This work analyses the diagnosis and prognosis of cancer and heart disease data using five Machine Learning (ML) algorithms. We compare the predictive ability of all the ML algorithms to breast cancer and heart disease. The important variables that causes cancer and heart disease are also studied. We predict the test data based on the important variables and compute the prediction accuracy using the Receiver Operating Characteristic (ROC) curve. The Random Forest (RF) and Principal Component Regression (PCR) provides the best performance in analyzing the breast cancer and heart disease data respectively.
1.
Introduction
Machine learning (ML) algorithms help to detect and classify chronic diseases like cancer, heart disease, tumor, diabetes, and several others [1]–[5]. These techniques are useful in many statistical and optimization problems that allow computers to learn past observations and to detect patterns in new set of observations. In addition, some of the ML techniques help to identify the sources and order variables that plays significant role in the cause of the disease.
In the past decades, breast cancer (BC) has a high mortality rate [6]. In the United States, the risk of a woman having breast cancer at some point in her life is about 12%. In fact, one in eight women has the risk of developing breast cancer in her life [6]. Almost (80%) breast cancers are invasive and they break through the walls of the glands or ducts where they appear and then spread into surrounding breast tissue. However, the mortality rate has declined over the past years with the application of ML techniques. A recent analysis shows that the survival rate is 91% after 5 years of diagnosis and 80% after 15 years of diagnosis [6]. Vikas et al. compares several supervised learning classifiers, such as Naive Bayes, Support Vector Machine-Radial Basis Function (SVM-RBF) kernel, Radial Basis Function neural networks, and Decision trees to find the best classifier in breast cancer datasets [7]. Their studies show that SVM-RBF kernel is more accurate (96.84%) than the other classifiers. T. Joachims et al. shown (95.06%) of accuracy with the use of neuron-fuzzy techniques [7]. Other researchers have worked on several data mining algorithms such as SVM, k-nearest neighbor algorithm (IBK), and Bloom Filter (BF) Tree on breast cancer data [8].
Heart disease has created grave concerns among medical researchers. A recent analysis has shown that every year about 735,000 Americans have heart attacks. Of these, 525,000 are first heart-attack victims and 210,000 have already had heart attacks [9]. One of the major challenges in heart disease is its correct detection inside a human. Since a lot of parameters and technicality are involved for accurately predicting this disease, there is a vast scope of research including ML algorithms. In ref. [10], the authors used logistic regression, artificial neural network, and support vector machine techniques on heart disease data and concluded the highest classification 85% of accuracy with logistic regression model. Other authors also worked on artificial neural network and fuzzy neural network on Cleveland heart disease data and obtained 86.8% of accuracy [11]. Thus ML techniques play a crucial role in the diagnosis and prognosis of heart disease in patients.
In previous studies involving the analysis of BC and heart disease data, even though the ML algorithms provided good prediction accuracy, most of the models lack good interpretations. An important feature of classification problem is that the model should be able to order key variable that causes the disease. Therefore to overcome some of the drawbacks in the previous studies, we analyze the BC and heart disease data using five ML models that have good prediction accuracy and the results obtained are easy to interpret. The models used are as follows: Logistic regression, Principal component regression, Random Forest, Multivariate adaptive regression splines and Support vector machine for breast cancer and heart disease diagnosis and prognosis. The objective of this study is to firstly predict the Class variable and to conclude whether a patient's tumor is malignant or benign and secondly to determine the attributes which are important to help detect that a patient suffering from cancer.
The paper is organized as follows: The methodology section presents a brief background of the five supervised machine learning techniques. The regularization techniques to fit the best predictive model are also discussed. In the data background section, we present a brief description of the datasets used in this studies. We discuss the association of the datasets in the exploratory data analysis section. Applications of the models to cancer and heart disease data are presented in the results and discussion section. In the last section, we present the conclusion and discussion the suitability of our models to diagnose the cancer and heart disease data.
2.
Methodology
This section briefly describes the five machine learning techniques that will be used to analyze breast cancer and heart disease data. We will discuss the regularization techniques to obtain the best model with important features in the datasets. We will also estimate the tuning parameters of the models to obtain the lowest mean squared error, lowest miss-classification rate and highest predictive accuracy. We begin with the logistic regression model.
2.1. Logistic regression model
Logistic regression is a powerful classification algorithm that is used to predict the probability of a categorical variable. We assume that the predictors (xk) are independent of each other, so the model has no multicollinearity. We express the model as:
where
p is the probability of presence of the characteristic of interest and
β0,
β1, …,
βk are the coefficient parameters. The logit transformation is defined as the log odds that is
lnp1−p. So the logistic regression model is similar to a linear regression, but it is constructed using the natural logarithm of the odds of the target variable. Thus:
Since logistic regression predicts probabilities, rather than classes, we can fit it into the data using the likelihood technique. The likelihood helps to find the best model that explains the datasets well. The dataset used in this study contains a vector of features (xi) and an observed class (yi). We assume the probability of that class is either p, when yi = 1, or 1−p, when yi = 0. So the likelihood function of Eq 2 is as follows:
We now seek to estimate the parameters β0, β1, …, βk that maximize the likelihood function L(β0 + β1x1 + … + βkxk) in Eq 3. We maximize the logarithm of the likelihood function [12] as follows:
We then use some regularization techniques to obtain a parsimonious model with important features from the original model. The regularization technique penalizes the magnitude of coefficients of features thereby minimizing the error between predicted and actual observations. In this study, the regularization techniques used in the logistic regression are the L1 and L2 regularization.
2.1.1. L1 regularization
We use the least absolute shrinkage and selection operator (lasso) regularization technique by adding an L1 penalty term in Eq 4. This forces the absolute value sum of the regression coefficient to be less than a fixed value. This is due to the fact that the tuning parameter makes certain coefficients to be set to zero, effectively by choosing a simpler model that does not include those coefficients [13]. So we maximize the penalized versions as follows:
where
λ is a tuning parameter that controls the strength of penalty term. The parameter
λ is selected in a way that the resulting model minimizes the out of sample error.
2.1.2. L2 regularization
We also use Ridge-regression by adding a L2 penalty term in Eq 4. This regularization technique overcomes the multicollinearity problem in our data. When we have multicollinearity in the data, the variance of estimation goes to large values. So the parameter estimation may be far from the true value. To overcome this issue, we add a degree of bias to the regression estimates and shrink the estimators to the true parameters. We maximized the L2 penalized versions [14] as follows:
where
λ controls the amount of regularization.
2.2. Principal component regression
Principal Component Regression (PCR) is based on the principal components of data. We perform PCR technique by transforming the independent variables (X) to their principal components (PC) of data. An important feature of principal components is that they reduce the dimension of dataset that explain most of the variability of the original data [15]. The regression equation can be expressed as:
where
Y is the standardized dependent variable,
X is the standardized independent variables,
B is the regression coefficients to be estimated and
ε is the residual term. We now estimate the regression coefficients using ordinary least square method as follows:
Since the variables are standardized, X′X is a correlation matrix of independent variables from the data. In order to perform the PCR, we transform the independent variables to their principal components as follows:
where
D is a diagonal matrix of the eigenvalues of
X′
X;
P is the eigenvector matrix of
X′
X where
P is an orthogonal matrix, that is
P′
P =
I, where
I is an identity matrix. Now
PDP′ gives us the new matrix of principal components (
Z′
Z). The new variables
Z are the weighted averages of the original variables
X. Since these new variables are principal components, their correlations with each other would be all zero. We then regress
Y on
Z obtaining least squares estimates of
A. The estimation formula is as follows:
2.3. Random forest
The random forest technique is a type of additive model that predicts the data by combining decisions from a sequence of base models. It reduces the variance by avoiding over fitting of the model. The class of base models can be expressed as follows:
where the final model
g is the sum of simple base models
fi. We define each base classifier as a simple decision tree. So it is an ensemble technique that considers multiple learning algorithms to obtain best predictive model. At this point, all the base models or trees are made independently using a different subsample of the data. Once we have a new generated training set, we divide it randomly into two parts. The two-third samples are used to build a tree and the one-third samples are used to obtain the predictions of trees. We take the majority vote of these one-third predictions as the predicted value for the data point and then we estimate the error. For a full detail study of Random Forest, the reader is referred to the reference in
[16]. We now present the algorithm of random forest that is used in this study:
-
We first take a random sample of size N with replacement from the data.
-
Take a random sample without replacement of the predictors.
-
Construct a split by using predictors selected in step 2.
-
Repeat steps 2 and 3 for each subsequent split until the tree is as large as desired.
-
Drop the out-of-bag data down the tree. We then store the class assigned to each observation along with each observation's predictor values.
-
Repeat steps 1–5 for large number of times.
-
For each observation in the dataset, we count the number of trees that it is classified in one category over the number of trees.
-
Assign each observation to a final category by a majority vote over the set of trees. Thus, if 51% of the time over a large number of trees a given observation is classified as a “1” that becomes its classification.
The random forest includes three main tuning parameters such as node size, number of trees (ntree) and number of predictors sampled (mtry) for splitting. To build a best predictive model, we estimate the best tuning parameters and important variables using mean decrease accuracy (MDA) and mean decrease Gini (MDG) indices. The MDA determines the importance of a variable by measuring the change in prediction accuracy, when the values of the variable are randomly permuted compared to the original observations. However, the MDG index is a measure of how each variable contributes to the homogeneity of the nodes and leaves in the resulting random forest. For the details of these methodologies, consult [17] and references therein.
2.4. Multivariate Adaptive Regression Splines (MARS)
MARS is a non-parametric regression technique. It is used to study the nonlinear relationship between a target variable and a set of predictors with the help of splines. We partition the training data set into piecewise linear segments with different gradients. These segments are connected smoothly together and we define them as splines [18]. The connection points between the segments are known as knots. An important property of MARS model is that it makes no assumptions about the underlying functional relationships between dependent and independent variables. We now define the MARS model as follows:
where
y is a response variable,
f(
x) is a “true” underlying function,
x = (
x1,
x2, …,
xp)
T, and epsilon is the error term. To approximate a nonlinear relationship, we first develop a flexible model using piecewise linear basis functions (BFs) as:
At this point, f(x) can be expressed as a linear combination of BFs and their interactions:
where each
λm is a BF,
βi is constant coefficient that is estimated through a least-squares method. In order to fit the MARS model with the data, we perform forward stepwise technique on the training dataset with initialize value of
M = 0,
λ0(
xi) = 1, and
f(
xi) =
β0λ0(
xi). At each subsequent step, we add the basis pair that gives the maximum reduction in the training error. This process of adding BFs continues until the model reaches some predetermined maximum number. The forward stepwise process over fits the model. We improve the model using backward deletion technique. This technique keeps deleting the less significant terms of the model to find best sub-model. We compare the sub-models using Generalized Cross-Validation (GCV) to obtain the best one. The GCV is the mean-squared residual error divided by a penalty that is dependent on the model complexity
[19] i.e.:
where
M is the number of BFs,
d is a penalty for each basis function included in the developed submodel,
N is the number of data sets, and
f(
xi) denotes the MARS predicted values. So the numerator term is the mean square error of the evaluated model, that penalized by the denominator. In this study, we make the order of important variables by analyzing the variance (ANOVA) between the BFs involving one variable and the BFs involving pairwise interactions. For the details of this methodology, please see the reference in
[16].
2.5. Support Vector Machine (SVM)
SVM is a supervised ML technique that is used for both classification and regression tasks. It identifies the optimal decision boundary that separates data points from different classes, and then it predicts the class of test observations using the separation boundary [20]. So we first normalize and scale the variables to obtain a decision boundary as follows:
which is a non-convex programming problem which computes the distance from a wrongly classified observation
xi to its corresponding margin. Here,
ξi ≥ 0 measures the degree of missclassification of the
i-th individual. We now consider the problem as follows:
where
∑ni=1ξi≤C and the constant C determines the possible miss classification rate. The higher the value of C, the less likely it is that the SVM algorithm will miss classify a point. So in this study our approach is to tune the parameter
C. Now we drop the constraint ║β║ = 1 and set
M = 1/║β║ in the problem and we obtain:
The above equation is a convex programming problem and can be solved via Lagrangian and Karush-Kuhn-Tucker (KKT) conditions as follows:
Setting ∂ℒ∂β,∂ℒ∂β0,∂ℒ∂ξi to be 0 gives the following conditions:
where,
αi ≥ 0,
γi ≥ 0, and
ξi ≥ 0. We can solve the Lagrangian problem via coordinate descent method. Now the KKT complementary slackness condition yields the following case:
In this study, we compute the SVM for different values of C and choose the optimal C that maximizes the model cross-validation accuracy. We use the caret package in R software to compute the linear SVM, radial SVM techniques. For more details of the SVM technique, the reader is referred to [13] and references therein.
2.6. Data background
In this study, we analyzed the breast cancer [10] and heart disease [11] datasets, that are available in UCI machine learning repository. The breast cancer datasets has 699 observations with 11 variables. Table 1 summarizes the short description of the breast cancer dataset. The “Class” column is the response variable that includes the status of a tumor as malignant (breast cancer) or benign (not breast cancer). Our objective is to predict the “Class” variable and to conclude whether a patient's tumor is malignant or benign.
For the heart disease data, we used 14 variables that play important role in causing heart disease. The variables are such as age of patients, sex, chest pain, resting blood pressure, fasting blood sugar, number of major vessel and several others. Table 2 summarizes the short description of heart disease dataset. The target variable is num that contains the rate of diameter narrowing of coronary artery. It takes value 0 when the rate < 50% and value 1 when the rate > 50% We assume that the patient has no heart disease when num is 0 and the patient has heart disease when num is 1. The goal is to predict the num variable using the ML techniques to determine whether a patient has heart disease.
In the next section, we perform some exploratory data analysis by studying the association and correlation of all variables in the data sets, which are effective in capturing the characteristic and patterns of the data.
3.
Exploratory data analysis
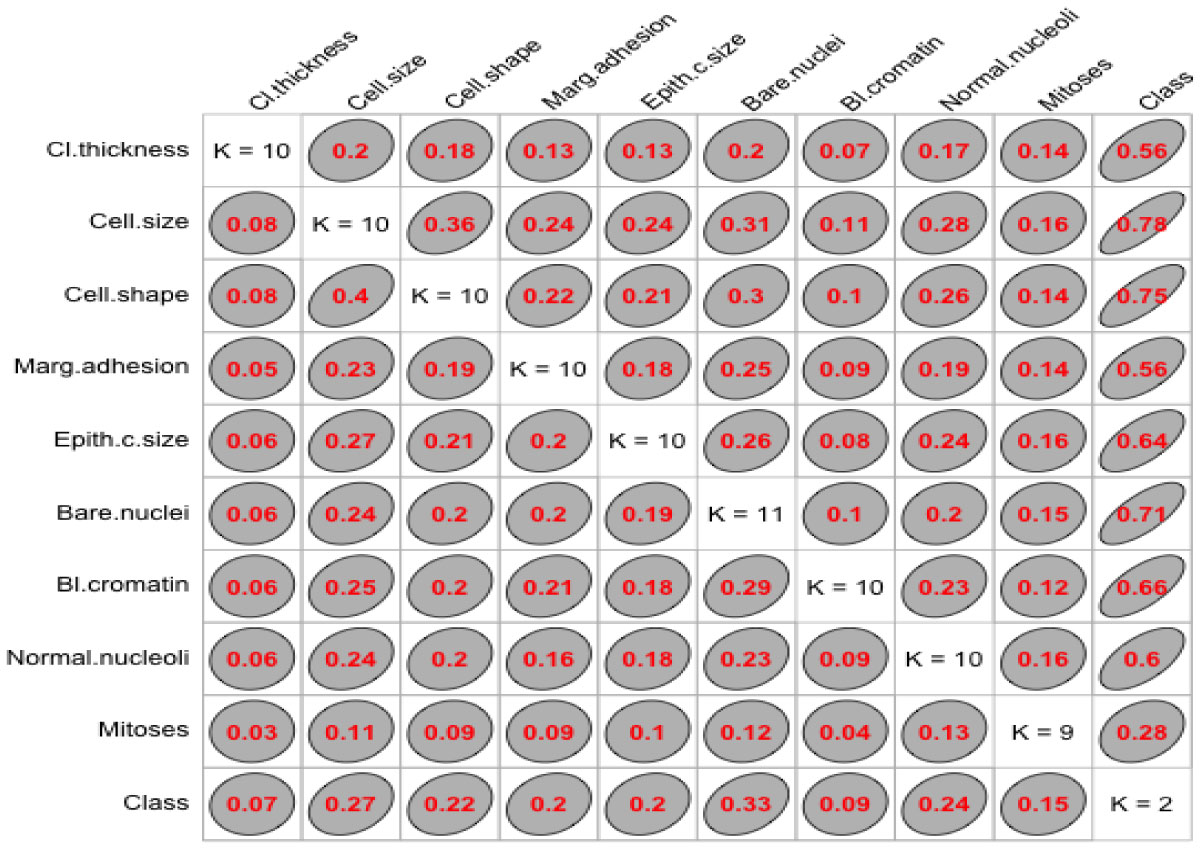
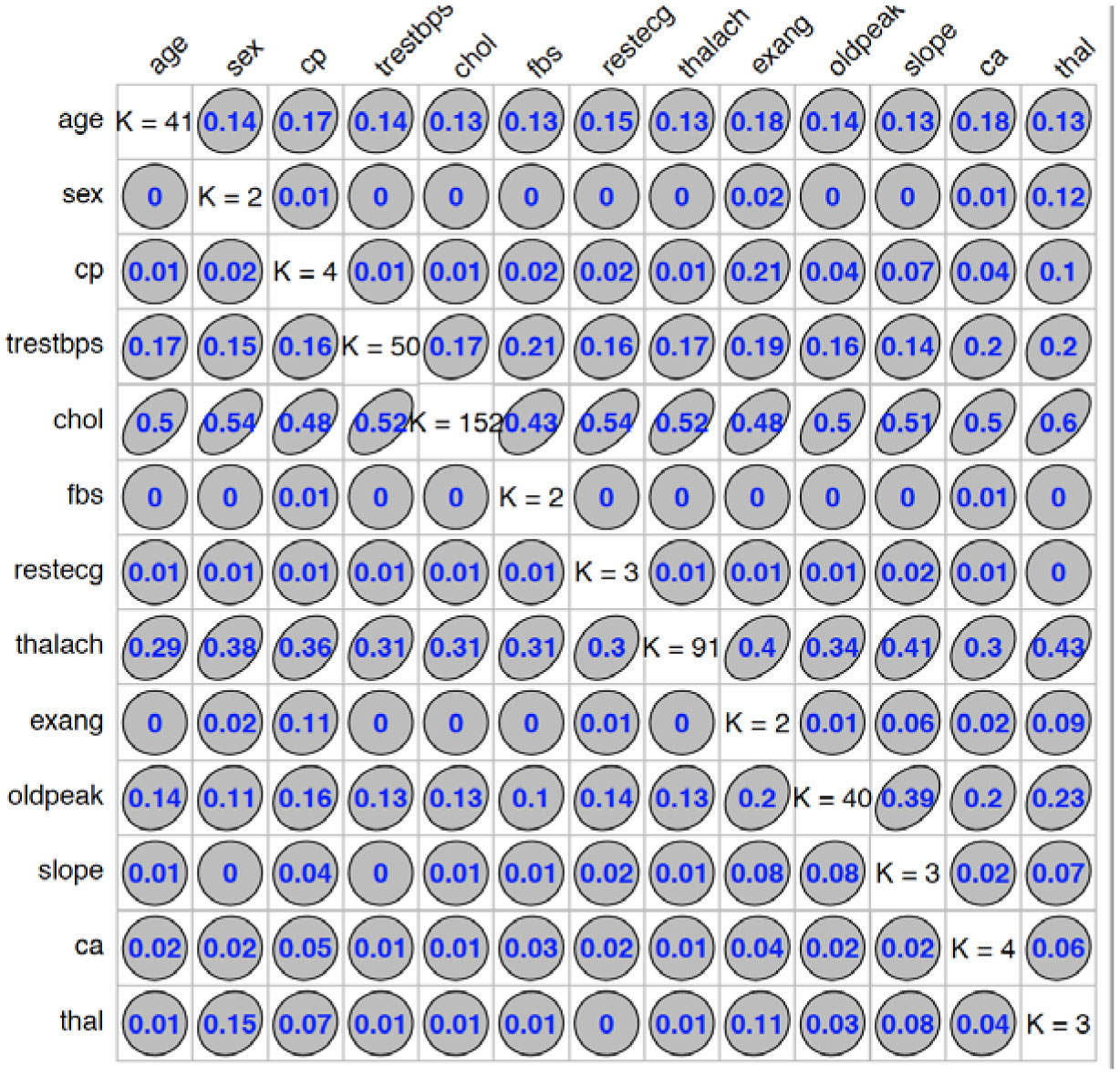
We used “GoodmanKruskal” library in R program to determine the association among predictors. Figures 1 and 2 represent the association among the variables for cancer and heart disease data, respectively. In these figures, the diagonal element K refers to the number of unique levels for each variable. The measure of association indicates the strength of the relationship among the variables. The off-diagonal elements contain the forward and backward measures (τ) for each variable pair. In Figure 1, we observe that the variable Cell.size (x) is almost perfectly predictable (i.e. τ(x,y) = 0.78) from Class (y) and this forward association is quite strong. On the other hand, the reverse association between Class and Cell.size (τ(x,y) = 0.27) is not strong association as forward. Similarly, we can analyze the forward and backward association among the variables in heart disease data (see Figure 2).
4.
Results and discussions
In this section we present the results of the machine learning techniques when they are applied to the breast cancer and heart disease datasets. We trained five ML models to accurately predict whether a sample patient has been diagnosed with heart disease or cancer. We randomly split the data into training set (67% for building a predictive model) and test set (33% for evaluating the model). We then compute the prediction mean squared error (PMSE), missclassification rate (MCR), and prediction accuracy using the ROC curve that validates the fitted model with the data. The analyses was done by R statistical programs.
4.1. Analysis of fitted models
4.1.1. Logistic regression
We first used the logistic regression technique for the train data to build a predictive model. In this case, we used the lasso regularization with L1 penalty and obtained the tuning parameter λ with cross-validation. The L1 penalty is used for both variable selection and shrinkage, since it has the effect of forcing some of the coefficient estimates to be zero. Tables 3 and 4 represent important predictors using the best predictive model with L1 penalty. It is clear that Cell.size for cancer disease (Table 3) and Age, Sex, Trestbps, Chol, Fbs and Restecg for heart disease (Table 4) are not important predictors. We then predict the test data using this predictive model and compute the accuracy.
We also used the Lasso regression model with L2 penalty term on the parameters β. The reason is that L2 penalty overcomes the multicollinearity issue of the datasets. We tuned λ until we find a model that generalizes well to the test data. In this case, we select the tuning parameter by 10-fold cross validation. From Table 5, we see that the prediction mean squared error and classification rate of this model are very low for both cancer and heart disease data.
4.1.2. Principal component regression
We used a dimension reduction tool, namely principal component regression to reduce the set of correlated predictors. In this case, we transformed the entire dataset into three principal components to build the predictive model. The first principal component contains most of the variability in the data. PCR also overcomes the multicollinearity issue of the cancer and heart disease datasets. We compared the predictive performance of PCR to the other methodologies in Table 5.
4.1.3. Random forest
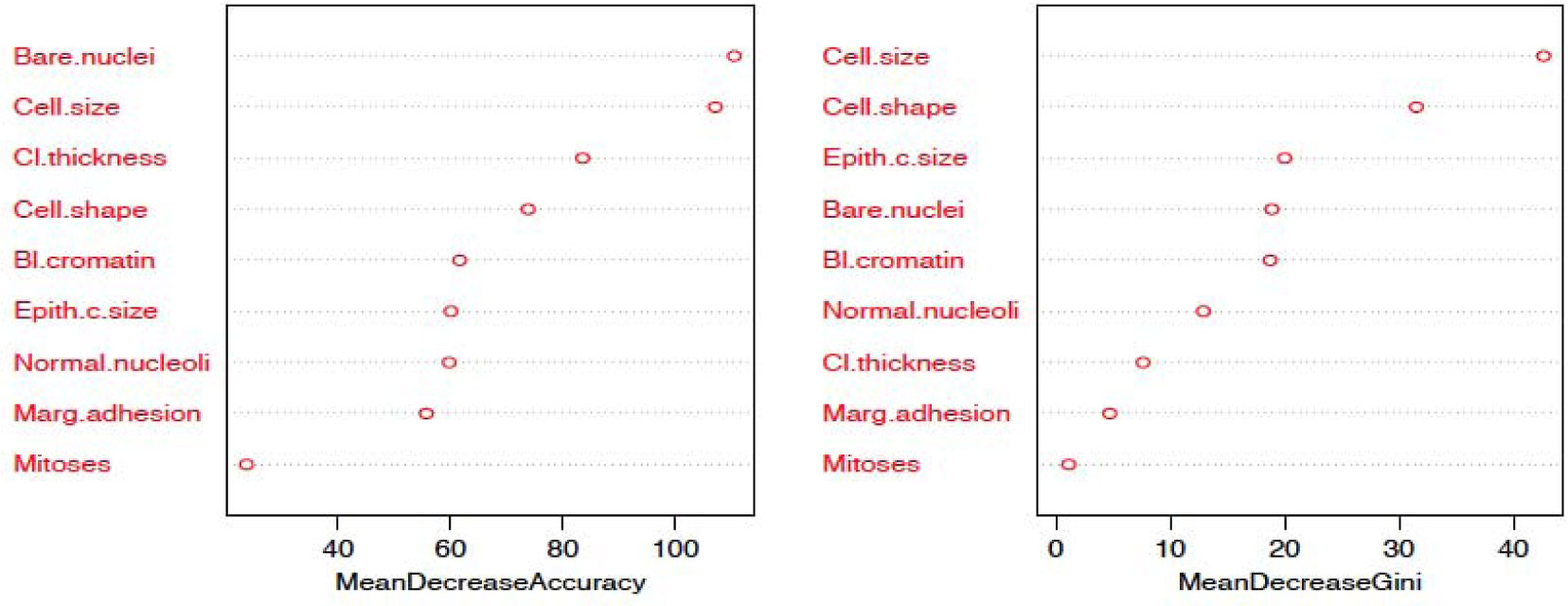
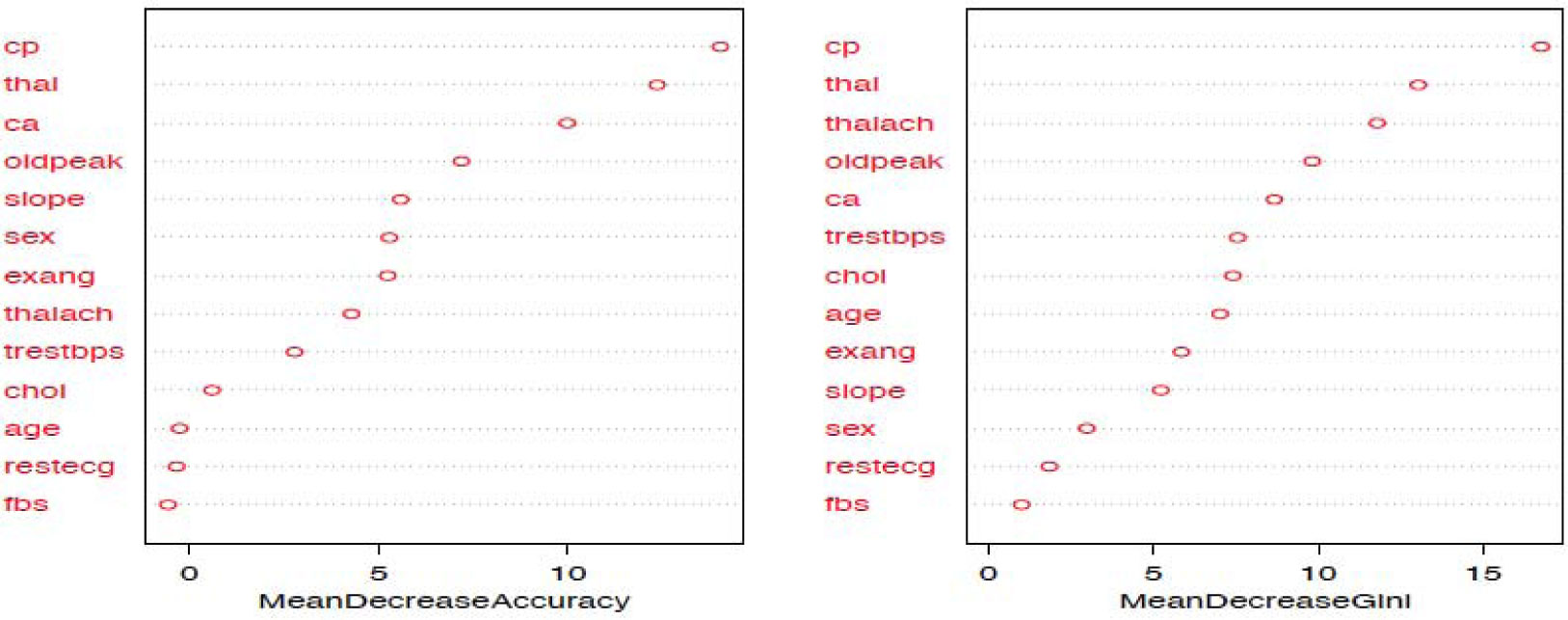
The random forest model is fit with the train data to build a predictive model. We used 500 trees and sampled 3 variables at each split. We obtained a very good prediction accuracy on test data, which are 97.38% for cancer disease, and 88.10% for heart disease. We also ranked the variable importance using the Mean Decrease Accuracy and Mean Decrease Gini indices. From Figure 3, the predictor Cell.size is the most important variable and the predictor Mitoses is the least important variable in causing breast cancer using the Mean Decrease Gini index. From Figure 4, we see that the predictor Cp is the most important predictor and the predictor Fbs is the least important predictor in causing heart disease.
4.1.4. Multivariate adaptive regression splines
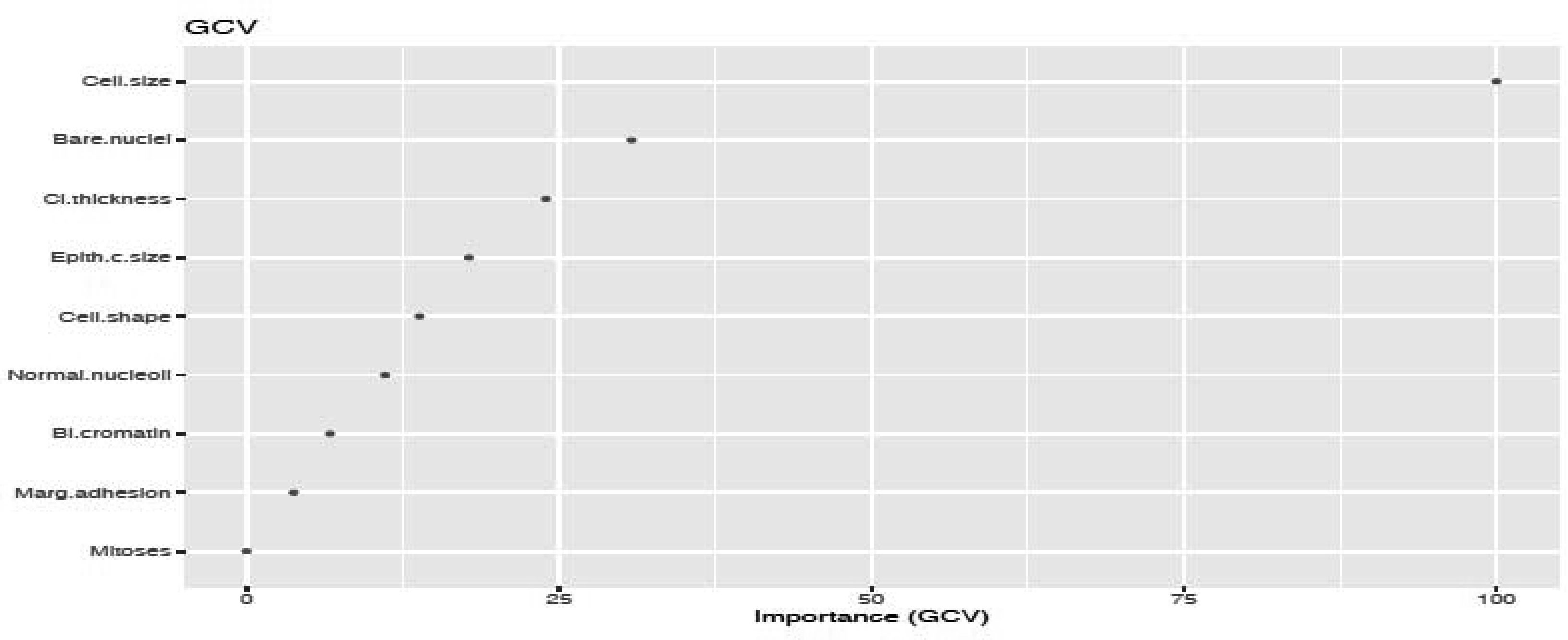
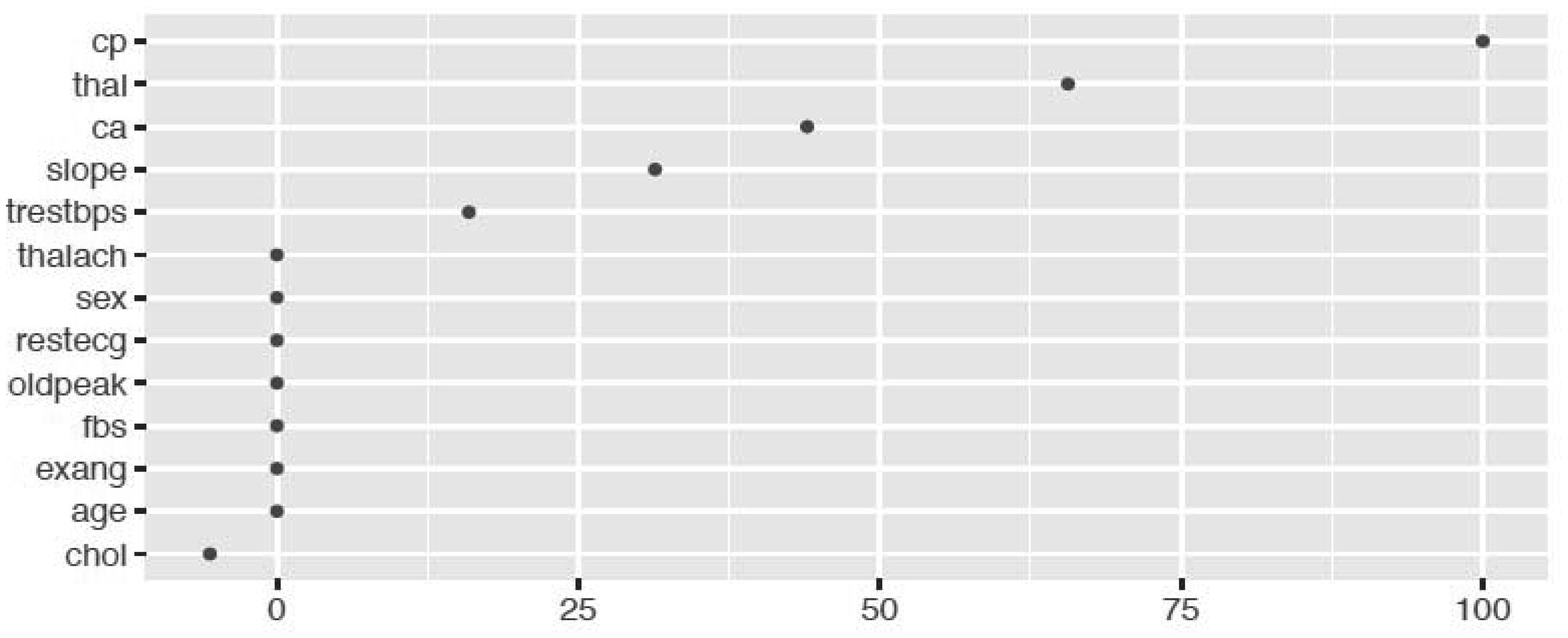
We fitted the MARS model with the train data using 3-fold cross-validation. The reason of using MARS model is that it does not assume or impose any particular type or class of relationship between the predictor variables and the target variable. We ranked the predictors in terms of importance using the Generalized Cross-Validation (GCV) (see Figures 5 and 6). The GCV is a type of regularization technique that trades-off goodness-of-fit against the model complexity. It adjusts the training residual sum of squares (RSS) and takes into account the flexibility of the model. In Figures 5 and 6, we see that Cell.size and Cp are the most important variables for breast cancer and heart disease, respectively, which are consistent with the results obtained using logistics regression and random forest.
4.1.5. Support vector machine
We analyzed two types of support vector machine technique namely, SVM linear and SVM kernel. To fit the models, we first standardized the data and used 10-fold cross-validation in training data. We evaluated different cost levels (C) to obtain the best predictive model with optimal cost. For SVM linear, we obtained the highest accuracy of predictive model when costs are 0.05 (cancer data) and 0.04 (heart disease data). On the other hand, for Kernel SVM, we achieved the highest accuracy when γ is 0.001 (cancer data) and 0.002 (heart disease data). In Table 5, we summarize the predictive mean square error (PMSE) for the predicted probabilities and missclassification rate (MCR) for both cancer and heart disease data.
4.1.6. Model accuracy
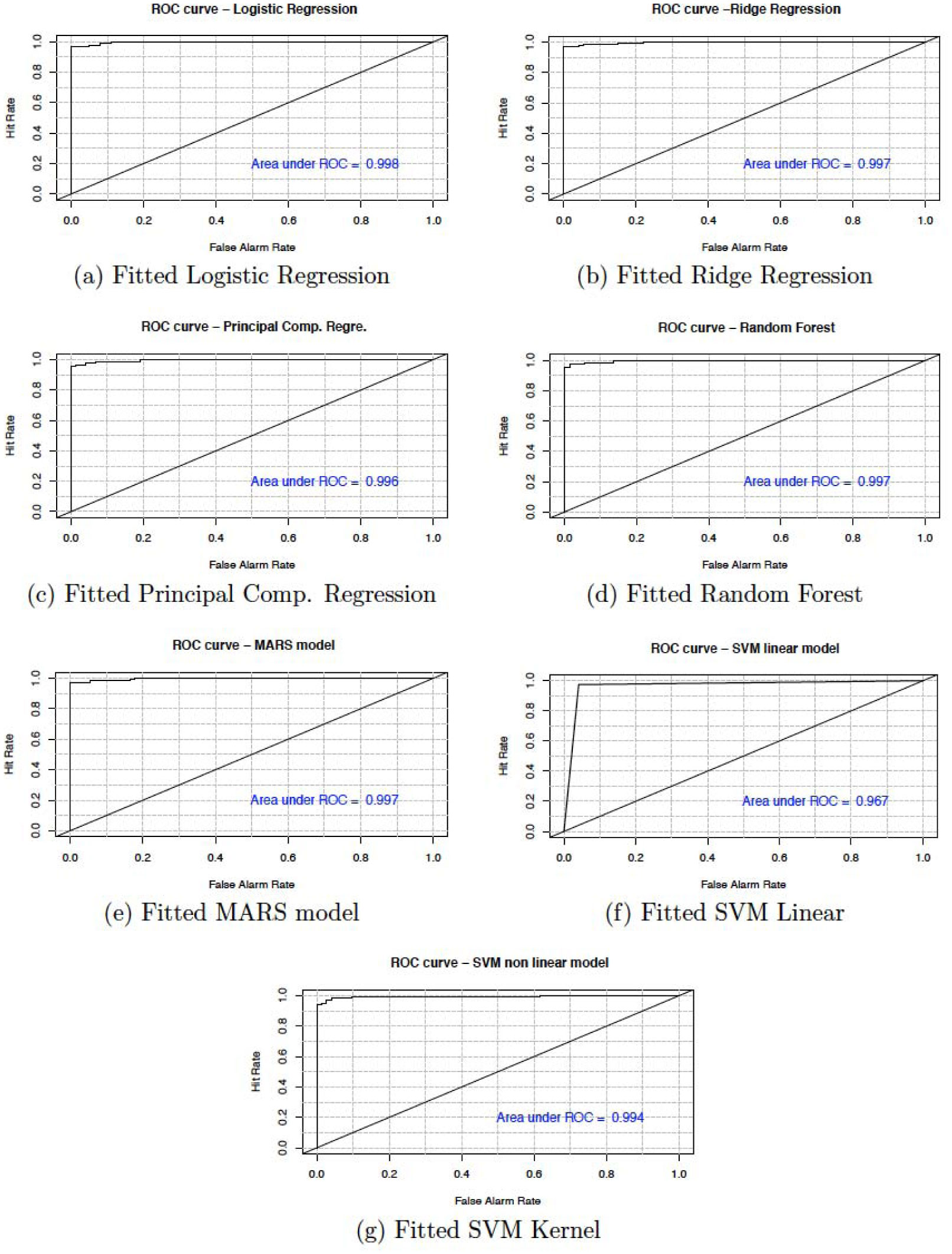
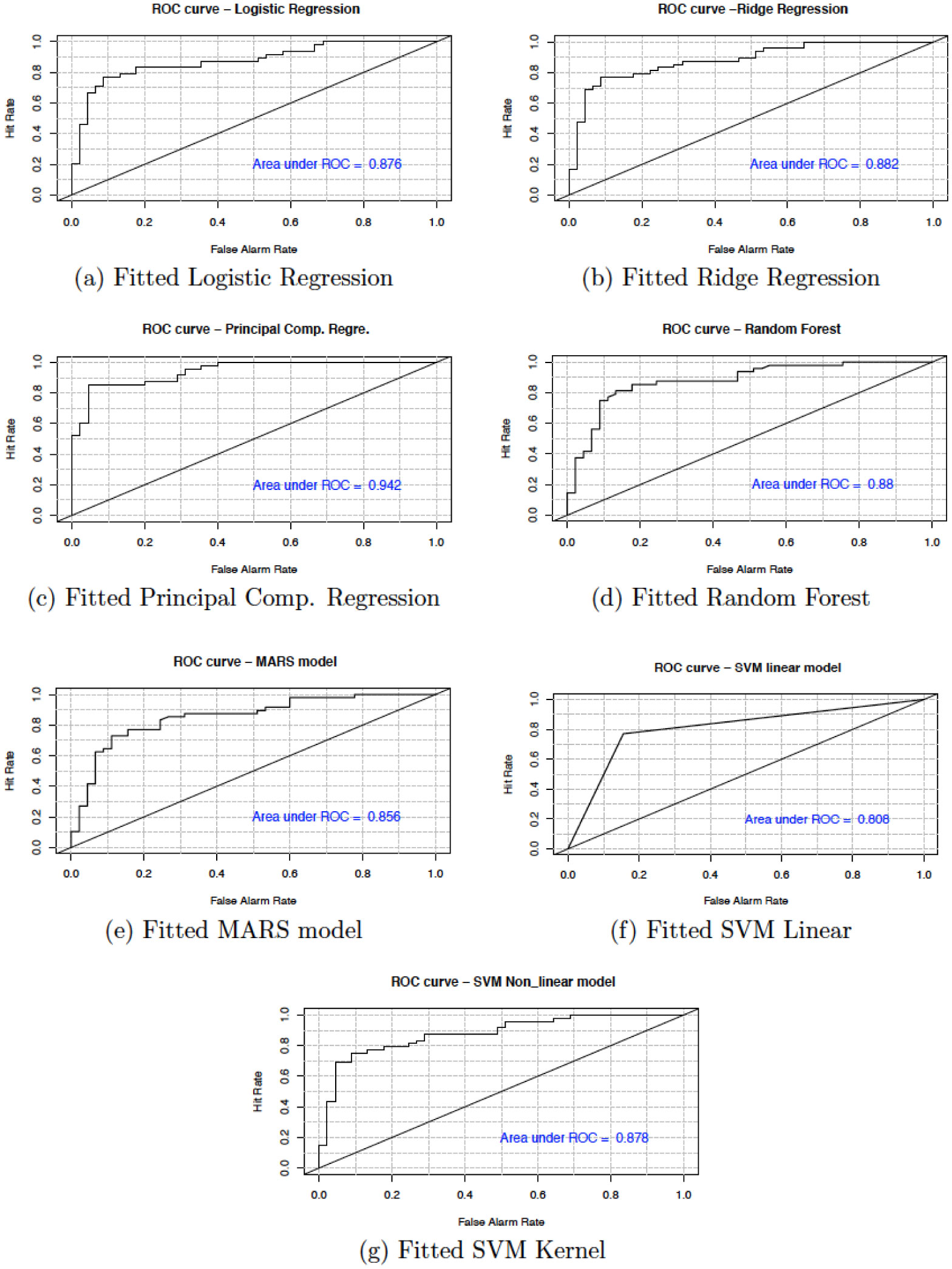
In this section, we present the accuracy of our predictive models used in the study. Table 6 shows the sensitivity, specificity, accuracy and confidence interval with 95% significance level for both cancer and heart disease data. Here, sensitivity is the True Positive Rate or the proportion of identified positives among the cancer or heart disease-positive population. Specificity measures the True Negative Rate (TNR) that is the proportion of identified negatives among the cancer or heart disease-negative population. We plotted the ROC curve between True Positive Rate (Y-axis) and False Positive Rate (X-axis) (see Figures 7 and 8). In these figures, the diagonal line represents the threshold (0.5) of ROC curve. We see that the area under the curve approaches to 1 for the logistic regression (0.998) and random forest (0.997) in cancer data and, for principal component regression (0.942) in heart disease data.
5.
Conclusion
In this study, we analyzed five different machine learning techniques namely; Logistic regression with L1 and L2 regularization, Principal component regression, Random forest, MARS model and SVM model. The objective is to use these algorithms to predict the presence of breast cancer and heart disease in patients.
We improved the model for each technique by removing the non-significant variables through cross-validation and using different tuning parameters. Once the predictive models were built, we checked their efficiency in the diagnosis and prognosis of disease using test data. In order to obtain the most efficient model, we compared the prediction mean squared error and miss-classification rate among these models (see Table 5). We also compared the prediction accuracy, sensitivity and specificity to find the best classification accuracy (see Tables 6 and 7).
Additionally, from the plot of the variable importance, we also conclude that a patient suffering from breast cancer are highly affected by the uniformity of cell size (Cell.size), bare nuclei (Bare.nuclei), uniformity of cell shape (Cell.shape), and bland chromatin (Bl.cromatin). We also observed that heart disease is highly affected by the chest pain (cp ), maximum heart rate (thalach), number of major vessels (ca), Thalassamia (Thal) and slope of the peak exercise ST segment (slope) of the patient (see Tables 3,4 and Figures 3,4).
We have shown that the selection of the top variables, based on the variable importance of models, will help researchers to quickly identify specific variables which are relevant to causing breast cancer and heart diseases. The results show that all the techniques described are very efficient to describe and predict the breast cancer and heart disease data. However, based on the area under the curve of the receiver operating characteristic (ROC) we observe that the RF and PCR provides the best fit to the breast cancer and heart disease data. We recall that the ROC curve is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied.





 DownLoad:
DownLoad: