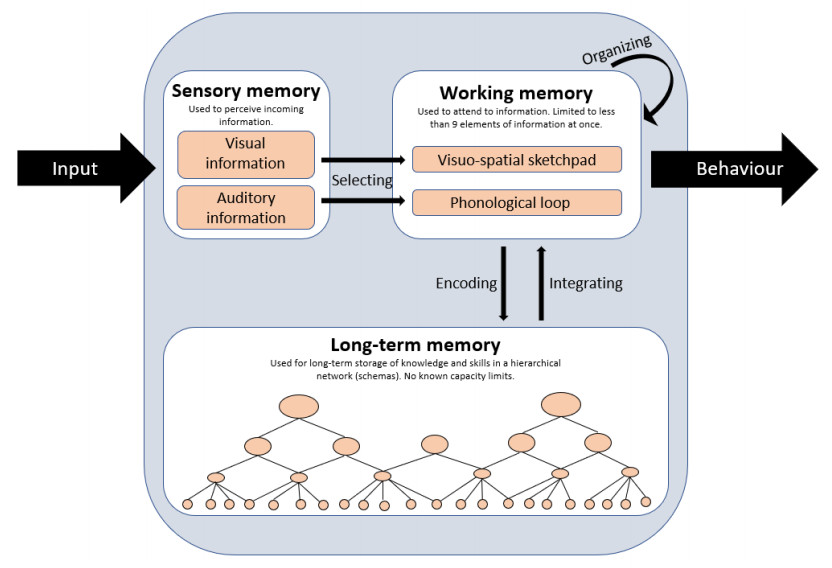
Finding effective ways to engage students in sense-making while learning is one of the central challenges discussed in mathematics education literature. One of the big issues is the prevalence of summative assessment tasks prompting students to demonstrate procedural knowledge only, which is a common problem at the tertiary level. In this study, in a large university classroom setting (N = 355), an instructional innovation was designed, developed, implemented and evaluated involving novel tasks–Knowledge Organisers. The tasks comprised prompts for students to generate examples/non-examples and construct a concept map of the key mathematical concepts in the course. The initiative's design was based on the current understanding of human cognitive architecture. A concept map is a visualisation of a group of related abstract concepts with their relationships identified by connections using directed arrows, which can be viewed as an externalisation of a schema stored in a learner's long-term memory. As such, we argue for a distinction between a local conceptual understanding (e.g., example space) versus a global conceptual understanding, manifesting through a high-quality concept map linking a group of related concepts. By utilising a mixed-methods approach and triangulation of the findings from qualitative and quantitative analyses, we were able to discern critical aspects pertaining to the feasibility of implementation and evaluate learners' perceptions. Students' performance on concept mapping is positively correlated with their perceptions of the novel tasks and the time spent completing them. Qualitative analysis showed that students' perceptions are demonstrably insightful about the key mechanisms that supposedly make the tasks beneficial to their learning. Based on the results of the data analyses and their theoretical interpretations, we propose pedagogical strategies for the effective use of Knowledge Organisers.
Citation: Inae Jeong, Tanya Evans. Knowledge Organisers for learning: Examples, non-examples and concept maps in university mathematics[J]. STEM Education, 2023, 3(2): 103-129. doi: 10.3934/steme.2023008
Finding effective ways to engage students in sense-making while learning is one of the central challenges discussed in mathematics education literature. One of the big issues is the prevalence of summative assessment tasks prompting students to demonstrate procedural knowledge only, which is a common problem at the tertiary level. In this study, in a large university classroom setting (N = 355), an instructional innovation was designed, developed, implemented and evaluated involving novel tasks–Knowledge Organisers. The tasks comprised prompts for students to generate examples/non-examples and construct a concept map of the key mathematical concepts in the course. The initiative's design was based on the current understanding of human cognitive architecture. A concept map is a visualisation of a group of related abstract concepts with their relationships identified by connections using directed arrows, which can be viewed as an externalisation of a schema stored in a learner's long-term memory. As such, we argue for a distinction between a local conceptual understanding (e.g., example space) versus a global conceptual understanding, manifesting through a high-quality concept map linking a group of related concepts. By utilising a mixed-methods approach and triangulation of the findings from qualitative and quantitative analyses, we were able to discern critical aspects pertaining to the feasibility of implementation and evaluate learners' perceptions. Students' performance on concept mapping is positively correlated with their perceptions of the novel tasks and the time spent completing them. Qualitative analysis showed that students' perceptions are demonstrably insightful about the key mechanisms that supposedly make the tasks beneficial to their learning. Based on the results of the data analyses and their theoretical interpretations, we propose pedagogical strategies for the effective use of Knowledge Organisers.

| [1] |
Schroeder, N.L., Nesbit, J.C., Anguiano, C.J. and Adesope, O.O., Studying and Constructing Concept Maps: a Meta-Analysis. Educational Psychology Review, 2018, 30(2): 431‒455. https://doi.org/10.1007/s10648-017-9403-9 doi: 10.1007/s10648-017-9403-9

|
| [2] | Barta, A., Fodor, L.A., Tamas, B. and Szamoskozi, I., The development of students critical thinking abilities and dispositions through the concept mapping learning method – A meta-analysis. Educational Research Review, 2022, 37: 100481. https://doi.org/1016/j.edurev.2022.100481 |
| [3] | Novak, J.D., Learning, creating, and using knowledge: Concept maps as facilitative tools in schools and corporations, 2010. Routledge. |
| [4] | Farrokhnia, M., Pijeira-Díaz, H.J., Noroozi, O. and Hatami, J., Computer-supported collaborative concept mapping: The effects of different instructional designs on conceptual understanding and knowledge co-construction. Computers & Education, 2019,142: 103640. |
| [5] |
Novak, J.D., Concept mapping: A useful tool for science education. Journal of research in science teaching, 1990, 27(10): 937‒949. https://doi.org/10.1002/tea.3660271003 doi: 10.1002/tea.3660271003
|
| [6] | Novak, J.D. and Cañas, A.J., The theory underlying concept maps and how to construct them, 2008, Florida Institute for Human and Machine Cognition. |
| [7] |
Chiou, C.-C., Effects of concept mapping strategy on learning performance in business and economics statistics. Teaching in Higher Education, 2009, 14(1): 55‒69. https://doi.org/10.1080/13562510802602582 doi: 10.1080/13562510802602582
|
| [8] |
Lambiotte, J.G., Skaggs, L.P. and Dansereau, D.F., Learning from lectures: Effects of knowledge maps and cooperative review strategies. Applied Cognitive Psychology, 1993, 7(6): 483‒497. https://doi.org/10.1002/acp.2350070604 doi: 10.1002/acp.2350070604
|
| [9] | Sas, M., The effects of students' asynchronous online discussions of conceptual errors on intentionally flawed teacher-constructed concept maps, 2008, UNLV Retrospective Theses & Dissertations. 2800. |
| [10] |
Ryve, A., Can collaborative concept mapping create mathematically productive discourses? Educational Studies in Mathematics, 2004, 56(3): 157‒177. https://doi.org/10.1023/b:educ.0000040395.17555.c2 doi: 10.1023/b:educ.0000040395.17555.c2
|
| [11] |
Williams, C.G., Using Concept Maps to Assess Conceptual Knowledge of Function. Journal for Research in Mathematics Education JRME, 1998, 29(4): 414‒421. https://doi.org/10.5951/jresematheduc.29.4.0414 doi: 10.5951/jresematheduc.29.4.0414
|
| [12] |
Wilcox, S.K. and Sahloff, M., Assessment: Another Perspective on Concept Maps: Empowering Students. Mathematics Teaching in the Middle School, 1998, 3(7): 464‒469. https://doi.org/10.5951/mtms.3.7.0464 doi: 10.5951/mtms.3.7.0464
|
| [13] |
Baroody, A.J. and Bartels, B.H., Using Concept Maps to Link Mathematical Ideas. Mathematics Teaching in the Middle School, 2000, 5(9): 604‒609. https://doi.org/10.5951/mtms.5.9.0604 doi: 10.5951/mtms.5.9.0604
|
| [14] |
Gallenstein, N.L., Mathematics concept maps: assessing connections. Teaching Children Mathematics, 2011, 17(7): 436‒440. https://doi.org/10.5951/teacchilmath.17.7.0436 doi: 10.5951/teacchilmath.17.7.0436
|
| [15] | Afamasaga-Fuata, K., Concept mapping in mathematics, 2009. Springer. |
| [16] | Prestage, S. and Perks, P., Adapting and Extending Secondary Mathematics Activities, 2013. https://doi.org/10.4324/9780203462386 |
| [17] | Ollerton, M. and Watson, A., Inclusive Mathematics 11-18, 2001, London: Continuum. |
| [18] | Schmittau, J., Uses of concept mapping in teacher education in mathematics. in AJ Canãs, JD Novak & Gonázales (Eds), Concept Maps: Theory, Methodology, Technology. Proceedings of the First International Conference on Concept Mapping. 2004,571‒578. |
| [19] | Jin, H. and Wong, K., Training on concept mapping skills in geometry. Journal of Mathematics Education, 2010, 3(1): 104‒119. |
| [20] |
Jin, H. and Wong, K.Y., Mapping conceptual understanding of algebraic concepts: An exploratory investigation involving grade 8 Chinese students. International Journal of Science and Mathematics Education, 2015, 13(3): 683‒703. https://doi.org/10.1007/s10763-013-9500-2 doi: 10.1007/s10763-013-9500-2
|
| [21] |
Jin, H. and Wong, K.Y., Complementary measures of conceptual understanding: a case about triangle concepts. Mathematics Education Research Journal, 2021. https://doi.org/10.1007/s13394-021-00381-y doi: 10.1007/s13394-021-00381-y
|
| [22] |
Evans, T. and Jeong, I., Concept maps as assessment for learning in university mathematics. Educational Studies in Mathematics, 2023,113: 475–498. https://doi.org/10.1007/s10649-023-10209-0 doi: 10.1007/s10649-023-10209-0
|
| [23] |
Riegel, K., Evans, T. and Stephens, J.M., Development of the measure of assessment self-efficacy (MASE) for quizzes and exams. Assessment in Education: Principles, Policy & Practice, 2022, 29(6): 729‒745. https://doi.org/10.1080/0969594X.2022.2162481 doi: 10.1080/0969594X.2022.2162481
|
| [24] | Sweller, J., Human cognitive architecture. Handbook of research on educational communications and technology, 2008, 35: 369‒381. |
| [25] |
Evans, T. and Dietrich, H., Inquiry-based mathematics education: a call for reform in tertiary education seems unjustified. STEM Education, 2022, 2(3): 221‒244. https://doi.org/10.3934/steme.2022014 doi: 10.3934/steme.2022014
|
| [26] |
Sweller, J., van Merriënboer, J.J. and Paas, F., Cognitive architecture and instructional design: 20 years later. Educational Psychology Review, 2019, 31(2): 261‒292. https://doi.org/10.1007/s10648-019-09465-5 doi: 10.1007/s10648-019-09465-5
|
| [27] | Sweller, J., van Merrienboer, J.J. and Paas, F.G., Cognitive architecture and instructional design. Educational Psychology Review, 1998, 10(3): 251‒296. |
| [28] | Sweller, J., Evolution of human cognitive architecture. Psychology of learning and motivation, 2003, 43: 216‒266. |
| [29] | Klausmeier, H.J. and Feldman, K.V., Effects of a definition and a varying number of examples and nonexamples on concept attainment. Journal of Educational Psychology, 1975, 67(2): 174. |
| [30] |
Fukawa-Connelly, T.P. and Newton, C., Analyzing the teaching of advanced mathematics courses via the enacted example space. Educational Studies in Mathematics, 2014, 87(3): 323‒349. https://doi.org/10.1007/s10649-014-9554-2 doi: 10.1007/s10649-014-9554-2
|
| [31] | Mason, J. and Watson, A., Mathematics as a constructive activity: Exploiting dimensions of possible variation, in Making the connection: Research and teaching in undergraduate mathematics education. 2008,191‒204: The Mathematical Association of America Washington, DC. |
| [32] | Weber, K., Porter, M. and Housman, D., Worked Examples and Concept Example Usage in Understanding Mathematical Concepts and Proofs, in Making the Connection: Research and Teaching in Undergraduate Mathematics Education, C. Rasmussen and M.P. Carlson, Editors. 2008,245‒252. Mathematical Association of America. |
| [33] |
Sandefur, J., Mason, J., Stylianides, G.J. and Watson, A., Generating and using examples in the proving process. Educational Studies in Mathematics, 2013, 83(3): 323‒340. https://doi.org/10.1007/s10649-012-9459-x doi: 10.1007/s10649-012-9459-x
|
| [34] | Watson, A. and Mason, J., Mathematics as a constructive activity: learners generating examples, 2005, Mahwah, New Jersey: Lawrence Erlbaum Associates. |
| [35] | Alcock, L. and Weber, K., Undergraduates' example use in proof construction: Purposes and effectiveness. Investigations in Mathematics Learning, 2010, 3(1): 1‒22. |
| [36] | Zazkis, R. and Leikin, R., Exemplifying definitions: a case of a square. Educational Studies in Mathematics, 2008, 69(2): 131‒148. |
| [37] |
Tall, D. and Vinner, S., Concept image and concept definition in mathematics with particular reference to limits and continuity. Educational Studies in Mathematics, 1981, 12(2): 151‒169. https://doi.org/10.1007/bf00305619 doi: 10.1007/bf00305619
|
| [38] |
Goldenberg, P. and Mason, J., Shedding light on and with example spaces. Educational Studies in Mathematics, 2008, 69(2): 183‒194. https://doi.org/10.1007/s10649-008-9143-3 doi: 10.1007/s10649-008-9143-3
|
| [39] | Marton, F., Necessary conditions of learning, 2014. Routledge. |
| [40] | Zaslavsky, O. and Shir, K., Students' conceptions of a mathematical definition. Journal for Research in Mathematics Education, 2005, 36(4): 317‒346. |
| [41] | Henderson, K.B., A model for teaching mathematical concepts. The Mathematics Teacher, 1967, 60(6): 573‒577. |
| [42] | Liz, B., Dreyfus, T., Mason, J., Tsamir, P., Watson, A. and Zaslavsky, O., Exemplification in mathematics education. Proceedings of the 30th Conference of the International Group for the Psychology of Mathematics Education, 2006,126‒154. ERIC. |
| [43] | Tsamir, P., Tirosh, D. and Levenson, E., Intuitive nonexamples: The case of triangles. Educational Studies in Mathematics, 2008, 69(2): 81‒95. |
| [44] | Novak, J.D. and Musonda, D., A twelve-year longitudinal study of science concept learning. American educational research journal, 1991, 28(1): 117‒153. |
| [45] |
Nesbit, J.C. and Adesope, O.O., Learning With Concept and Knowledge Maps: A Meta-Analysis. Review of Educational Research, 2006, 76(3): 413‒448. https://doi.org/10.3102/00346543076003413 doi: 10.3102/00346543076003413
|
| [46] |
Gurlitt, J. and Renkl, A., Prior knowledge activation: how different concept mapping tasks lead to substantial differences in cognitive processes, learning outcomes, and perceived self-efficacy. Instructional Science, 2010, 38(4): 417‒433. https://doi.org/10.1007/s11251-008-9090-5 doi: 10.1007/s11251-008-9090-5
|
| [47] |
Kalyuga, S., Knowledge elaboration: A cognitive load perspective. Learning and Instruction, 2009, 19(5): 402‒410. https://doi.org/10.1016/j.learninstruc.2009.02.003 doi: 10.1016/j.learninstruc.2009.02.003
|
| [48] |
Chi, M.T.H., De Leeuw, N., Chiu, M.H. and LaVancher, C., Eliciting self-explanations improves understanding. Cognitive Science, 1994, 18(3): 439‒477. https://doi.org/10.1016/0364-0213(94)90016-7 doi: 10.1016/0364-0213(94)90016-7
|
| [49] |
Dunlosky, J., Rawson, K.A., Marsh, E.J., Nathan, M.J. and Willingham, D.T., Improving Students' Learning With Effective Learning Techniques. Psychological Science in the Public Interest, 2013, 14(1): 4‒58. https://doi.org/10.1177/1529100612453266 doi: 10.1177/1529100612453266
|
| [50] | Karpicke, J.D. and Blunt, J.R., Retrieval Practice Produces More Learning than Elaborative Studying with Concept Mapping. Science, 2011,331(6018): 772‒775. https://doi.org/doi:10.1126/science.1199327 |
| [51] |
O'Day, G.M. and Karpicke, J.D., Comparing and combining retrieval practice and concept mapping. Journal of Educational Psychology, 2021,113(5): 986–997. https://doi.org/10.1037/edu0000486 doi: 10.1037/edu0000486
|
| [52] | Fiorella, L. and Mayer, R.E., Learning as a generative activity, 2015. Cambridge University Press. |
| [53] | Skemp, R.R., Relational understanding and instrumental understanding. Mathematics teaching, 1976, 77(1): 20‒26. |
| [54] | Hiebert, J. and Lefevre, P., Conceptual and procedural knowledge in mathematics: An introductory analysis. Conceptual and procedural knowledge: The case of mathematics, 1986, 2: 1‒27. |
| [55] | Star, J.R., Reconceptualizing procedural knowledge. Journal for Research in Mathematics Education, 2005, 36(5): 404‒411. |
| [56] |
Inglis, M. and Mejía-Ramos, J.P., Functional explanation in mathematics. Synthese, 2021,198(S26): 6369‒6392. https://doi.org/10.1007/s11229-019-02234-5 doi: 10.1007/s11229-019-02234-5
|
| [57] | Chappuis, S. and Stiggins, R.J., Classroom assessment for learning. Educational leadership, 2002, 60(1): 40‒44. |
| [58] |
Buchholtz, N.F., Krosanke, N., Orschulik, A.B. and Vorhölter, K., Combining and integrating formative and summative assessment in mathematics teacher education. ZDM, 2018, 50(4): 715‒728. https://doi.org/10.1007/s11858-018-0948-y doi: 10.1007/s11858-018-0948-y
|
| [59] |
Crooks, N.M. and Alibali, M.W., Defining and measuring conceptual knowledge in mathematics. Developmental review, 2014, 34(4): 344‒377. https://doi.org/10.1016/j.dr.2014.10.001 doi: 10.1016/j.dr.2014.10.001
|
| [60] |
Bergqvist, E., Types of reasoning required in university exams in mathematics. The Journal of Mathematical Behavior, 2007, 26(4): 348‒370. https://doi.org/10.1016/j.jmathb.2007.11.001 doi: 10.1016/j.jmathb.2007.11.001
|
| [61] |
Iannone, P., Czichowsky, C. and Ruf, J., The impact of high stakes oral performance assessment on students' approaches to learning: a case study. Educational Studies in Mathematics, 2020,103(3): 313‒337. https://doi.org/10.1007/s10649-020-09937-4 doi: 10.1007/s10649-020-09937-4
|
| [62] |
Iannone, P. and Simpson, A., The summative assessment diet: how we assess in mathematics degrees. Teaching Mathematics and its Applications: An International Journal of the IMA, 2011, 30(4): 186‒196. https://doi.org/10.1093/teamat/hrr017 doi: 10.1093/teamat/hrr017
|
| [63] | Jeong, I. and Evans, T., Embedding concept mapping into university mathematics: comparison and validation of marking rubrics. Proceedings of the 13th Southern Hemisphere Conference on the Teaching and Learning of Undergraduate Mathematics and Statistics. 2021, 2‒16. Auckland, New Zealand. https://doi.org/10.17608/k6.auckland.20330460.v1 |
| [64] |
Johnson, R.B. and Onwuegbuzie, A.J., Mixed Methods Research: A Research Paradigm Whose Time Has Come. Educational Researcher, 2004, 33(7): 14‒26. https://doi.org/10.3102/0013189X033007014 doi: 10.3102/0013189X033007014
|
| [65] |
Braun, V. and Clarke, V., Using thematic analysis in psychology. Qualitative Research in Psychology, 2006, 3(2): 77‒101. https://doi.org/10.1191/1478088706qp063oa doi: 10.1191/1478088706qp063oa
|
| [66] |
Wigfield, A. and Eccles, J.S., Expectancy–Value Theory of Achievement Motivation. Contemporary Educational Psychology, 2000, 25(1): 68‒81. https://doi.org/10.1006/ceps.1999.1015 doi: 10.1006/ceps.1999.1015
|
| [67] |
Stylianides, A.J. and Stylianides, G.J., Seeking research-grounded solutions to problems of practice: classroom-based interventions in mathematics education. ZDM, 2013, 45(3): 333‒341. https://doi.org/10.1007/s11858-013-0501-y doi: 10.1007/s11858-013-0501-y
|
| [68] | Peterson, J.C., Effect of an Advanced Organizer, A Post Organizer, or Knowledge of a Behavioral Objective on Achievement and Retention of a Mathematical Concept, 1971. |
| [69] |
Peterson, J.C., Thomas, H.L., Lovett, C.J. and Bright, G.W., The Effect of Organizers and Knowledge of Behavioral Objectives on Learning a Mathematical Concept. Journal for Research in Mathematics Education JRME, 1973, 4(2): 76‒84. https://doi.org/10.5951/jresematheduc.4.2.0076 doi: 10.5951/jresematheduc.4.2.0076
|





Figures(6) / Tables(5)
Inae Jeong, Tanya Evans. Knowledge Organisers for learning: Examples, non-examples and concept maps in university mathematics[J]. STEM Education, 2023, 3(2): 103-129. doi: 10.3934/steme.2023008







 DownLoad:
DownLoad: