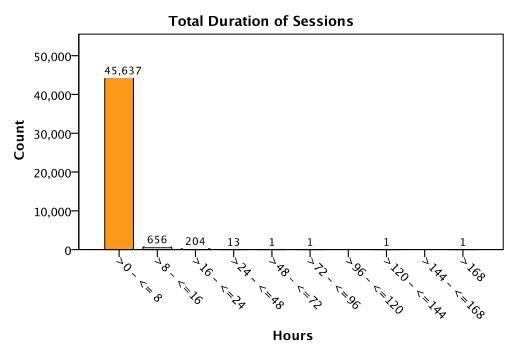
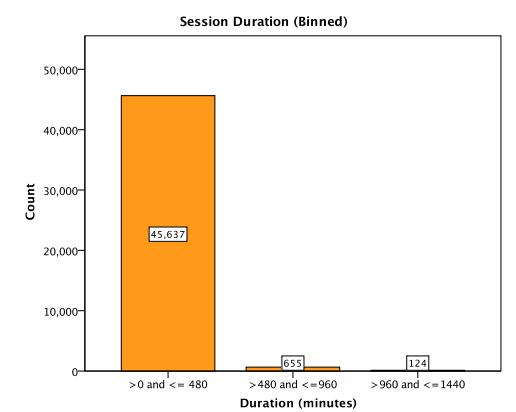
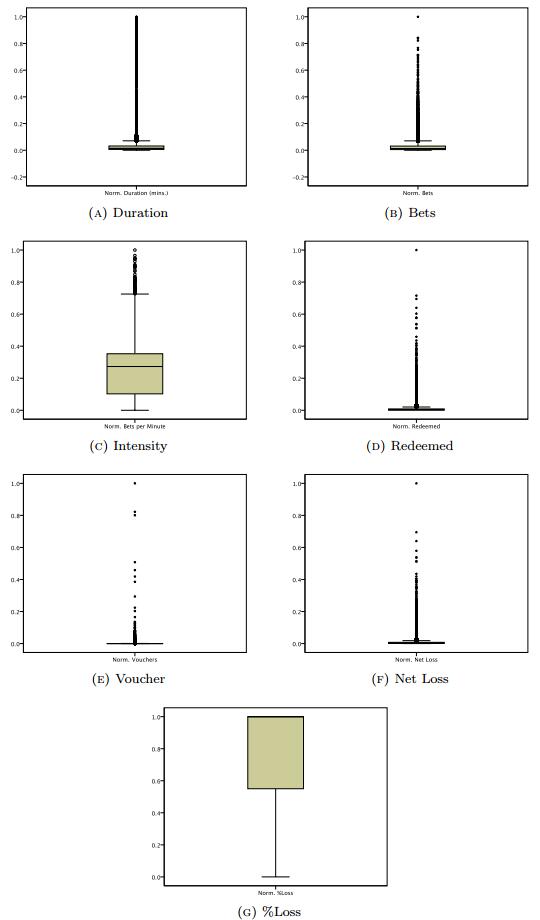
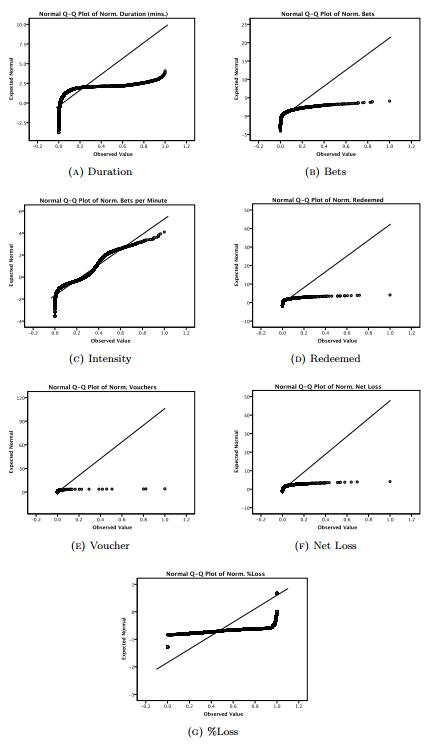
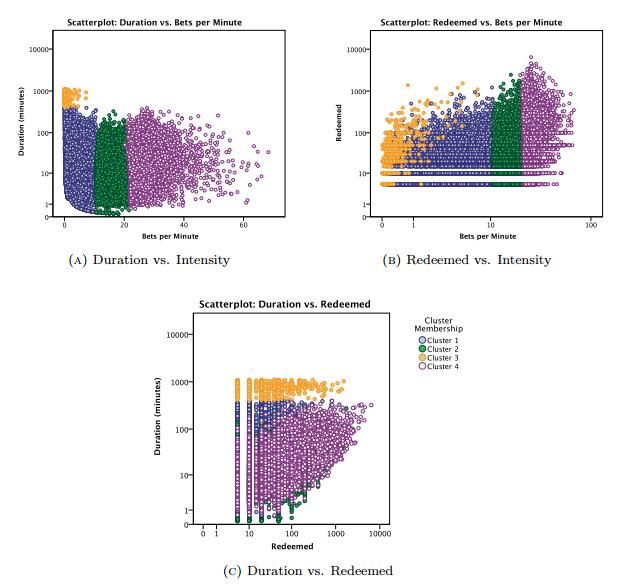
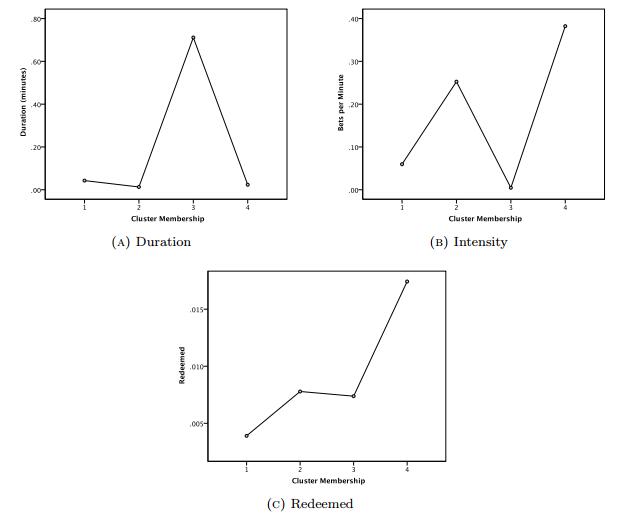
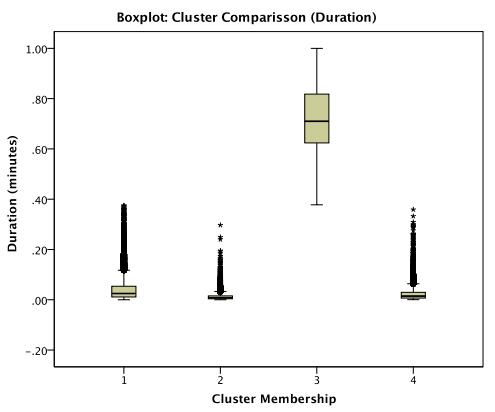
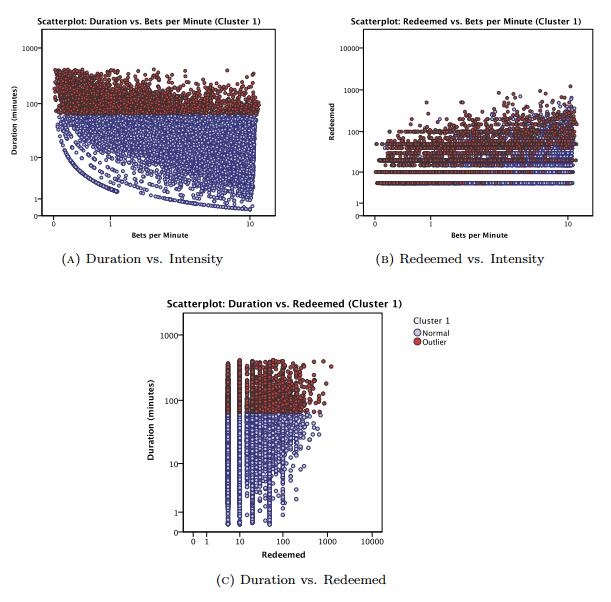
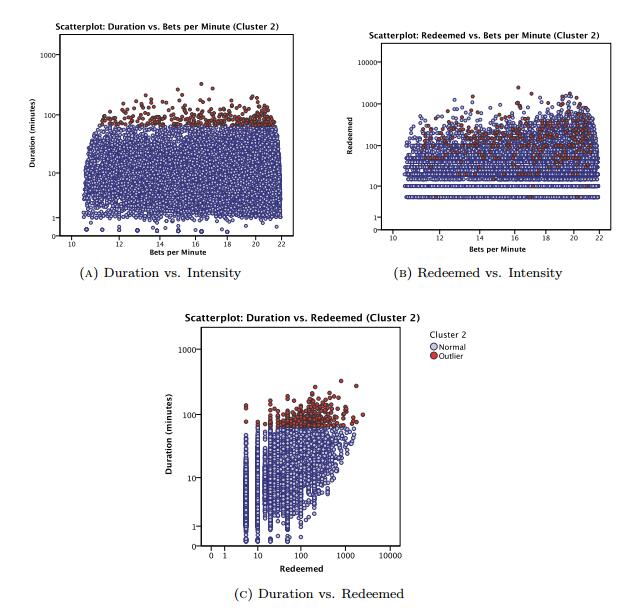
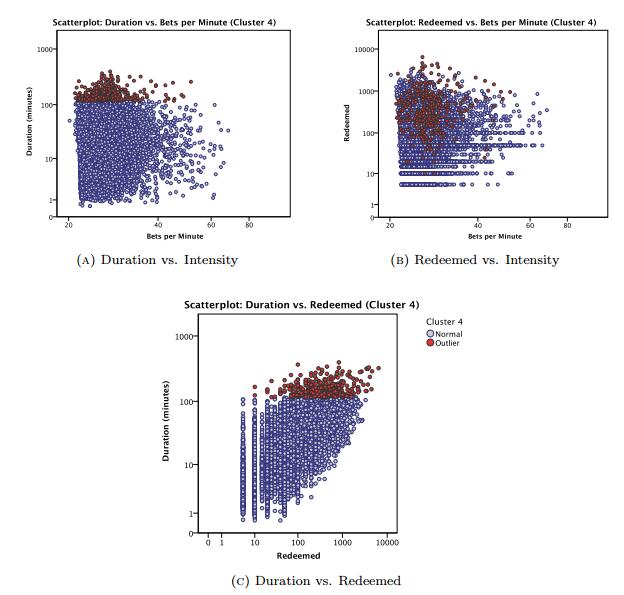
The rising accessibility in gambling products, such as Electronic Gaming Machines (EGM), has increased interest in the effects of gambling; in particular, the potential for impulse control disorders, such as problem gambling. Nevertheless, empirical research of EGM gambling behaviour is scarce. In this exploratory study, we apply data mining techniques on 46,416 gambling sessions, collected in situ from 288 EGMs. Our research focused on identifying the at-risk behavioural markers of sessions to help distinguish gambling personae. Our data included measures of gambling involvement, out-of pocket expense of sessions, amount won, and cost of gambling. This research, discusses the methodology used to collect and analyze the required gambling measures, explains the criteria used for identifying valid sessions, and combines outlier mining methods to identify instances of heavily involved gambling (i.e., outliers). Our results suggest that sessions were classified as potential non-problem, potential low-risk, potential moderate risk, and potential problem gambling sessions. Further, outlier sessions were more heavily involved in terms of gambling intensity and amount redeemed, despite having low duration times. Finally, our methods suggest that the lack of player identification does not prevent one from identifying the potential incidence of problem gambling behaviour.
Citation: Maria Gabriella Mosquera, Vlado Keselj. Identifying electronic gaming machine gambling personae through unsupervised session classification[J]. Big Data and Information Analytics, 2017, 2(2): 141-175. doi: 10.3934/bdia.2017015
The rising accessibility in gambling products, such as Electronic Gaming Machines (EGM), has increased interest in the effects of gambling; in particular, the potential for impulse control disorders, such as problem gambling. Nevertheless, empirical research of EGM gambling behaviour is scarce. In this exploratory study, we apply data mining techniques on 46,416 gambling sessions, collected in situ from 288 EGMs. Our research focused on identifying the at-risk behavioural markers of sessions to help distinguish gambling personae. Our data included measures of gambling involvement, out-of pocket expense of sessions, amount won, and cost of gambling. This research, discusses the methodology used to collect and analyze the required gambling measures, explains the criteria used for identifying valid sessions, and combines outlier mining methods to identify instances of heavily involved gambling (i.e., outliers). Our results suggest that sessions were classified as potential non-problem, potential low-risk, potential moderate risk, and potential problem gambling sessions. Further, outlier sessions were more heavily involved in terms of gambling intensity and amount redeemed, despite having low duration times. Finally, our methods suggest that the lack of player identification does not prevent one from identifying the potential incidence of problem gambling behaviour.

| [1] |
C. C. Aggarwal, Outlier Analysis, Springer, New York, 2013. MR3024573 |
| [2] | American Psychiatric Association, Diagnostic and Statistical Manual of Mental Disorders, 4th edition, American Psychiatric Association, Washington, DC, 1994. |
| [3] | G. Banks, R. Fitzgerald and L. Sylvan, Gambling: Productivity Commission Inquiry Report, Technical Report 50,2010, http://www.pc.gov.au/inquiries/completed/gambling-2009/report/gambling-report-volume1.pdf(visited on: 09/12/2012). |
| [4] | M. Berry and G. Linoff, Data Mining Techniques for Marketing, Sales, and Customer Relationship Management, 2nd edition, Wiley Publishing Inc., Indianapolis, 2004. |
| [5] |
Braverman J., LaBrie R.A., Shaffer H.J. (2011) A taxometric analysis of actual Internet sport gambling behavior. Psychological Assessment 23: 234-244. doi: 10.1037/a0021404

|
| [6] |
Braverman J., LaPlante D.A., Nelson S.E., Shaffer H.J. (2013) Using cross-game behavioral markers for early identification of high-risk Internet gamblers. Psychology of Addictive Behaviors 27: 868-877. doi: 10.1037/a0032818
|
| [7] |
Braverman J., Shaffer H.J. (2012) How do gamblers start gambling: Identifying behavioral markers for high-risk Internet gambling. European Journal of Public Health 22: 273-278. doi: 10.1093/eurpub/ckp232
|
| [8] |
S. Carpendale, Evaluating information visualizations, in Information Visualization, Lecture Notes in Computer Science, A simple univariate outlier identification procedure, 4950 (2008), 19-45. 10.1007/978-3-540-70956-5_2 |
| [9] | National Research Council (1999) Pathological Gambling: A Critical Review Washington D.C.: National Academies Press. |
| [10] | P. Delfabbro, A. Osborn, M. Nevile, L. Skelt and J. MacMillen, Identifying Problem Gamblers in Gambling Venues, Technical report, 2007. |
| [11] |
Dixon M.J., Harrigan K.A., Jarrick M., MacLaren V., Fugelsang J.A., Sheepy E. (2011) Psychophysiological arousal signatures of near-misses in slot machine play. International Gambling Studies 11: 393-407. doi: 10.1080/14459795.2011.603134
|
| [12] |
Dixon L., Trigg R., Griffiths M. (2007) An empirical investigation of music and gambling behaviour. International Gambling Studies 7: 315-326. doi: 10.1080/14459790701601471
|
| [13] |
Dragicevic S., Tsogas G., Kudic A. (2011) Analysis of casino online gambling data in relation to behavioural risk markers for high-risk gambling and player protection. International Gambling Studies 11: 377-391. doi: 10.1080/14459795.2011.629204
|
| [14] |
Ellery M., Stewart S.H., Loba P. (2005) Alcohol's effects on video lottery terminal (vlt) play among probable pathological and non-pathological gamblers. Journal of Gambling Studies 21: 299-324. doi: 10.1007/s10899-005-3101-0
|
| [15] | J. Ferris and H. Wynne, The Canadian Problem Gambling Index: Final Report, Technical Report, 2001, http://www.ccgr.ca/en/projects/resources/CPGI-Final-Report-English.pdf(visited on: 06/28/2013). |
| [16] | G. Data, Canadian Gaming Market Report, Technical report, 2011, http://www.gamblingdata.com/files/Gambling%20Data%20Canadian%20Gaming%20Market%20Report%20Final_0.pdf (visited on: 04/10/2013). |
| [17] | GSA, G2S Message Protocol v1. 1 Game-to-system, Technical Report GSA-P0075. 024. 00-2011, GSA, 2011. |
| [18] | GSA, G2S Message Protocol v2. 0 Game-to-system, Technical Report GSA-P0075. 0800. 00-2006, GSA, 2006. |
| [19] | J. Han and M. Kamber, Data Mining: Concepts and Techniques, 3rd edition, Morgan Kaufmann, Waltham, 2012. |
| [20] | Harrigan K.A., Dixon M. (2009) Par sheets, probabilities, and slot machine play: Implications of problem and non-problem gambling. Journal of Gambling Issues 23: 81-110. |
| [21] | Harrigan K.A. (2007) Slot machine structural characteristics: Distorted player views of payback percentages. Journal of Gambling Issues 20: 215-234. |
| [22] |
Harrigan K.A. (2009) Slot machines: Pursuing responsible gaming practices for virtual reels and near misses. International Journal of Mental Health Addiction 7: 68-83. doi: 10.1007/s11469-007-9139-8
|
| [23] |
Hennig C. (2007) Cluster-wise assessment of cluster stability. Computational Statistics & Data Analysis 52: 258-271. doi: 10.1016/j.csda.2006.11.025
|
| [24] |
Hoaglin D.C. (2003) John W. Tukey and data analysis. Statistical Science 18: 311-318. doi: 10.1214/ss/1076102418
|
| [25] | B. Iglewicz and S. Banerjee, A Simple Univariate Outlier Identification Procedure, Proceedings of Annual Meeting of the American Statistical Association, 2001. |
| [26] |
LaBrie R.A., LaPlante D.A., Nelson S.E., Schumann A., Shaffer H.J. (2007) Assessing the playing field: A prospective longitudinal study of Internet sports gambling behavior. Journal of Gambling Studies 23: 347-362. doi: 10.1007/s10899-007-9067-3
|
| [27] |
LaBrie R.A., Kaplan S.A., LaPlante D.A., Nelson S.E., Shaffer H.J. (2008) Inside the virtual casino: A prospective longitudinal study of actual Internet casino gambling. European Journal of Public Health 18: 410-416. doi: 10.1093/eurpub/ckn021
|
| [28] |
LaPlante D. A., Nelson S. E., LaBrie R. A., Shaffer H. J. (2008) Stability and progression of disordered gambling: Lessons from longitudinal studies. Canadian Journal of Psychiatry 53: 52-60. doi: 10.1177/070674370805300108
|
| [29] |
LaPlante D.A., Nelson S.E., LaBrie R.A., Shaffer H.J. (2011) Disordered gambling, type of gambling and gambling involvement in the British gambling prevalence survey 2007. European Journal of Public Health 21: 532-537. doi: 10.1093/eurpub/ckp177
|
| [30] |
Liu H., Keselj V. (2007) Combined mining of web server logs and web contents for classifying user navigation patterns and predicting users' future requests. Data & Knowledge Engineering 61: 304-330. doi: 10.1016/j.datak.2006.06.001
|
| [31] | Loba P., Stewart S. H., Klein R. M., Blackburn J. R. (2001) Manipulations of the features of standard video lottery terminal (VLT) games: Effects in pathological and non-pathological gamblers. Journal of Gambling Studies 17: 94-98. |
| [32] |
MacLaren V.V., Fugelsang J.A., Harrigan K., Dixon M. (2011) The personality of pathological gamblers: A meta-analysis. Clinical Psychology Review 31: 1057-1067. doi: 10.1016/j.cpr.2011.02.002
|
| [33] | K. Marshall, Gambling 2011, Technical Report 4,2011, http://www.statcan.gc.ca/pub/75-001-x/2011004/article/11551-eng.pdf(visited on: 04/10/2013). |
| [34] |
Mishra S., Lumiére M.L., Williams R.J. (2010) Gambling as a form of risk-taking: Individual differences in personality, risk-accepting attitudes, and behavioral preferences for risk. Personality and Individual Differences 49: 616-621. doi: 10.1016/j.paid.2010.05.032
|
| [35] | National Research Council (1999) Pathological Gambling: A Critical Review Washington D.C.: The National Academies Press. |
| [36] |
Nelson S.R., LaPlante D.A., Peller A.J., Schumann A., LaBrie R.A., Shaffer H.J. (2008) Real limits in the virtual world: Self-limiting behavior of Internet gamblers. Journal of Gambling Studies 24: 463-477. doi: 10.1007/s10899-008-9106-8
|
| [37] | J. Pallant, SPSS Survival Manual: A Step By Step Guide to Data Analysis Using SPSS, 4th edition, Allen & Unwin, Sydney, 2011. |
| [38] |
Y. Peng, K. Gang and Y. Shi (eds. ), Knowledge-rich data mining in financial risk detection, in Computational Science - ICCS 2009 (eds. G. Allen, J. Nabrzyski, E. Seidel, G. D. van Albada, J. Dongarra and P. M. A. Sloot), Springer Berlin Heidelberg, 5545 (2009), 534-542. 10.1007/978-3-642-01973-9_60 |
| [39] |
Pham D. T., Dimov S. S., Nguyen C. D. (2005) Selection of k in k-means clustering. Journal of Mechanical Engineering Science 219: 103-119. doi: 10.1243/095440605X8298
|
| [40] | A. Rakhlin and A. Caponnetto (eds. ), Stability of k-means clustering, in Advances in Neural Information Processing Systems 19 (eds. B. Schölkopf, J. Platt and T. Hoffman), MIT Press, (2006), 1121-1128. http://papers.nips.cc/paper/3116-stability-of-k-means-clustering (visited on: 12/10/2014) |
| [41] | Responsible Gambling Council, Electronic Gaming Machines and Problem Gambling, Saskachewan Liquour and Gaming Authority, 2006, http://www.responsiblegambling.org/docs/research-reports/electronic-gaming-machines-and-problem-gambling.pdf?sfvrsn=10 (visited on: 06/28/2013). |
| [42] | Responsible Gambling Council, Canadian Gambling Digest 2011-2012, Technical report, 2013, http://www.responsiblegambling.org/docs/default-document-library/20130605_canadian_gambling_digest_2011-12.pdf?sfvrsn=2 (visited on: 05/04/2015). |
| [43] | G. Schwartz, The Impulse Economy, Atria Books, New York, 2011. |
| [44] | S. Seo, A Review and Comparison of Methods for Detecting Outliers in Univariate Data Sets, M. S thesis, University of Pittsburg in Pensylvania, 2006. |
| [45] |
Shaffer H.J., Korn D.A. (2002) Gambling and related mental disorders: A public health analysis. Annual Review of Public Health 23: 171-212. doi: 10.1146/annurev.publhealth.23.100901.140532
|
| [46] |
Shaffer H.J., Peller A.J., LaPlante D.A., Nelson S.E., LaBrie R.A. (2010) Toward a paradigm shift in Internet gambling research: From opinion and self-report to actual behavior. Addiction Research and Theory 18: 270-283. doi: 10.3109/16066350902777974
|
| [47] | Sim J., Wright C.C. (2005) Understanding interobserver agreement: The Kappa statistic. Family Medicine 37: 360-363. |
| [48] |
Stewart S. H., Collins P., Blackburn J. R., Ellery M., Klein R. M. (2005) Heart rate increase to alcohol administration and video lottery terminal (VLT) play among regular VLT players. Psychology of Addictive Behaviors 19: 94-98. doi: 10.1037/0893-164X.19.1.94
|
| [49] |
S. Tufféry, Data Mining and Statistics for Decision Making, John Wiley & Sons, Ltd., Chichester, 2011.
10.1002/9780470979174 |
| [50] | Viera A.J., Garrett J.M. (2005) The Kappa statistic in reliability studies: Use, interpretation, and sample size requirements. Journal of the American Physical Therapy Association 85: 257-268. |
| [51] | C. Wheelan, Naked Statistics: Stripping the Dread from the Data, W. W. Norton and Company, New York, 2013. |
| [52] | R. J. Williams, R. A. Volberg and R. M. G. Stevens, The Population Prevalence of Problem Gambling: Methodological Influences, Standardized Rates, Jurisdictional Differences, and Worldwide Trends, Technical report, 2012, https://www.uleth.ca/dspace/bitstream/handle/10133/3068/2012-PREVALENCE-OPGRC%20(2).pdf?sequence=3 (visited on: 08/12/2013). |
| [53] |
Wilson D. S., Kauffman R. A., Purdy M. S. (2002) A program for at-risk high school students
informed by evolutionary science. PLoS ONE 31: 76-77. doi: 10.1371/journal.pone.0027826
|
| [54] |
Witten I.H., Frank E. (2002) Data mining: Practical machine learning tools and techniques. Newsletter: ACM SIGMOD Record Homepage archive 31: 76-77. doi: 10.1145/507338.507355
|
| [55] |
Xuan Z., Shaffer H. (2009) How do gamblers end gambling: Longitudinal analysis of Internet gambling behaviors prior to account closure due to gambling related problems. Journal of Gambling Studies 25: 239-252. doi: 10.1007/s10899-009-9118-z
|
Figures(10) / Tables(13)

Maria Gabriella Mosquera, Vlado Keselj. Identifying electronic gaming machine gambling personae through unsupervised session classification[J]. Big Data and Information Analytics, 2017, 2(2): 141-175. doi: 10.3934/bdia.2017015









 DownLoad:
DownLoad: