component studies for peduncle length affecting grain yield in wheat. Int J Adv Appl Sci 5: 67–75. |
| [9] | Steel R, TORRIE JC (1980) Principles and procedures of statistics: A biometrical approach. McGraw-Hill. |
| [10] | Kempthorne O (1957) An introduction to genetic statistics. John Wiley And Sons, Inc.; New York. |
| [11] | Dabholkar AR (1992) Elements of biometrical genetics. |
| [12] | Fellahi ZEA, Hannachi A, Bouzerzour H, et al. (2013) Line × tester mating design analysis for grain yield and yield related traits in bread wheat (Triticum aestivum L.). Int J Agron, 2013. |
| [13] |
Farooq MU, Khan AS, Ishaaq I, et al. (2018) Growing Degree Days during the Late Reproductive Phase Determine Spike Density and Cognate Yield Traits. Agronomy 8: 217. doi: 10.3390/agronomy8100217
|
| [14] | Menon U, Sharma S (1997) Genetics of yield determining factors in spring wheat over environments. Indian J Genet Plant Breed 57: 301–306. |
| [15] | Javaid A, Masood S, Minhas N (2001) Analysis of combining ability in wheat (Triticum aestivum L.) using F2 generation. Pak J Biol Sci 4: 1303–1305. |
| [16] | Yadav NK, Yadav PC, Shweta, et al. (2014) Combining ability and heterotic response for yield and its attributing traits in wheat (Triticum aestivum L.). Int J Plant Sci 9: 377–380. |
| [17] | Nazir S, Khan AS, Ali Z (2005) Combining ability analysis for yield and yield contributing traits in bread wheat. J Agric Soc Sci 1: 129–132. |
| [18] | Ahmad E, Akhtar M, Badoni S, et al. (2017) Combining ability studies for seed yield related attributes and quality parameters in bread wheat (Triticum aestivum L.). J Genet Genomics Plant Breed 1: 21–27. |
| [19] | Saeed A, Chowdhry MA, Saedd N, et al. (2001) Line × tester analysis for some morpho-physiological traits in bread wheat. Int J Agric Biol 3: 444–447. |
| [20] |
Bao YG, Wang S, Wang XQ, et al. (2009) Heterosis and Combining Ability for Major Yield Traits of a New Wheat Germplasm Shannong 0095 Derived from Thinopyrum intermedium. Agric Sci China 8: 753–760. doi: 10.1016/S1671-2927(08)60275-8
|
| [21] | Akram Z, Ajmal SU, Khan KS, et al. (2011) Combining ability estimates of some yield and quality related traits in spring wheat (Triticum aestivum L.). Pak J Bot 43: 221–231. |
| [22] | Malik MFA, Awan SI, Ali S (2005) Genetic behavior and analysis of quantitative traits in five wheat genotypes. J Agric Soc Sci 1: 313–315. |
| [23] | Baloch MJ, Mallano IA, Baloch AW, et al. (2011) Efficient methods of choosing potential parents and hybrids: Line Tester analysis of spring wheat (Triticum aestivum L.) cultivars. 54: 117–121. |
| [24] | Ammar A, Irshad A, Liaqat S, et al. (2014) Combining ability studies for yield components in wheat (Triticum aestivum). J Food Agric Environ 12: 383–386. |
| [25] | Mahpara S, Ali Z, Ahsan M (2008) Combining ability analysis for yield and yield related traits among wheat varieties and their F1 hybrids. Int J Agric Biol 10: 599–604. |
| [26] | Lohithaswa H, Desai S, Hanchinal R, et al. (2014) Combining ability in tetraploid wheat for yield, yield attributing traits, quality and rust resistance over environments. Karnataka J Agric Sci, 26. |
| [27] | Hussain B, Khan AS, Farid MZ (2014) Inheritance of Plant Height, Yield and Yield Related Traits in Bread Wheat. Inter J Modern Agri 3: 74–80. |
| [28] | Hasnain Z, Abbas G, Saeed A, et al. (2006) Combining ability for plant height and yield related traits in wheat (Triticum aestivum L.). J Agric Res 44: 167–173. |
| [29] | Jatav M, Jatav S, Kandalkar V (2014) Combining ability and heterosis analysis of morpho-physiological characters in wheat. Ann Plant Soil Res 16: 79–83. |
| [30] | Awan SI, Malik MFA, Siddique M (2005) Combining ability analysis in intervarietal crosses for component traits in hexaploid wheat. J Agric Soc Sci 1: 316–317. |
| [31] | Zeeshan M, Arshad W, Ali S, et al. (2013) Estimation of combining ability effects for some yield related metric traits in intra-specific crosses among different spring wheat (Triticum aestivum L.) genotypes. Int J Adv Res 1: 6–10. |
| [32] | Akbar M, Anwar J, Hussain M, et al. (2009) Line tester analysis in bread wheat (Triticum aestivum L.). J Agric Res, 47. |
| [33] | Anwar J, Akbar M, Hussain M, et al. (2011) Combining ability estimates for grain yield in wheat. J Agric Res, 49. |
| [34] |
Yao J, Ma H, Yang X, et al. (2014) Inheritance of grain yield and its correlation with yield components in bread wheat (Triticum aestivum L.). Afr J Biotechnol 13: 1379–1385. doi: 10.5897/AJB12.2169
|
| [35] | Topal A, Aydın C, Akgün N, et al. (2004) Diallel cross analysis in durum wheat (Triticum durum Desf.): Identification of best parents for some kernel physical features. Field Crop Res 87: 1–12. |
| [36] | Iqbal M, Khan A (2006) Analysis of combining ability for spike characteristics in wheat (Triticum aestivum L.). Int J Agric Biol 8: 684–687. |
| [37] | Cheema NM, Muhammad I, Mian MA, et al. (2007) Gene action studies for some economic traits in spring wheat. Pak J Agric Res 20: 99–104. |
| [38] | Seboka H, Ayana A, Zelleke H (2009) Combining ability analysis for bread wheat (Triticum aestivum L.). East Afr J Sci, 3. |
| [39] |
Tiwari D, Pandey P, Giri S, et al. (2011) Prediction of gene action, heterosis and combining ability to identify superior rice hybrids. Int J Bot 7: 126–144. doi: 10.3923/ijb.2011.126.144
|
| [40] | Çifci EA, Yagdi K (2010) The research of the combining ability of agronomic traits of bread wheat in F1 and F2 generations. J Agric Fac Uludag U 24: 85–92. |
| [41] | Ahmad F, Khan S, Ahmad SQ, et al. (2011) Genetic analysis of some quantitative traits in bread wheat across environments. Afr J Agric Res 6: 686–692. |
| [42] | Jain S, Sastry E (2012) Heterosis and combining ability for grain yield and its contributing traits in bread wheat (Triticum aestivum L.). J Agric All Sci 1: 17–22. |
| [43] | Yadav AK, Maan RK, Kumar S, et al. (2011) Research Note Variability, heritability and genetic advance for quantitative characters in hexaploid wheat (Triticum aestivum L.). Elect J Plant Breed 2: 405–408. |
| [44] | Hussain Q, Aziz T, Khalil IH, et al. (2017) Estimation of heritability and selection response for some yield traits in F3 populations of wheat. Int J Agric Appl Sci 9: 6–13. |
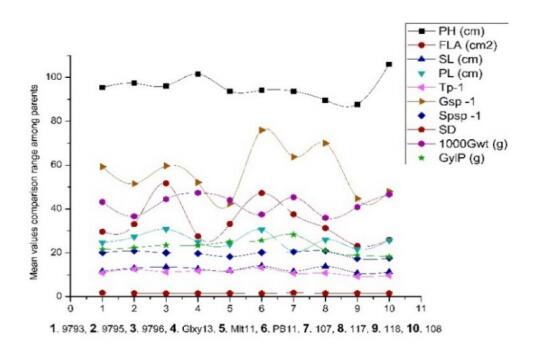
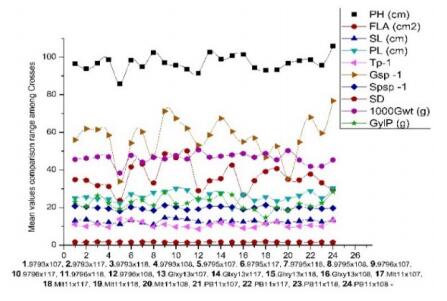
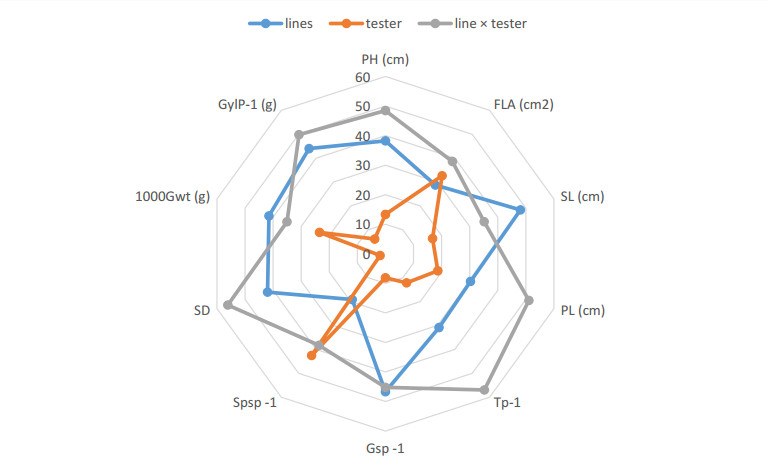
Figures(3) / Tables(8)

Muhammad Umer Farooq, Iqra Ishaaq, Rizwana Maqbool, Iqra Aslam, Syed Muhammad Taseer Abbas Naqvi, Sana e Mustafa. Heritability, genetic gain and detection of gene action in hexaploid wheat for yield and its related attributes[J]. AIMS Agriculture and Food, 2019, 4(1): 56-72. doi: 10.3934/agrfood.2019.1.56







 DownLoad:
DownLoad: