Citation: Vandana Gulati, Mansi Dass Singh, Pankaj Gulati. Role of mushrooms in gestational diabetes mellitus[J]. AIMS Medical Science, 2019, 6(1): 49-66. doi: 10.3934/medsci.2019.1.49

| [1] |
Buchanan TA, Xiang AH (2005) Gestational diabetes mellitus. J Clin Invest 115: 485–491. doi: 10.1172/JCI200524531

|
| [2] |
Konstanze M, Holger S, Mathias F (2012) Leptin, adiponectin and other adipokines in gestational diabetes mellitus and pre-eclampsia. Clin Endocrinol 76: 2–11. doi: 10.1111/j.1365-2265.2011.04234.x
|
| [3] |
Bellamy L, Casas JP, Hingorani AD, et al. (2009) Type 2 diabetes mellitus after gestational diabetes: a systematic review and meta-analysis. Lancet 373: 1773–1779. doi: 10.1016/S0140-6736(09)60731-5
|
| [4] | Bener A, Saleh NM, Al-Hamaq A (2011) Prevalence of gestational diabetes and associated maternal and neonatal complications in a fast-developing community: global comparisons. Int J Women's Health 3: 367–373. |
| [5] |
Reece EA, Leguizamón G, Wiznitzer A (2009) Gestational diabetes: the need for a common ground. Lancet 373: 1789–1797. doi: 10.1016/S0140-6736(09)60515-8
|
| [6] |
Hod M, Kapur A, Sacks DA, et al. (2015) The International Federation of Gynecology and Obstetrics (FIGO) Initiative on gestational diabetes mellitus: A pragmatic guide for diagnosis, management, and care. Int J Gynecol Obstet 131: S173–S211. doi: 10.1016/S0020-7292(15)30033-3
|
| [7] |
Craig WJ (2010) Nutrition Concerns and Health Effects of Vegetarian Diets. Nutr Clin Pract 25: 613–620. doi: 10.1177/0884533610385707
|
| [8] |
De Silva DD, Rapior S, Hyde KD, et al. (2012) Medicinal mushrooms in prevention and control of diabetes mellitus. Fungal Divers 56: 1–29. doi: 10.1007/s13225-012-0187-4
|
| [9] |
Martel J, Ojcius DM, Chang CJ, et al. (2017) Anti-obesogenic and antidiabetic effects of plants and mushrooms. Nat Rev Endocrinol 13: 149–160. doi: 10.1038/nrendo.2016.142
|
| [10] | Royse DJ, Singh M (2014) A global perspective on the high five: Agaricus, Pleurotus, Lentinula, Auricularia & Flammulina, 1–6. |
| [11] | Valverde ME, Hernndez-Prez T, Paredes-Lopez O (2015) Edible Mushrooms: Improving Human Health and Promoting Quality Life. Int J Microbiol 2015: 376387. |
| [12] |
Horowitz S (2011) Medicinal Mushrooms: Research Support for Modern Applications of Traditional Uses. Altern Complem Ther 17: 323–329. doi: 10.1089/act.2011.17602
|
| [13] | Mohamed M, Nassef D, Waly E, et al. (2012) Earliness, Biological efficiency and basidiocarp yield of Pleurotus ostreatus and P. columbinus oyster mushrooms in response to different sole and mixed substrates. Assiut J Agric Sci 43: 91–114. |
| [14] |
Gargano ML, van Griensven LJ, Isikhuemhen OS, et al. (2017) Medicinal mushrooms: Valuable biological resources of high exploitation potential. Plant Biosys 151: 548–565. doi: 10.1080/11263504.2017.1301590
|
| [15] | Deepalakshmi K, Mirunalini S (2011) Therapeutic properties and current medical usage of medicinal mushroom: Ganoderma lucidum. Inter J Pharm Sci Res 2: 1922–1929. |
| [16] |
Klupp NL, Kiat H, Bensoussan A, et al. (2016) A double-blind, randomised, placebo-controlled trial of Ganoderma lucidum for the treatment of cardiovascular risk factors of metabolic syndrome. Sci Rep 6: 29540. doi: 10.1038/srep29540
|
| [17] |
Holliday JC, Cleaver MP (2008) Medicinal Value of the Caterpillar Fungi Species of the Genus Cordyceps (Fr.) Link (Ascomycetes). A Review. Int J Med Mushrooms 10: 219–234. doi: 10.1615/IntJMedMushr.v10.i3.30
|
| [18] |
Firenzuoli F, Gori L, Lombardo G (2008) The Medicinal Mushroom Agaricus blazei Murrill: Review of Literature and Pharmaco-Toxicological Problems. Evid Based Complement Alternat Med 5: 3–15. doi: 10.1093/ecam/nem007
|
| [19] |
Vitak T, Yurkiv B, Wasser S, et al. (2017) Effect of medicinal mushrooms on blood cells under conditions of diabetes mellitus. World J Diabetes 8: 187–201. doi: 10.4239/wjd.v8.i5.187
|
| [20] |
Lei H, Guo S, Han J, et al. (2012) Hypoglycemic and hypolipidemic activities of MT-α-glucan and its effect on immune function of diabetic mice. Carbohydr Polym 89: 245–250. doi: 10.1016/j.carbpol.2012.03.003
|
| [21] |
Khan MA, Tania M (2012) Nutritional and medicinal importance of Pleurotus mushrooms: An overview. Food Rev Int 28: 313–329. doi: 10.1080/87559129.2011.637267
|
| [22] |
Vitak TY, Wasser SP, Nevo E, et al. (2015) Structural Changes of Erythrocyte Surface Glycoconjugates after Treatment with Medicinal Mushrooms. Int J Med Mushrooms 17: 867–878. doi: 10.1615/IntJMedMushrooms.v17.i9.70
|
| [23] |
Maschio BH, Gentil BC, Caetano ELA, et al. (2017) Characterization of the Effects of the Shiitake Culinary-Medicinal Mushroom, Lentinus edodes (Agaricomycetes), on Severe Gestational Diabetes Mellitus in Rats. Int J Med Mushrooms 19: 991–1000. doi: 10.1615/IntJMedMushrooms.2017024498
|
| [24] |
Chen YH, Lee CH, Hsu TH, et al. (2015) Submerged-Culture Mycelia and Broth of the Maitake Medicinal Mushroom Grifola frondosa (Higher Basidiomycetes) Alleviate Type 2 Diabetes-Induced Alterations in Immunocytic Function. Int J Med Mushrooms 17: 541–556. doi: 10.1615/IntJMedMushrooms.v17.i6.50
|
| [25] |
Rony KA, Ajith TA, Janardhanan KK (2015) Hypoglycemic and Hypolipidemic Effects of the Cracked-Cap Medicinal Mushroom Phellinus rimosus (Higher Basidiomycetes) in Streptozotocin-Induced Diabetic Rats. Int J Med Mushrooms 17: 521–531. doi: 10.1615/IntJMedMushrooms.v17.i6.30
|
| [26] |
Yurkiv B, Wasser SP, Nevo E, et al. (2015) The Effect of Agaricus brasiliensis and Ganoderma lucidum Medicinal Mushroom Administration on the L-arginine/Nitric Oxide System and Rat Leukocyte Apoptosis in Experimental Type 1 Diabetes Mellitus. Int J Med Mushrooms 17: 339–350. doi: 10.1615/IntJMedMushrooms.v17.i4.30
|
| [27] | Jayasuriya WJ, Suresh TS, Abeytunga D, et al. (2012) Oral hypoglycemic activity of culinary-medicinal mushrooms Pleurotus ostreatus and P. cystidiosus (higher basidiomycetes) in normal and alloxan-induced diabetic Wistar rats. Int J Med Mushrooms 14: 347–355. |
| [28] |
Ganeshpurkar A, Kohli S, Rai G (2014) Antidiabetic potential of polysaccharides from the white oyster culinary-medicinal mushroom Pleurotus florida (higher Basidiomycetes). Int J Med Mushrooms 16: 207–217. doi: 10.1615/IntJMedMushr.v16.i3.10
|
| [29] |
Lei H, Guo S, Han J, et al. (2012) Hypoglycemic and hypolipidemic activities of MT-alpha-glucan and its effect on immune function of diabetic mice. Carbohydr Polym 89: 245–250. doi: 10.1016/j.carbpol.2012.03.003
|
| [30] |
Zhang Y, Hu T, Zhou H, et al. (2016) Antidiabetic effect of polysaccharides from Pleurotus ostreatus in streptozotocin-induced diabetic rats. Int J Biol Macromol 83: 126–132. doi: 10.1016/j.ijbiomac.2015.11.045
|
| [31] |
Zhou S, Liu Y, Yang Y, et al. (2015) Hypoglycemic Activity of Polysaccharide from Fruiting Bodies of the Shaggy Ink Cap Medicinal Mushroom, Coprinus comatus (Higher Basidiomycetes), on Mice Induced by Alloxan and Its Potential Mechanism. Int J Med Mushrooms 17: 957–964. doi: 10.1615/IntJMedMushrooms.v17.i10.50
|
| [32] |
Jeong SC, Jeong YT, Yang BK, et al. (2010) White button mushroom (Agaricus bisporus) lowers blood glucose and cholesterol levels in diabetic and hypercholesterolemic rats. Nutr Res 30: 49–56. doi: 10.1016/j.nutres.2009.12.003
|
| [33] |
Kiho T, Sobue S, Ukai S (1994) Structural features and hypoglycemic activities of two polysaccharides from a hot-water extract of Agrocybe cylindracea. Carbohydr Res 251: 81–87. doi: 10.1016/0008-6215(94)84277-9
|
| [34] |
Gray AM, Flatt PR (1998) Insulin-releasing and insulin-like activity of Agaricus campestris (mushroom). J Endocrinol 157: 259–266. doi: 10.1677/joe.0.1570259
|
| [35] |
Wisitrassameewong K, Karunarathna SC, Thongklang N, et al. (2012) Agaricus subrufescens: A review. Saudi J Biol Sci 19: 131–146. doi: 10.1016/j.sjbs.2012.01.003
|
| [36] |
Kerrigan RW (2005) Agaricus subrufescens, a cultivated edible and medicinal mushroom, and its synonyms. Mycologia 97: 12–24. doi: 10.1080/15572536.2006.11832834
|
| [37] |
Niwa A, Tajiri T, Higashino H (2011) Ipomoea batatas and Agarics blazei ameliorate diabetic disorders with therapeutic antioxidant potential in streptozotocin-induced diabetic rats. J Clin Biochem Nutr 48: 194–202. doi: 10.3164/jcbn.10-78
|
| [38] |
Vincent HK, Innes KE, Vincent KR (2007) Oxidative stress and potential interventions to reduce oxidative stress in overweight and obesity. Diabetes Obes Metab 9: 813–839. doi: 10.1111/j.1463-1326.2007.00692.x
|
| [39] |
Hu XY, Liu CG, Wang X, et al. (2017) Hpyerglycemic and anti-diabetic nephritis activities of polysaccharides separated from Auricularia auricular in diet-streptozotocin-induced diabetic rats. Exp Ther Med 13: 352–358. doi: 10.3892/etm.2016.3943
|
| [40] |
Ding ZY, Lu YJ, Lu ZX, et al. (2010) Hypoglycaemic effect of comatin, an antidiabetic substance separated from Coprinus comatus broth, on alloxan-induced-diabetic rats. Food Chem 121: 39–43. doi: 10.1016/j.foodchem.2009.12.001
|
| [41] |
Lv YT, Han LN, Yuan C, et al. (2009) Comparison of Hypoglycemic Activity of Trace Elements Absorbed in Fermented Mushroom of Coprinus comatus. Biol Trace Elem Res 131: 177–185. doi: 10.1007/s12011-009-8352-7
|
| [42] |
Guo JY, Han CC, Liu YM (2010) A Contemporary Treatment Approach to Both Diabetes and Depression by Cordyceps sinensis, Rich in Vanadium. Evid Based Complement Alternat Med: 7: 387–389. doi: 10.1093/ecam/nep201
|
| [43] |
Nie S, Cui SW, Xie MY, et al. (2013) Bioactive polysaccharides from Cordyceps sinensis: Isolation, structure features and bioactivities. Bioact Carbohydrates Dietary Fibre 1: 38–52. doi: 10.1016/j.bcdf.2012.12.002
|
| [44] |
Pan D, Zhang D, Wu JS, et al. (2013) Antidiabetic, Antihyperlipidemic and Antioxidant Activities of a Novel Proteoglycan from Ganoderma Lucidum Fruiting Bodies on db/db Mice and the Possible Mechanism. PLoS One 8: e68332. doi: 10.1371/journal.pone.0068332
|
| [45] |
Hong L, Xun M, Wutong W (2007) Anti-diabetic effect of an alpha-glucan from fruit body of maitake (Grifola frondosa) on KK-Ay mice. J Pharm Pharmacol 59: 575–582. doi: 10.1211/jpp.59.4.0013
|
| [46] |
Chaiyasut C, Sivamaruthi BS (2017) Anti-hyperglycemic property of Hericium erinaceus – A mini review. Asian Pac J Trop Biomed 7: 1036–1040. doi: 10.1016/j.apjtb.2017.09.024
|
| [47] |
Liang B, Guo ZD, Xie F, et al. (2013) Antihyperglycemic and antihyperlipidemic activities of aqueous extract of Hericium erinaceus in experimental diabetic rats. BMC Complement Altern Med 13: 253. doi: 10.1186/1472-6882-13-253
|
| [48] |
Geng Y, Lu ZM, Huang W, et al. (2013) Bioassay-Guided Isolation of DPP-4 Inhibitory Fractions from Extracts of Submerged Cultured of Inonotus obliquus. Molecules 18: 1150–1161. doi: 10.3390/molecules18011150
|
| [49] |
Wang J, Wang C, Li S, et al. (2017) Anti-diabetic effects of Inonotus obliquus polysaccharides in streptozotocin-induced type 2 diabetic mice and potential mechanism via PI3K-Akt signal pathway. Biomed Pharmacother 95: 1669–1677. doi: 10.1016/j.biopha.2017.09.104
|
| [50] |
Bisen P, Baghel RK, Sanodiya BS, et al. (2010) Lentinus edodes: A macrofungus with pharmacological activities. Curr Med Chem 17: 2419–2430. doi: 10.2174/092986710791698495
|
| [51] | Wahab NAA, Abdullah N, Aminudin N (2014) Characterisation of Potential Antidiabetic-Related Proteins from Pleurotus pulmonarius (Fr.) Quél. (Grey Oyster Mushroom) by MALDI-TOF/TOF Mass Spectrometry. Biomed Res Int 2014: 131607. |
| [52] | Badole SL, Patel NM, Thakurdesai PA, et al. (2008) Interaction of Aqueous Extract of Pleurotus pulmonarius (Fr.) Quel-Champ. with Glyburide in Alloxan Induced Diabetic Mice. Evid Based Complement Alternat Med 5: 159–164. |
| [53] |
Kiho T, Morimoto H, Kobayashi T, et al. (2000) Effect of a polysaccharide (TAP) from the fruiting bodies of Tremella aurantia on glucose metabolism in mouse liver. Biosci Biotechnol Biochem 64: 417–419. doi: 10.1271/bbb.64.417
|
| [54] |
Kiho T, Kochi M, Usui S, et al. (2001) Antidiabetic effect of an acidic polysaccharide (TAP) from Tremella aurantia and its degradation product (TAP-H). Biol Pharm Bull 24: 1400–1403. doi: 10.1248/bpb.24.1400
|
| [55] |
Cho EJ, Hwang HJ, Kim SW, et al. (2007) Hypoglycemic effects of exopolysaccharides produced by mycelial cultures of two different mushrooms Tremella fuciformis and Phellinus baumii in ob/ob mice. Appl Microbiol Biotechnol 75: 1257–1265. doi: 10.1007/s00253-007-0972-2
|
| [56] |
Fu M, Wang L, Wang XY, et al. (2018) Determination of the Five Main Terpenoids in Different Tissues of Wolfiporia cocos. Molecules 23: 1839. doi: 10.3390/molecules23081839
|
| [57] |
Esteban CI (2009) Medicinal interest of Poria cocos (Wolfiporia extensa). Rev Iberoam Micol 26: 103–107. doi: 10.1016/S1130-1406(09)70019-1
|
| [58] |
Li Y, Zhang J, Li T, et al. (2016) A Comprehensive and Comparative Study of Wolfiporia extensa Cultivation Regions by Fourier Transform Infrared Spectroscopy and Ultra-Fast Liquid Chromatography. PLoS One 11: e0168998. doi: 10.1371/journal.pone.0168998
|
| [59] |
Shafrir E, Spielman S, Nachliel I, et al. (2001) Treatment of diabetes with vanadium salts: general overview and amelioration of nutritionally induced diabetes in the Psammomys obesus gerbil. Diabetes Metab Res Rev 17: 55–66. doi: 10.1002/1520-7560(2000)9999:9999<::AID-DMRR165>3.0.CO;2-J
|
| [60] |
Clark TA, Deniset JF, Heyliger CE, et al. (2014) Alternative therapies for diabetes and its cardiac complications: role of vanadium. Heart Fail Rev 19: 123–132. doi: 10.1007/s10741-013-9380-0
|
| [61] | Gruzewska K, Michno A, Pawelczyk T, et al. (2014) Essentiality and toxicity of vanadium supplements in health and pathology. J Physiol Pharmacol 65: 603–611. |
| [62] |
Halberstam M, Cohen N, Shlimovich P, et al. (1996) Oral vanadyl sulfate improves insulin sensitivity in NIDDM but not in obese nondiabetic subjects. Diabetes 45: 659–666. doi: 10.2337/diab.45.5.659
|
| [63] | Huang HY, Korivi M, Chaing YY, et al. (2012) Pleurotus tuber-regium Polysaccharides Attenuate Hyperglycemia and Oxidative Stress in Experimental Diabetic Rats. Evid Based Complement Alternat Med 2012: 856381. |
| [64] |
Huang HY, Korivi M, Yang HT, et al. (2014) Effect of Pleurotus tuber-regium polysaccharides supplementation on the progression of diabetes complications in obese-diabetic rats. Chin J Physiol 57: 198–208. doi: 10.4077/CJP.2014.BAC245
|
| [65] |
Kobayashi M, Kawashima H, Takemori K, et al. (2012) Ternatin, a cyclic peptide isolated from mushroom, and its derivative suppress hyperglycemia and hepatic fatty acid synthesis in spontaneously diabetic KK-A(y) mice. Biochem Biophys Res Commun 427: 299–304. doi: 10.1016/j.bbrc.2012.09.045
|
| [66] | Laurino LF, Viroel FJM, Pickler TB, et al. (2017) Functional foods in gestational diabetes: Evaluation of the oral glucose tolerance test (OGTT) in pregnant rats treated with mushrooms. Reprod Toxicol 72: 36. |
| [67] | Jayasuriya WJ, Wanigatunge CA, Fernando GH, et al. (2015) Hypoglycaemic activity of culinary Pleurotus ostreatus and P. cystidiosus mushrooms in healthy volunteers and type 2 diabetic patients on diet control and the possible mechanisms of action. Phytother Res 29: 303–309. |
| [68] | Gao Y, Lan J, Dai X, et al. (2004) A Phase I/II Study of Ling Zhi Mushroom Ganoderma lucidum (W.Curt.:Fr.) Lloyd (Aphyllophoromycetideae) Extract in Patients with Type II Diabetes Mellitus. Int J Med Mushrooms 6: 327-334. |
| [69] |
Friedman M (2016) Mushroom Polysaccharides: Chemistry and Antiobesity, Antidiabetes, Anticancer, and Antibiotic Properties in Cells, Rodents, and Humans. Foods 5: 80. doi: 10.3390/foods5040080
|
| [70] |
Lo HC, Wasser SP (2011) Medicinal mushrooms for glycemic control in diabetes mellitus: history, current status, future perspectives, and unsolved problems (review). Int J Med Mushrooms 13: 401–426. doi: 10.1615/IntJMedMushr.v13.i5.10
|
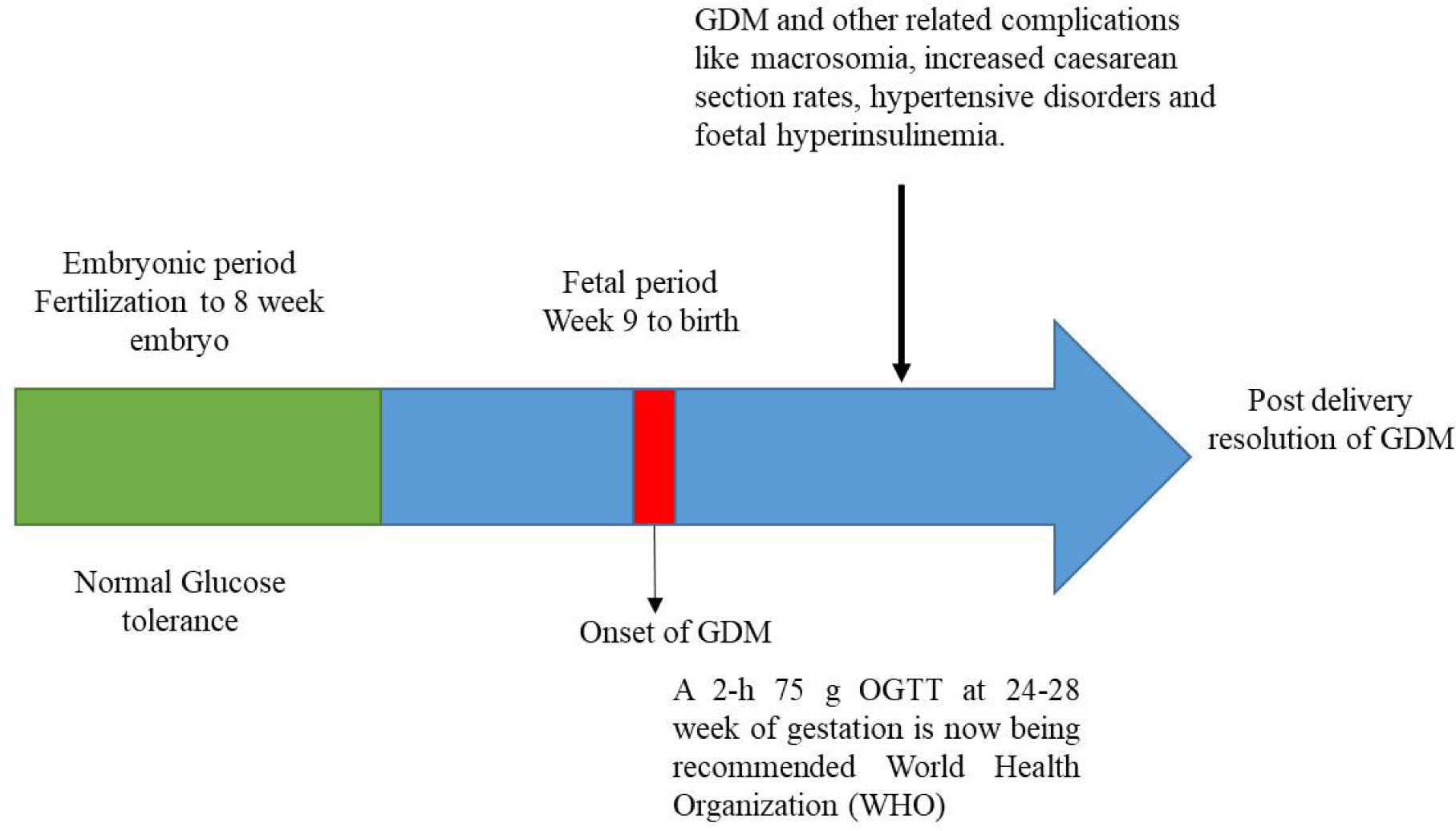
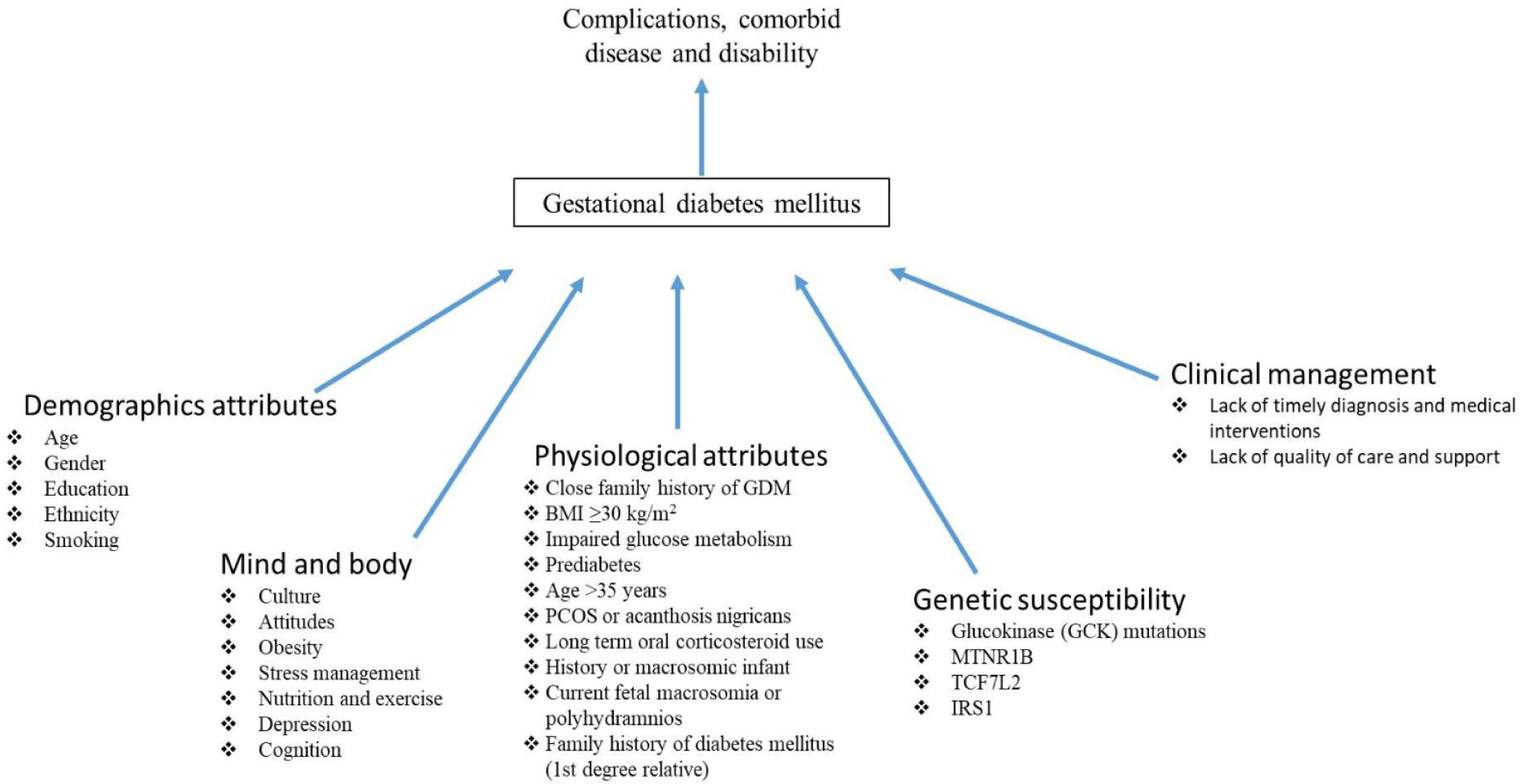
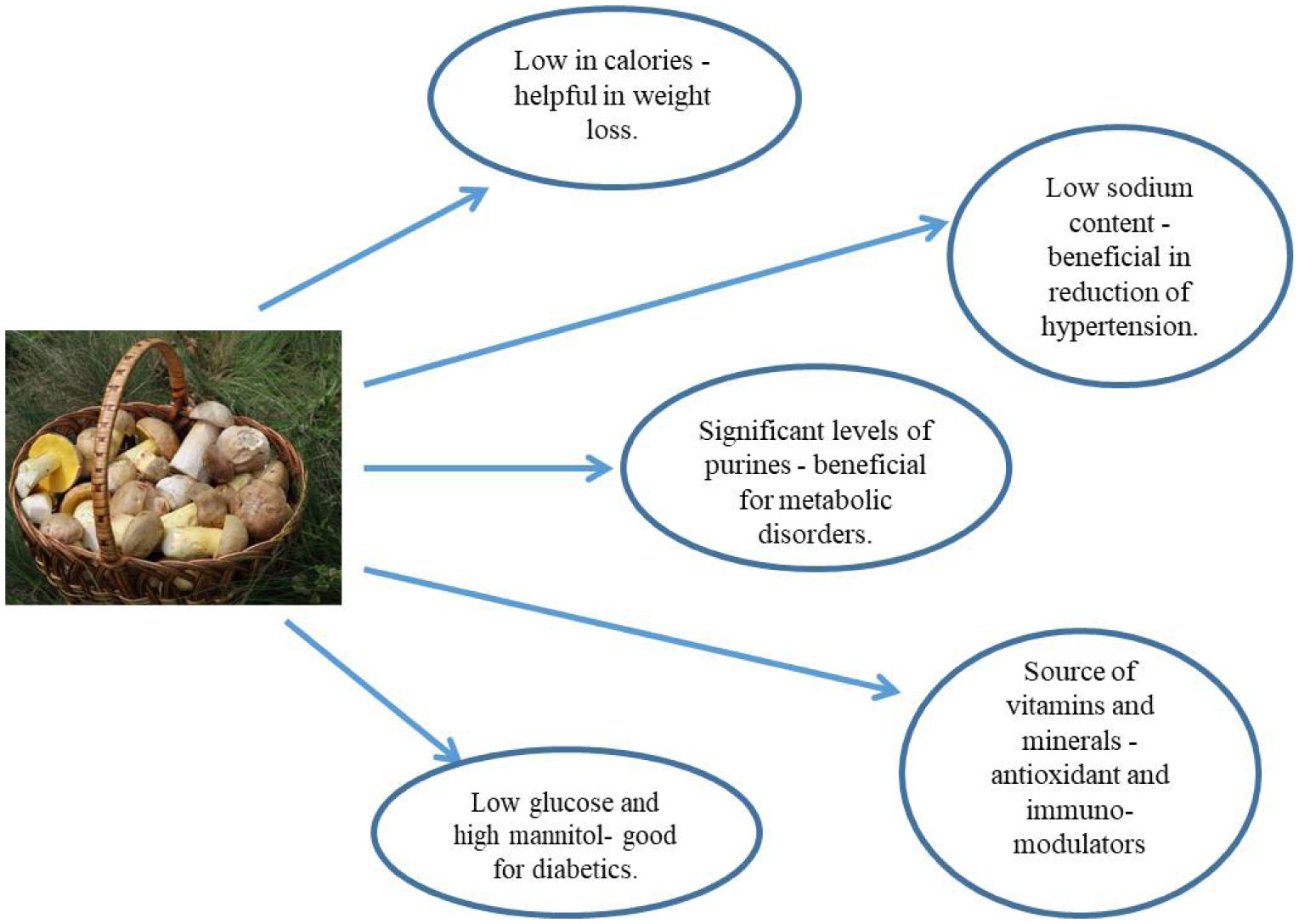
Figures(3) / Tables(2)

Vandana Gulati, Mansi Dass Singh, Pankaj Gulati. Role of mushrooms in gestational diabetes mellitus[J]. AIMS Medical Science, 2019, 6(1): 49-66. doi: 10.3934/medsci.2019.1.49







 DownLoad:
DownLoad: