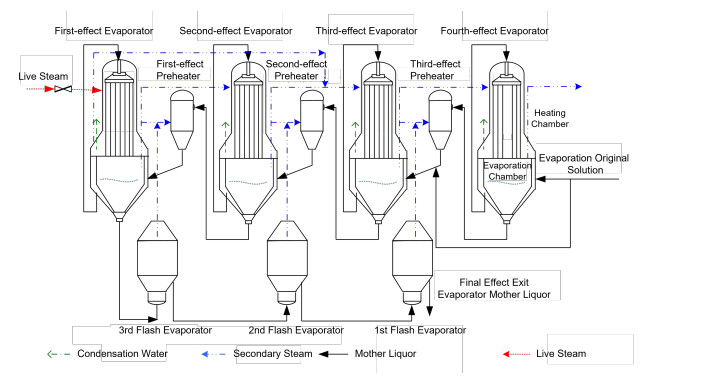
The evaporation process is vital in alumina production, with mother liquor concentration serving as a critical control parameter. To address the challenge of online detection, we propose the introduction of a soft measurement strategy. First, due to the significant fluctuations in the production process variables and inter-variable coupling, comprehensive grey correlation analysis and kernel principal component analysis are employed to reduce the input dimension and computational complexity of the data, enhancing the efficiency of the soft sensing model. The reduced robust least-squares support-vector machine (LSSVM), with its commendable predictive performance, is used for modeling and predicting the principal components. Concurrently, an improved Pattern Search-Differential Evolution (PS-DE) algorithm is proposed for optimizing the pivotal parameters of the LSSVM network. Lastly, on-site industrial data validation indicates that the new model offers superior tracking capabilities and heightened accuracy. It is deemed aptly suitable for the online detection of mother liquor concentration.
Citation: Xiaoshan Qian, Lisha Xu, Xinmei Yuan. Soft-sensing modeling of mother liquor concentration in the evaporation process based on reduced robust least-squares support-vector machine[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19941-19962. doi: 10.3934/mbe.2023883
The evaporation process is vital in alumina production, with mother liquor concentration serving as a critical control parameter. To address the challenge of online detection, we propose the introduction of a soft measurement strategy. First, due to the significant fluctuations in the production process variables and inter-variable coupling, comprehensive grey correlation analysis and kernel principal component analysis are employed to reduce the input dimension and computational complexity of the data, enhancing the efficiency of the soft sensing model. The reduced robust least-squares support-vector machine (LSSVM), with its commendable predictive performance, is used for modeling and predicting the principal components. Concurrently, an improved Pattern Search-Differential Evolution (PS-DE) algorithm is proposed for optimizing the pivotal parameters of the LSSVM network. Lastly, on-site industrial data validation indicates that the new model offers superior tracking capabilities and heightened accuracy. It is deemed aptly suitable for the online detection of mother liquor concentration.

| [1] |
Z. Huda, N. I. Taib, T. Zaharinie, Characterization of 2024-t3: An aerospace aluminum alloy, Mater. Chem. Phys., 113 (2009), 515–517. https://doi.org/10.1016/j.matchemphys.2008.09.050 doi: 10.1016/j.matchemphys.2008.09.050

|
| [2] |
J. Zhao, Y. Lv, Output-feedback robust tracking control of uncertain systems via adaptive learning, Int. J. Control Autom. Syst., 21 (2023), 1108–1118. https://doi.org/10.1007/s12555-021-0882-6 doi: 10.1007/s12555-021-0882-6
|
| [3] | A. Smirnov, D. Kibartas, A. Senyuta, A. Panov, Miniplant tests of hcl technology of alumina production, Light Metals, Springer, (2018), 57–62. https://doi.org/10.1007/978-3-319-72284-9 |
| [4] |
C. Damour, M. Benne, B. Grondin-Perez, J. P. Chabriat, Soft-sensor for industrial sugar crystallization: On-line mass of crystals, concentration and purity measurement, Control Eng. Pract., 18 (2010), 839–844. https://doi.org/10.1016/j.conengprac.2010.03.005 doi: 10.1016/j.conengprac.2010.03.005
|
| [5] |
Y. Meng, Q. Lan, J. Qin, S. Yu, H. Pang, K. Zheng, Data-driven soft sensor modeling based on twin support vector regression for cane sugar crystallization, J. Food Eng., 241 (2019), 159–165. https://doi.org/10.1016/j.jfoodeng.2018.07.035 doi: 10.1016/j.jfoodeng.2018.07.035
|
| [6] | S. Jouenne, G. Heurteux, B. Levache, Online monitoring for measuring the viscosity of the injected fluids containing polymer in chemical eor, in SPE EOR Conference at Oil and Gas West Asia, 2022. https://doi.org/10.2118/200209-MS |
| [7] |
J. Tran, M. Linnemann, M. Piper, E. Kenig, On the coupled condensation-evaporation in pillow-plate condensers: Investigation of cooling medium evaporation, Appl. Thermal Eng., 124 (2017), 1471–1480. https://doi.org/10.1016/j.applthermaleng.2017.06.050 doi: 10.1016/j.applthermaleng.2017.06.050
|
| [8] |
A. Peters, W. Durner, Simplified evaporation method for determining soil hydraulic properties, J. Hydrology, 356 (2008), 147–162. https://doi.org/10.1016/j.jhydrol.2008.04.016 doi: 10.1016/j.jhydrol.2008.04.016
|
| [9] |
J. A. Suykens, J. Vandewalle, Least squares support vector machine classifiers, Neural Process. Lett., 9 (1999), 293–300. https://doi.org/10.1023/A:1018628609742 doi: 10.1023/A:1018628609742
|
| [10] |
Z. Liu, D. Yang, Y. Wang, M. Lu, R. Li, Egnn: Graph structure learning based on evolutionary computation helps more in graph neural networks, Appl. Soft Comput., 135 (2023), 110040. https://doi.org/10.1016/j.asoc.2023.110040 doi: 10.1016/j.asoc.2023.110040
|
| [11] |
Y. Wang, Z. Liu, J. Xu, W. Yan, Heterogeneous network representation learning approach for ethereum identity identification, IEEE Trans. Comput. Social Syst., 2022. https://doi.org/10.1109/TCSS.2022.3164719 doi: 10.1109/TCSS.2022.3164719
|
| [12] |
P. Kadlec, B. Gabrys, S. Strandt, Data-driven soft sensors in the process industry, Comput. chem. Eng., 33 (2009), 795–814. https://doi.org/10.1016/j.compchemeng.2008.12.012 doi: 10.1016/j.compchemeng.2008.12.012
|
| [13] |
M. L. Fravolini, G. Del Core, U. Papa, P. Valigi, M. R. Napolitano, Data-driven schemes for robust fault detection of air data system sensors, IEEE Trans. Control Syst. Technol., 27 (2017), 234–248. https://doi.org/10.1109/TCST.2017.2758345 doi: 10.1109/TCST.2017.2758345
|
| [14] | Y. Wang, J. Ding, T. Chai, Soft-sensor for alkaline solution concentration of evaporation process, in 2008 7th World Congress on Intelligent Control and Automation, (2008), 3476–3480. https://doi.org/10.1109/WCICA.2008.4594499 |
| [15] |
H. Su, W. Qi, Y. Schmirander, S. E. Ovur, S. Cai, X. Xiong, A human activity-aware shared control solution for medical human–robot interaction, Assembly Autom., 42 (2022), 388–394. https://doi.org/10.1108/AA-12-2021-0174 doi: 10.1108/AA-12-2021-0174
|
| [16] |
W. Qi, H. Su, A cybertwin based multimodal network for ecg patterns monitoring using deep learning, IEEE Trans. Industr. Inform., 18 (2022), 6663–6670. https://doi.org/10.1109/TII.2022.3159583 doi: 10.1109/TII.2022.3159583
|
| [17] |
H. Morales, F. di Sciascio, E. Aguirre-Zapata, A. N. Amicarelli, A model-based supersaturation estimator (inferential or soft-sensor) for industrial sugar crystallization process, J. Process Control, 129 (2023), 103065. https://doi.org/10.1016/j.jprocont.2023.103065 doi: 10.1016/j.jprocont.2023.103065
|
| [18] | H. Wang, D. Hu, Comparison of svm and ls-svm for regression, in 2005 International conference on neural networks and brain, 1 (2005), 279–283. https://doi.org/10.1109/icnnb.2005.1614615 |
| [19] |
W. Qi, H. Fan, H. R. Karimi, H. Su, An adaptive reinforcement learning-based multimodal data fusion framework for human–robot confrontation gaming, Neural Networks, 164 (2023), 489–496. https://doi.org/10.1016/j.neunet.2023.04.043 doi: 10.1016/j.neunet.2023.04.043
|
| [20] |
H. Xu, G. Chen, An intelligent fault identification method of rolling bearings based on lssvm optimized by improved pso, Mech. Syst. Signal Process., 35 (2013), 167–175. https://doi.org/10.1016/j.ymssp.2012.09.005 doi: 10.1016/j.ymssp.2012.09.005
|
| [21] |
W. Qi, S. E. Ovur, Z. Li, A. Marzullo, R. Song, Multi-sensor guided hand gesture recognition for a teleoperated robot using a recurrent neural network, IEEE Robot. Autom. Lett., 6 (2021), 6039–6045. https://doi.org/10.1109/LRA.2021.3089999 doi: 10.1109/LRA.2021.3089999
|
| [22] | Y. Wang, X. Chen, On temperature soft sensor model of rotary kiln burning zone based on rs-lssvm, in 2017 36th Chinese Control Conference (CCC), (2017), 9643–9646. https://doi.org/10.23919/chicc.2017.8028894 |
| [23] | T. Zheng, Q. Li, Soft measurement modeling based on temperature prediction of lssvm and arma rotary kiln burning zone, in 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), (2019), 642–647. https://doi.org/10.1109/imcec46724.2019.8983824 |
| [24] |
J. Liu, L. Yang, X. Nan, Y. Liu, Q. Hou, K. Lan, et al., A soft sensing method of billet surface temperature based on ilgssa-lssvm, Sci. Reports, 12 (2022), 21876. https://doi.org/10.1038/s41598-022-26478-3 doi: 10.1038/s41598-022-26478-3
|
| [25] |
Z. J. Liu, J. Q. Wan, Y. W. Ma, Y. Wang, Online prediction of effluent cod in the anaerobic wastewater treatment system based on pca-lssvm algorithm, Environ. Sci. Pollut. Res., 26 (2019), 12828–12841. https://doi.org/10.1007/s11356-019-04671-8 doi: 10.1007/s11356-019-04671-8
|
| [26] |
Y. Kuo, T. Yang, G. W. Huang, The use of grey relational analysis in solving multiple attribute decision-making problems, Comput. Industr. Eng., 55 (2008), 80–93. https://doi.org/10.1016/j.cie.2007.12.002 doi: 10.1016/j.cie.2007.12.002
|
| [27] |
N. Tosun, Determination of optimum parameters for multi-performance characteristics in drilling by using grey relational analysis, Int. J. Adv. Manuf. Technol., 28 (2006), 450–455. https://doi.org/10.1007/s00170-004-2386-y doi: 10.1007/s00170-004-2386-y
|
| [28] |
E. Özgür, E. C. Sabir, Ç. Sarpkaya, Multi-objective optimization of thermal and sound insulation properties of basalt and carbon fabric reinforced composites using the taguchi grey relations analysis, J. Natural Fibers, 20 (2023), 2178580. https://doi.org/10.1080/15440478.2023.2178580 doi: 10.1080/15440478.2023.2178580
|
| [29] |
R. W. Saaty, The analytic hierarchy process–what it is and how it is used, Math. Model., 9 (1987), 161–176. https://doi.org/10.1016/0270-0255(87)90473-8 doi: 10.1016/0270-0255(87)90473-8
|
| [30] |
Q. Jiang, X. Yan, Parallel pca–kpca for nonlinear process monitoring, Control Eng. Pract., 80 (2018), 17–25. https://doi.org/10.1016/j.conengprac.2018.07.012 doi: 10.1016/j.conengprac.2018.07.012
|
| [31] |
J. Liu, J. Wang, X. Liu, T. Ma, Z. Tang, Mwrspca: online fault monitoring based on moving window recursive sparse principal component analysis, J. Intell. Manuf., (2022), 1–17. https://doi.org/10.1007/s10845-020-01721-8 doi: 10.1007/s10845-020-01721-8
|
| [32] | J. Suykens, Least squares support vector machines for classification and nonlinear modelling, Neural Network World, 10 (2000), 29–48. |
| [33] |
J. A. Suykens, J. De Brabanter, L. Lukas, J. Vandewalle, Weighted least squares support vector machines: robustness and sparse approximation, Neurocomputing, 48 (2002), 85–105. https://doi.org/10.1016/S0925-2312(01)00644-0 doi: 10.1016/S0925-2312(01)00644-0
|
| [34] |
C. F. Lin, S. D. Wang, Training algorithms for fuzzy support vector machines with noisy data, Patt. Recogn. Lett., 25 (2004), 1647–1656. https://doi.org/10.1016/j.patrec.2004.06.009 doi: 10.1016/j.patrec.2004.06.009
|
| [35] |
D. Tsujinishi, S. Abe, Fuzzy least squares support vector machines for multiclass problems, Neural Networks, 16 (2003), 785–792. https://doi.org/10.1016/S0893-6080(03)00110-2 doi: 10.1016/S0893-6080(03)00110-2
|
| [36] |
X. Q. Zeng, G. Z. Li, Incremental partial least squares analysis of big streaming data, Patt. Recognit., 47 (2014), 3726–3735. https://doi.org/10.1016/j.patcog.2014.05.022 doi: 10.1016/j.patcog.2014.05.022
|
| [37] | K. Bennett, M. Embrechts, An optimization perspective on kernel partial least squares regression, Nato Sci. Series sub series III computer and systems sciences, 190 (2003), 227–250. |
| [38] | J. Valyon, G. Horváth, A sparse least squares support vector machine classifier, in 2004 IEEE International Joint Conference on Neural Networks, 1 (2004), 543–548. https://doi.org/10.1109/IJCNN.2004.1379967 |
| [39] | D. R. Heisterkamp, J. Peng, H. K. Dai, Adaptive quasiconformal kernel metric for image retrieval, in Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2 (2001), 543–548. https://doi.org/10.1109/CVPR.2001.990987 |
| [40] | G. Baudat, F. Anouar, Kernel-based methods and function approximation, in IJCNN'01. International Joint Conference on Neural Networks, 2 (2001), 1244–1249. https://doi.org/10.1109/IJCNN.2001.939539 |
| [41] | R. Rosipal, L. J. Trejo, Kernel partial least squares regression in reproducing kernel hilbert space, J. Mach. Learn. Res., 2 (2001), 97–123. |
| [42] | R. Sun, X. Qian, Soft sensor of concentration of sodium aluminate solution based on reduction robust lssvm, J. Syst. Simul., 27 (2015), 2203. |
| [43] |
M. C. Chen, D. M. Tsai, A simulated annealing approach for optimization of multi-pass turning operations, Int. J. Product. Res., 34 (1996), 2803–2825. https://doi.org/10.1080/00207549608905060 doi: 10.1080/00207549608905060
|
| [44] |
N. Mughees, M. H. Jaffery, A. Mughees, E. A. Ansari, A. Mughees, Reinforcement learning-based composite differential evolution for integrated demand response scheme in industrial microgrids, Appl. Energy, 342 (2015), 121150. https://doi.org/10.1016/j.apenergy.2023.121150 doi: 10.1016/j.apenergy.2023.121150
|
| [45] |
H. Su, W. Qi, J. Chen, D. Zhang, Fuzzy approximation-based task-space control of robot manipulators with remote center of motion constraint, IEEE Trans. Fuzzy Syst., 30 (2022), 1564–1573. https://doi.org/10.1109/tfuzz.2022.3157075 doi: 10.1109/tfuzz.2022.3157075
|
| [46] |
H. Su, W. Qi, Y. Hu, H. R. Karimi, G. Ferrigno, E. De Momi, An incremental learning framework for human-like redundancy optimization of anthropomorphic manipulators, IEEE Trans. Industr. Inform., 18 (2020), 1864–1872. https://doi.org/10.1109/TII.2020.3036693 doi: 10.1109/TII.2020.3036693
|






Figures(7) / Tables(4)

Xiaoshan Qian, Lisha Xu, Xinmei Yuan. Soft-sensing modeling of mother liquor concentration in the evaporation process based on reduced robust least-squares support-vector machine[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19941-19962. doi: 10.3934/mbe.2023883







 DownLoad:
DownLoad: